Совсем недавно был обновлен плагин ml-agents. Для тех кто не знает это плагин с открытым кодом, который является средой для обучения агентов в unity. Их можно обучать с использованием reinforcement learning, imitation learning, neuroevolution или других методов машинного обучения используя Python API. Так же в нем предоставлен ряд современных алгоритмов (основанных TensorSlow), которые позволяют создавать более умных NPC для ваших игр.
Скачать данный плагин можно по ссылке . Вам понадобится папка unity-envonment. Перед этим создайте пустой проект. В папку Assets добавьте содержание папки Assets с unity-envonment. Подобное проделайте с ProjectSettings. Обратите внимание, если вы добавляете данный плагин в уже существующий проект, для начала создайте пустой проект выполните пункты выше описание выше и создайте package (Assets-ExportPackage) и далее просто импортируйте его в свой существующий проект. Это нужно, чтобы вы не потеряли имеющийся настройки ProjectSettings в вашем проекте.
Реализацию машинного обучения я продемонстрирую вам на примере игры футбол (данная сцена уже есть в плагине). В ней есть две команды, синие и красные. У каждой команды есть нападающий и вратарь.

Вернемся к самому плагину. Для того чтобы он работал нам на сцене нужна минимум по одному объекту Academy, Brain и Agent. Схему взаимодействия можно посмотреть ниже
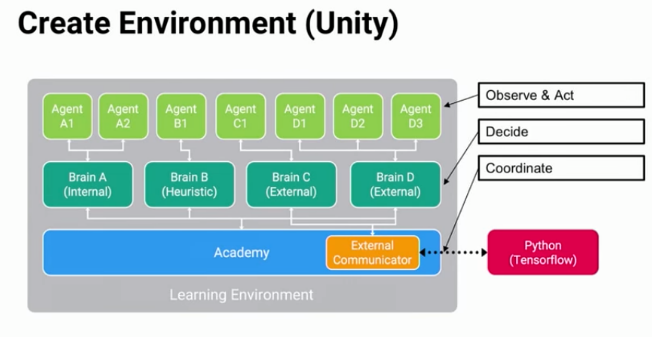
На сцене расположены обьект Academy и дочерние ему GoalieBrain, StrikerBrain. Как мы можем заметить со схемы, у каждой Academy может быть несколько Brain, но у каждого Brain должна быть одна Academy.
Agent — это наши игровые обькты, которые мы хотим обучить

Далее переходим к коду. Класс SoccerAcademy, который добавлен на GameObject Academy наследуеться от класса Academy, перед этим стоит добавить пространтсво имен using MLAgents. После этого нам стоит переопределить методы
И добавить ссылки на созданные Brain
Добавляем компонент Brain на GoalieBrain, StrikerBrain и присваиваем их в Academy
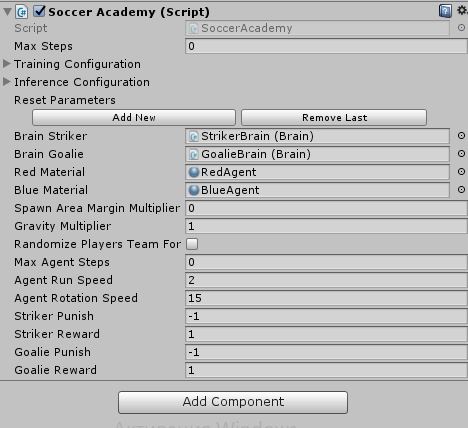
Класс AgentSoccer наследуется от Soccer. Добавляем его на каждого игрока и указывам какой Brain будет использоваться.
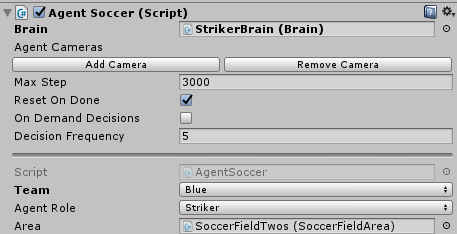
В скрипте AgentSoccer мы опишем логику игроков. В переопределенном методе CollectObservations() мы добавляем список лучей, которые помогут игрокам следить за игровым процессом и реагировать на них.
Переопределенный метод AgentAction, это некий аналог Update. В нем мы вызываем метод перемещения и расспределяем награды.
Если соприкасаемся с мячом, толкаем его
Сбрасываем команды, когда цель выполнена
Обучать агентов можно как с редактора unity, так с помощью TensorFlow. Что касается unity, то вам нужно в Academy указать наказание и и награду для каждого Brain.
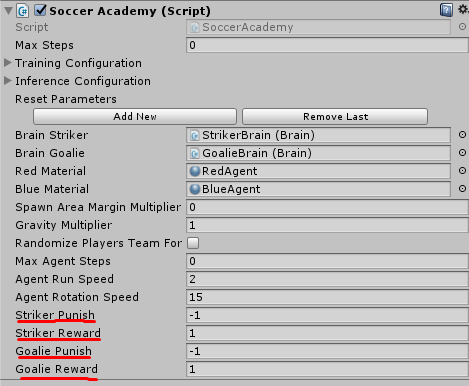
Так же стоит указать Brain его TypeBrain установив значение External. Они так же бывают следующих типов:
Что вам нужно чтобы внедрить машинное обучение в Unity?
