 В данной статье я хочу продолжить тему сравнения баз данных, которые можно использовать для построения хранилища данных (DWH) и аналитики. Ранее я описал результаты тестов для Oracle In-Memory Option и In-Memory RDBMS Exasol. В данной же статье основное внимание будет уделено СУБД Vertica. Для всех описанных тестов использовались tpc-h benchmark на небольшом объёме исходных данных (2 Гб) и конфигурация БД на одном узле. Эти ограничения позволили мне многократно повторить бенчмарк в разных вариациях и с различными настройками. Для выбора аналитической СУБД под конкретный проект призываю читателей проводить испытания на своих кейсах (данные, запросы, оборудование и другие особенности).
В данной статье я хочу продолжить тему сравнения баз данных, которые можно использовать для построения хранилища данных (DWH) и аналитики. Ранее я описал результаты тестов для Oracle In-Memory Option и In-Memory RDBMS Exasol. В данной же статье основное внимание будет уделено СУБД Vertica. Для всех описанных тестов использовались tpc-h benchmark на небольшом объёме исходных данных (2 Гб) и конфигурация БД на одном узле. Эти ограничения позволили мне многократно повторить бенчмарк в разных вариациях и с различными настройками. Для выбора аналитической СУБД под конкретный проект призываю читателей проводить испытания на своих кейсах (данные, запросы, оборудование и другие особенности).Краткая информация о СУБД Vertica
Vertica — это реляционная аналитическая column-oriented MPP база данных. На Хабре достаточно статей с описанием основных возможностей этой СУБД (в конце статьи приведены ссылки на некоторые их них), поэтому я не буду их описывать и упомяну только несколько интересных, на мой взгляд, фактов о Vertica:
- Facebook использует Vertica для своих внутренних аналитических задач. 2 года назад там был кластер из сотен серверов и десятки петабайт данных… Я не нашёл актуальной информации об этом проекте, может кто-то поделится достоверной ссылкой в комментариях.
- Vertica была разработана командой под руководством Майкла Стоунбрейкера (изначально называлась C-Store). Написана была с нуля специально для аналитических задач с учётом большого предшествующего опыта Майкла (Ingres, Postgres, Informix и другие СУБД). Для сравнения подходов можно вспомнить конкурента Vertica – Greenplum (сейчас принадлежит компании Dell), это MPP СУБД, которая базируется на доработанной БД PostgreSQL.
- В 2016 году Hewlett-Packard Enterprise (HPE) продала свой софтверный бизнес вместе с Vertica компании Micro Focus. Как это отразится на развитии Vertica пока не понятно, но я очень надеюсь, что данная сделка не погубит отличный продукт.
- В контексте сравнения с Exasol важно отметить, что Vertica не является in-memory базой данных и более того, в Vertica нет буферного пула. То есть БД предназначена в первую очередь для обработки объёмов данных, которые значительно превосходят размер оперативной памяти, а на отказе от поддержки буферного КЭШа можно сэкономить существенную часть ресурсов сервера. В то же время, Vertica эффективно использует возможности файловой системы и в частности кэширование.
TPC-H Benchmark
Для тех, кто не читал предыдущие мои 2 статьи, кратко опишу tpc-h benchmark. Он предназначен для сравнения производительности аналитических систем и хранилищ данных. Этот бенчмарк используют многие производители как СУБД, так и серверного оборудования. На странице tpс-h доступно много результатов, для публикации которых необходимо выполнить все требования спецификации на 136 страницах. Я публиковать официально свои тесты не собирался, поэтому всем правилам строго не следовал. Отмечу, что в рейтинге нет ни одного теста СУБД Vertica.
TPC-H позволяет сгенерировать данные для 8-ми таблиц с использованием заданного параметра scale factor, который определяет примерный объём данных в гигабайтах. Для всех тестов, результаты которых публикую, я ограничился 2 Гб.

Бенчмарк включает 22 SQL запроса различной сложности. Отмечу, что сгенерированные утилитой qgen запросы, нужно корректировать под особенности конкретной СУБД, но как и Exasol, Vertica поддерживает стандард ANSI SQL-99 и все запросы для этих 2-х СУБД были абсолютно идентичны. Для теста было сгенерировано 2 вида нагрузки:
- 8 виртуальных пользователей параллельно 3 раза по кругу выполняют все 22 запроса
- 2 виртуальных пользователя параллельно 12 раз по кругу выполняют все 22 запроса
В итоге в обоих случаях оценивалось время выполнения 528-ми SQL запросов.
Тестовая площадка
Ноутбук со следующими характеристиками:
Intel Core i5-4210 CPU 1.70GHz – 4 virt. processors; DDR3 16 Gb; SSD Disk.
