
В нашем блоге мы много пишем о создании email-рассылок и работе с электронной почтой. В современном мире люди получают множество писем, и в полный рост встает проблема с их классификацией и упорядочиванием почтового ящика. Инженер из США Андрей Куренков в своем блоге рассказал о том, как решил эту задачу с помощью нейронной сети. Мы решили осветить ход этого проекта — несколько дней назад опубликовали первую часть рассказа, а сегодня представляем вашему вниманию его продолжение.
Глубинное обучение здесь не подходит
Когда Куренков впервые начал изучать код Keras, то полагал (ошибочно), что он будет использовать последовательность, отражающую фактический порядок слов в текстах. Выяснилось, что это не так, но это не значит, что такой вариант невозможен. Что в сфере машинного обучения действительно стоит отметить – так это рекуррентные нейронные сети, которые отлично подходят для работы с большими последовательностями данных, пишет автор. Этот подход подразумевает, что при работе со словами выполняется «подготовительный» шаг, на котором каждое слово конвертируется в числовой вектор так, что похожие слова переходят в похожие векторы.
Благодаря этому вместо преобразования писем в матрицы бинарных признаков можно просто заменить слова на числа, используя частоты их появления в письмах, а сами числа – на векторы, отражающие «смысл» каждого слова. Тогда появляется возможность использования полученной последовательности для обучения рекуррентной нейронной сети типа Long Short Term Memory или Gated Recurrent. И этот подход уже реализован: можно просто запустить пример и посмотреть, что будет:
Epoch 1/15 7264/7264 [===========================] - 1330s - loss: 2.3454 - acc: 0.2411 - val_loss: 2.0348 - val_acc: 0.3594 Epoch 2/15 7264/7264 [===========================] - 1333s - loss: 1.9242 - acc: 0.4062 - val_loss: 1.5605 - val_acc: 0.5502 Epoch 3/15 7264/7264 [===========================] - 1337s - loss: 1.3903 - acc: 0.6039 - val_loss: 1.1995 - val_acc: 0.6568 ... Epoch 14/15 7264/7264 [===========================] - 1350s - loss: 0.3547 - acc: 0.9031 - val_loss: 0.8497 - val_acc: 0.7980 Epoch 15/15 7264/7264 [===========================] - 1352s - loss: 0.3190 - acc: 0.9126 - val_loss: 0.8617 - val_acc: 0.7869 Test score: 0.861739277323
Точность: 0.786864931846
Обучение заняло вечность, при этом результат оказался далеко не так хорош. Предположительно, причиной может быть то, что данных было немного, и последовательности в целом недостаточно эффективны для их категоризации. Значит, повышенная сложность обучения на последовательностях не окупается преимуществом обработки слов текста в правильном порядке (все-таки отправитель и определённые слова в письме хорошо показывают, к какой категории оно принадлежит).
Но дополнительный «подготовительный» шаг всё ещё казался инженеру полезным, поскольку создаёт более широкое представление слова. Поэтому он посчитал стоящим попробовать использовать его, подключив свертку для поиска важных локальных признаков. И опять нашелся пример Keras, который выполняет подготовительный шаг и при этом передаёт полученные векторы слоям свертки и субдискретизации вместо слоёв LSTM. Но результаты вновь не впечатляют:
Epoch 1/3 5849/5849 [===========================] - 127s - loss: 1.3299 - acc: 0.5403 - val_loss: 0.8268 - val_acc: 0.7492 Epoch 2/3 5849/5849 [===========================] - 127s - loss: 0.4977 - acc: 0.8470 - val_loss: 0.6076 - val_acc: 0.8415 Epoch 3/3 5849/5849 [===========================] - 127s - loss: 0.1520 - acc: 0.9571 - val_loss: 0.6473 - val_acc: 0.8554 Test score: 0.556200767488
Точность: 0.858725761773
Инженер действительно надеялся, что обучение с использованием последовательностей и подготовительных шагов покажет себя лучше модели N-грамм, поскольку теоретически последовательности содержат больше информации о самих письмах. Но распространенное мнение о том, что глубинное обучение не очень эффективно для небольших наборов данных, оказалось справедливым.
