Большую часть своей веб-карьеры я работал исключительно на стороне клиента. Проектирование адаптивных макетов, создание визуализаций из больших объемов данных, создание инструментальных панелей приложений и т. Д. Но мне никогда не приходилось иметь дело с маршрутизацией или HTTP-запросами напрямую. До не давнего времени.
Этот пост представляет собой описание того, как я узнал больше о веб-разработке на стороне сервера с помощью Node.js, и краткое сравнение написания простого HTTP-сервера с использованием 3 разных сред, Express, Koa.js и Hapi.js.
Примечание: если вы опытный разработчик Node.js, вы, вероятно, подумаете о том, что это все элементарно/просто. ¯\_(ツ)_/¯.
Когда я начал работать в веб-индустрии пару лет назад, я наткнулся на курс по компьютерным сетям профессора Дэвида Ветерала на Coursera. К сожалению, он больше не доступен, но лекции по-прежнему доступны на веб-сайте Pearson.
Мне очень понравился этот курс, потому что он объяснял, что происходило под капотом, в понятной форме, поэтому, если вы можете взять в руки учебник «Компьютерные сети», прочитайте все подробности о чудесах сети.

Здесь, однако, я собираюсь лишь кратко рассказать о контексте. HTTP (Hypertext Transfer Protocol) — это протокол связи, используемый в компьютерных сетях. В Интернете их много, таких как SMTP (простой протокол передачи почты), FTP (протокол передачи файлов), POP3 (протокол почтового отделения 3) и так далее.
Эти протоколы позволяют устройствам с совершенно разным аппаратным / программным обеспечением связываться друг с другом, поскольку они предоставляют четко определенные форматы сообщений, правила, синтаксис и семантику и т.д. Это означает, что, пока устройство поддерживает определенный протокол, оно может связываться с любым другим устройством. в сети.

От TCP / IP против OSI: в чем разница между двумя моделями?
Операционные системы обычно поставляются с поддержкой сетевых протоколов, таких как HTTP, из коробки, что объясняет, почему нам не нужно явно устанавливать какое-либо дополнительное программное обеспечение для доступа в Интернет. Большинство сетевых протоколов поддерживают открытое соединение между двумя устройствами, что позволяет им передавать данные туда и обратно.
HTTP, на котором работает сеть, отличается. Он известен как протокол без установления соединения, потому что он основан на режиме работы запрос / ответ. Веб-браузеры отправляют на сервер запросы на изображения, шрифты, контент и т.д., но после выполнения запроса соединение между браузером и сервером разрывается.

Термин сервер может слегка сбивать с толку людей, впервые знакомых с отраслью, поскольку он может относиться как к аппаратному обеспечению (физические компьютеры, на которых размещены все файлы и программное обеспечение, требуемое веб-сайтами), так и к программному обеспечению (программе, которая позволяет пользователям получать доступ к этим файлам в Интернете).
Сегодня мы поговорим о программной стороне вещей. Но сначала несколько определений. URL обозначает Universal Resource Locator и состоит из 3 частей: протокола, сервера и запрашиваемого файла.
