Одной из причин слабого использования Linked Data-баз знаний в обычных, ненаучных приложениях является то, что мы не привыкли придумывать юзкейсы, видя перед собой только данные. Трудно спорить с тем, что сейчас в России производится крайне мало взаимосвязанных данных. Однако это не значит, что разработчик, создающий приложение для русскоязычной аудитории совсем уж отрезан от мира семантического веба: кое-что всё-таки у нас есть.
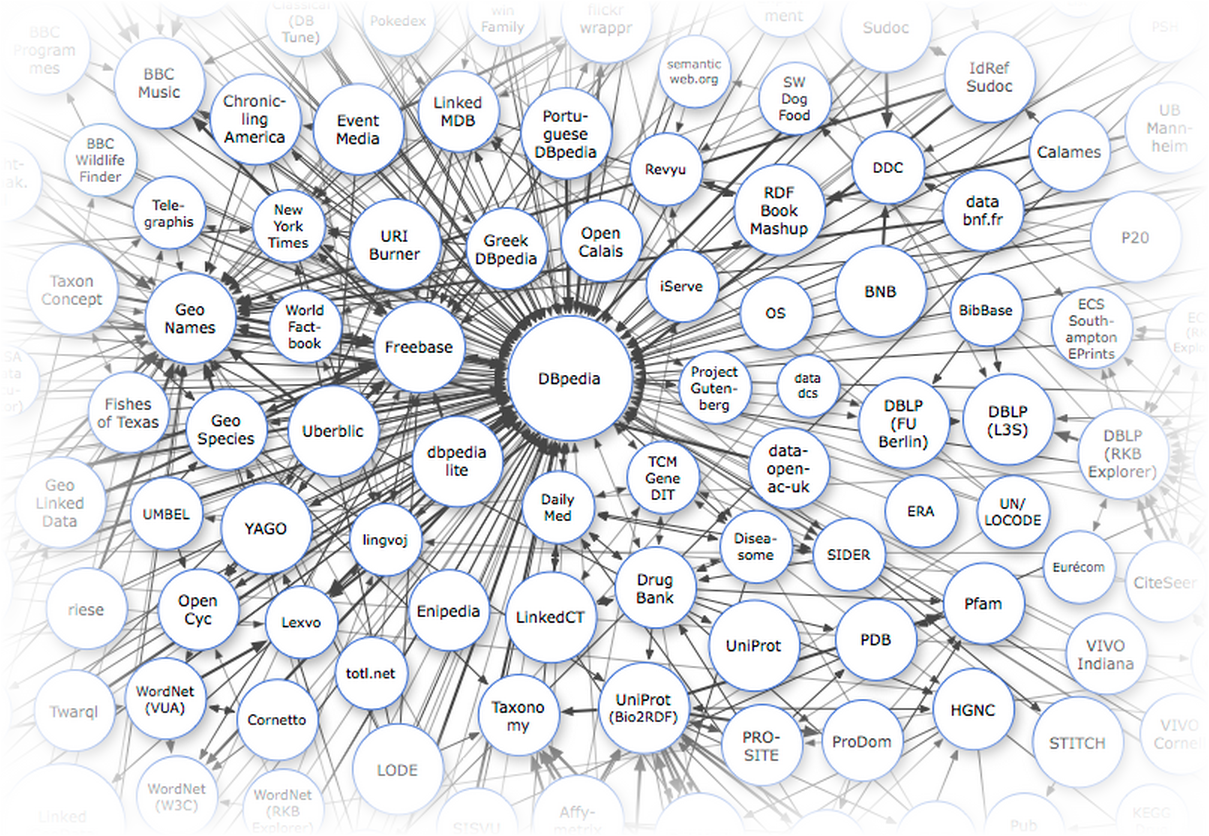
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Эта статья — первая из цикла Базы знаний. Следите за обновлениями.