Всё из-за признаков, дурень
Итак, проведенные тесты не дали желанной точности в 90%… Как видно, текущий подход определения признаков по 2500 наиболее часто встречающихся слов не годится, так как он включает такие общие слова как «я» или «что» наряду с полезными специфичными для категорий словами типа «домашка». Но рискованно просто убирать популярные слова или забраковать какие-то наборы слов – никогда не знаешь, что окажется полезным для определения признаков, поскольку, возможно, иногда я использую то или иное «простое» слово в одной из категорий чаще, чем в других (например, в разделе «Личное»).
Здесь следует перейти от гадания к использованию метода отбора признаков для выбора слов, которые действительно хороши, и фильтровать слова, не работающие. Для этого легче всего использовать scikit и его класс SelectKBest, который настолько быстр, что отбор занимает минимум времени по сравнению с работой нейронной сети. Итак, поможет ли это?
Зависимость тестовой точности от количества обрабатываемых слов:
Работает – 90%!
Отлично! Несмотря на небольшие различия в итоговой результативности, начинать явно лучше с большего набора слов. Однако этот набор можно довольно сильно уменьшить с помощью отбора признаков и не потерять производительности. По всей видимости, у этой нейронной сети нет проблем с переобучением. Рассмотрение «лучших и худших» слов по версии программы подтверждает, что она достаточно хорошо определяет их:
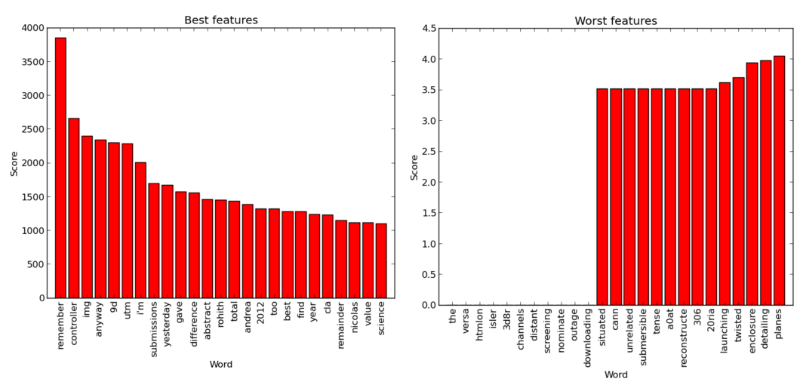
«Лучшие» и «худшие» слова: отбор признаков с использованием критерия хи-квадрат (основано на коде из примера scikit)
Многие «хорошие» слова, как и следовало ожидать, – имена или специфические термины (например, «controller»), хотя Куренков говорит, что некоторые слова типа «remember» или «total» сам бы не выбрал. «Худшие» слова, с другой стороны, довольно предсказуемы, так как они или слишком общие, или слишком редкие.
Можно подвести итог: чем больше слов, тем лучше, и отбор признаков может помочь сделать работу быстрее. Он помогает, но, возможно, есть способ дополнительно повысить результаты тестов. Чтобы узнать это, инженер решил взглянуть на то, какие ошибки делает нейронная сеть, с помощью матрицы ошибок, также взятой с scikit learn:
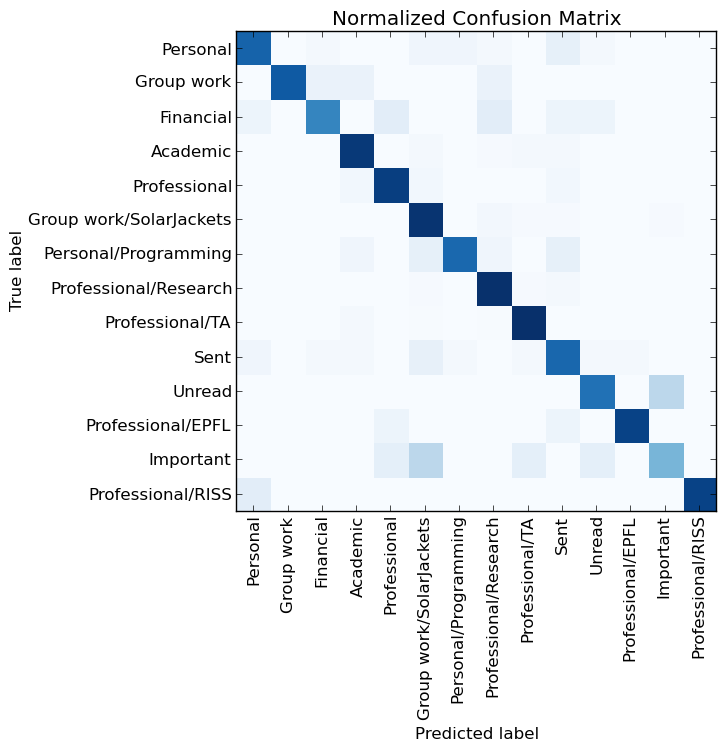
Матрица ошибок для результатов работы нейронной сети
Отлично, большинство цветных блоков расположено по диагонали, однако есть ещё несколько других «раздражающих пятен». В частности, на визуализации категории «Непрочитанное» и «Важное» обозначены как проблемные. Но подождите! Я не создавал эти категории, и мне все равно, насколько хорошо система обрабатывает как их, так и категорию «Отправленные». Несомненно, я должен убрать их и посмотреть, насколько хорошо нейронная сеть работает именно с созданными мною категориями.
