Сегодня я постараюсь разъяснить, что такое концепция доступности данных с точки зрения ИТ-специалиста, будь то ИТ-администратор, системный интегратор, консультант по внедрению и т.д. Надеюсь, что эта статья будет полезна читателям при составлении экономического обоснования на внедрение соответствующих программных и\или аппаратных решений, а также соглашений об уровне обслуживания (SLA) – а кому-то поможет сделать эти документы более убедительными.
Для начала в качестве «узелков на память» сформулирую два постулата, с которыми многие, уверен, довольно хорошо знакомы:
Часто эта пара показателей отображается в виде одномерного графика вдоль оси времени.
Но в таком одномерном графике нет самого главного, на что ориентируется бизнес – денег! О том, как рассчитывать RTO и RPO, исходя из требований бизнеса, я расскажу под катом.

Начнем «от печки», то есть с прямой линии вдоль оси времени, где:
(Здесь идет речь о целевых показателях, поскольку для конкретных систем должны быть конкретные значения.)

Ясно, что все системы в компании работают не просто так, а для различных нужд/целей. Сама же компания зарабатывает (и тратит) деньги. В случае сбоя системы компания, очевидно, деньги теряет. Показатели RTO и RPO – то, что говорит о приемлемых размерах этих потерь.
Поэтому в график вводится второе измерение – финансовое (вот они, деньги – $):

Из такого графика уже видно, что стоимость простоя сервиса растет со временем: чем дольше не работает система, тем больше денег теряет компания.
Тоже самое и со стоимостью потерь данных: чем больше мы их (в исторической перспективе) теряем, тем дороже такая потеря обойдется компании. И да, эти графики в живой природе не симметричны.
Как правило, эти стоимости меняются не линейно, что отражено на картинке. Чаще всего наступает момент, когда стоимость потери начинает резко возрастать – отсюда и те самые печальные истории, когда компании теряли так много от сбоя системы, что некоторые даже не смогли вернуться в бизнес.
Чтобы защититься от таких проблем, необходимо внедрить систему, которая будет обеспечивать защиту от потерь данных и восстановление после сбоев. Такие системы имеют свои стоимости, и, значит, их тоже можно отразить на графике (нарисуем их синим):

Как видно из графика, чем меньше показатели RPO и RTO при потере данных, чем меньшее время простоя сервиса обеспечивает решение по защите, тем дороже такая защита стоит.
И тут мы наблюдаем пересечение кривых на графике – я отметил эти точки зелеными стрелками. Это так называемые точки безубыточности для системы защиты и для защищаемой информационной системы. Отдаляясь от данной точки, мы получаем дорогую систему защиты, стоимость которой превышает стоимость потери/простоя, либо наоборот – дешевую систему защиты, но не обеспечивающую приемлемый уровень потерь.
Как кажется, вывод напрашивается сам собой: именно ориентируясь на точки безубыточности, и надо подбирать системы, которые обеспечат нам необходимую защиту.
На самом деле, если мы построим такие графики, ориентируясь на данные из реальной жизни, то получим несколько иную картину. В частности, график стоимости решения по защите будет иметь вид не сплошной линии, а множества точек. Различные защитные решения не выстраиваются вплотную друг за другом вдоль графика, а представляют собой отдельные точки, ведь каждое имеет свои «координаты»: стоимость (обозначенная вендором-производителем данного решения) и время обеспечения этим решением соответствующих потерь данных (RPO) и скорости восстановления работоспособности (RTO).
К тому же, как правило, ищется решение по защите не одной конкретной информационной системы (ИС), а группы (или вообще всех) инфосистем компании (то есть всей инфраструктуры). При этом каждое такое решение, скорее всего, будет иметь свои графики зависимостей стоимости простоя/потери данных от времени.
