Иногда возникает необходимость получить данные c веб-страниц и сохранить их в структурированном виде.
Инструменты веб-скрапинга (web scraping) разрабатываются для извлечения данных с веб-сайтов. Эти инструменты бывают полезны тем, кто пытается получить данные из Интернета. Веб-скрапинг — это технология, позволяющая получать данные без необходимости открывать множество страниц и заниматься копипастом. Эти инструменты позволяют вручную или автоматически извлекать новые или обновленные данные и сохранять их для последующего использования. Например, с помощью инструментов веб-скрапинга можно извлекать информацию о товарах и ценах из интернет-магазинов.
Возможные сценарии использования инструментов веб-скрапинга:
Существует большое количество инструментов, позволяющих извлекать данные из веб-сайтов, не написав ни одной строчки кода «10 Web Scraping Tools to Extract Online Data». Инструменты могут быть самостоятельными приложениями, веб-сайтами или плагинами для браузеров. Перед тем, как писать собственный веб-скрапер, стоит изучить существующие инструменты. Как минимум, это полезно с той точки зрения, что многие из них имеют очень даже неплохие видео руководства, в которых объясняется, как все это работает.
Веб скрапер можно написать на Python (Web Scraping с помощью python) или R (Еще примеры использования R для решения практических бизнес-задач).
Я буду писать на C# (хотя, полагаю, что применяемый подход не будет зависеть от языка разработки). Особое внимание я постараюсь уделить тем досадным ошибкам, которые я допустил, поверив, что все будет работать легко и просто.
Зачем я это сделал и как я это использовал, можно прочитать здесь:
Итак, я хочу извлечь информацию о наборах данных с портала открытых данных России data.gov.ru и сохранить для последующей обработки в виде простого текстового файла формата csv. Наборы данных выводятся постранично в виде списка, каждый элемент которого содержит краткую информацию о наборе данных.

Чтоб получить более подробную информацию, необходимо перейти по ссылке.
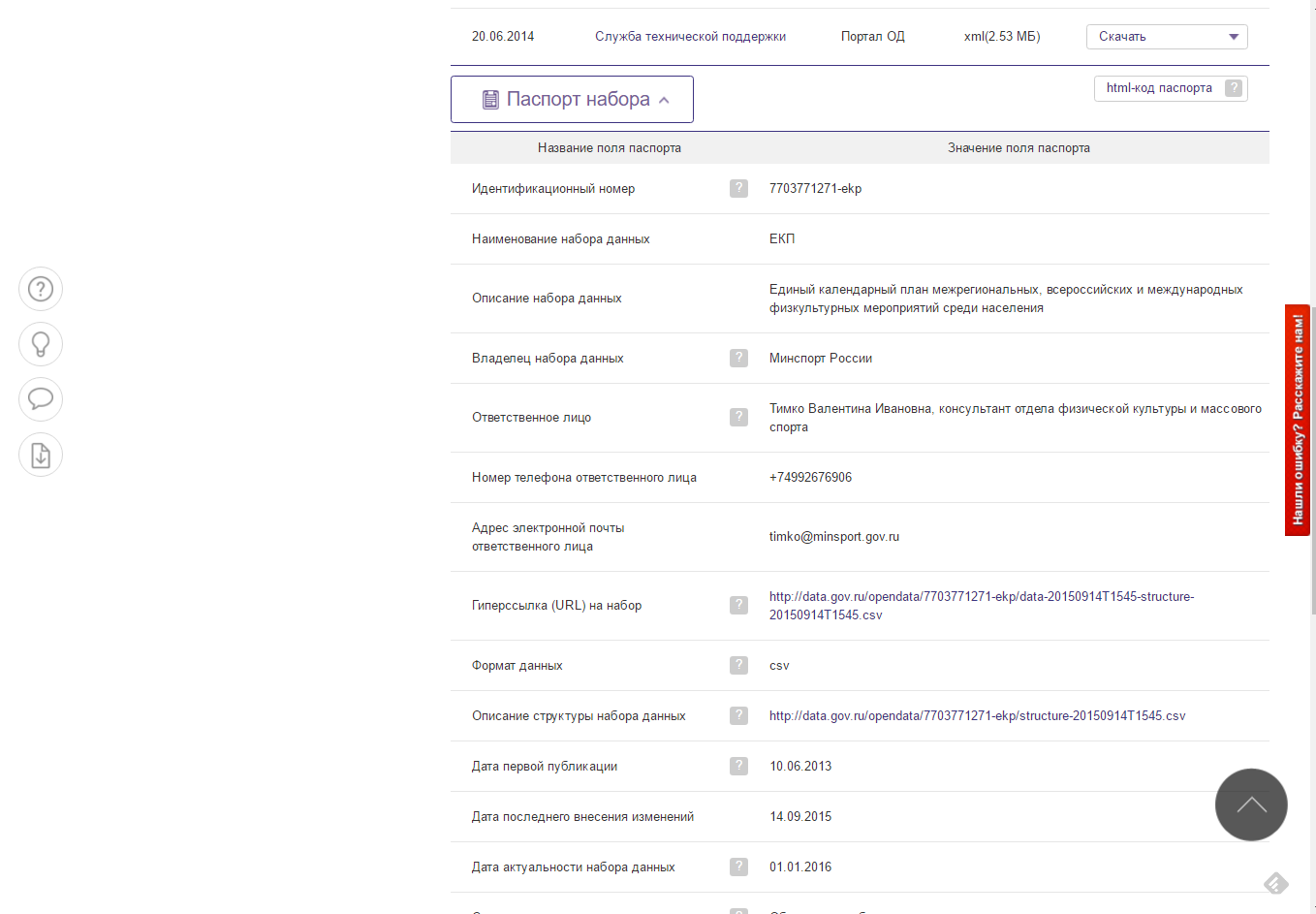
Таким образом, для того, чтобы получить информацию о наборах данных, мне необходимо:
Чего я делать не буду, так это самостоятельно загружать страницу с помощью HttpClient или WebRequest, самостоятельно парсить страницу.
Я воспользуюсь фреймворком ScrapySharp. ScrapySharp имеет встроенный веб-клиент, который может эмулировать реальный веб-браузер. Также, ScrapySharp позволяет легко парсить Html с помощью CSS селекторов и Linq. Фреймворк является надстройкой над HtmlAgilityPack. В качестве альтернативы можно рассмотреть, например, AngleSharp.