Поэтому, давайте проведем последний эксперимент, в котором все неподходящие категории отсутствуют, и где будет использоваться наибольшее количество признаков – 10 000 слов с отбором 4 000 лучших:
Epoch 1/5 5850/5850 [==============================] - 2s - loss: 0.8013 - acc: 0.7879 - val_loss: 0.2976 - val_acc: 0.9369 Epoch 2/5 5850/5850 [==============================] - 1s - loss: 0.1953 - acc: 0.9557 - val_loss: 0.2322 - val_acc: 0.9508 Epoch 3/5 5850/5850 [==============================] - 1s - loss: 0.0988 - acc: 0.9795 - val_loss: 0.2418 - val_acc: 0.9338 Epoch 4/5 5850/5850 [==============================] - 1s - loss: 0.0609 - acc: 0.9865 - val_loss: 0.2275 - val_acc: 0.9462 Epoch 5/5 5850/5850 [==============================] - 1s - loss: 0.0406 - acc: 0.9925 - val_loss: 0.2326 - val_acc: 0.9462 722/722 [==============================] - 0s Test score: 0.243211859068
Точность: 0.940443213296
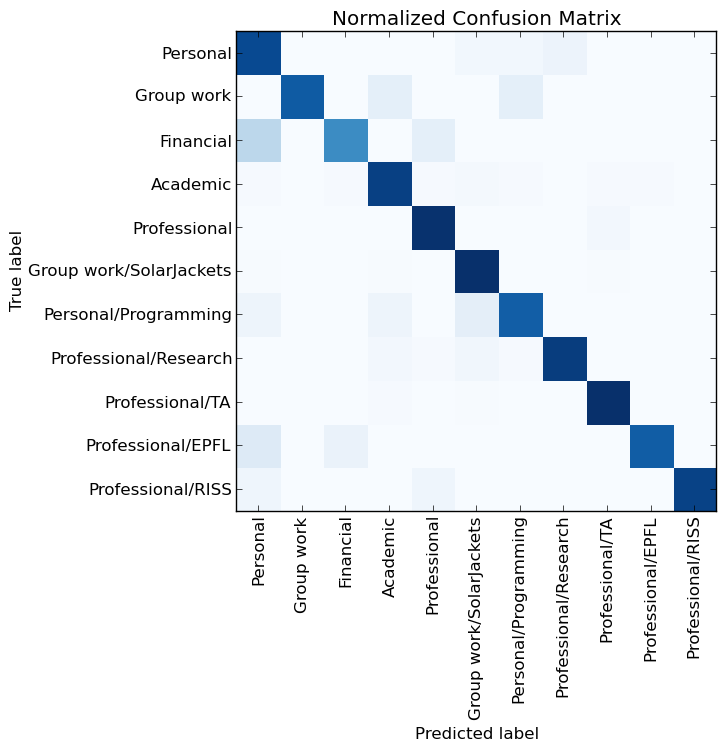
Матрица ошибок для новых результатов нейронной сети
Вот так-то! Нейронная сеть может угадывать категории с 94% точности. Хотя эффект обусловлен прежде всего большим набором признаков, хороший классификатор (классификатор scikit learn Passive Agressive) и сам по себе даёт 91% точности на тех же входных данных. На самом деле, существуют идеи о том, что, в данном случае эффективным может оказаться и метод опорных векторов (LinearSVC), – используя его, можно также получить приблизительно 94% точности.
