В какой-то момент тихую гавань воспринимаемого мной интернета всколыхнула одна из лекций TED.
Описание лекции с сайта:
Внимание.
Для понимания дальнейшего текста просмотр лекции обязателен.
Она длится лишь 18 минут и имеет русские субтитры (спасибо Надежде Лебедевой).
Возможность предсказания поведения акторов сети исключительно путём анализа распространения контента вскружила мне голову! Я во что бы то не стало решил повторить эксперимент хотя бы в кустарных условиях. Остудив голову и поразмыслив, у меня возникло две претензии к профессорам:
1) Поведение биологических вирусов (грипп, T-Virus) если и можно предсказать статистикой распространения, то с огромной погрешностью, ведь помимо контактов акторов на распространение будет влиять и множество сторонних факторов, от физического здоровья участвующих персонажей до вспышек на солнце.
2) Концепция «Парадокса дружбы» (случайный человек называет своего друга и у того в большинстве случаев будет больше друзей) порой кажется мне и вовсе абсурдной. Для проверки я попросил десятерых своих друзей назвать наобум какого-нибудь своего друга, и выбор лишь двоих из них был солидарен с теорией «Парадокса дружбы».
Для решения первого вопроса в качестве информационного вируса мной была выбрана просьба о помощи. У одного из участников выборки угнали скутер. Инфоповод этот был удобен тем, что потерпевший вёл поиски используя социальные сети и регулярно отчитывался в них же о результатах.
Для решения вопроса второго вместо теории «Парадокса дружбы» в целях выявления наиболее популярных пользователей в выборке я просто подсчитывал количество связей каждого участника внутри выборки.
Также необходимо упомянуть что в отличии от оригинального исследования средой была выбрана социальная сеть ВКонтакте.
Выборка была собрана из 100 студентов разных факультетов одного московского ВУЗа.
Шкала времени поделена на 20 отметок, где одна отметка — один день (период с 30 июля по 18 августа).
Под «Моментом заражения» подразумевается первый контакт пользователя с инфоповодом (репост, комментирование записи и т.д.).
Весь сбор данных и их обработка проходили вручную (я гуманитарий).
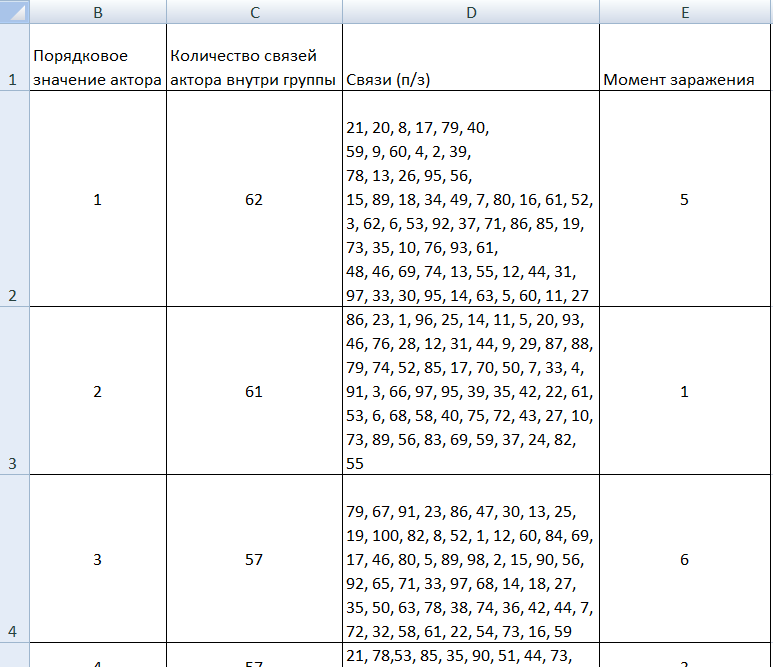
Результатом муторных подсчётов стала таблица ниже.
(показаны по три самых популярных и не популярных актора)


На основе данных популярности акторов внутри выборки я разделил их на две группы:
Группа А — наиболее популярные 20 пользователей
Группа B — остальные 80 пользователей
И окончательным результатом работы стал график.
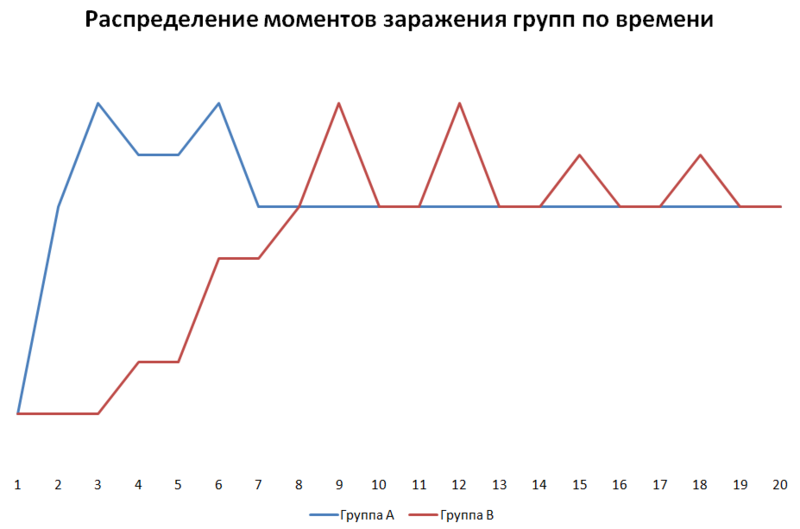
Несмотря на то что данное моё исследование подтвердило первоначальную теорию, ещё раз необходимо напомнить что эксперимент проводился в условиях кустарных, а потому на его результаты полагаться слишком нельзя. Но сам я твёрдо уверовал в возможность предсказания информационных вирусов подобными методами.