Получается, что наши точки безубыточности – уже не точки, а области:
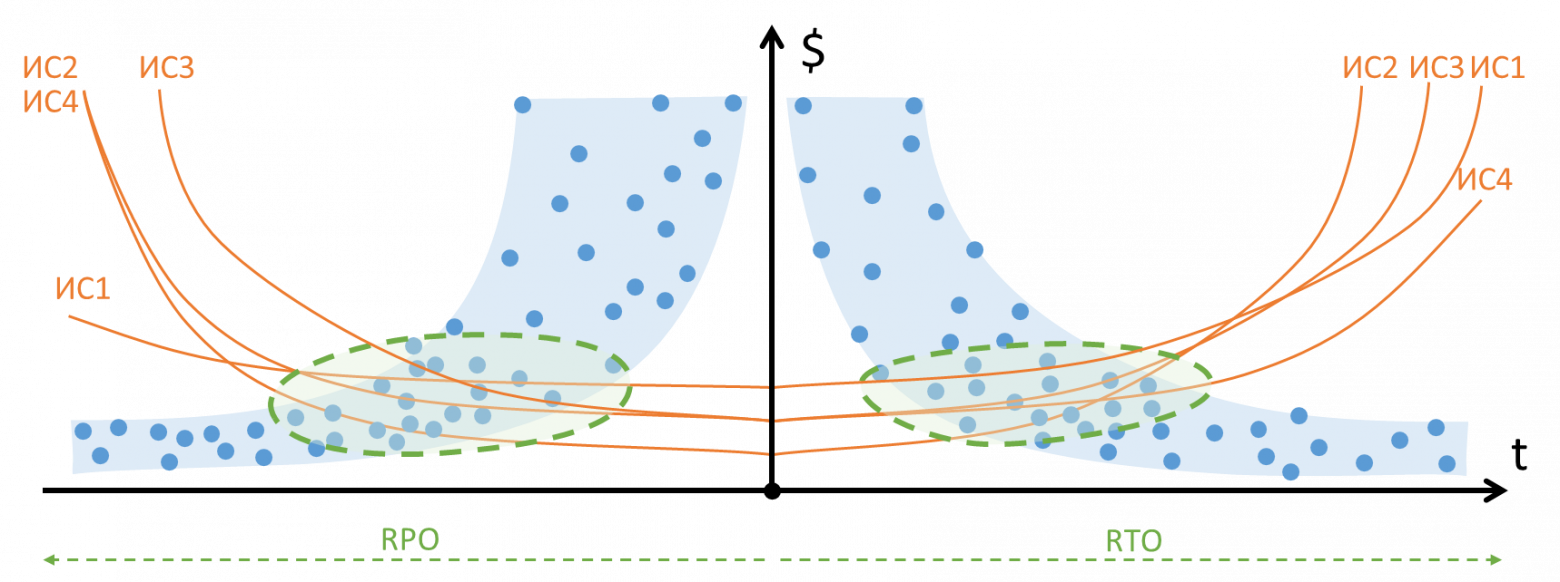
Если мы рассмотрим нашу инфраструктуру более пристально и начнем строить графики для каждой ИС, то мы увидим интересную тенденцию — системы группируются со схожими. Об этом ниже.
Обратите внимание, до сего момента я говорил про «защиту», но не оговаривал, что это за защита конкретно: резервное копирование, кластер, какие-то еще виды защиты? Тут стоит сказать, что системы защиты бывают разные, и их можно классифицировать.
На схеме ниже видно, какой примерно класс решения в зависимости от целевых RTO/RPO рекомендуется выбирать.

Конечно, на картинке всё изображено достаточно схематично. На самом деле нет четких границ между типами решений, как и точных значений в виде точек.
Например, сейчас многие решения по резервному копированию используют технологию запуска сервиса из резервной копии. Время обеспечения доступности при использовании такой технологии — в среднем ~2-5 минут на одну ВМ. И такие показатели находятся в рамках RTO для реплик или даже кластеров.
Кластеры, как и DR-решения (и вообще практически все решения по защите от потерь данных или восстановлению работоспособности) имеют свои значения по скорости восстановления данных и объемам данных, которые теряются. Потому они также связаны со своими показателями RTO/RPO.
Говоря, например, про HA-кластер (HA – High Availability), имеем в виду, что его RTO равно времени переключения. Допустим, MSCS для двух нод переключает СУБД за 30 секунд. Значит, целевое RTO, которое можно обеспечить этим видом кластера — от 30 секунд.
А если рассмотреть VMware HA, которое отработает за 2 минуты (с учетом старта виртуальной машины, ее гостевой ОС и приложений)? Значит, такое решение подходит для приложений с целевым значением RTO от 2 минут.
Где же потери для HA-кластера (и соответственно, обеспечение RPO), спросите вы? Когда сервис поднимается, есть вероятность небольших потерь данных. Например, если СУБД проверит состояние базы данных и может откатить своё состояние на некорректно проведенную транзакцию. Или если файловая система вернется к некорректно сохраненной версии файла, и т.д., и т.п.