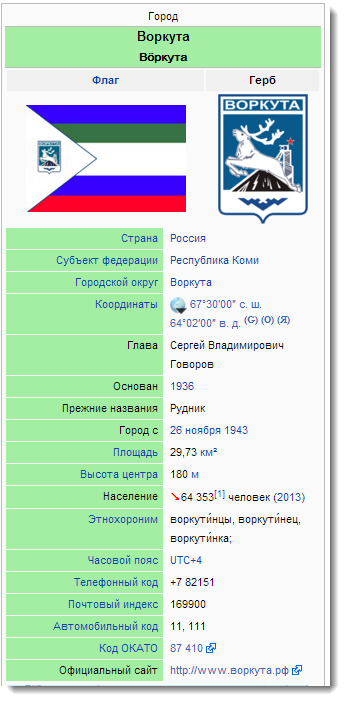 Если вас интересуют города и страны, то в Linked Data вы найдете не только информация об их местоположении (которую, если честно, лучше тащить из других источников), но также:
Если вас интересуют города и страны, то в Linked Data вы найдете не только информация об их местоположении (которую, если честно, лучше тащить из других источников), но также:
Обратите внимание, что когда мы здесь говорим, к примеру, о достопримечательностях, мы не имеем в виду жалкий список названий, упорядоченных по алфавиту. Все данные разбиты на категории, имеют привязку ко времени и месту, именам архитекторов, эпохам, художественным направлениям. Если вы наткнетесь на музей, вы сможете вытащить наиболее важные экспонаты, выставляемые в нем. Само собой, информация о людях-создателях этих экспонатов будет также доступна.
Как и везде в семантической паутине мы будем получать списки объектов, связанных с другими объектами и порой указывающими на альтернативные описания в других базах данных. Мне на ум сразу приходят туристические приложения: пользователю можно предоставить не просто возможность «посмотреть достопримечательности в районе Московского проспекта», но позволить ему отфильтровать только объекты, относящиеся к неоклассицизму первой четверти XX века. А если вы задействуете дерево категорий DBPedia, но можете предложить пользователю еще и связанные стили, например, ранний модерн.
Некоторые географические точки привязаны к событиям — про них тоже можно узнать довольно многое. Так например, довольно просто получить соотношение сил и количество убитых в Куликовской или Бородинской битвах. Разумеется, не забыты и персоналии, с которыми связаны события.