Чтобы начать использовать ScrapySharp, достаточно подключить соответствующий nuget пакет.
Теперь можно воспользоваться встроенным веб-браузером для загрузки страницы:
Страница вернулась в виде объекта типа WebPage. Страница представляется в виде набора узлов типа HtmlNode. С помощью свойства InnerHtml можно посмотреть Html код элемента, а с помощью InnerText — получить текст внутри элемента.
Собственно, чтобы извлечь необходимую информацию, мне необходимо найти нужный элемент страницы и извлечь из него текст.
Вопрос: как посмотреть код страницы и найти нужный элемент?
Можно просто посмотреть код страницы в браузере. Можно, как рекомендуют в некоторых статьях, использовать такой инструмент, как Fiddler.
Но мне показалось более удобным использовать Инструменты разработчика в Google Chrome.

Для удобства анализа кода страницы я поставил расширение XPath Helper для Chrome. Практически сразу видно, что все элементы списка содержат один и тот же класс CSS .node-dataset. Чтобы в этом убедиться, можно воспользоваться одной из функций консоли для поиска по стилю CSS.

Заданный стиль встречается на странице 30 раз и точно соответствует элементу списка, содержащего краткую информацию о наборе данных.
Получаю с помощью ScrapySharp все элементы списка, содержащие .node-dataset.
и извлекаю все элементы div, в которых лежит текст.
На самом деле, есть множество вариантов извлечения нужных данных. И я действовал по принципу «если что-то работает, то не надо это трогать».
Например, ссылку на расширенную информацию можно получить из атрибута about
В ScrapySharp это можно сделать следующим образом:
Собственно, это все, что нужно для извлечения информации о наборе данных из списка.
Казалось бы, все хорошо, но это не так.
Ошибка №1. Я считаю, что данные всегда одинаковые и в них не может быть ошибок (о качестве загруженных данных я уже писал здесь Анализ наборов данных с портала открытых данных data.gov.ru).
Например, для некоторых наборов данных присутствует текст «Рекомендовано». Мне эта информация не нужна. Пришлось добавить проверку:
Я сохраняю полученную информацию в обычные списки:
потому что в данных есть ошибки. Если я создам типизированную структуру, то мне сразу придется эти ошибки обрабатывать. Я поступил проще – сохранил данные в csv файл. Что с ними будет дальше, меня сейчас не очень волнует.
Чтобы перебрать все страницы, я не стал изобретать велосипед. Достаточно посмотреть структуру ссылок:
Для перехода к нужной странице можно использовать прямую ссылку:
Конечно, можно было искать ссылку на следующую страницу, но, тогда как я параллельно буду запрашивать страницы? Все что мне нужно, это определить, сколько всего страниц.
