JSON, YAML сейчас популярны, а XML технологии считаются пережитком прошлого.

Попробуем использовать «ретро технологии» для работы с данными в формате JSON и YAML. И порассуждаем о причинах применять их в наши дни.
Есть задача — логику трансформации данных вынести в конфигурацию приложения, желательно в декларативном стиле и унифицировано для разных форматов. Данные могут быть в различных текстовых форматах сериализации json, yaml, xml, java properties, ini file. Но при этом Data Lake слишком тяжелая артиллерия для этого. Помещать данные в документоориентированную или объектно-реляционную базу и пытаться выполнять запросы по загруженным туда данным тоже over engineering для первого этапа ETL трансформации.
JsonPath повторяет подмножество XPath, но только к JSON формату. И написать декларативный запрос без программирования не выйдет — нет аналога XQuery. Как вариант — можно было бы использовать какую-либо embedded database в jvm с ее декларативным языком запросом, но это тема для отдельной публикации и исходная модель данных в json, yaml не реляционная.
XQuery можно выполнять над данными в Document Object Model. Как бы преобразовать данные из JSON/YAML в DOM объект… Можно воспользоваться camel-xmljson или json2xml. В этих библиотеках источник данных только json. Поэтому помчим на своем dom-transformation велосипеде. Эта библиотека умеет принимать на вход Map<String, Object> и превращать его в org.w3c.dom.Node, а так же есть обратное преобразование.
Осталось научиться превращать JSON и YAML в Map<String, Object>. Например, это можно сделать с помощью класса com.fasterxml.jackson.databind.ObjectMapper из jackson.
Превращаем JSON в Map:
Превращаем YAML в Map:
Превращаем Map в Document Object Model, подключив к проекту библиотеку:
Можно использовать любую реализацию XQuery для выполнения запросов. Мне нравится basex как до сих пор развивающийся open source проект. Подключаем к проекту зависимость org.basex:basex:jar:9.0 и выполняем декларативный запрос:
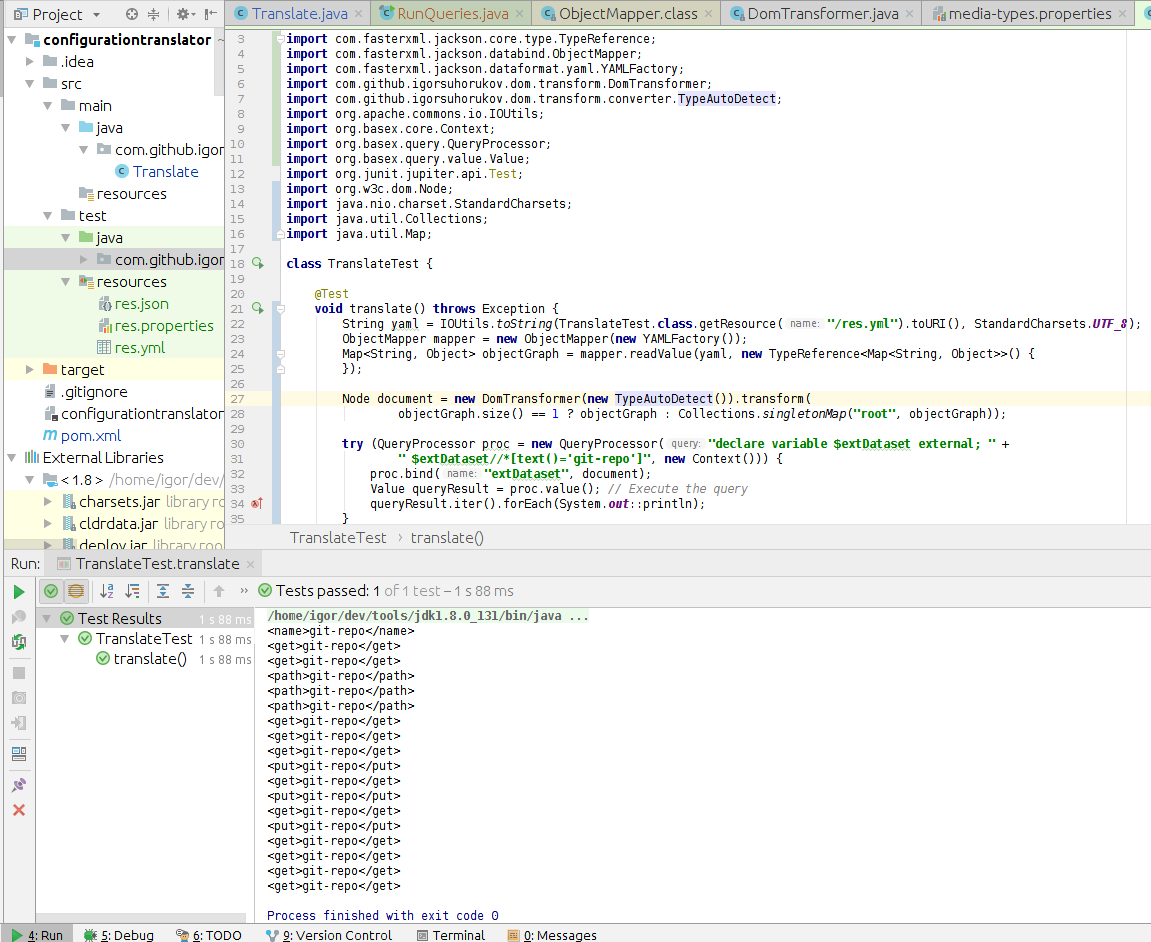
Результаты работы для данных из pipeline.yml
Если же нужно преобразовать DOM/XML в JSON/YAML с помощью jackson, то transform(Node currentNode) может помочь в этом.
С помощью XQuery можно выполнять запросы не только к XML данным. С чем этот язык запросов до сих пор успешно справляется и этот «старичок» еще поживет в java проектах по трансформации данных даже в форматах JSON и YAML.
Конечно, слабоструктурированные данные это не только JSON, YAML и XML. И ставить точку в обработке всего на свете еще рано…