Такого рода даты часто нужны в аналитике. Например для того, чтобы подсчитывать, какой вуз выпускает больше всего олигархов/ученых/писателей, достойных упоминания в Википедии.
Насчет фильмов все выглядит более чем крепко: Freebase, Dbpedia и Linkedmdb располагают очень и очень неплохими массивами данных на тему кинематографии.
ileriseviye.wordpress.com/2012/07/11/is-semantic-web-and-linked-data-good-enough-sparql-dbpedia-vs-python-imdbpy
Мы не только легко можем посмотреть, какой актер где снимался, в каком году вышел фильм и кто его выпустил, но еще и узнать, кто повлиял на актёра, когда он родился, что у него с семейным положением и занимается ли он чем-либо, кроме съемок.
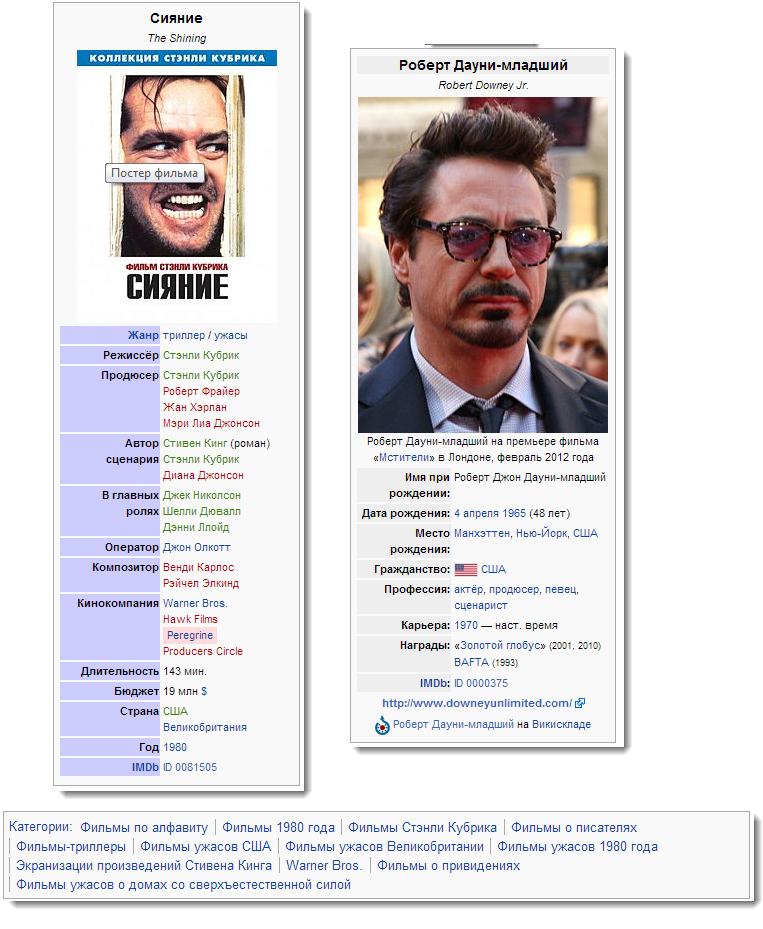
Например, вот этот запрос к Dbpedia выведет всех актеров, которые снимались и в фильме The Shining, и в фильме Hoffa:

Самым замечательным источником данных в области музыки, пожалуй, является MusicBrainz. Конечно же, он есть и в RDF, и конечно же, вы будете использовать традиционные API чтобы получить к ним доступ. Однако Freebase и Dbpedia могут пригодиться и тут — в последней есть, например, информация о гастролях музыкальных групп. Ну и даты рождения, влияние, стили и жанры — энциклопедические данные для музыки тоже присутствуют. Собственно в обучающих материалах Freebase используется как раз музыкальный пример: доставание данных о группе The Police:
Наверное, интересно было бы использовать это в связке с API Last.fm
