Продолжение перевода небольшой книги:
«Understanding Message Brokers»,
автор: Jakub Korab, издательство: O'Reilly Media, Inc., дата издания: June 2017, ISBN: 9781492049296.
Предыдущая часть: Понимание брокеров сообщений. Изучение механики обмена сообщениями посредством ActiveMQ и Kafka. Глава 1. Введение
ActiveMQ лучше всего описать, как классическую систему обмена сообщениями. Она была написана в 2004 году, восполняя потребность в брокере сообщений с открытым исходным кодом. В то время, если вы хотели использовать обмен сообщениями в своих приложениях, единственным выбором были дорогие коммерческие продукты.
ActiveMQ была разработана как реализация спецификации Java Message Service (JMS). Это решение было принято, чтобы удовлетворить требования к реализации JMS-совместимого обмена сообщениями в проекте Apache Geronimo — сервере приложений J2EE с открытым исходным кодом.
Система обмена сообщениями (или промежуточное ПО, ориентированное на сообщения, как ее иногда называют), реализующая спецификацию JMS, состоит из следующих компонентов:
Брокер
Центральная часть промежуточного программного обеспечения, распределяющая сообщения.
Клиент
Часть программного обеспечения, которая перебрасывает сообщения с помощью брокера. Она, в свою очередь, состоит из следующих артефактов:
Клиент и брокер общаются друг с другом через протокол прикладного уровня, также известный, как протокол взаимодействия (Figure. 2-1). Спецификация JMS оставила детали этого протокола конкретным реализациям.

Figure 2-1. Обзор JMS
JMS использует термин провайдер для описания реализации вендором системы обмена сообщениями, лежащей в основе API JMS, которая включает брокер, а также ее клиентские библиотеки.
Выбор в пользу внедрения JMS имел далеко идущие последствия для имплементационных решений, принятых авторами ActiveMQ. В самой спецификации изложены четкие указания по обязанностям клиента системы обмена сообщениями и брокера, с которым он общается, отдавая предпочтение обязательству брокера распределять и доставлять сообщения. Основная обязанность клиента — взаимодействовать с адресатом (очередью или топиком) отправляемых им сообщений. Сама спецификация направлена на то, чтобы сделать взаимодействие API с брокером относительно простым.
Это направление, как мы увидим позже, сильно повлияло на производительность ActiveMQ. В дополнение к сложностям брокера, пакет совместимости для спецификации, предоставленной Sun Microsystems, имел множество нюансов, с их собственным влиянием на производительность. Данные нюансы должны были все быть учтены, чтобы ActiveMQ считалась совместимой с JMS.
Хотя API и ожидаемое поведение были хорошо определены в спецификации JMS, фактический протокол связи между клиентом и брокером был намеренно исключен из спецификации, чтобы существующие брокеры могли быть сделаны JMS-совместимыми. Таким образом, ActiveMQ был свободен в определении своего собственного протокола взаимодействия — OpenWire. OpenWire используется реализацией клиентской библиотеки ActiveMQ JMS, а также ее аналогами в .Net и C++: NMS и CMS, которые являются подпроектами ActiveMQ, размещенными в Apache Software Foundation.
Со временем в ActiveMQ была добавлена поддержка других протоколов взаимодействия, что увеличило возможности взаимодействия с другими языками и средами:
AMQP 1.0
Расширенный протокол очереди сообщений (Advanced Message Queuing Protocol) (ISO / IEC 19464:2014) не следует путать с его предшественником 0.X, который реализован в других системах обмена сообщениями, в частности в RabbitMQ, использующий 0.9.1. AMQP 1.0 является двоичным протоколом общего назначения для обмена сообщениями между двумя узлами. Он не имеет понятия клиентов или брокеров и включает в себя такие функции, как управление потоками, транзакции и различные QoS (не более одного раза, не менее одного раза и точно один раз).
STOMP
Простой / потоковый текстовый протокол обмена сообщениями (Simple/Streaming Text Oriented Messaging Protocol), простой в реализации протокол, который имеет десятки клиентских реализаций на разных языках.