Я использую простой XPath запрос для получения необходимого элемента.
Предварительно я проверил его в консоли инструментов разработчика Chrome.

Я могу пройти по всем страницам и извлечь краткую информацию о наборах данных и получить ссылки на страницы с полной информацией (паспорт набора данных).
Ошибка №2. Сервер всегда возвращает нужную страницу.
Наивно полагать, что все будет работать так, как задумано. Может пропасть интернет соединение, последняя страница может быть удалена (у меня так было), сервер может решить, что это DDOS атака. Да, в какой-то момент сервер перестал мне отвечать – слишком много запросов.
Чтобы победить ошибку, я использовал следующую стратегию:
И только так я действительно смог получить все страницы.
Получение паспорта набора данных оказалось простой задачей. Вся информация лежала в таблице. И мне надо было просто извлечь текст из нужной колонки.
У каждого набора данных есть оценка, которая определяется голосованием пользователей портала. Оценка расположена не в таблице, а в отдельном теге p.
Для извлечения оценки надо найти тег p с классом .vote-current-score.
Задача решена. Данные извлечены. Можно сохранить их в текстовый файл.
Для полноценного тестирования полученного веб-скрапера я завернул его в простой REST сервис, внутри которого запускаю фоновый процесс загрузки.

И разместил его в Azure.
Чтоб было удобно контролировать процесс добавил простенький интерфейс.

Сервис извлекает данные и сохраняет в виде файлов. Помимо этого, сервис сравнивает извлеченные данные с предыдущей версией и сохраняет информацию о количестве добавленных, удаленных, измененных наборах данных.
Выводы
Создание веб-скрапера не является сверхсложной задачей.
Для создания веб-скрапера достаточно понимать, что из себя представляет Html, как используется CSS и XPath.
Существуют готовые фреймворки, которые существенно облегчают задачу, позволяя концентрироваться непосредственно на извлечении данных.
Инструментов разработчика Google Chrome вполне достаточно для того, чтобы разобраться, что и как извлекать.
Существует множество вариантов, как извлечь данные, и все они правильные, если результат достигнут.
Инструменты веб-скрапинга (web scraping) разрабатываются для извлечения данных с веб-сайтов. Эти инструменты бывают полезны тем, кто пытается получить данные из Интернета. Веб-скрапинг — это технология, позволяющая получать данные без необходимости открывать множество страниц и заниматься копипастом. Эти инструменты позволяют вручную или автоматически извлекать новые или обновленные данные и сохранять их для последующего использования. Например, с помощью инструментов веб-скрапинга можно извлекать информацию о товарах и ценах из интернет-магазинов.
Возможные сценарии использования инструментов веб-скрапинга:
- Сбор данных для маркетинговых исследований
- Извлечение контактной информации (адреса электронной почты, телефоны и т.д.) с разных сайтов для создания собственных списков поставщиков, производителей или любых других лиц, представляющих интерес.
- Загрузка решений со StackOverflow (или других подобных сайтов с вопросами-ответами) для возможности оффлайн чтения или хранения данных с различных сайтов — тем самым снижается зависимость от доступа в Интернет.
- Поиск работы или вакансий.
- Отслеживание цен на товары в различных магазинах.
Существует большое количество инструментов, позволяющих извлекать данные из веб-сайтов, не написав ни одной строчки кода «10 Web Scraping Tools to Extract Online Data». Инструменты могут быть самостоятельными приложениями, веб-сайтами или плагинами для браузеров. Перед тем, как писать собственный веб-скрапер, стоит изучить существующие инструменты. Как минимум, это полезно с той точки зрения, что многие из них имеют очень даже неплохие видео руководства, в которых объясняется, как все это работает.
Веб скрапер можно написать на Python (Web Scraping с помощью python) или R (Еще примеры использования R для решения практических бизнес-задач).
Я буду писать на C# (хотя, полагаю, что применяемый подход не будет зависеть от языка разработки). Особое внимание я постараюсь уделить тем досадным ошибкам, которые я допустил, поверив, что все будет работать легко и просто.