Итак, вывод довольно простой – «модные» методы машинного обучения не особенно эффективны на небольших наборах данных, а старые подходы типа N-грамм + TF-IFD + SVM могут сработать так же хорошо, как и современные нейронные сети. Говоря короче, одно только использование метода Bag of Words сработает достаточно хорошо при условии, что писем немного и они отсортированы так же чётко, как и в примере выше.
Возможно, немногие используют категории в gmail, но если создать хороший классификатор действительно настолько просто, то было бы неплохо, чтобы в gmail была машинно-обучаемая система, определяющая категорию каждого письма для организации почты в один клик. На этом этапе Куренков был очень доволен тем, что улучшил собственные результаты на 20% и познакомился с Keras в процессе работы.
Эпилог: Дополнительные эксперименты
Работая над своим экспериментом, инженер сделал еще кое-что. Он столкнулся с проблемой: все вычисления выполнялись долго, по большей части потому, что автор материала не использовал теперь уже обыденный трюк с запуском машинного обучения с использованием GPU. Следуя превосходному руководству, он сделал это, и получил отличные результаты:
Время, затраченное на достижение описанных выше 90% с графическим процессором и без него; отличное ускорение!
Следует отметить, что нейронную сеть Keras, демонстрирующую 94% точности, было намного быстрее обучить (и работать с ней), нежели сеть, обучающуюся на основе метода опорных векторов; первая оказалась наилучшим решением из всех, что я опробовал.
Инженер хотел визуализировать что-то ещё помимо матриц ошибочности. В этом отношении с Keras мало чего удалось добиться, хотя и автор и наткнулся на обсуждение вопросов визуализации. Это привело меня к форку Keras с неплохим вариантом отображения процесса обучения. Он не очень эффективный, но любопытный. После небольшого его изменения, он сгенерировал отличные графики обучения:
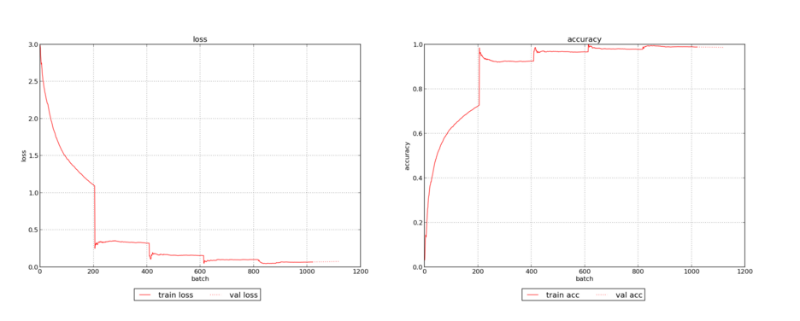
Прогресс обучения нейронной сети на слегка измененном примере (с большим количеством обрабатываемых слов)
Здесь наглядно показано, как точность обучения стремится к единице и выравнивается.
Неплохо, но инженера больше волновало увеличение точности. Как и ранее, первым делом он задался вопросом: «Можно ли быстро поменять формат представления признаков, чтобы помочь нейронной сети?» Модуль Keras, превращающий текст в матрицы, имеет несколько вариантов помимо создания двоичных матриц: матрицы со счётчиками слов, частотами или значениями TF-IDF.
Изменять количество слов, хранимых в матрицах в виде признаков, также оказалось несложно, так что Куренков написал несколько циклов, оценивающих, как влияет тип признаков и количество слов на точность тестов. Получился интересный график:
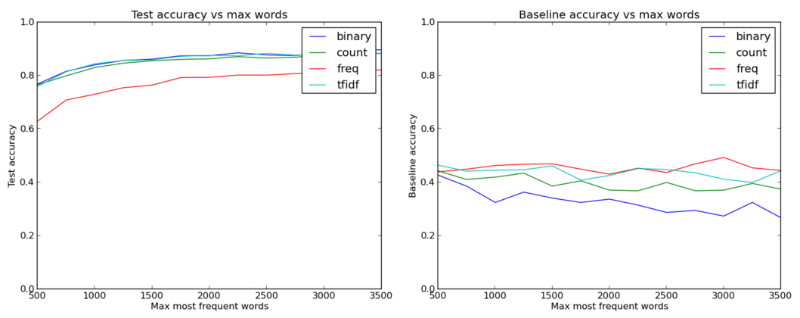
Точность теста в зависимости от типа признаков и того, сколько слов взято в качестве признаков (базовая точность учитывает k ближайших «соседей»)
Здесь впервые стало понятно, что нужно увеличить количество слов до значения, превышающего 1 000. Также было интересно увидеть, что тип признаков, отличающийся простотой и наименьшей информационной плотностью (бинарный), оказался не хуже и даже лучше других типов, передающих больше информации о данных.