При описании персоналий в википедиях информационные боксы используются довольно интенсивно — это придаёт статье строгий вид. Поэтому если вы социальный активист и пишете сайт с информацией о политиках — вы найдете в Dbpedia, кто где учился, какие награды имеет и какие должности занимал. Приложения, связанные со спортом могут использовать данные о карьере спортсмена, его рост, вес и важные факты биографии.

Для нужд классификации и кластеризации, а также задач математической лингвистики часто нужны иерархии понятий. Например, что палец является разновидностью части тела. Semantic Web спешит на помощь и позволяет вам не парсить категории википедии, а доставать их готовыми из Dbpedia или www.mpi-inf.mpg.de/yago-naga YAGO. Если же размер иерархии для вас менее важен, чем её качество, вы можете поглядеть на созданные вручную онтологии Dbpedia, Cyc, Umbel.
В конце 2012 года команда Dbpedia запустила проект Wiktionary — доступ к Викисловарю как к базе данных. Сейчас можно делать запросы к английскому, немецкому, французскому, русскому, греческому и вьетнамскому языкам. Давайте попробуем вытащить переводы для какого-нибудь хорошего русского слова через SPARQL-точку Wiktionary:

Среди Semantic Web энтузиастов немало лингвистов, а потому лингвистический мир имеет своё собственное облако взаимосвязанных данных.
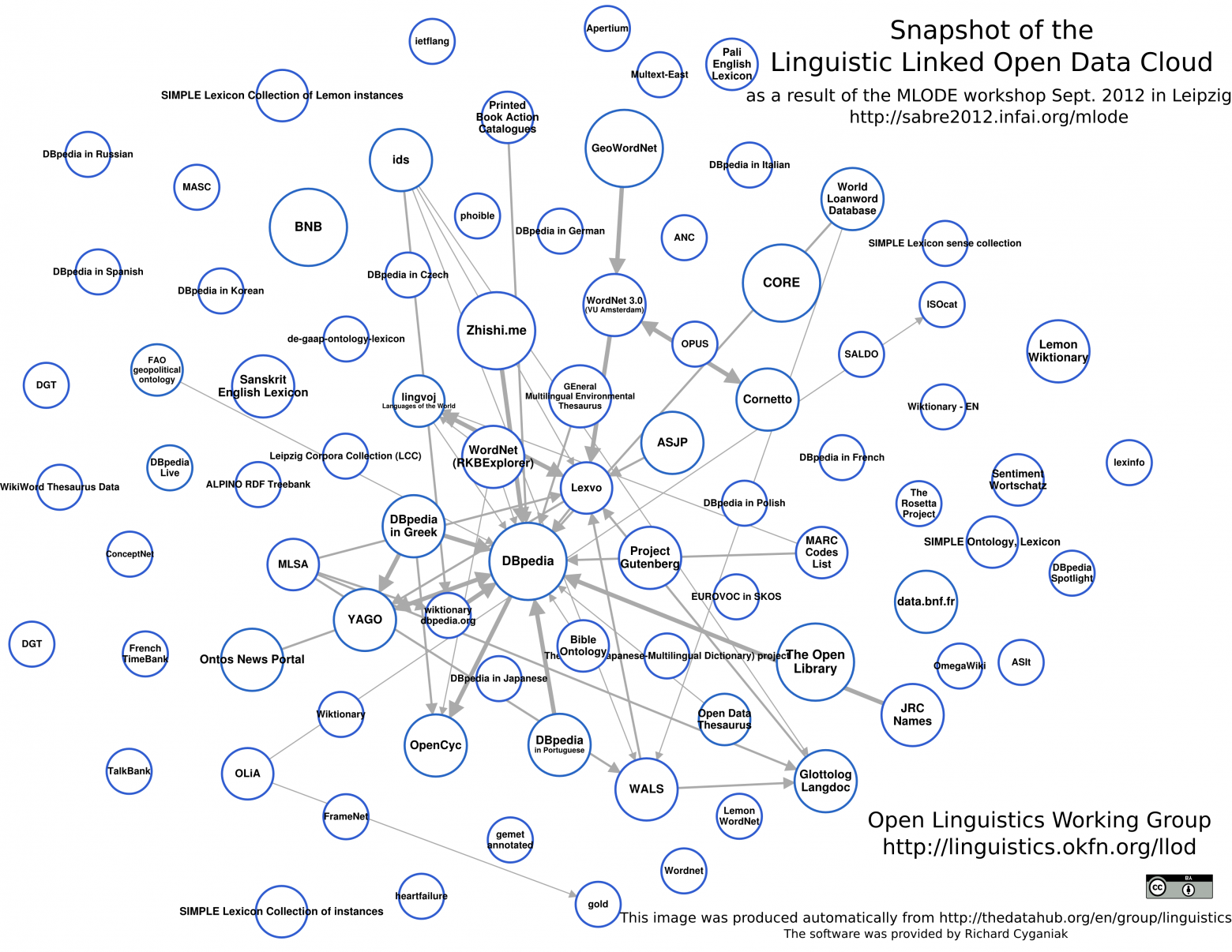
Много полезной информации по Linked и не-Linked данным можно получить c порталов Open Knowledge Foundation и нашего русского NLPub.
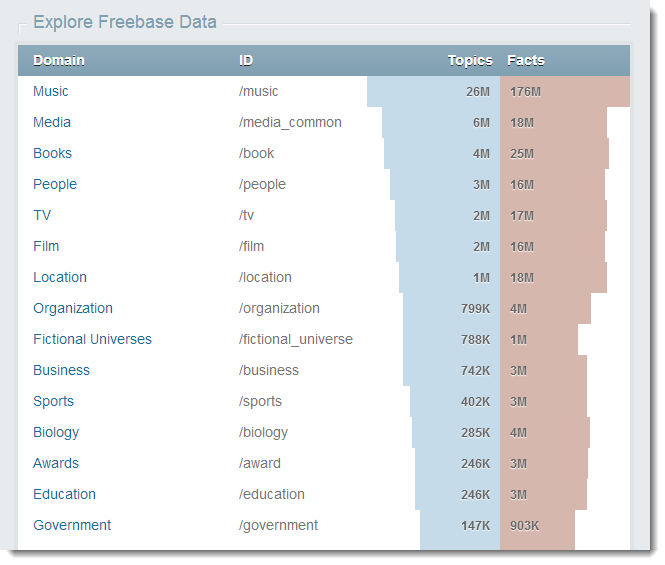
Для Freebase на главной странице есть визуализация того, какие категории содержат наибольшее количество объектов.
Для DBPedia простой способ понять, где скрываются качественные данные тоже есть. Надо обратиться к приложению Mappings.DBpedia и его статистической сводке.