Вывод: не всегда стоит строить одинаковые решения одно поверх другого, например, HA над HA. Это только излишне усложнит инфраструктуру, усложнит (и удорожает) поддержку работы таких систем.
Обратим внимание еще на ряд факторов:
Так что совокупное применение различных решений – благо. Главное — подходить с умом и понимать, для чего какое решение применяется.
Хочу сделать на этом акцент, поскольку я сам периодически совершаю ошибку, потому и остерегаю от этого вас:
RTO и RPO – это целевые значения для информационных систем (ИС), максимальные рамки, в которые мы должны уложиться. И эти целевые значения нам, ИТ-специалистам, сообщает бизнес, точнее, бизнес-владельцы соответствующей ИС, но не наоборот.
То есть:
Нельзя сказать, что RTO функции Instant Recovery – 2 минуты.
Нельзя считать, что резервное копирование раз в сутки и есть RPO 24 часа.
Всё идет в обратную сторону, то есть от бизнеса, и конкретно для RTO будет озвучиваться так:
Или же для RPO:
Допустим, бизнес озвучивает следующее: «Это очень важный, критический сервис, и, если он будет простаивать больше 5 минут – случатся <такая-то сумма>-финансовые потери, а через 30 минут простоя – в 10 раз больше! И это уже не приемлемо для компании.»
Казалось бы, можно рассуждать так:
Но! При этом надо понимать еще несколько моментов:
Все это влияет на общее время восстановления.
Поэтому рассуждаем дальше:
Как видим, в 5 минут мы вряд ли укладываемся.
Теперь подумаем, возможно, нужен HA-кластер со временем восстановления 2 минуты? Но и он не обеспечит нам защиту от всех типов сбоев: рестарт машины в BSoD вполне вероятен, диск ВМ — тоже точка отказа, и т.п. Следовательно нужна дополнительная защита. Значит, продолжаем наши рассуждения:
В итоге, ваш ответ бизнес-владельцу ИС будет таким:
Очень важно! Самый главный совет: после того, как вы согласовали с владельцем ИС конкретные целевые показатели, договорились – обязательно фиксируйте ваши договоренности с ним в письменном виде, подписывайте с ним соглашение об уровне обслуживания (SLA).
Заметили, что я пишу постоянно «восстановление данных и восстановление работоспособности сервиса»? Чаще всего пишу вместе, в одном предложении. Это две связанные между собой вещи, которые почти всегда не могу жить друг без друга.
Мы восстановили работу сервиса, но при этом потеряли все его данные – это неприемлемо. Мы восстановили БД, но СУБД не запускается, прочитать данные не могут – это неприемлемо. Именно поэтому мы говорим о доступности и данных, и сервисов. Важны и RPO, и RTO – в совокупности они обеспечивают доступность и того, и другого.
Вот такой вот дуализм ;) Вместе дуальная пара RTO и RPO является важным показателем в том самом соглашении об уровне обслуживания (Service Level Agreement, или SLA) для конкретной ИС в части обеспечения доступности её сервисов и данных в случае возникновения сбоя. А подписывается соответствующее соглашение, как я говорил выше, между владельцем ИС (заказчиком услуги), и вами, ИТ-отделом (поставщиком услуги).
Для начала в качестве «узелков на память» сформулирую два постулата, с которыми многие, уверен, довольно хорошо знакомы:
- RPO (recovery point objective) – допустимая потеря данных. Любая информационная система должна обеспечивать (внутренними ли средствами, или сторонними) защиту своих данных от потери выше приемлемого уровня.
- RTO (recovery time objective) – допустимое время восстановления данных Любая информационная система должна обеспечивать (внутренними ли средствами, или сторонними) возможность восстановления своей работы в приемлемый срок.
Часто эта пара показателей отображается в виде одномерного графика вдоль оси времени.
Но в таком одномерном графике нет самого главного, на что ориентируется бизнес – денег! О том, как рассчитывать RTO и RPO, исходя из требований бизнеса, я расскажу под катом.
Начнем «от печки», то есть с прямой линии вдоль оси времени, где:
- Точкой-событием отмечается сбой в работе системы
- Левее этой точки (то есть в прошлое) отмечается целевое значение RPO
- Правее (то есть в будущем) отмечается целевое значение RTO
(Здесь идет речь о целевых показателях, поскольку для конкретных систем должны быть конкретные значения.)