Хотя это довольно предсказуемо – скорее всего, более интересные слова типа «code» или «grade» полезны для категоризации писем, и единичное их появление в письме так же важно, как и большее число упоминаний. Без сомнения, наличие информативных признаков может быть полезно, но может и понизить результаты теста из-за увеличения вероятности переобучения.
В общем, мы видим, что бинарные признаки показали себя лучше других и что увеличение количества слов отлично помогает достижению 87%-88% точности.
Инзенер также просмотрел базовые алгоритмы, чтобы убедиться, что что-то вроде метода k ближайших соседей (scikit) не является (по эффективности) эквивалентом нейронных сетей – это оказалось правдой. Линейная регрессия сработала даже хуже, так что выбор нейронных сетей вполне обоснован.
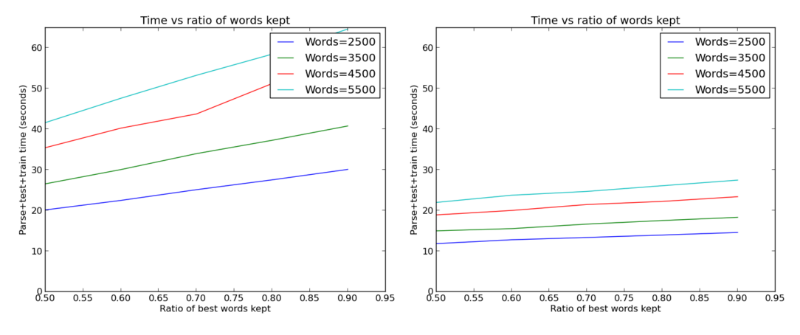
Увеличение количества слов, кстати, не проходит даром. Даже с кэшированной версией данных, когда не надо было каждый раз парсить почту и извлекать признаки, запуск всех этих тестов занимал массу времени:
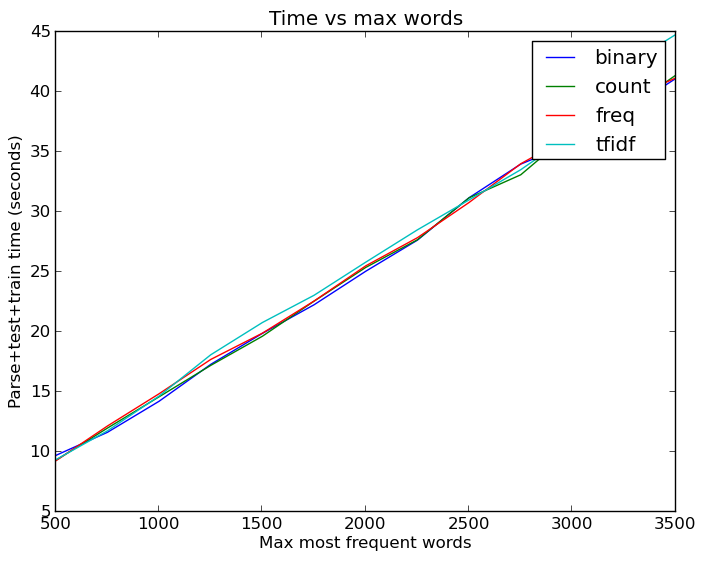
Линейная зависимость роста времени от количества слов. На самом деле неплохо, с линейной регрессией было намного хуже
Увеличение количества слов помогло, но экспериментатор всё ещё не мог достичь желанного порога в 90%. Поэтому следующей мыслью было придерживаться 2 500 слов и попробовать изменить размер нейронной сети. Кроме того, как оказалось, модель из примера Keras имеет 50%-ную dropout-регуляризацию на скрытом слое: инженеру стало интересно посмотреть, действительно ли это увеличивает эффективность работы сети. Он запустил ещё один набор циклов и получил ещё один прекрасный график:
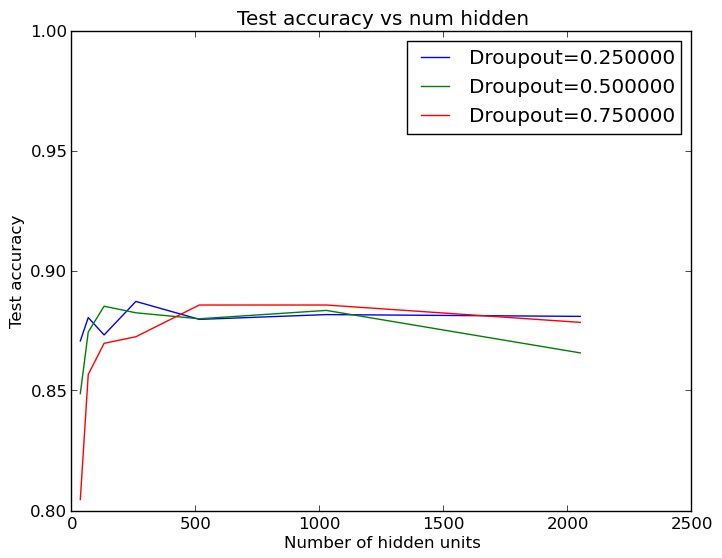
График изменения точности для различных вариантов dropout-регуляризации и размеров скрытого слоя
Оказывается, размер скрытого слоя необязательно должен быть достаточно велик, чтобы все работало как надо! 64 или 124 нейрона в скрытом слое могут выполнить задачу так же хорошо, как и стандартные 512. Эти результаты, кстати, усреднены по пяти запускам, так что небольшой разброс в выходных данных не связан с возможностями небольших скрытых слоев.
Из этого следует, что большое количество слов нужно лишь для определения полезных признаков, но самих полезных признаков не так уж и много – иначе для лучшего результата требовалось бы больше нейронов. Это хорошо, поскольку мы можем сэкономить немало времени, используя меньшие скрытые слои:
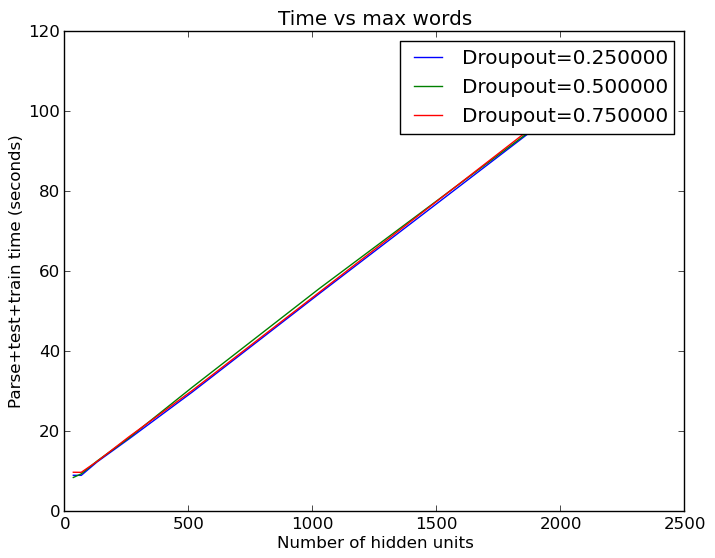
И вновь время вычислений растет линейно при увеличении нейронов скрытого слоя
Но это не совсем точно. Проведя больше запусков с большим количеством признаков, инженер обнаружил, что стандартный размер скрытого слоя (512 нейронов) работает значительно лучше, чем более маленькие скрытые слои:
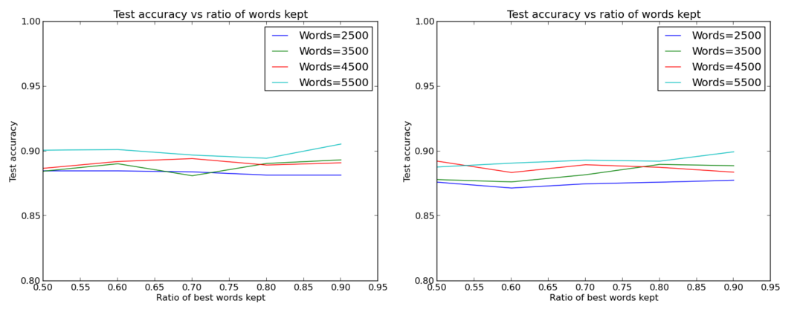
Сравнение эффективности работы слоев с 512 и 32 нейронами соответственно
Остается лишь констатировать то, что и так было известно: чем больше слов, тем лучше.
