
Усовершенствования в скорости работы ЦП замедляются, и мы наблюдаем, как полупроводниковая индустрия переходит на карточки ускорителей, чтобы результаты продолжали заметно улучшаться. Больше всего выгоды от этого перехода получила Nvidia, однако, это часть одной и той же тенденции, питающей исследования в области ускорителей нейросетей, FPGA, и таких продуктов, как TPU от Google. Эти ускорители невероятно увеличили быстродействие электроники в последние годы, и многие начали надеяться, что они представляют собой новый путь развития, в связи с подтормаживанием закона Мура. Но новая научная работа высказывает предположение, что на самом деле всё не так радужно, как хотелось бы некоторым.
Такие специальные архитектуры, как GPU, TPU, FPGA и ASIC если даже и работают совсем не так, как CPU общего назначения, то всё равно используют те же функциональные узлы, что и процессоры x86, ARM или POWER. А это значит, что увеличение быстродействия этих ускорителей тоже в какой-то мере зависит от улучшений, связанных с масштабированием транзисторов. Но какая доля этих улучшений зависела от улучшения технологий производства и увеличения плотности, связанной с законом Мура, а какая – от улучшений в целевых областях, для которых предназначены эти процессоры? Какая доля улучшений связана только с транзисторами?
Адъюнкт-профессор по электротехнике Принстонского университета Дэвид Венцлаф и его аспирант Ади Фукс создали модель, позволяющую им измерять скорость улучшений. Их модель использует характеристики 1612 CPU и 1001 GPU различной мощности, выполненных на основе различных функциональных узлов, чтобы численно оценить преимущества, связанные с улучшениями узлов. Венцлаф и Фукс создали метрику улучшения эффективности, связанного с прогрессом в области CMOS (CMOS-Driven return, CDR), которую можно сравнить с улучшениями, приобретённым за счёт специализации чипов (Chip Specialization Return, CSR).

Команда пришла к обескураживающему выводу. Преимущества, полученные за счёт специализации чипов, фундаментально связаны с количеством транзисторов, помещающихся в миллиметре кремния в долгосрочной перспективе, а также с улучшениями этих транзисторов, связанными с каждым новым функциональным узлом. Что хуже, существуют фундаментальные ограничения того, сколько быстродействия мы можем извлечь из улучшения схемы ускорителя, не улучшая масштаб CMOS.
Важно, что всё перечисленное действует на долгосрочной перспективе. Исследование Венцлафа и Фукса показывает, что быстродействие нередко резко повышается при первоначальном вводе в строй ускорителей. Со временем, когда методы оптимального ускорения оказываются изученными, а лучшие практики описанными, исследователи выходят на самый оптимальный подход. Причём на ускорителях хорошо решаются хорошо определённые задачи из хорошо изученной области, которые можно распараллелить (GPU). Однако это же означает, что те же самые свойства, благодаря которым задачу можно приспособить под ускорители, ограничивают преимущество, полученное от этого ускорения в долгосрочной перспективе. Команда назвала эту проблему «тупиком ускорителей».
И рынок высокопроизводительных вычислений, вероятно, уже какое-то время ощущал это на себе. В 2013-м мы писали о трудной дороге к суперкомпьютерам экза-масштабов. И даже тогда Top500 предсказывал, что ускорители дадут единовременный скачок в рейтингах быстродействия, но не увеличат скорость увеличения быстродействия.

Однако последствия этих открытий выходят за рамки рынка высокопроизводительных вычислений. К примеру, изучив GPU, Венцлаф и Фукс обнаружили, что преимущества, которые нельзя отнести на счёт улучшения CMOS, были весьма малы.