ОС:
MS Windows 8.1 x64
VMware Workstation 12 Player
Virtual OS: Ubuntu 14.04.4 x64 (Memory: 8 Gb; Processors: 4)
СУБД:
Vertica Analytic Database v7.2.2-1 (single node)
Физическая модель данных в Vertica
Объём занимаемого дискового пространства и производительность запросов в Vertica сильно зависит от порядка сортировки и алгоритма сжатия столбцов проекций. Исходя из этого, свои тесты я выполнял в несколько этапов. На первом этапе были созданы только super projections таким способом:
CREATE TABLE ORDERS ( O_ORDERKEY INT NOT NULL,
O_CUSTKEY INT NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE NUMERIC(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INT NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL)
PARTITION BY (date_part('year', ORDERS.O_ORDERDATE));
Две самые объёмные таблицы ORDERS и LINEITEM были партиционированы по годам. Так как бенчмарк проводился на 1 узле, сегментирования (шардинга) не было. На последующих этапах физическая структура оптимизировалась с помощью Database Designer, об этом ниже.
Загрузка данных в Vertica
Для загрузки данных из текстового файла я использовал следующий скрипт:
COPY tpch.lineitem FROM LOCAL 'D:\lineitem.tbl' exceptions 'D:\l_error.log';
Время загрузки всех файлов составило 5 мин. 21 сек. (в Exasol 3 мин. 37 сек.). Таким способом данные изначально загружаются построчно в оперативную память в WOS контейнеры (параметры wosdata pool по умолчанию: maxmemorysize = 25%), затем автоматически на диск поколоночно в ROS контейнеры. Также я протестировал загрузку из файлов и из Oracle c использованием ETL инструмента Pentaho DI (aka Kettle), получается существенно медленнее даже со специальным плагином для Vertica.
Результаты выполнения теста
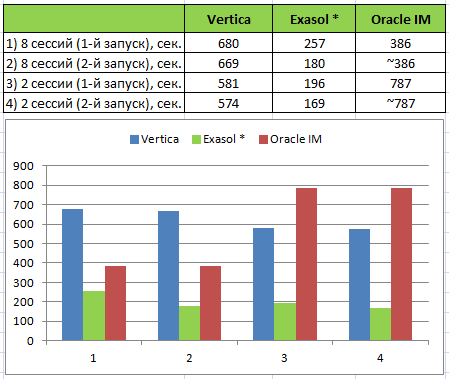
* В предыдущем тесте выполнение запросов в Exasol заняло значительно меньше времени за счёт кэширования результатов (часть запросов в тесте не меняются, для части генерируются значения параметров). В Vertica такого кэширования нет и для уравнивания шансов, я отключил его и в Exasol:
alter session set QUERY_CACHE = 'OFF';Последовательность тестирования в Vertica
Этап 1. 1-й запуск
Первый запуск теста выполнялся после загрузки данных в super projections без сбора статистики. Время выполнения составило 581 секунду для 2-х сессий и 680 секунд для 8-ми сессий. При повторном выполнении время сократилось минимально (см. в таблице выше).
Далее в таблице представлена информация о том, как данные были организованы в Exasol и Vertica после первоначальной загрузки:
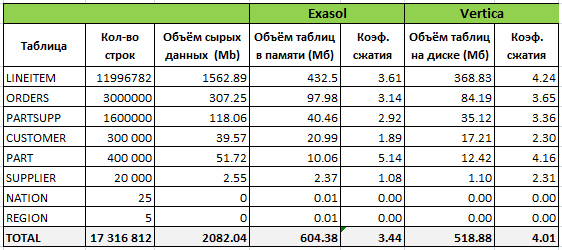
Запрос для получения информации по занимаемому объёму на диске и в памяти в Vertica:
SELECT
ANCHOR_TABLE_NAME,
PROJECTION_NAME,
USED_BYTES/1024/1024 as USED_Mb,
ROS_USED_BYTES/1024/1024 as ROS_Mb,
WOS_USED_BYTES/1024/1024 as WOS_Mb
FROM PROJECTION_STORAGE
WHERE ANCHOR_TABLE_SCHEMA='tpch'
order by 1,3 desc;
Из таблицы видно, что Vertica немного лучше сжала данные, несмотря на то, что проекции были созданы не оптимальным способом. В процессе тестирования я также пробовал оптимизировать структуру с помощью DB Designer на основании загруженных данных и без учёта запросов. Коэффициент сжатия получился равным 6.
Этап 2. Сбор статистики
После сбора статистики по таблицам время выполнения неожиданно увеличилось примерно на 30%. Анализ статистики и планов выполнения запросов показал, что для большинства запросов время выполнения незначительно уменьшилось или не поменялось, но для пары запросов существенно увеличилось. В этих запросах соединялось множество таблиц, включая ORDERS и LINEITEM, и меньшая стоимость (cost) соответствовала более длительному времени выполнения.