Надеюсь, что подход из публикации поможет вам выполнять в приложении декларативные запросы по разнородным данным. Или же вы сталкивались с подобной задачей в JVM и у вас есть идеи лучше, делитесь в комментариях!

Попробуем использовать «ретро технологии» для работы с данными в формате JSON и YAML. И порассуждаем о причинах применять их в наши дни.
Есть задача — логику трансформации данных вынести в конфигурацию приложения, желательно в декларативном стиле и унифицировано для разных форматов. Данные могут быть в различных текстовых форматах сериализации json, yaml, xml, java properties, ini file. Но при этом Data Lake слишком тяжелая артиллерия для этого. Помещать данные в документоориентированную или объектно-реляционную базу и пытаться выполнять запросы по загруженным туда данным тоже over engineering для первого этапа ETL трансформации.
JsonPath повторяет подмножество XPath, но только к JSON формату. И написать декларативный запрос без программирования не выйдет — нет аналога XQuery. Как вариант — можно было бы использовать какую-либо embedded database в jvm с ее декларативным языком запросом, но это тема для отдельной публикации и исходная модель данных в json, yaml не реляционная.
Подход к запросам данных из JSON/YAML
XQuery можно выполнять над данными в Document Object Model. Как бы преобразовать данные из JSON/YAML в DOM объект… Можно воспользоваться camel-xmljson или json2xml. В этих библиотеках источник данных только json. Поэтому помчим на своем dom-transformation велосипеде. Эта библиотека умеет принимать на вход Map<String, Object> и превращать его в org.w3c.dom.Node, а так же есть обратное преобразование.
Осталось научиться превращать JSON и YAML в Map<String, Object>. Например, это можно сделать с помощью класса com.fasterxml.jackson.databind.ObjectMapper из jackson.
Превращаем JSON в Map:
ObjectMapper mapper = new ObjectMapper();
Map<String, Object> objectTree = mapper.readValue(yaml, new TypeReference<Map<String, Object>>() {});
Превращаем YAML в Map:
ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
Map<String, Object> objectTree = mapper.readValue(yaml, new TypeReference<Map<String, Object>>() {});
Превращаем Map в Document Object Model, подключив к проекту библиотеку:
DomTransformer toDom = new DomTransformer(new TypeAutoDetect()).transform(objectTree.size() == 1 ? objectTree : Collections.singletonMap("root", objectTree));
Node document = toDom.translate(objectTree);
Можно использовать любую реализацию XQuery для выполнения запросов. Мне нравится basex как до сих пор развивающийся open source проект. Подключаем к проекту зависимость org.basex:basex:jar:9.0 и выполняем декларативный запрос:
String yaml = IOUtils.toString(TranslateTest.class.getResource("/pipeline.yml").toURI(), StandardCharsets.UTF_8);
ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
Map<String, Object> objectGraph = mapper.readValue(yaml, new TypeReference<Map<String, Object>>() {});
Node document = new DomTransformer(new TypeAutoDetect()).transform(
objectGraph.size() == 1 ? objectGraph : Collections.singletonMap("root", objectGraph));
try(QueryProcessor proc = new QueryProcessor("declare variable $extDataset external; " +
" $extDataset//*[text()='git-repo']", new Context())) {
proc.bind("extDataset", document);
Value queryResult = proc.value(); // execute the query
queryResult.iter().forEach(System.out::println);
}
Результаты работы для данных из pipeline.yml