Скачать данный плагин можно по ссылке . Вам понадобится папка unity-envonment. Перед этим создайте пустой проект. В папку Assets добавьте содержание папки Assets с unity-envonment. Подобное проделайте с ProjectSettings. Обратите внимание, если вы добавляете данный плагин в уже существующий проект, для начала создайте пустой проект выполните пункты выше описание выше и создайте package (Assets-ExportPackage) и далее просто импортируйте его в свой существующий проект. Это нужно, чтобы вы не потеряли имеющийся настройки ProjectSettings в вашем проекте.
Реализацию машинного обучения я продемонстрирую вам на примере игры футбол (данная сцена уже есть в плагине). В ней есть две команды, синие и красные. У каждой команды есть нападающий и вратарь.
Вернемся к самому плагину. Для того чтобы он работал нам на сцене нужна минимум по одному объекту Academy, Brain и Agent. Схему взаимодействия можно посмотреть ниже
На сцене расположены обьект Academy и дочерние ему GoalieBrain, StrikerBrain. Как мы можем заметить со схемы, у каждой Academy может быть несколько Brain, но у каждого Brain должна быть одна Academy.
Agent — это наши игровые обькты, которые мы хотим обучить
Далее переходим к коду. Класс SoccerAcademy, который добавлен на GameObject Academy наследуеться от класса Academy, перед этим стоит добавить пространтсво имен using MLAgents. После этого нам стоит переопределить методы
public override void AcademyReset() { } public override void AcademyStep() { }
И добавить ссылки на созданные Brain
public Brain brainStriker; public Brain brainGoalie;
Добавляем компонент Brain на GoalieBrain, StrikerBrain и присваиваем их в Academy
Класс AgentSoccer наследуется от Soccer. Добавляем его на каждого игрока и указывам какой Brain будет использоваться.
В скрипте AgentSoccer мы опишем логику игроков. В переопределенном методе CollectObservations() мы добавляем список лучей, которые помогут игрокам следить за игровым процессом и реагировать на них.
public override void CollectObservations() { float rayDistance = 20f; float[] rayAngles = { 0f, 45f, 90f, 135f, 180f, 110f, 70f }; string[] detectableObjects; if (team == Team.red) { detectableObjects = new string[] { "ball", "redGoal", "blueGoal", "wall", "redAgent", "blueAgent" }; } else { detectableObjects = new string[] { "ball", "blueGoal", "redGoal", "wall", "blueAgent", "redAgent" }; } AddVectorObs(rayPer.Perceive(rayDistance, rayAngles, detectableObjects, 0f, 0f)); AddVectorObs(rayPer.Perceive(rayDistance, rayAngles, detectableObjects, 1f, 0f)); }
Переопределенный метод AgentAction, это некий аналог Update. В нем мы вызываем метод перемещения и расспределяем награды.
public override void AgentAction(float[] vectorAction, string textAction) { // Existential penalty for strikers. if (agentRole == AgentRole.striker) { AddReward(-1f / 3000f); } // Existential bonus for goalies. if (agentRole == AgentRole.goalie) { AddReward(1f / 3000f); } MoveAgent(vectorAction); }
Если соприкасаемся с мячом, толкаем его
void OnCollisionEnter(Collision c) { float force = 2000f * kickPower; if (c.gameObject.tag == "ball") { Vector3 dir = c.contacts[0].point - transform.position; dir = dir.normalized; c.gameObject.GetComponent<Rigidbody>().AddForce(dir * force); } }
Сбрасываем команды, когда цель выполнена
public override void AgentReset() { if (academy.randomizePlayersTeamForTraining) { ChooseRandomTeam(); } if (team == Team.red) { JoinRedTeam(agentRole); transform.rotation = Quaternion.Euler(0f, -90f, 0f); } else { JoinBlueTeam(agentRole); transform.rotation = Quaternion.Euler(0f, 90f, 0f); } transform.position = area.GetRandomSpawnPos(team.ToString(), agentRole.ToString()); agentRB.velocity = Vector3.zero; agentRB.angularVelocity = Vector3.zero; area.ResetBall(); }
Варианты обучения
Обучать агентов можно как с редактора unity, так с помощью TensorFlow. Что касается unity, то вам нужно в Academy указать наказание и и награду для каждого Brain.
Так же стоит указать Brain его TypeBrain установив значение External. Они так же бывают следующих типов:
- External — где решения принимаются с использованием API Python. Здесь наблюдения и награды, генерируемые Brain, перенаправляются в API Python через внешний коммуникатор. Затем API-интерфейс Python возвращает соответствующее действие, которое должен выполнить агент..
- Internal — где решения принимаются с использованием встроенной модели TensorFlow. Вложенная модель TensorFlow представляет собой научную политику, и Brain напрямую использует эту модель для определения действия для каждого Агента.
- Player — где решения принимаются с использованием реального ввода с клавиатуры или контроллера. Здесь игрок-человек контролирует Агента, а наблюдения и награды, собранные Мозгом, не используются для управления Агентом.
- Heuristic — где решения принимаются с использованием жестко кодированного поведения. Это похоже на то, как в настоящее время определено большинство поведения персонажей и может быть полезно для отладки или сравнения того, как Агент с жестко закодированными правилами сравнивается с Агентом, чье поведение было обучено.