Буду благодарен за советы и рекомендации.
Описание лекции с сайта:
После составления карты запутанных социальных сетей Николас Кристакис и его коллега Джеймс Фаулер исследовали возможности использования этой информации во благо. И сейчас Николас Кристакис обнародует свое последнее открытие: социальные сети можно использовать как самый быстрый метод для обнаружения распространения любых эпидемий: от новаторских идей до социально опасного поведения или вирусов.
Внимание.
Для понимания дальнейшего текста просмотр лекции обязателен.
Она длится лишь 18 минут и имеет русские субтитры (спасибо Надежде Лебедевой).
Возможность предсказания поведения акторов сети исключительно путём анализа распространения контента вскружила мне голову! Я во что бы то не стало решил повторить эксперимент хотя бы в кустарных условиях. Остудив голову и поразмыслив, у меня возникло две претензии к профессорам:
1) Поведение биологических вирусов (грипп, T-Virus) если и можно предсказать статистикой распространения, то с огромной погрешностью, ведь помимо контактов акторов на распространение будет влиять и множество сторонних факторов, от физического здоровья участвующих персонажей до вспышек на солнце.
2) Концепция «Парадокса дружбы» (случайный человек называет своего друга и у того в большинстве случаев будет больше друзей) порой кажется мне и вовсе абсурдной. Для проверки я попросил десятерых своих друзей назвать наобум какого-нибудь своего друга, и выбор лишь двоих из них был солидарен с теорией «Парадокса дружбы».
Для решения первого вопроса в качестве информационного вируса мной была выбрана просьба о помощи. У одного из участников выборки угнали скутер. Инфоповод этот был удобен тем, что потерпевший вёл поиски используя социальные сети и регулярно отчитывался в них же о результатах.
Для решения вопроса второго вместо теории «Парадокса дружбы» в целях выявления наиболее популярных пользователей в выборке я просто подсчитывал количество связей каждого участника внутри выборки.
Также необходимо упомянуть что в отличии от оригинального исследования средой была выбрана социальная сеть ВКонтакте.
Выборка была собрана из 100 студентов разных факультетов одного московского ВУЗа.
Шкала времени поделена на 20 отметок, где одна отметка — один день (период с 30 июля по 18 августа).
Под «Моментом заражения» подразумевается первый контакт пользователя с инфоповодом (репост, комментирование записи и т.д.).
Весь сбор данных и их обработка проходили вручную (я гуманитарий).
Результатом муторных подсчётов стала таблица ниже.
(показаны по три самых популярных и не популярных актора)

На основе данных популярности акторов внутри выборки я разделил их на две группы:
Группа А — наиболее популярные 20 пользователей
Группа B — остальные 80 пользователей
И окончательным результатом работы стал график.
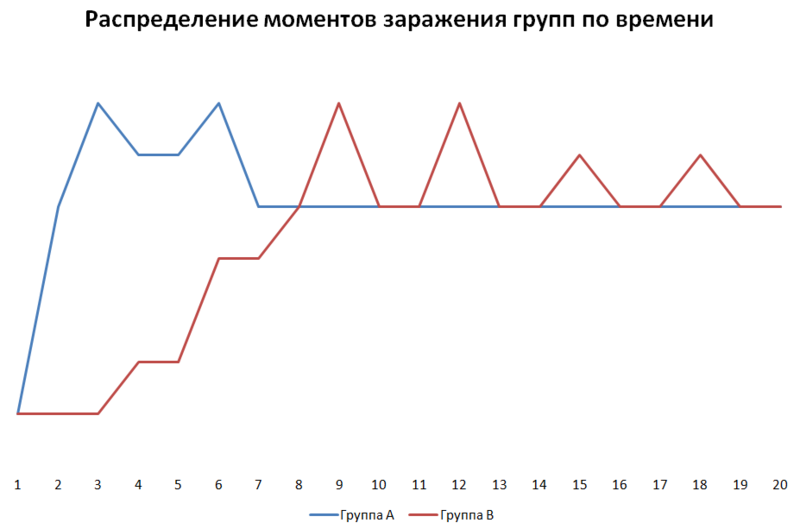
Несмотря на то что данное моё исследование подтвердило первоначальную теорию, ещё раз необходимо напомнить что эксперимент проводился в условиях кустарных, а потому на его результаты полагаться слишком нельзя. Но сам я твёрдо уверовал в возможность предсказания информационных вирусов подобными методами.
Буду благодарен за советы и рекомендации.