Ясно, что все системы в компании работают не просто так, а для различных нужд/целей. Сама же компания зарабатывает (и тратит) деньги. В случае сбоя системы компания, очевидно, деньги теряет. Показатели RTO и RPO – то, что говорит о приемлемых размерах этих потерь.
Поэтому в график вводится второе измерение – финансовое (вот они, деньги – $):

Из такого графика уже видно, что стоимость простоя сервиса растет со временем: чем дольше не работает система, тем больше денег теряет компания.
Тоже самое и со стоимостью потерь данных: чем больше мы их (в исторической перспективе) теряем, тем дороже такая потеря обойдется компании. И да, эти графики в живой природе не симметричны.
Как правило, эти стоимости меняются не линейно, что отражено на картинке. Чаще всего наступает момент, когда стоимость потери начинает резко возрастать – отсюда и те самые печальные истории, когда компании теряли так много от сбоя системы, что некоторые даже не смогли вернуться в бизнес.
Чтобы защититься от таких проблем, необходимо внедрить систему, которая будет обеспечивать защиту от потерь данных и восстановление после сбоев. Такие системы имеют свои стоимости, и, значит, их тоже можно отразить на графике (нарисуем их синим):

Как видно из графика, чем меньше показатели RPO и RTO при потере данных, чем меньшее время простоя сервиса обеспечивает решение по защите, тем дороже такая защита стоит.
Определим точки безубыточности решения по защите
И тут мы наблюдаем пересечение кривых на графике – я отметил эти точки зелеными стрелками. Это так называемые точки безубыточности для системы защиты и для защищаемой информационной системы. Отдаляясь от данной точки, мы получаем дорогую систему защиты, стоимость которой превышает стоимость потери/простоя, либо наоборот – дешевую систему защиты, но не обеспечивающую приемлемый уровень потерь.
Как кажется, вывод напрашивается сам собой: именно ориентируясь на точки безубыточности, и надо подбирать системы, которые обеспечат нам необходимую защиту.
На самом деле, если мы построим такие графики, ориентируясь на данные из реальной жизни, то получим несколько иную картину. В частности, график стоимости решения по защите будет иметь вид не сплошной линии, а множества точек. Различные защитные решения не выстраиваются вплотную друг за другом вдоль графика, а представляют собой отдельные точки, ведь каждое имеет свои «координаты»: стоимость (обозначенная вендором-производителем данного решения) и время обеспечения этим решением соответствующих потерь данных (RPO) и скорости восстановления работоспособности (RTO).
К тому же, как правило, ищется решение по защите не одной конкретной информационной системы (ИС), а группы (или вообще всех) инфосистем компании (то есть всей инфраструктуры). При этом каждое такое решение, скорее всего, будет иметь свои графики зависимостей стоимости простоя/потери данных от времени.
Получается, что наши точки безубыточности – уже не точки, а области:

Если мы рассмотрим нашу инфраструктуру более пристально и начнем строить графики для каждой ИС, то мы увидим интересную тенденцию — системы группируются со схожими. Об этом ниже.
Рассматриваем различные классы решений
Обратите внимание, до сего момента я говорил про «защиту», но не оговаривал, что это за защита конкретно: резервное копирование, кластер, какие-то еще виды защиты? Тут стоит сказать, что системы защиты бывают разные, и их можно классифицировать.
На схеме ниже видно, какой примерно класс решения в зависимости от целевых RTO/RPO рекомендуется выбирать.

Конечно, на картинке всё изображено достаточно схематично. На самом деле нет четких границ между типами решений, как и точных значений в виде точек.
Например, сейчас многие решения по резервному копированию используют технологию запуска сервиса из резервной копии. Время обеспечения доступности при использовании такой технологии — в среднем ~2-5 минут на одну ВМ. И такие показатели находятся в рамках RTO для реплик или даже кластеров.
Немного о кластерах
Кластеры, как и DR-решения (и вообще практически все решения по защите от потерь данных или восстановлению работоспособности) имеют свои значения по скорости восстановления данных и объемам данных, которые теряются. Потому они также связаны со своими показателями RTO/RPO.
Говоря, например, про HA-кластер (HA – High Availability), имеем в виду, что его RTO равно времени переключения. Допустим, MSCS для двух нод переключает СУБД за 30 секунд. Значит, целевое RTO, которое можно обеспечить этим видом кластера — от 30 секунд.
