Здравствуйте.
Если вы занимаетесь DataMining, анализом текстов на выявление мнений или вам просто интересны статистические модели для оценки эмоциональной окраски предложений — эта статья может оказаться интересной.
Далее, чтобы не тратить время потенциального читателя впустую на груду теории и рассуждений, сразу краткие результаты.
Реализованный подход работает приблизительно с 55% точностью в трех классах: негативный, нейтральный, позитивный. Как говорит Википедия, 70% точность приблизительно равна точности человеческих суждений в среднем (в силу субъективности трактований каждого).
Следует отметить, что существует немало утилит с точностью выше полученной мной, но описанный подход, можно достаточно просто усовершенствовать (будет описано ниже) и получить в итоге 65-70%. Если после всего вышеизложенного у вас осталось желание читать — добро пожаловать под кат.
Чтобы определить эмоциональную окраску предложения (SO — sentiment orientation), необходимо понять о чем в нем идет речь. Это логично. Но как объяснить машине, что такое хорошо, а что такое плохо?
Первым вариантом, сразу же появляющемся на уме, есть сумма количества плохих/хороших слов, умноженных на вес каждого. Так называемый подход, основанный на «мешке слов». Удивительно простой и быстрый алгоритм, в сочетании с предобработкой на основе правил дающий неплохие результаты (до 60 — 80% точности в зависимости от корпуса). По сути, такой подход является примером униграммной модели, а это значит, что в самом наивном случае предложения «This product rather good than bad» и «This product rather bad than good» будут иметь одинаковую SO. Решить эту проблему можно перейдя от униграммной к мультиномиальной модели. Также следует отметить, что необходимо иметь солидный постоянно обновляемый словарь, содержащий плохие и хорошие термы + их вес, который может быть специфичным в зависимости от данных.
Примером простейшей мультиномиальной модели является наивный метод Байеса. На хабре есть несколько статей, посвященных нему, в частности эта.
Преимущество мультиномиальной модели перед униграммной заключается в том, что мы можем учитывать контекст, в котором то или иное высказывание было произнесено. Это решает проблему с предложениями, описанными выше, но вводит новое ограничение: если в обучающей выборке отсутствует выбранный n-gram, то SO на тестовых данных будет равно 0. Эта проблема всегда была и будет. Ее можно решить 2 способами: увеличив объем обучающей выборки (не забывая, что можно попутно схватить эффект переобучения), либо используя сглаживание (например Лапласа или Good-Turing).
Наконец-то мы плавно подошли к идее PMI.
Наряду с формулой Байеса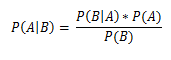 , введем понятие
, введем понятие
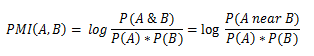
PMI — pointwise mutual information, поточечная взаимная информация.
в приведенной выше формуле A и B — слова/биграммы/n-нграммы, P(A), P(B) — априорные вероятности появления термина А и B соответственно в обучающей выборке (отношение количества вхождений к общему количеству слов в корпусе), P(A near B) — вероятность термина A встретиться вместе/рядом с термином B; «рядом» можно конфигурировать вручную, по умолчанию расстояние равно 10 терминам влево и вправо; основание логарифма не играет роли, для простоты примем его равным 2.
Позитивный знак логарифма будет означать положительны окрас A по сравнению с B, негативный — отрицательный.
Для нахождения нейтральных отзывов, можно принять какое-то скользящее окно (в данной работе за это отвечает отрезок [-0.154, 0.154]). Окно может быть как константным, так и плавающим в зависимости от данных (показано ниже).
Из сказанного выше можно прийти к следующим утверждениям:
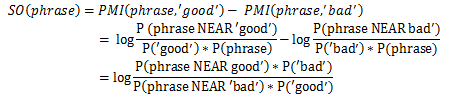
Действительно, чтобы определить к какому классу относятся высказывания «хорошая погода», «быстро ехать», достаточно проверить в обучающей выборке как часто «хорошая погода» и «быстро ехать» встречается рядом с заведомо (установленными человеком в зависимости от модели данных и тестовой выборки) хорошими и плохими словами и установить разницу.
Пойдем немного дальше и вместо сравнений с 1 опорным словом с негативной и позитивной стороны, будем использовать набор заведомо хороших и плохих слов (здесь, например, использовались такие слова:
Положительные: good, nice, excellent, perfect, correct, super
Отрицательные: bad, nasty, poor, terrible, wrong, awful
Соответственно, окончательная формула
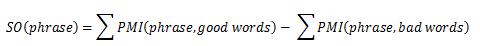
Так, с обсчетом SO разобрались, но как подобрать подходящих кандидатов?