Зачем я это сделал и как я это использовал, можно прочитать здесь:
- Загрузка данных с сайта открытых данных data.gov.ru
- Анализ наборов данных с портала открытых данных data.gov.ru
- Использование наборов данных с портала открытых данных России data.gov.ru
А если кратко
Заинтересовало насколько полезными могут быть открытые данные, размещенные на data.gov.ru, а имеющийся api и ссылки на самом портале не позволили загрузить актуальные данные
Итак, я хочу извлечь информацию о наборах данных с портала открытых данных России data.gov.ru и сохранить для последующей обработки в виде простого текстового файла формата csv. Наборы данных выводятся постранично в виде списка, каждый элемент которого содержит краткую информацию о наборе данных.
Чтоб получить более подробную информацию, необходимо перейти по ссылке.
Таким образом, для того, чтобы получить информацию о наборах данных, мне необходимо:
- Пройти по всем страницам, содержащим наборы данных.
- Извлечь краткую информацию о наборе данных и ссылку на страницу с полной информацией.
- Открыть каждую страницу с полной информацией.
- Извлечь из страницы полную информацию.
Чего я делать не буду, так это самостоятельно загружать страницу с помощью HttpClient или WebRequest, самостоятельно парсить страницу.
Я воспользуюсь фреймворком ScrapySharp. ScrapySharp имеет встроенный веб-клиент, который может эмулировать реальный веб-браузер. Также, ScrapySharp позволяет легко парсить Html с помощью CSS селекторов и Linq. Фреймворк является надстройкой над HtmlAgilityPack. В качестве альтернативы можно рассмотреть, например, AngleSharp.
Чтобы начать использовать ScrapySharp, достаточно подключить соответствующий nuget пакет.
Теперь можно воспользоваться встроенным веб-браузером для загрузки страницы:
//Создать веб-браузер
ScrapingBrowser browser = new ScrapingBrowser();
//Загрузить веб-страницу
WebPage page = browser.NavigateToPage(new Uri("http://data.gov.ru/opendata/"));Страница вернулась в виде объекта типа WebPage. Страница представляется в виде набора узлов типа HtmlNode. С помощью свойства InnerHtml можно посмотреть Html код элемента, а с помощью InnerText — получить текст внутри элемента.
Собственно, чтобы извлечь необходимую информацию, мне необходимо найти нужный элемент страницы и извлечь из него текст.
Вопрос: как посмотреть код страницы и найти нужный элемент?
Можно просто посмотреть код страницы в браузере. Можно, как рекомендуют в некоторых статьях, использовать такой инструмент, как Fiddler.

Но мне показалось более удобным использовать Инструменты разработчика в Google Chrome.

Для удобства анализа кода страницы я поставил расширение XPath Helper для Chrome. Практически сразу видно, что все элементы списка содержат один и тот же класс CSS .node-dataset. Чтобы в этом убедиться, можно воспользоваться одной из функций консоли для поиска по стилю CSS.
Заданный стиль встречается на странице 30 раз и точно соответствует элементу списка, содержащего краткую информацию о наборе данных.
Получаю с помощью ScrapySharp все элементы списка, содержащие .node-dataset.
var Table1 = page.Html.CssSelect(".node-dataset")и извлекаю все элементы div, в которых лежит текст.
var divs = item.SelectNodes("div")На самом деле, есть множество вариантов извлечения нужных данных. И я действовал по принципу «если что-то работает, то не надо это трогать».
Например, ссылку на расширенную информацию можно получить из атрибута about
<div rel="dc:hasPart" about="/opendata/1435111685-maininfo" typeof="sioc:Item foaf:Document dcat:Dataset" class="ds-1col node node-dataset node-teaser gosudarstvo view-mode-teaser clearfix" property="dc:title" content="Общая информация об Администрации Главы Республики Саха (Якутия) и Правительства Республики Саха (Якутия)">В ScrapySharp это можно сделать следующим образом:
String link = item.Attributes["about"]?.ValueСобственно, это все, что нужно для извлечения информации о наборе данных из списка.
Казалось бы, все хорошо, но это не так.
Ошибка №1. Я считаю, что данные всегда одинаковые и в них не может быть ошибок (о качестве загруженных данных я уже писал здесь Анализ наборов данных с портала открытых данных data.gov.ru).
Например, для некоторых наборов данных присутствует текст «Рекомендовано». Мне эта информация не нужна. Пришлось добавить проверку:
if (innerText != "Рекомендовано")
{
items.Add(innerText);
}Я сохраняю полученную информацию в обычные списки:
List<string> items = new List<string>()потому что в данных есть ошибки. Если я создам типизированную структуру, то мне сразу придется эти ошибки обрабатывать. Я поступил проще – сохранил данные в csv файл. Что с ними будет дальше, меня сейчас не очень волнует.
