
Привет, Хабр! Мы, Wrike, ежедневно сталкиваемся с потоком данных от сотен тысяч пользователей. Все эти сведения необходимо сохранять, обрабатывать и извлекать из них ценность. Справиться с этим колоссальным объёмом данных нам помогает Apache Spark.
Мы не будем делать введение в Spark или описывать его положительные и отрицательные стороны. Об этом вы можете почитать здесь, здесь или в официальной документации. В данной статье мы делаем упор на библиотеку Spark SQL и её практическое применение для анализа больших данных.
SQL? Мне не показалось?
Исторически сложилось, что отдел аналитики практически любой IT-компании строился на базе специалистов, хорошо владеющих и тонкостями бизнеса, и SQL. Работа BI или аналитического отдела практически никогда не обходится без ETL. Он, в свою очередь, чаще всего работает с источниками данных, к которым проще всего обращаться при помощи SQL.
Wrike не исключение. Долгое время основным источником данных для нас были шарды нашей базы данных в сочетании с ETL и Google Analytics, пока мы не столкнулись с задачей анализа поведения пользователей на основании серверных логов.
Одним из решений подобной проблемы может быть найм программистов, которые будут писать Map-Reduce для Hadoop и обеспечивать данными принятие решений в компании. Зачем это делать, если у нас уже есть целая группа квалифицированных специалистов, хорошо владеющих SQL и разбирающихся в тонкостях бизнеса?Альтернативным решением может быть складирование всего в реляционную БД. В этом случае вашей основной головной болью станет поддержка схемы как ваших таблиц, так и входных логов. Про производительность СУБД с таблицами на несколько сотен миллионов записей, думаем, можно даже не говорить.
Решением для нас стал Spark SQL.
Ok, что дальше?
Основной абстракций Spark SQL, в отличие от Spark RDD, является DataFrame.
DataFrame — это распределённая коллекция данных, организованная в виде именованных колонок. DataFrame концептуально похож на таблицу в базе данных, data frame в R или Python Pandas, но, конечно же, оптимизирован для распределённых вычислений.
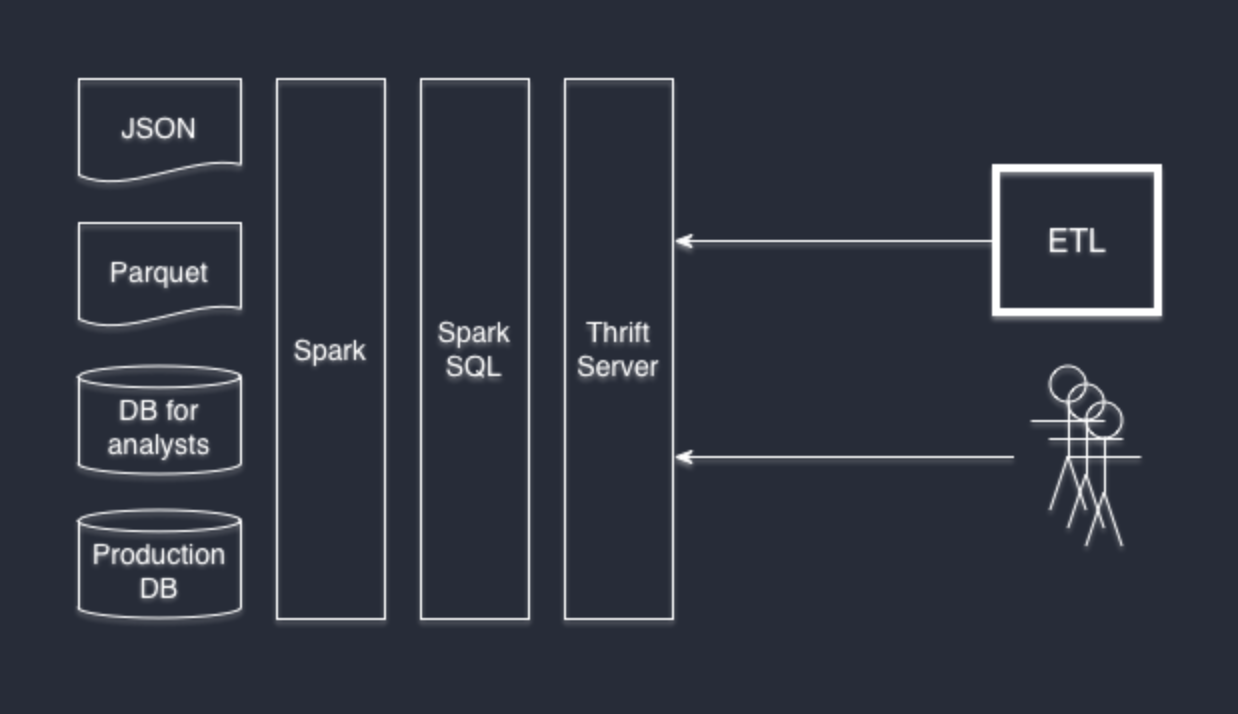
Инициализировать DataFrame можно на базе множества источников данных: структурированных или слабо-структурированных файлов, таких как JSON и Parquet, обычных баз данных посредством JDBC/ODBC и многими другими способами через коннекторы сторонних разработчиков (например Cassandra).