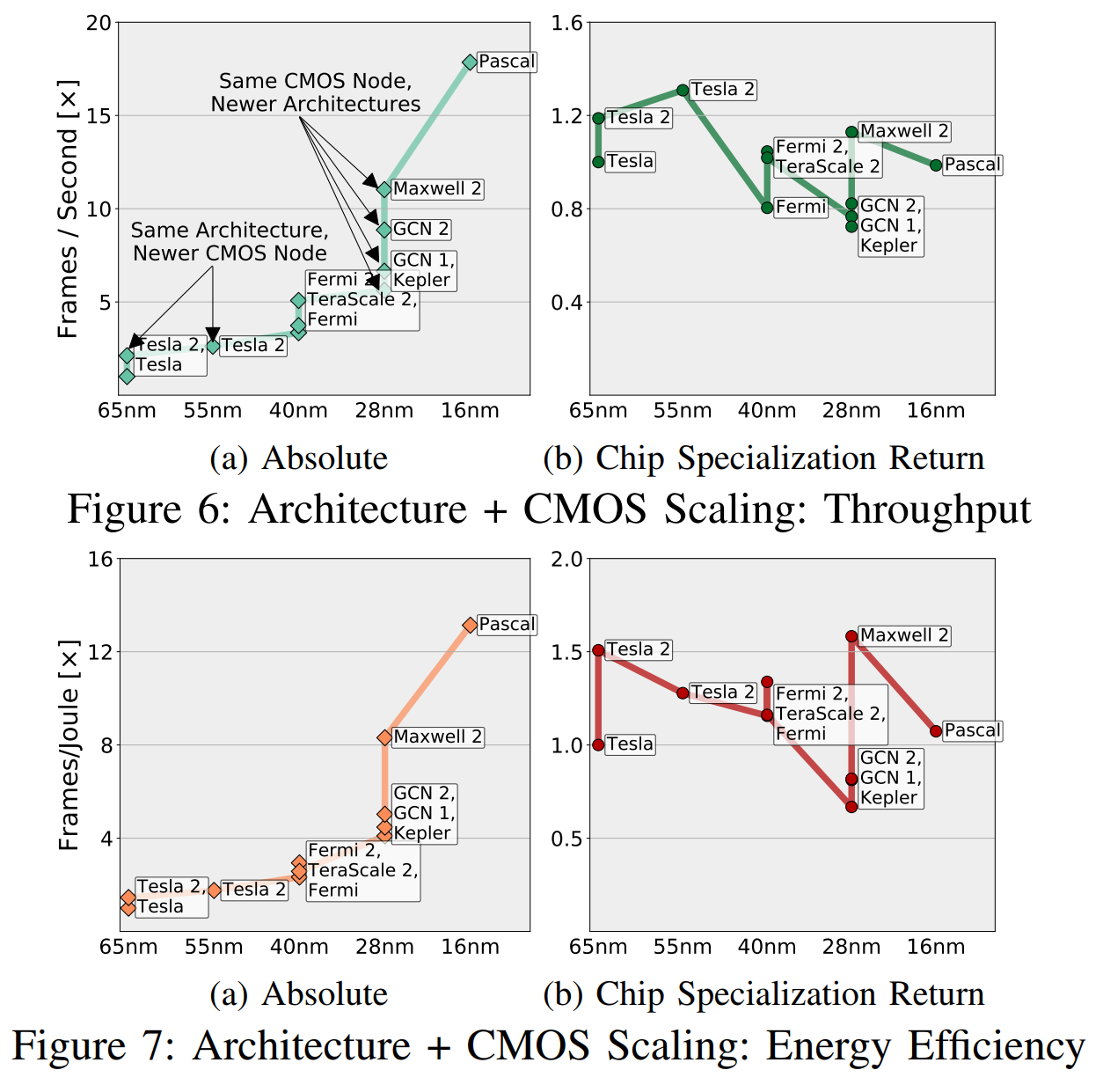
На рис. показан рост абсолютного быстродействия GPU (включая и преимущества, полученные от развития CMOS), и эти преимущества появились исключительно благодаря развитию CSR. CSR – это приблизительно те улучшения, которые остаются, если убрать из схемы GPU все прорывы в технологии CMOS.
Следующий рисунок проясняет взаимоотношение величин:
Уменьшение CSR не означает замедления GPU в абсолютных цифрах. Как писал Фукс:
CSR нормализует прибыль «в расчёте на потенциал CMOS», и этот «потенциал» учитывает количество транзисторов и разницу в скорости, эффективность по использованию энергии, площади и т.п. (в разных поколениях CMOS). На рис. 6 мы привели примерное сравнение комбинаций «архитектура + узлы CMOS», путём триангуляции измеренных скоростей всех приложений на разных комбинациях, и применяя транзитивные взаимоотношения между теми комбинациями, у которых нет достаточного количества общих приложений (менее пяти).
Интуитивно эти графики можно понять так, что на рис. 6а изображено то, «что видят инженеры и менеджеры», а на рис. 6b – то, «что мы видим, исключая потенциал CMOS». Рискну предположить, что вас больше волнует то, опережает ли ваш новый чип предыдущий, чем то, делает он это из-за лучших транзисторов или из-за лучшей специализации.
Рынок GPU хорошо определён, оформлен и специализирован, и как у AMD, так и у Nvidia есть все поводы опережать друг друга, улучшая схемы. Но, несмотря на это мы видим, что по большей части ускорения идут благодаря факторам, связанным с CMOS, а не из-за CSR.
FPGA и специальные платы для обработки видеокодеков, исследованные учёными, также попадают под такие характеристики, даже если относительное улучшение со временем становилось больше или меньше из-за взросления рынка. То же самые характеристики, что позволяют активно реагировать на ускорение, в итоге ограничивают возможности ускорителей улучшить свою эффективность. Про GPU Фукс и Венцлаф пишут: «Хотя частота кадров GPU-графики увеличилась в 16 раз, мы предполагаем, что далее последуют улучшения по быстродействию и энергоэффективности в 1,4-2,4 раз и 1,4-1,7 раз соответственно». Особого пространства для манёвра, в котором можно увеличить быстродействие, улучшая CMOS, у AMD и Nvidia не остаётся.
Последствия данной работы важны. Она говорит о том, что специфичные для своих областей архитектуры уже не будут давать значительных улучшений по быстродействию, когда закон Мура перестанет работать. И даже если разработчики чипов могут сконцентрироваться на улучшении быстродействия в условиях фиксированного количества транзисторов, эти улучшения будут ограничены тем, что хорошо изученные процессы уже почти некуда улучшать.
Работа указывает на необходимость разработки фундаментально нового подхода к вычислениям. Одна из потенциальных альтернатив — архитектура Intel Meso. Фукс и Венцлаф также предложили использовать альтернативные материалы и другие решения, выходящие за рамки CMOS, включая исследования возможности использования в качестве ускорителей энергонезависимой памяти.