А если рассмотреть VMware HA, которое отработает за 2 минуты (с учетом старта виртуальной машины, ее гостевой ОС и приложений)? Значит, такое решение подходит для приложений с целевым значением RTO от 2 минут.
Где же потери для HA-кластера (и соответственно, обеспечение RPO), спросите вы? Когда сервис поднимается, есть вероятность небольших потерь данных. Например, если СУБД проверит состояние базы данных и может откатить своё состояние на некорректно проведенную транзакцию. Или если файловая система вернется к некорректно сохраненной версии файла, и т.д., и т.п.
Вывод: не всегда стоит строить одинаковые решения одно поверх другого, например, HA над HA. Это только излишне усложнит инфраструктуру, усложнит (и удорожает) поддержку работы таких систем.
К предыдущим примерам двух HA. Определите, какое реальное значение RTO необходимо обеспечить для приложения? Для значений больше 2 минут нет смысла стоить еще и HA-кластер для сервисов внутри ВМ.
Обратим внимание еще на ряд факторов:
- Разные системы обеспечения доступности могут решать различные проблемы, закрывать различные риски (риск-менеджмент – отдельная тема). И даже разные кластеры могут закрывать различные потенциальные проблемы и также дополнять друг друга.
К примеру, резервное копирование почтового сервера не исключает, но дополняет использование кластера HA для почтовых серверов. Кластер защищает от выхода из строя физического сервера и обеспечивает быстрое переключение на резервный сервер. Но кластер не защищает от потери данных (нежелательного удаленных данных, невозможности запуска ВМ после сбоя оборудования и т.п.). Для этого необходимо применение резервного копирования.
- Сами кластеры тоже могут быть призваны защищать от различных сбоев и дополнять друг друга. Например, Micosoft Exchange DAG-кластер (HA) обеспечивает не только защиту от выхода из строя одной из вычислительных нод кластера (самого сервера), но и при выходе из строя диска сервера- за счет того, что данные дублируются на других нодах.
Что при этом дает совместное использование VMware vSphere HA? Быстрое восстановление уровня защиты. Если просто выключился один сервер с одной нодой MS Exchange, то вначале отработает DAG, переключив сервисы на другую ноду, а затем HA VMware загрузит сбойный сервер на другом плече своего кластера. И система готова к работе. (Хотя в этом примере я бы рассматривал применение виртуализации не только для одной функции только кластера, но и для всех остальных преимуществ самой платформы).
- Еще на графике выше я отметил решения по архивированию. Обратите внимание, что для архивов не имеет смысла рассматривать RTO, так как применяются такие решения для восстановления старых исторических данных. Для таких исторических данных необходимо обеспечивать RPO. То есть в этом случае речь идет про глубину и долгосрочность хранения данных, не используемых для текущей операционной деятельности компании.
Так что совокупное применение различных решений – благо. Главное — подходить с умом и понимать, для чего какое решение применяется.
Говорим и пишем правильно! Или еще раз про RTO и RPO
Хочу сделать на этом акцент, поскольку я сам периодически совершаю ошибку, потому и остерегаю от этого вас:
RTO ≠ скорость восстановления!
RPO ≠ количество потерянных данных!
RTO и RPO – это целевые значения для информационных систем (ИС), максимальные рамки, в которые мы должны уложиться. И эти целевые значения нам, ИТ-специалистам, сообщает бизнес, точнее, бизнес-владельцы соответствующей ИС, но не наоборот.
То есть:
Нельзя сказать, что RTO функции Instant Recovery – 2 минуты.
Нельзя считать, что резервное копирование раз в сутки и есть RPO 24 часа.
Всё идет в обратную сторону, то есть от бизнеса, и конкретно для RTO будет озвучиваться так:
Для определенного сервиса, в случае сбоя обслуживающей этот сервис системы, необходимо обеспечить восстановление, не допустив простоя в работе этого сервиса более 5 минут (RTO – 5 минут). Значит, подойдет решение, которое позволит сделать систему доступной за срок менее 5 минут.
Или же для RPO:
Для базы данных, в случае сбоя СУБД, нужно обеспечить восстановление с допустимой потерей данных сроком не более 24 часов от момента сбоя. Значит, подойдет решение, которое обеспечит гарантированное восстановление базы из точек восстановления, производимых чаще, чем 1 раз в сутки. При этом отмечу, что резервное копирование раз в час, создающее 24 точки восстановления, дает больше гарантий восстановления, чем копирование раз в сутки, делающее только 1 точку.