DataFrame API доступны из Scala, Java, Python и R. А с точки зрения SQL обращаться к ним можно как к обычным SQL-таблицам с полной поддержкой всех возможностей диалекта Hive. Spark SQL реализует интерфейс Hive, поэтому вы можете подменить свой Hive на Spark SQL без переписывания системы. Если вы раньше не работали с Hive но хорошо знакомы с SQL, тогда, скорее всего, вам не потребуется изучать что-либо дополнительно.
Я могу подключиться к Spark SQL при помощи %my-favorite-software%?
Если ваше любимое ПО поддерживает использование произвольных JDBC-коннекторов, тогда ответ — да. Нам нравится DBeaver, а нашим разработчикам — IntelliJ IDEA. И они обе прекрасно подключаются к Thrift Server.
Thrift Server является частью стандартной установки Spark SQL, который превращает Spark в поставщика данных. Поднять его очень просто:
./sbin/start-thriftserver.sh
Thrift JDBC/ODBC сервер полностью совместим с HiveServer2 и может прозрачно заменить его собой.
Вот так, например, выглядет окно подключения DBeaver к SparkSQL:

Хочу разные поставщики данных в одном запросе
Легко. Spark SQL частично расширяет диалект Hive таким образом, что вы можете формировать источники данных прямо при помощи SQL.
Давайте создадим «таблицу» на базе логов в json-формате:
CREATE TEMPORARY TABLE table_form_json
USING org.apache.spark.sql.json
OPTIONS (path '/mnt/ssd1/logs/2015/09/*/*-client.json.log.gz')
Обратите внимание, что мы используем не просто один файл, а по маске получаем данные, доступные за месяц.
Проделаем то же самое, но с нашей PostgreSQL базой. В качестве данных возьмём не всю таблицу, а только результат конкретного запроса:
CREATE TEMPORARY TABLE table_from_jdbc
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:postgresql://localhost/mydb?user=[username]&password=[password]&ssl=true",
dbtable "(SELECT * FROM profiles where profile_id = 5) tmp"
)
Теперь совершенно свободно мы можем выполнить запрос с JOIN'м, а Spark SQL Engine сделает всю остальную работу за нас:
SELECT * FROM table_form_json tjson JOIN table_from_jdbc tjdbc ON tjson.userid = tjdbc.user_id;
Комбинировать источники данных возможно в произвольном порядке. У себя во Wrike мы используем PostgreSQL базы, json-логи и parquet-файлы.
Что-нибудь ещё?
Если же вам, как и нам, интересно не только использовать Spark, но и понимать, как он устроен под капотом, мы рекомендуем обратить внимание на следующие публикации:
- Spark SQL: Relational Data Processing in Spark. Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, Matei Zaharia. SIGMOD 2015. June 2015
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award
- Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010