К примеру, есть у нас предложение «Сегодня чудное утро, хорошо бы поехать к озеру».
Логично предположить, что эмоциональный окрас предложению добавляют в большей части прилагательные и наречия. Поэтому чтобы воспользоваться этим, построим конечный автомат, который будет по заданным шаблонам частей речи, выделять из предложения кандидатов на оценку SO. Не трудно догадаться, что предложения будет считаться позитивным отзывом, если сумма SO всех кандидатов > 0.154
В данной работе использовались следующие шаблоны:

В таком случае кандидатами будут:
1. чудное утро
2. хорошо поехать
Осталось только собрать все вместе и протестировать.
Здесь вы найдете исходники на Java. Красоты там мало — писалось просто чтобы попробовать и решить, будет ли использоваться дальше
Корпус: Amazon Product Review Data (> 5.8 миллионов отзывов) liu2.cs.uic.edu/data
На этом корпусе с помощью Lucene строился инвертированный индекс, по которому и производился поиск.
В случае отсутствия данных в индексе, использовались поисковые системы Google(api) и Yahoo! (с их оператором around и near соответственно). Но, к сожалению, из-за скорости работы и неточности результатов (по высокочастотным запросам поисковики выдают приближенное значение количества результатов), решение не совершенно.
Для определения частей речи и токенизации использовалась библиотека OpenNLP
Исходя из вышеизложенного, наиболее предпочтительными векторами усовершенствований являются:
1. Построение более полного дерева разбора частей речи для фильтрации кандидатов
2. Использование бОльшего корпуска в качестве обучающей выборки
3. По возможности использование обучающего корпуса из той же socialmedia, что и тестовая выборка
4. Формирование опорных слов (good|bad) в зависимости от источника данных и тематики
5. Внедрение отрицания в дерево разбора шаблонов
6. Определение сарказма
В целом, система, основанная на PMI может составить конкуренцию системам, основанным на принципе «bag of words», но в идеальной реализации эти две системы должны дополнять друг друга: при отсутствии данных в обучающей выборке, в дело должна вступать система подсчета конкретных слов.
1. Введение в информационный поиск. К. Маннинг, П. Рагхаван, Х. Шютце
2. Foundations of statistical Natural Language Processing. C. Manning, H. Schutze
3.Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. Peter D. Turney
Если вы занимаетесь DataMining, анализом текстов на выявление мнений или вам просто интересны статистические модели для оценки эмоциональной окраски предложений — эта статья может оказаться интересной.
Далее, чтобы не тратить время потенциального читателя впустую на груду теории и рассуждений, сразу краткие результаты.
Реализованный подход работает приблизительно с 55% точностью в трех классах: негативный, нейтральный, позитивный. Как говорит Википедия, 70% точность приблизительно равна точности человеческих суждений в среднем (в силу субъективности трактований каждого).
Следует отметить, что существует немало утилит с точностью выше полученной мной, но описанный подход, можно достаточно просто усовершенствовать (будет описано ниже) и получить в итоге 65-70%. Если после всего вышеизложенного у вас осталось желание читать — добро пожаловать под кат.
Краткое описание принципа
Чтобы определить эмоциональную окраску предложения (SO — sentiment orientation), необходимо понять о чем в нем идет речь. Это логично. Но как объяснить машине, что такое хорошо, а что такое плохо?
Первым вариантом, сразу же появляющемся на уме, есть сумма количества плохих/хороших слов, умноженных на вес каждого. Так называемый подход, основанный на «мешке слов». Удивительно простой и быстрый алгоритм, в сочетании с предобработкой на основе правил дающий неплохие результаты (до 60 — 80% точности в зависимости от корпуса). По сути, такой подход является примером униграммной модели, а это значит, что в самом наивном случае предложения «This product rather good than bad» и «This product rather bad than good» будут иметь одинаковую SO. Решить эту проблему можно перейдя от униграммной к мультиномиальной модели. Также следует отметить, что необходимо иметь солидный постоянно обновляемый словарь, содержащий плохие и хорошие термы + их вес, который может быть специфичным в зависимости от данных.
Примером простейшей мультиномиальной модели является наивный метод Байеса. На хабре есть несколько статей, посвященных нему, в частности эта.
Преимущество мультиномиальной модели перед униграммной заключается в том, что мы можем учитывать контекст, в котором то или иное высказывание было произнесено. Это решает проблему с предложениями, описанными выше, но вводит новое ограничение: если в обучающей выборке отсутствует выбранный n-gram, то SO на тестовых данных будет равно 0. Эта проблема всегда была и будет. Ее можно решить 2 способами: увеличив объем обучающей выборки (не забывая, что можно попутно схватить эффект переобучения), либо используя сглаживание (например Лапласа или Good-Turing).