Если же нужно преобразовать DOM/XML в JSON/YAML с помощью jackson, то transform(Node currentNode) может помочь в этом.
Выводы
С помощью XQuery можно выполнять запросы не только к XML данным. С чем этот язык запросов до сих пор успешно справляется и этот «старичок» еще поживет в java проектах по трансформации данных даже в форматах JSON и YAML.
Конечно, слабоструктурированные данные это не только JSON, YAML и XML. И ставить точку в обработке всего на свете еще рано…

Надеюсь, что подход из публикации поможет вам выполнять в приложении декларативные запросы по разнородным данным. Или же вы сталкивались с подобной задачей в JVM и у вас есть идеи лучше, делитесь в комментариях!
26 апреля мы с коллегой проводим открытый java meetup в московском офисе. Будем рады гостям!
Вы сможете отдохнуть после рабочего дня, узнать что-то новое, подискутировать, перекусить пиццой и пообщаться с разработчиками.
Встреча пройдёт 26 апреля 2018 19:00-21:00 в московском офисе «Aligh Technology» по адресу Варшавское ш., 9, стр. 4. Регистрация по ссылке: Amazon Web Services и JVM для server side проектов.
В программе три доклада.
Как эффективно разрабатывать Big Data приложения на инфраструктуре Amazon Web Services. Постараемся чтобы локально разрабатывать решение было просто, а интеграционные тесты работали быстро и максимально дешево для нас. Помним об экономии, пока глава Amazon — Джефф Безос запускает ракеты в Blue Origin и гуляет с роботом SpotMini от Boston Dynamics. В докладе расскажу как получилось эмулировать S3 filesystem, Redshift data warehouse, SQS queues, PostgreSQL RDS service в JVM процессе на основе open source проектов. В рамках доклада также будет сравнение популярных Big Data решений для BI аналитики.
Простые, но не очевидные советы для разработчиков по созданию устойчивых и диагностируемых серверных приложений. Доклад будет сфокусирован на основных принципах, поэтому может оказаться полезным разработчикам на разных языках программирования и платформах.
В «облаках» с Groovy на стероидах можно сделать больше и удобнее. Поговорим о динамической загрузке классов из maven артефактов и о том как удобно запускать скрипты в Amazon Web Services и Docker контейнерах. Как выжить скриптам в изолированном корпоративном окружении. И конечно же похоливарим тему зачем нужен Groovy, когда есть Kotlin.
Встреча пройдёт 26 апреля 2018 19:00-21:00 в московском офисе «Aligh Technology» по адресу Варшавское ш., 9, стр. 4. Регистрация по ссылке: Amazon Web Services и JVM для server side проектов.
В программе три доклада.
Эмуляция Amazon web services в JVM процессе: ускоряем разработку, тестирование и экономим деньги.
Спикер: Игорь СухоруковКак эффективно разрабатывать Big Data приложения на инфраструктуре Amazon Web Services. Постараемся чтобы локально разрабатывать решение было просто, а интеграционные тесты работали быстро и максимально дешево для нас. Помним об экономии, пока глава Amazon — Джефф Безос запускает ракеты в Blue Origin и гуляет с роботом SpotMini от Boston Dynamics. В докладе расскажу как получилось эмулировать S3 filesystem, Redshift data warehouse, SQS queues, PostgreSQL RDS service в JVM процессе на основе open source проектов. В рамках доклада также будет сравнение популярных Big Data решений для BI аналитики.
Код для продакшена.
Спикер: Юрий ГеинишПростые, но не очевидные советы для разработчиков по созданию устойчивых и диагностируемых серверных приложений. Доклад будет сфокусирован на основных принципах, поэтому может оказаться полезным разработчикам на разных языках программирования и платформах.
Мельдоний для Groovy: витаем в «облаках» или погружаемся в «кровавый enterprise»
Спикер: Игорь СухоруковВ «облаках» с Groovy на стероидах можно сделать больше и удобнее. Поговорим о динамической загрузке классов из maven артефактов и о том как удобно запускать скрипты в Amazon Web Services и Docker контейнерах. Как выжить скриптам в изолированном корпоративном окружении. И конечно же похоливарим тему зачем нужен Groovy, когда есть Kotlin.