Маппинги — это отличный инструмент, позволяющий пользователям DBpedia влиять на то, как работают парсеры. Я обязательно расскажу про них подробнеев последующих статьях, а пока ограничимся вот этой страницей:
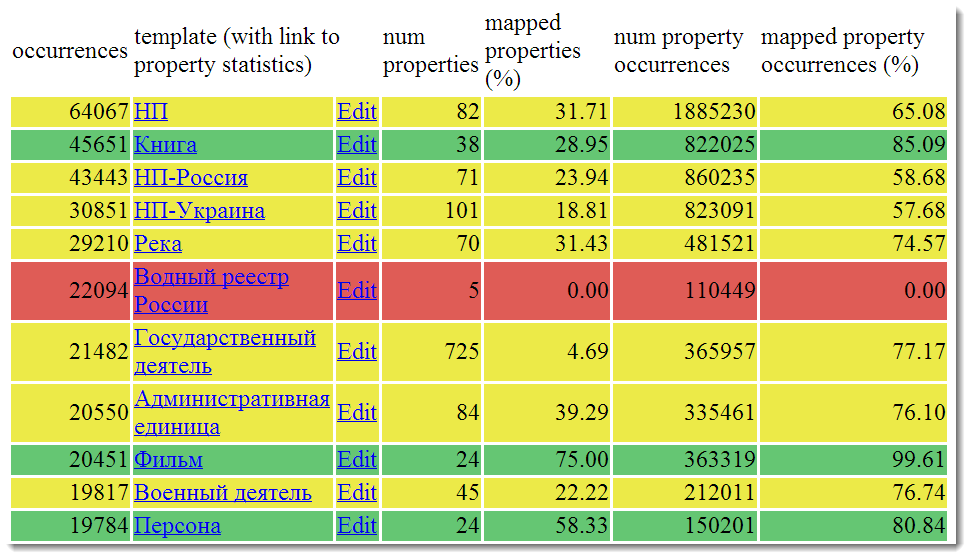
В ячейках написаны названия википедических шаблонов. Более красные ячейки содержат данные, распарсенные полностью автоматически, более зеленые указывают на то, что парсинг производился с участием людей, а потому качество данных должно быть выше.
Ну а что тут сказать, поиск он и есть поиск. Мы используем движки Sig.ma, Sindice и Swoogle. Все они позволяют искать внутри одного датасета или же по всему множеству LInked Data.
В следующий раз я постараюсь описать то, как научиться строить SPARQL-запросы к базе знаний Dbpedia.
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Эта статья — первая из цикла Базы знаний. Следите за обновлениями.
- Часть 1 — Введение
- Часть 2 — Freebase: делаем запросы к Google Knowledge Graph
- Часть 3 — Dbpedia — ядро мира Linked Data
- Часть 4 — Wikidata — семантическая википедия
Городах, страны, исторические данные
Если вас интересуют города и страны, то в Linked Data вы найдете не только информация об их местоположении (которую, если честно, лучше тащить из других источников), но также:- достопримечательности вроде дворцов и памятников
- родившихся и умерших известных людей
- метеостатистику вроде месячного количества осадков и времени восхода солнца
- гербы, флаги
- демографию
- связанные исторические события
Обратите внимание, что когда мы здесь говорим, к примеру, о достопримечательностях, мы не имеем в виду жалкий список названий, упорядоченных по алфавиту. Все данные разбиты на категории, имеют привязку ко времени и месту, именам архитекторов, эпохам, художественным направлениям. Если вы наткнетесь на музей, вы сможете вытащить наиболее важные экспонаты, выставляемые в нем. Само собой, информация о людях-создателях этих экспонатов будет также доступна.
Как и везде в семантической паутине мы будем получать списки объектов, связанных с другими объектами и порой указывающими на альтернативные описания в других базах данных. Мне на ум сразу приходят туристические приложения: пользователю можно предоставить не просто возможность «посмотреть достопримечательности в районе Московского проспекта», но позволить ему отфильтровать только объекты, относящиеся к неоклассицизму первой четверти XX века. А если вы задействуете дерево категорий DBPedia, но можете предложить пользователю еще и связанные стили, например, ранний модерн.
Некоторые географические точки привязаны к событиям — про них тоже можно узнать довольно многое. Так например, довольно просто получить соотношение сил и количество убитых в Куликовской или Бородинской битвах. Разумеется, не забыты и персоналии, с которыми связаны события.
SELECT DISTINCT ?strength, ?result, ?longitute, ?latitude, ?commander WHERE {
dbpedia:Battle_of_Kulikovo dbpprop:strength ?strength;
dbpprop:result ?result;
geo:long ?longitute;
geo:lat ?latitude;
dbpedia-owl:commander ?commander
}
LIMIT 1000
Данные об институтах, организациях, госструктурах
Такого рода даты часто нужны в аналитике. Например для того, чтобы подсчитывать, какой вуз выпускает больше всего олигархов/ученых/писателей, достойных упоминания в Википедии.