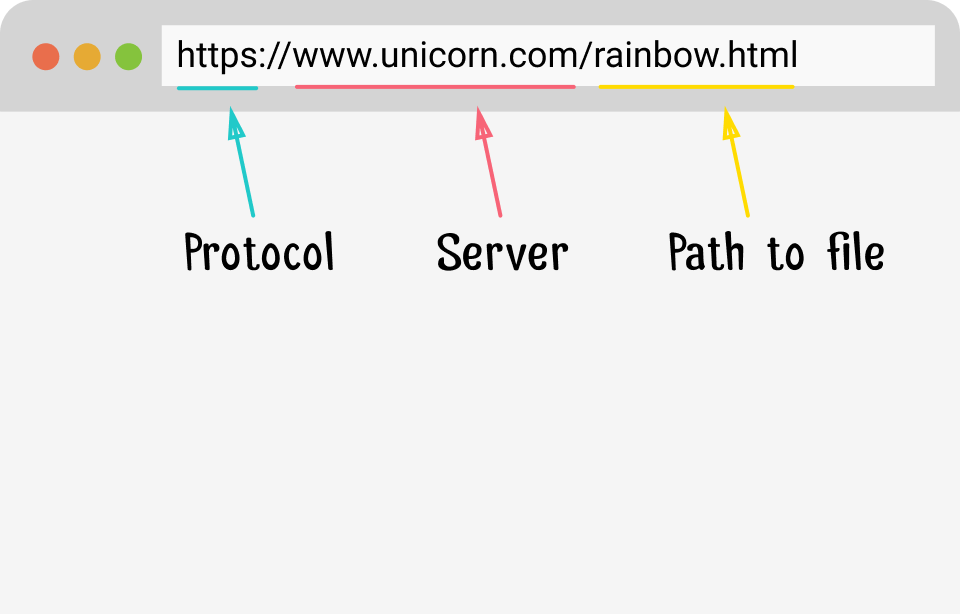
Структура URL адреса
Протокол HTTP определяет несколько методов, которые браузер может использовать, чтобы попросить сервер выполнить кучу различных действий, наиболее распространенными из которых являются GET и POST. Когда пользователь щелкает ссылку или вводит URL-адрес в адресную строку, браузер отправляет GET-запрос на сервер для получения ресурса, определенного в URL-адресе.
Сервер должен знать, как обрабатывать этот HTTP-запрос, чтобы получить правильный файл, а затем отправить его обратно браузеру, который его запросил. Наиболее популярное программное обеспечение веб-сервера, которое обрабатывает это Apache и NGINX.

Веб-серверы обрабатывают входящие запросы и отвечают на них соответственно
Оба представляют собой полнофункциональные пакеты программного обеспечения с открытым исходным кодом, которые включают в себя такие функции, как схемы аутентификации, перезапись URL-адресов, ведение журнала и проксирование, и это лишь некоторые из них. Apache и NGINX написаны на C. Технически, вы можете написать веб-сервер на любом языке. Python, golang.org/pkg/net/http, Ruby, этот список может продолжаться довольно долго. Просто некоторые языки лучше выполняют определенные вещи, чем другие.
Node.js — это среда выполнения Javascript, построенная на движке Chrome V8 Javascript. Он поставляется с модулем http, который предоставляет набор функций и классов для построения HTTP-сервера.
Для этого базового HTTP-сервера мы также будем использовать файловую систему, путь и URL-адрес, которые являются собственными модулями Node.js.
Начните с импорта необходимых модулей.
Мы также создадим словарь типов MIME, чтобы мы могли назначить соответствующий тип MIME запрашиваемому ресурсу на основе его расширения. Полный список типов MIME можно найти в Internet Assigned Numbers Authority (интернет-центре назначенных номеров).
Теперь мы можем создать HTTP-сервер с функцией
Мы передадим функцию-обработчик запроса в
Сервер запускается путем вызова метода
Объект
Объект
В обработчике запросов мы хотим сделать следующее:
Весь код размещен на Glitch, и вы можете сделать ремикс на проект, если хотите.
https://glitch.com/edit/#!/node-http
Фреймворки Node.js, такие как Express, Koa.js и Hapi.js, поставляются с различными полезными функциями промежуточного программного обеспечения, в дополнение к множеству других удобных функций, которые избавляют разработчиков от необходимости писать самим.
Лично я чувствую, что лучше сначала изучать основы без фреймворков, просто для понимания того, что происходит под капотом, а затем после этого сходить с ума с любым фреймворком, который вам нравится.
В Express имеется собственный встроенный плагин для обслуживания статических файлов, поэтому код, необходимый для выполнения тех же действий, что и в собственном Node.js, значительно короче.