Чтобы перебрать все страницы, я не стал изобретать велосипед. Достаточно посмотреть структуру ссылок:
<div class="item-list"><ul class="pager"><li class="pager-first first"><a title="На первую страницу" href="/opendata?query=">« первая</a></li>
<li class="pager-previous"><a title="На предыдущую страницу" href="/opendata?query=&page=32">‹ предыдущая</a></li>
<li class="pager-item"><a title="На страницу номер 30" href="/opendata?query=&page=29">30</a></li>
<li class="pager-item"><a title="На страницу номер 31" href="/opendata?query=&page=30">31</a></li>
…
<li class="pager-item"><a title="На страницу номер 37" href="/opendata?query=&page=36">37</a></li>
<li class="pager-item"><a title="На страницу номер 38" href="/opendata?query=&page=37">38</a></li>
<li class="pager-next"><a title="На следующую страницу" href="/opendata?query=&page=34">следующая ›</a></li>
<li class="pager-last last"><a title="На последнюю страницу" href="/opendata?query=&page=423">последняя »</a></li>
</ul></div> Для перехода к нужной странице можно использовать прямую ссылку:
http://data.gov.ru/opendata?query=&page={0}Конечно, можно было искать ссылку на следующую страницу, но, тогда как я параллельно буду запрашивать страницы? Все что мне нужно, это определить, сколько всего страниц.
WebPage page = _Browser.NavigateToPage(new Uri("http://data.gov.ru/opendata"));
var lastPageLink = page.Html.SelectSingleNode("//li[@class='pager-last last']/a");
if (lastPageLink != null)
{
string href = lastPageLink.Attributes["href"].Value;
…Я использую простой XPath запрос для получения необходимого элемента.
Предварительно я проверил его в консоли инструментов разработчика Chrome.
Я могу пройти по всем страницам и извлечь краткую информацию о наборах данных и получить ссылки на страницы с полной информацией (паспорт набора данных).
Ошибка №2. Сервер всегда возвращает нужную страницу.
Наивно полагать, что все будет работать так, как задумано. Может пропасть интернет соединение, последняя страница может быть удалена (у меня так было), сервер может решить, что это DDOS атака. Да, в какой-то момент сервер перестал мне отвечать – слишком много запросов.
Чтобы победить ошибку, я использовал следующую стратегию:
- Если сервер не вернул страницу, повторять n раз (не до бесконечности, страницы уже может не быть).
- Если сервер не вернул страницу, не запрашивать ее сразу, а сделать таймаут на k миллисекунд. И при следующей ошибке для этой же страницы увеличивать его.
- Запрашивать не сразу все страницы, а с небольшой задержкой.
И только так я действительно смог получить все страницы.
Получение паспорта набора данных оказалось простой задачей. Вся информация лежала в таблице. И мне надо было просто извлечь текст из нужной колонки.
List<string> passport = new List<string>();
var table = page.Html.CssSelect(".sticky-enabled").FirstOrDefault();
if (table != null)
{
foreach (var row in table.SelectNodes("tbody/tr")) {
foreach (var cell in row.SelectNodes("td[2]")) {
passport.Add(cell.InnerText);
}
}
}
У каждого набора данных есть оценка, которая определяется голосованием пользователей портала. Оценка расположена не в таблице, а в отдельном теге p.
Для извлечения оценки надо найти тег p с классом .vote-current-score.
var score = PageResult.Html.SelectSingleNode("//p[@class='vote-current-score']");Задача решена. Данные извлечены. Можно сохранить их в текстовый файл.
Для полноценного тестирования полученного веб-скрапера я завернул его в простой REST сервис, внутри которого запускаю фоновый процесс загрузки.
И разместил его в Azure.
Чтоб было удобно контролировать процесс добавил простенький интерфейс.
Сервис извлекает данные и сохраняет в виде файлов. Помимо этого, сервис сравнивает извлеченные данные с предыдущей версией и сохраняет информацию о количестве добавленных, удаленных, измененных наборах данных.
Выводы
Создание веб-скрапера не является сверхсложной задачей.
Для создания веб-скрапера достаточно понимать, что из себя представляет Html, как используется CSS и XPath.
Существуют готовые фреймворки, которые существенно облегчают задачу, позволяя концентрироваться непосредственно на извлечении данных.
Инструментов разработчика Google Chrome вполне достаточно для того, чтобы разобраться, что и как извлекать.
Существует множество вариантов, как извлечь данные, и все они правильные, если результат достигнут.