А вот и практический пример
Допустим, бизнес озвучивает следующее: «Это очень важный, критический сервис, и, если он будет простаивать больше 5 минут – случатся <такая-то сумма>-финансовые потери, а через 30 минут простоя – в 10 раз больше! И это уже не приемлемо для компании.»
Казалось бы, можно рассуждать так:
«Применение функции Instant Recovery обеспечит технический процесс восстановления в 2 минуты...»
Но! При этом надо понимать еще несколько моментов:
- Нам, прежде всего, необходимо отследить момент возникновения сбоя.
- Определить последствия от сбоя: всё сломалось или что-то доступно.
- Желательно найти причины возникновения сбоя, или хотя бы локализовать (изолировать) проблему: если пожар – потушить его, прежде чем пытаться восстановить что-либо в ту же инфраструктуру; если вирус портит данные – отключить от сети зараженный сервер, а не кормить вирус восстановленным сервером.
- Далее определить способы реанимации (наиболее подходящую процедуру восстановления: перегрузить ВМ, дождаться переключения кластера на другую ноду, или восстановить из резервной копии).
- Принять решение по восстановлению и собственно запустить восстановление.
Все это влияет на общее время восстановления.
Поэтому рассуждаем дальше:
«У меня настроен мониторинг для этого сервиса, и оповещение сработает и будет замечено за минуту-две (телефон с полученной СМС надо из кармана достать, или почтовый клиент с новым письмом надо открыть). Я сяду за компьютер, пингану сервис, попытаюсь открыть на нем консоль, посмотрю, что там с гипервизором и железом. Проведу первичную реанимацию (попробую перегрузить машину). На все это я потрачу порядка 15 минут. Если не помогут действия по быстрой реанимации — восстановлюсь из резервной копии. Но так как копироваться из бэкапа данные будут еще минут 15-20, то я воспользуюсь Instant VM Recovery за 2 минуты, а затем запущу онлайн перенос данных машины в продакшен.»
Как видим, в 5 минут мы вряд ли укладываемся.
Теперь подумаем, возможно, нужен HA-кластер со временем восстановления 2 минуты? Но и он не обеспечит нам защиту от всех типов сбоев: рестарт машины в BSoD вполне вероятен, диск ВМ — тоже точка отказа, и т.п. Следовательно нужна дополнительная защита. Значит, продолжаем наши рассуждения:
«В случае кластера я восстановлюсь за 2 минуты. А в дополнение я потрачу, как уже прикинул(а), 15+2 минут при восстановлении из резервной копии, всего 2+15+2=19 минут, и 11 минут ещё остаются в запасе.»
В итоге, ваш ответ бизнес-владельцу ИС будет таким:
«ОК. Я обеспечу RTO в 30 минут. Я включу этот сервис в кластер — для обеспечения 5 минутного RTO, и настрою резервное копирование — для защиты от сбоев с более серьёзными последствиями.»
Очень важно! Самый главный совет: после того, как вы согласовали с владельцем ИС конкретные целевые показатели, договорились – обязательно фиксируйте ваши договоренности с ним в письменном виде, подписывайте с ним соглашение об уровне обслуживания (SLA).
Почему мы называем это «концепцией доступности»?
Заметили, что я пишу постоянно «восстановление данных и восстановление работоспособности сервиса»? Чаще всего пишу вместе, в одном предложении. Это две связанные между собой вещи, которые почти всегда не могу жить друг без друга.
Мы восстановили работу сервиса, но при этом потеряли все его данные – это неприемлемо. Мы восстановили БД, но СУБД не запускается, прочитать данные не могут – это неприемлемо. Именно поэтому мы говорим о доступности и данных, и сервисов. Важны и RPO, и RTO – в совокупности они обеспечивают доступность и того, и другого.
Через 15 минут после сбоя восстановлен доступ к сервису с данными за весь предыдущий период работы (до 1 часа включительно) – это всё про общую доступность.
Вот такой вот дуализм ;) Вместе дуальная пара RTO и RPO является важным показателем в том самом соглашении об уровне обслуживания (Service Level Agreement, или SLA) для конкретной ИС в части обеспечения доступности её сервисов и данных в случае возникновения сбоя. А подписывается соответствующее соглашение, как я говорил выше, между владельцем ИС (заказчиком услуги), и вами, ИТ-отделом (поставщиком услуги).