Koa.js не имеет подобного плагина внутри своего ядра, поэтому любой требуемый плагин должен быть установлен отдельно. Последняя версия Koa.js использует асинхронные функции в пользу обратных вызовов. Для обслуживания статических файлов вы можете использовать плагин
Hapi.js поддерживает настройку и вращается вокруг настройки объекта
У каждой из этих платформ есть свои плюсы и минусы, и они будут более очевидными для более крупных приложений, а не просто для обслуживания одной HTML-страницы. Выбор структуры будет сильно зависеть от реальных требований проекта, над которым вы работаете.
Если сетевая сторона вещей всегда была для вас черным ящиком, надеюсь, эта статья может послужить полезным введением в протокол, который обеспечивает работу сети. Я также настоятельно рекомендую прочитать документацию по API Node.js, которая очень хорошо написана и очень полезна для любого новичка в Node.js в целом.
Этот пост представляет собой описание того, как я узнал больше о веб-разработке на стороне сервера с помощью Node.js, и краткое сравнение написания простого HTTP-сервера с использованием 3 разных сред, Express, Koa.js и Hapi.js.
Примечание: если вы опытный разработчик Node.js, вы, вероятно, подумаете о том, что это все элементарно/просто. ¯\_(ツ)_/¯.
Некоторые основы сети
Когда я начал работать в веб-индустрии пару лет назад, я наткнулся на курс по компьютерным сетям профессора Дэвида Ветерала на Coursera. К сожалению, он больше не доступен, но лекции по-прежнему доступны на веб-сайте Pearson.
Мне очень понравился этот курс, потому что он объяснял, что происходило под капотом, в понятной форме, поэтому, если вы можете взять в руки учебник «Компьютерные сети», прочитайте все подробности о чудесах сети.

Здесь, однако, я собираюсь лишь кратко рассказать о контексте. HTTP (Hypertext Transfer Protocol) — это протокол связи, используемый в компьютерных сетях. В Интернете их много, таких как SMTP (простой протокол передачи почты), FTP (протокол передачи файлов), POP3 (протокол почтового отделения 3) и так далее.
Эти протоколы позволяют устройствам с совершенно разным аппаратным / программным обеспечением связываться друг с другом, поскольку они предоставляют четко определенные форматы сообщений, правила, синтаксис и семантику и т.д. Это означает, что, пока устройство поддерживает определенный протокол, оно может связываться с любым другим устройством. в сети.
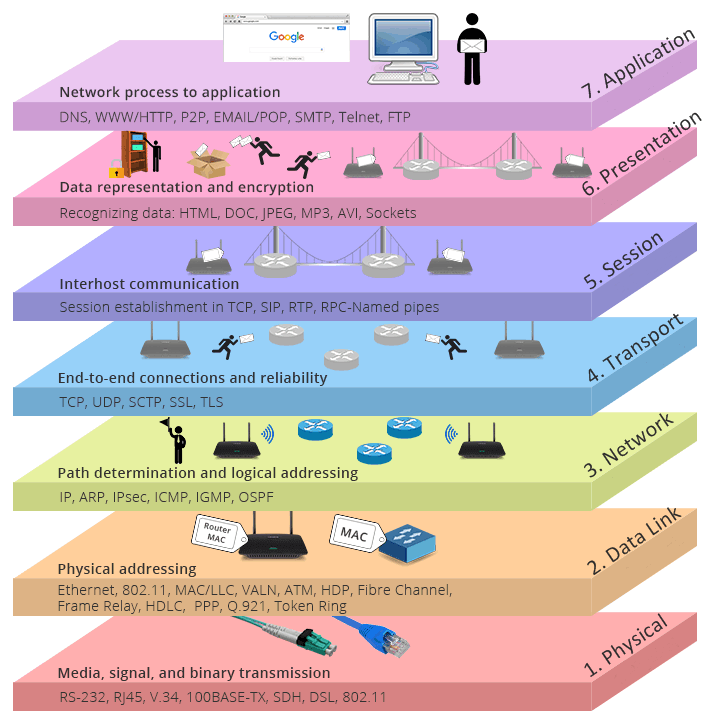
От TCP / IP против OSI: в чем разница между двумя моделями?