- численность персонала/студентов/профессоров, для студентов — количество баков, магистров, иностранных студентов
- годовая выручка
- место в рейтингах
- даты основания
- дочерние и материнские компании
- информация о руководителях
Композиторы, музыканты, фильмы
Насчет фильмов все выглядит более чем крепко: Freebase, Dbpedia и Linkedmdb располагают очень и очень неплохими массивами данных на тему кинематографии.
ileriseviye.wordpress.com/2012/07/11/is-semantic-web-and-linked-data-good-enough-sparql-dbpedia-vs-python-imdbpy
Мы не только легко можем посмотреть, какой актер где снимался, в каком году вышел фильм и кто его выпустил, но еще и узнать, кто повлиял на актёра, когда он родился, что у него с семейным положением и занимается ли он чем-либо, кроме съемок.
Например, вот этот запрос к Dbpedia выведет всех актеров, которые снимались и в фильме The Shining, и в фильме Hoffa:
Самым замечательным источником данных в области музыки, пожалуй, является MusicBrainz. Конечно же, он есть и в RDF, и конечно же, вы будете использовать традиционные API чтобы получить к ним доступ. Однако Freebase и Dbpedia могут пригодиться и тут — в последней есть, например, информация о гастролях музыкальных групп. Ну и даты рождения, влияние, стили и жанры — энциклопедические данные для музыки тоже присутствуют. Собственно в обучающих материалах Freebase используется как раз музыкальный пример: доставание данных о группе The Police:
{
"type" : "/music/album",
"name" : "Synchronicity",
"artist" : "The Police",
"track" : [{
"name":null,
"length":null
}]
}Наверное, интересно было бы использовать это в связке с API Last.fm
Персоналии: политики, спортсмены, исторические фигуры
При описании персоналий в википедиях информационные боксы используются довольно интенсивно — это придаёт статье строгий вид. Поэтому если вы социальный активист и пишете сайт с информацией о политиках — вы найдете в Dbpedia, кто где учился, какие награды имеет и какие должности занимал. Приложения, связанные со спортом могут использовать данные о карьере спортсмена, его рост, вес и важные факты биографии.
Лингвистические приложения. Иерархия категорий
Для нужд классификации и кластеризации, а также задач математической лингвистики часто нужны иерархии понятий. Например, что палец является разновидностью части тела. Semantic Web спешит на помощь и позволяет вам не парсить категории википедии, а доставать их готовыми из Dbpedia или www.mpi-inf.mpg.de/yago-naga YAGO. Если же размер иерархии для вас менее важен, чем её качество, вы можете поглядеть на созданные вручную онтологии Dbpedia, Cyc, Umbel.
Лингвистические приложения. Викисловарь и переводы
В конце 2012 года команда Dbpedia запустила проект Wiktionary — доступ к Викисловарю как к базе данных. Сейчас можно делать запросы к английскому, немецкому, французскому, русскому, греческому и вьетнамскому языкам. Давайте попробуем вытащить переводы для какого-нибудь хорошего русского слова через SPARQL-точку Wiktionary:
Среди Semantic Web энтузиастов немало лингвистов, а потому лингвистический мир имеет своё собственное облако взаимосвязанных данных.
Много полезной информации по Linked и не-Linked данным можно получить c порталов Open Knowledge Foundation и нашего русского NLPub.
Как находить хорошие данные
Для Freebase на главной странице есть визуализация того, какие категории содержат наибольшее количество объектов.
Для DBPedia простой способ понять, где скрываются качественные данные тоже есть. Надо обратиться к приложению Mappings.DBpedia и его статистической сводке.
Маппинги — это отличный инструмент, позволяющий пользователям DBpedia влиять на то, как работают парсеры. Я обязательно расскажу про них подробнеев последующих статьях, а пока ограничимся вот этой страницей:
В ячейках написаны названия википедических шаблонов. Более красные ячейки содержат данные, распарсенные полностью автоматически, более зеленые указывают на то, что парсинг производился с участием людей, а потому качество данных должно быть выше.
Поиск
Ну а что тут сказать, поиск он и есть поиск. Мы используем движки Sig.ma, Sindice и Swoogle. Все они позволяют искать внутри одного датасета или же по всему множеству LInked Data.
В следующий раз я постараюсь описать то, как научиться строить SPARQL-запросы к базе знаний Dbpedia.