Этап 3. Оптимизация структуры с помощью DB Designer
Был создан Comprehensive design с опцией Query perfomance (larger footprint) на основании 21-го запроса бенчмарка tpc-h (1 пропущен, т.к. для него view создаётся перед выполнением). В результате получились следующие цифры:
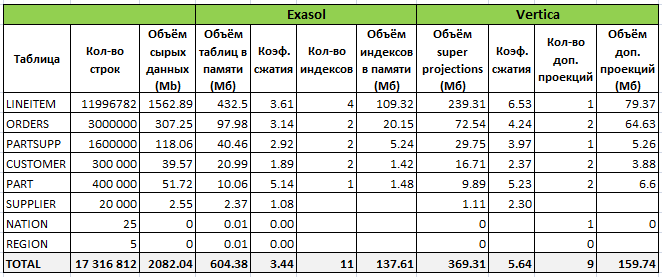
Таким образом, было создано 9 дополнительных проекций, но общий объём данных на диске почти не поменялся за счёт оптимизации структуры (порядка следования колонок и различных алгоритмов их сжатия). Однако новая структура ещё больше замедлила проблемные запросы и соответственно общее время выполнения.
Этап 4. Ручная оптимизация
Учитывая свой предыдущий опыт работы с Vertica на других моделях данных (преимущественно star schema), я ожидал от БД лучших результатов, поэтому решил глубже поискать узкие места. Для этого были выполнены следующие действия:
- Анализ статистики и планов выполнения запросов — системные таблицы v_monitor: query_requests, query_plan_profiles, execution_engine_profiles, query_events;
- Анализ рекомендаций БД по результату выполнения функции ANALYZE_WORKLOAD();
- Создание нескольких дополнительных проекций;
- Изменение параметров для general пула.
Всё это значимых результатов не принесло.
Далее был переписан проблемный запрос, который занимал около 30% времени выполнения всех запросов:
Исходный код запроса:
select
nation,
o_year,
sum(amount) as sum_profit
from
(
select
n_name as nation,
extract(year from o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity as amount
from
part,
supplier,
lineitem,
partsupp,
orders,
nation
where
s_suppkey = l_suppkey
and ps_suppkey = l_suppkey
and ps_partkey = l_partkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and s_nationkey = n_nationkey
and p_name like '%thistle%'
) as profit
group by
nation,
o_year
order by
nation,
o_year desc;
Переписанный код запроса с использование подсказки оптимизатору:
select
/*+SYNTACTIC_JOIN */
n_name as nation,
extract(year from o_orderdate) as o_year,
sum(l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity) as amount
from lineitem
join orders on o_orderkey = l_orderkey
join partsupp on ps_suppkey = l_suppkey and ps_partkey = l_partkey
join part on p_partkey = l_partkey and p_name like '%thistle%'
join supplier on s_suppkey = l_suppkey
join nation on s_nationkey = n_nationkey
group by
n_name,
extract(year from o_orderdate)
order by 1, 2 desc;
В результате запрос ускорился примерно в 4 раза.
В итоге, минимальное время выполнения теста в 2 сессии со структурой созданной DB Designer и корректировкой 1 запроса составило 531 секунду (самый первый запуск без оптимизаций длился 581 сек.).
На этом я остановился, так как не было цели выжать максимум путём переписывания запросов, изменения модели и других не совсем «честных» способов.
Выводы
Данный тест в очередной раз подтверждает правило, что всегда необходимо выбирать инструменты и варианты реализации, которые будут оптимальны для вашей конкретной задачи/проекта. Бенчмарк tpc-h с моими заданными ограничениями является «неудобным» для СУБД Vertica по следующим причинам:
- Все данные помещались в оперативную память, а Vertica не является in-memory DB;
- Нормализованная модель tpc-h и ошибки оптимизатора. Когда приоритетным требованием является производительность ad-hoc запросов, для презентационного слоя хранилища в Vertica лучше подходит денормализованная модель (например, star schema). A БД Exasol отлично справляется и с нормализованной моделью, в чём, на мой взгляд, её большое преимущество, так как можно сократить количество слоёв DWH.
Vertica не перегружена лишним функционалом и относительно проста для разработки и администрирования, но Exasol в этом плане ещё проще и почти всё делает за вас. Что лучше гибкость или простота, зависит от конкретной задачи.
Стоимости лицензий Vertica и Exasol сопоставимы, а также доступны бесплатные версии с ограничениями. В процессе выбора аналитической СУБД я бы рекомендовал рассматривать оба продукта.
Полезные ссылки о Vertica
- Обзор архитектуры и основных возможностей;
- Больше всех делится практическим опытом на русском языке, наверное, Алексей Константинов ascrus. Спасибо ему за это, рекомендую все его публикации на Хабре и в блоге;
- Вводная статья и практический опыт от alexzaitsev;
- Выбор методологии для хранилища на Vertica от Николая Голова azathot. Интересный и неожиданный для Vertica выбор Anchor Modeling (6 NF). Николай нередко делится практическим опытом на различных мероприятиях, например, на Higload++ или HPE конференции;
- Официальная on-line документация с множеством примеров;
- Краткая статья о том, чего нет в Vertica, но что многие ищут.
Спасибо за внимание, на очереди один из лидеров среди аналитических БД — Teradata.