Операционные системы обычно поставляются с поддержкой сетевых протоколов, таких как HTTP, из коробки, что объясняет, почему нам не нужно явно устанавливать какое-либо дополнительное программное обеспечение для доступа в Интернет. Большинство сетевых протоколов поддерживают открытое соединение между двумя устройствами, что позволяет им передавать данные туда и обратно.
HTTP, на котором работает сеть, отличается. Он известен как протокол без установления соединения, потому что он основан на режиме работы запрос / ответ. Веб-браузеры отправляют на сервер запросы на изображения, шрифты, контент и т.д., но после выполнения запроса соединение между браузером и сервером разрывается.
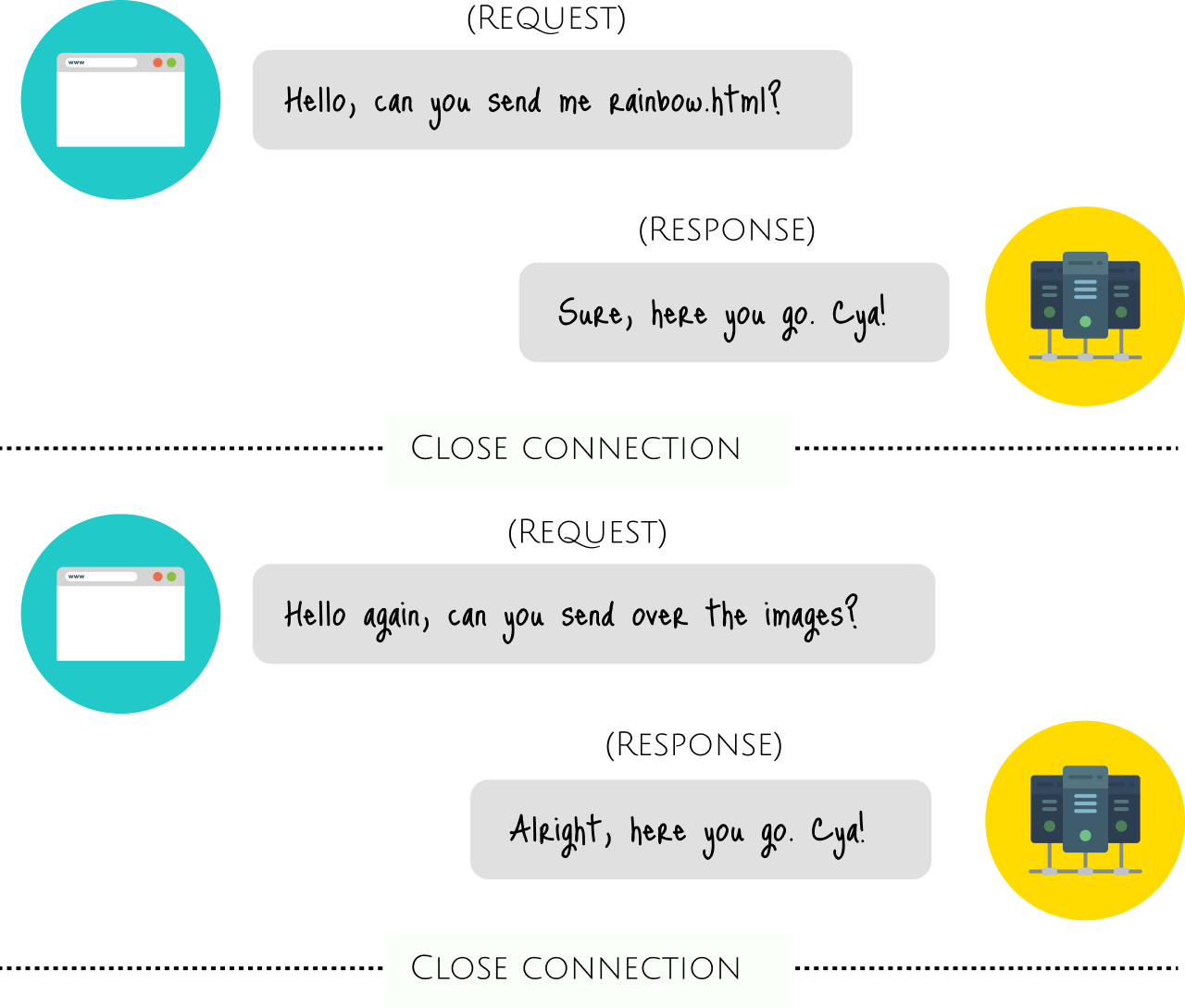
Servers and Clients