Наконец-то мы плавно подошли к идее PMI.
Наряду с формулой Байеса
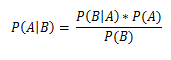 , введем понятие
, введем понятие 
PMI — pointwise mutual information, поточечная взаимная информация.
в приведенной выше формуле A и B — слова/биграммы/n-нграммы, P(A), P(B) — априорные вероятности появления термина А и B соответственно в обучающей выборке (отношение количества вхождений к общему количеству слов в корпусе), P(A near B) — вероятность термина A встретиться вместе/рядом с термином B; «рядом» можно конфигурировать вручную, по умолчанию расстояние равно 10 терминам влево и вправо; основание логарифма не играет роли, для простоты примем его равным 2.
Позитивный знак логарифма будет означать положительны окрас A по сравнению с B, негативный — отрицательный.
Для нахождения нейтральных отзывов, можно принять какое-то скользящее окно (в данной работе за это отвечает отрезок [-0.154, 0.154]). Окно может быть как константным, так и плавающим в зависимости от данных (показано ниже).
Из сказанного выше можно прийти к следующим утверждениям:
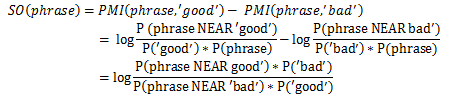
Действительно, чтобы определить к какому классу относятся высказывания «хорошая погода», «быстро ехать», достаточно проверить в обучающей выборке как часто «хорошая погода» и «быстро ехать» встречается рядом с заведомо (установленными человеком в зависимости от модели данных и тестовой выборки) хорошими и плохими словами и установить разницу.
Пойдем немного дальше и вместо сравнений с 1 опорным словом с негативной и позитивной стороны, будем использовать набор заведомо хороших и плохих слов (здесь, например, использовались такие слова:
Положительные: good, nice, excellent, perfect, correct, super
Отрицательные: bad, nasty, poor, terrible, wrong, awful
Соответственно, окончательная формула

Так, с обсчетом SO разобрались, но как подобрать подходящих кандидатов?
К примеру, есть у нас предложение «Сегодня чудное утро, хорошо бы поехать к озеру».
Логично предположить, что эмоциональный окрас предложению добавляют в большей части прилагательные и наречия. Поэтому чтобы воспользоваться этим, построим конечный автомат, который будет по заданным шаблонам частей речи, выделять из предложения кандидатов на оценку SO. Не трудно догадаться, что предложения будет считаться позитивным отзывом, если сумма SO всех кандидатов > 0.154
В данной работе использовались следующие шаблоны:

В таком случае кандидатами будут:
1. чудное утро
2. хорошо поехать
Осталось только собрать все вместе и протестировать.
Реализация
Здесь вы найдете исходники на Java. Красоты там мало — писалось просто чтобы попробовать и решить, будет ли использоваться дальше
Корпус: Amazon Product Review Data (> 5.8 миллионов отзывов) liu2.cs.uic.edu/data
На этом корпусе с помощью Lucene строился инвертированный индекс, по которому и производился поиск.
В случае отсутствия данных в индексе, использовались поисковые системы Google(api) и Yahoo! (с их оператором around и near соответственно). Но, к сожалению, из-за скорости работы и неточности результатов (по высокочастотным запросам поисковики выдают приближенное значение количества результатов), решение не совершенно.
Для определения частей речи и токенизации использовалась библиотека OpenNLP
Как лучше?
Исходя из вышеизложенного, наиболее предпочтительными векторами усовершенствований являются:
1. Построение более полного дерева разбора частей речи для фильтрации кандидатов
2. Использование бОльшего корпуска в качестве обучающей выборки
3. По возможности использование обучающего корпуса из той же socialmedia, что и тестовая выборка
4. Формирование опорных слов (good|bad) в зависимости от источника данных и тематики
5. Внедрение отрицания в дерево разбора шаблонов
6. Определение сарказма
Выводы
В целом, система, основанная на PMI может составить конкуренцию системам, основанным на принципе «bag of words», но в идеальной реализации эти две системы должны дополнять друг друга: при отсутствии данных в обучающей выборке, в дело должна вступать система подсчета конкретных слов.
Использованная литература:
1. Введение в информационный поиск. К. Маннинг, П. Рагхаван, Х. Шютце
2. Foundations of statistical Natural Language Processing. C. Manning, H. Schutze
3.Thumbs Up or Thumbs Down? Semantic Orientation Applied to Unsupervised Classification of Reviews. Peter D. Turney