Термин сервер может слегка сбивать с толку людей, впервые знакомых с отраслью, поскольку он может относиться как к аппаратному обеспечению (физические компьютеры, на которых размещены все файлы и программное обеспечение, требуемое веб-сайтами), так и к программному обеспечению (программе, которая позволяет пользователям получать доступ к этим файлам в Интернете).
Сегодня мы поговорим о программной стороне вещей. Но сначала несколько определений. URL обозначает Universal Resource Locator и состоит из 3 частей: протокола, сервера и запрашиваемого файла.
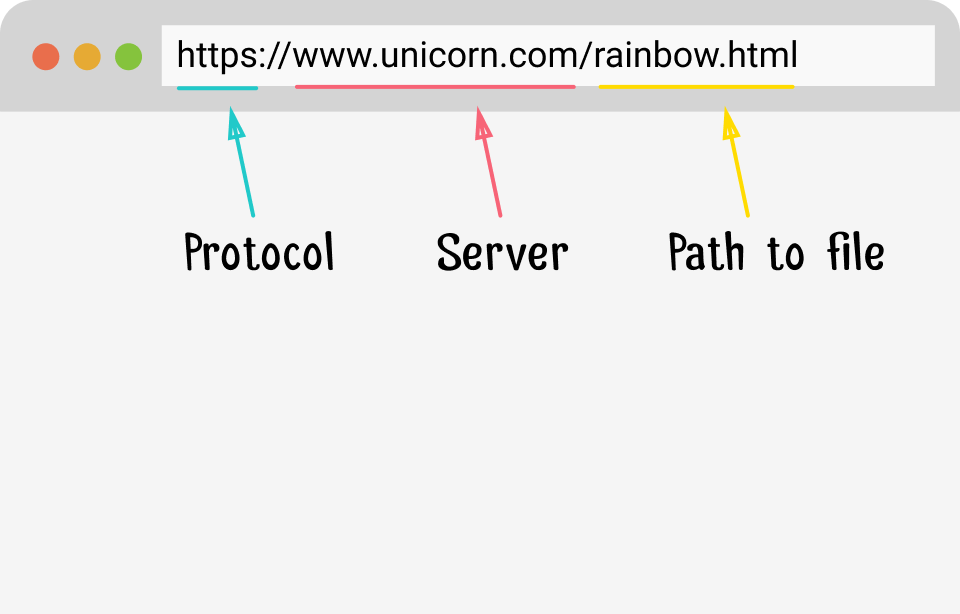
Структура URL адреса
Протокол HTTP определяет несколько методов, которые браузер может использовать, чтобы попросить сервер выполнить кучу различных действий, наиболее распространенными из которых являются GET и POST. Когда пользователь щелкает ссылку или вводит URL-адрес в адресную строку, браузер отправляет GET-запрос на сервер для получения ресурса, определенного в URL-адресе.
Сервер должен знать, как обрабатывать этот HTTP-запрос, чтобы получить правильный файл, а затем отправить его обратно браузеру, который его запросил. Наиболее популярное программное обеспечение веб-сервера, которое обрабатывает это Apache и NGINX.

Веб-серверы обрабатывают входящие запросы и отвечают на них соответственно
Оба представляют собой полнофункциональные пакеты программного обеспечения с открытым исходным кодом, которые включают в себя такие функции, как схемы аутентификации, перезапись URL-адресов, ведение журнала и проксирование, и это лишь некоторые из них. Apache и NGINX написаны на C. Технически, вы можете написать веб-сервер на любом языке. Python, golang.org/pkg/net/http, Ruby, этот список может продолжаться довольно долго. Просто некоторые языки лучше выполняют определенные вещи, чем другие.
Создание HTTP сервера с Node.js
Node.js — это среда выполнения Javascript, построенная на движке Chrome V8 Javascript. Он поставляется с модулем http, который предоставляет набор функций и классов для построения HTTP-сервера.
Для этого базового HTTP-сервера мы также будем использовать файловую систему, путь и URL-адрес, которые являются собственными модулями Node.js.
Начните с импорта необходимых модулей.
const http = require('http') // Чтобы использовать HTTP-интерфейсы в Node.js
const fs = require('fs') // Для взаимодействия с файловой системой
const path = require('path') // Для работы с путями файлов и каталогов
const url = require('url') // Для разрешения и разбора URL
Мы также создадим словарь типов MIME, чтобы мы могли назначить соответствующий тип MIME запрашиваемому ресурсу на основе его расширения. Полный список типов MIME можно найти в Internet Assigned Numbers Authority (интернет-центре назначенных номеров).
const mimeTypes = {
'.html': 'text/html',
'.js': 'text/javascript',
'.css': 'text/css',
'.ico': 'image/x-icon',
'.png': 'image/png',
'.jpg': 'image/jpeg',
'.gif': 'image/gif',
'.svg': 'image/svg+xml',
'.json': 'application/json',
'.woff': 'font/woff',
'.woff2': 'font/woff2'
}
Теперь мы можем создать HTTP-сервер с функцией
http.createServer(), которая будет возвращать новый экземпляр http.Server.const server = http.createServer()Мы передадим функцию-обработчик запроса в
createServer() с объектами запроса и ответа. Эта функция вызывается один раз каждый раз, когда к серверу поступает HTTP-запрос.server.on('request', (req, res) => {
// здесь нужно сделать больше
})
Сервер запускается путем вызова метода
listen объекта server с номером порта, который мы хотим, чтобы сервер прослушивал, например, 5000.server.listen(5000)Объект
request является экземпляром IncomingMessage и позволяет нам получать доступ ко всей информации о запросе, такой как статус ответа, заголовки и данные.Объект
response является экземпляром ServerResponse, который является записываемым потоком и предоставляет множество методов для отправки данных обратно клиенту.В обработчике запросов мы хотим сделать следующее:
- Разобрать входящий запрос и обработать его без расширений
const parsedUrl = new URL(req.url, 'https://node-http.glitch.me/') let pathName = parsedUrl.pathname let ext = path.extname(pathName) // Для обработки URL с конечным символом '/', удаляем вышеупомянутый '/' // затем перенаправляем пользователя на этот URL с помощью заголовка 'Location' if (pathName !== '/' && pathName[pathName.length - 1] === '/') { res.writeHead(302, {'Location': pathName.slice(0, -1)}) res.end() return } // Если запрос для корневого каталога, вернуть index.html // В противном случае добавляем «.html» к любому другому запросу без расширения if (pathName === '/') { ext = '.html' pathName = '/index.html' } else if (!ext) { ext = '.html' pathName += ext }
- Выполните некоторые элементарные проверки, чтобы определить, существует ли запрошенный ресурс, и ответить соответственно
// Создаем правильный путь к файлу, чтобы получить доступ к соответствующим ресурсам const filePath = path.join(process.cwd(), '/public', pathName) // Проверяем, существует ли запрошенный ресурс на сервере fs.exists(filePath, function (exists, err) { // Если запрошенный ресурс не существует, ответим 404 Not Found if (!exists || !mimeTypes[ext]) { console.log('Файл не найден: ' + pathName) res.writeHead(404, {'Content-Type': 'text/plain'}) res.write('404 Not Found') res.end() return } // В противном случае отправим ответ со статусом 200 OK, // и добавляем правильный заголовок типа контента res.writeHead(200, {'Content-Type': mimeTypes[ext]}) // Считать файл и передать его в ответ const fileStream = fs.createReadStream(filePath) fileStream.pipe(res) })
Весь код размещен на Glitch, и вы можете сделать ремикс на проект, если хотите.
https://glitch.com/edit/#!/node-http
Создание HTTP-сервера с фреймворками Node.js
Фреймворки Node.js, такие как Express, Koa.js и Hapi.js, поставляются с различными полезными функциями промежуточного программного обеспечения, в дополнение к множеству других удобных функций, которые избавляют разработчиков от необходимости писать самим.
Лично я чувствую, что лучше сначала изучать основы без фреймворков, просто для понимания того, что происходит под капотом, а затем после этого сходить с ума с любым фреймворком, который вам нравится.
В Express имеется собственный встроенный плагин для обслуживания статических файлов, поэтому код, необходимый для выполнения тех же действий, что и в собственном Node.js, значительно короче.
const express = require('express')
const app = express()
// Укажем директорию в которой будут лежать наши файлы
app.use(express.static('public'))
// Отправляем index.html, когда пользователи получают доступ к
// корневому каталог с использованием res.sendFile()
app.get('/', (req, res) => {
res.sendFile(__dirname + '/public/index.html')
})
app.listen(5000)Koa.js не имеет подобного плагина внутри своего ядра, поэтому любой требуемый плагин должен быть установлен отдельно. Последняя версия Koa.js использует асинхронные функции в пользу обратных вызовов. Для обслуживания статических файлов вы можете использовать плагин
koa-static.const serve = require('koa-static')
const koa = require('koa')
const app = new koa()
// Укажем директорию в которой будут лежать наши файлы
// По умолчанию koa-static будет обслуживать файл index.html в корневом каталоге
app.use(serve(__dirname + '/public'))
app.listen(5000)Hapi.js поддерживает настройку и вращается вокруг настройки объекта
server. Он использует плагины для расширения возможностей, таких как маршрутизация, аутентификация и так далее. Для обслуживания статических файлов нам понадобится плагин с именем inert.const path = require('path')
const hapi = require('hapi')
const inert = require('inert')
// Маршруты могут быть настроены на объекте сервера
const server = new hapi.Server({
port: 5000,
routes: {
files: {
relativeTo: path.join(__dirname, 'public')
}
}
})
const init = async () => {
// server.register() команда добавляет плагин в приложение
await server.register(inert)
// inert добавляет обработчик каталога в
// указатель маршрута для обслуживания нескольких файлов
server.route({
method: 'GET',
path: '/{param*}',
handler: {
directory: {
path: '.',
redirectToSlash: true,
index: true
}
}
})
await server.start()
}
init()У каждой из этих платформ есть свои плюсы и минусы, и они будут более очевидными для более крупных приложений, а не просто для обслуживания одной HTML-страницы. Выбор структуры будет сильно зависеть от реальных требований проекта, над которым вы работаете.
Завершение
Если сетевая сторона вещей всегда была для вас черным ящиком, надеюсь, эта статья может послужить полезным введением в протокол, который обеспечивает работу сети. Я также настоятельно рекомендую прочитать документацию по API Node.js, которая очень хорошо написана и очень полезна для любого новичка в Node.js в целом.