XMPP
Расширяемый протокол обмена сообщениями и присутствия. (Extensible Messaging and Presence Protocol). Ранее называемый Jabber, этот протокол, основанный на XML, был первоначально разработан для систем чатов, но был расширен за пределы его первоначальных сценариев использования для включения обмена сообщениями типа «публикация-подписка».
MQTT
Легковесный протокол «публикация-подписка» (ISO / IEC 20922:2016), используемый для приложений «Машина-Машина» (M2M) и «Интернет вещей» (IoT).
ActiveMQ также поддерживает наложение вышеуказанных протоколов на WebSockets, что обеспечивает полнодуплексный обмен данными между приложениями в веб-браузере и адресатами в брокере.
Учитывая это, сейчас, когда мы говорим об ActiveMQ, мы больше не ссылаемся исключительно на стек взаимодействия, основанный на библиотеках JMS / NMS / CMS и протоколе OpenWire. Становится все более популярным сочетание и подбор языков, платформ и внешних библиотек, которые лучше всего подходят для данного приложения. Например, возможно, чтобы приложение JavaScript выполнялось в браузере с использованием MQTT библиотеки Eclipse Paho для отправки сообщений в ActiveMQ через веб-сокеты и эти сообщения читались серверным процессом C++, который использует AMQP посредством библиотеки Apache Qpid Proton. С этой точки зрения ландшафт обмена сообщениями становится все более разнообразным.
Заглядывая в будущее, AMQP, в частности, будет иметь гораздо больше возможностей, чем сейчас, поскольку компоненты, которые не являются ни клиентами, ни брокерами, становятся более знакомой частью ландшафта системы обмена сообщениями. Например, Apache Qpid Dispatch Router выступает в роли маршрутизатора сообщений, к которому клиенты подключаются напрямую, позволяя различным адресатам обрабатывать разные адреса, а также предоставляя возможность шардинга (разделения).
При работе со сторонними библиотеками и внешними компонентами необходимо учитывать, что они имеют переменное качество и могут быть несовместимы с функциями, предоставляемыми в ActiveMQ. Как очень простой пример — невозможно отправить сообщения в очередь через MQTT (без настройки маршрутизации в брокере). Таким образом, вам нужно будет потратить некоторое время на работу с опциями, чтобы определить стек системы обмена сообщений, наиболее подходящий для требований вашего приложения.
Прежде чем мы углубимся в детали того, как работает обмен сообщениями «точка-точка» в ActiveMQ, нам нужно немного поговорить о том, с чем сталкиваются все системы с интенсивной обработкой данных: компромисс между производительностью и надежностью.
Любая система, принимающая данные, будь то брокер сообщений или база данных, должна быть проинструктирована о том, как следует обрабатывать эти данные в случае сбоев. Сбой может принимать различные формы, но для простоты мы сузим его до ситуации, когда система теряет питание и немедленно отключается. В такой ситуации нам нужно порассуждать о том, что случится с данными, которые были в системе. Если данные (в данном случае сообщения) находились в памяти или в энергозависимой части железа, например в кэше, то эти данные будут потеряны. Однако, если данные были отправлены в энергонезависимое хранилище, например на диск, они снова будут доступны, когда система вернется в работу.
С этой точки зрения имеет смысл, что, если мы не хотим потерять сообщения в случае сбоя брокера, нам нужно записать их в постоянное хранилище. Стоимость этого конкретного решения, к сожалению, довольно высока.
Учтите, что разница между записью мегабайта данных на диск в 100-1000 раз медленнее, чем запись в память. Таким образом, разработчик приложения должен принять решение относительно того, стоит ли надежность сообщения потери производительности. Решения, подобные этим, должны приниматься на основе сценария использования.
Компромисс между производительностью и надежностью основан на спектре вариантов. Чем выше надежность, тем ниже производительность. Если вы решите сделать систему менее надежной, например, сохраняя сообщения только в памяти, ваша производительность значительно возрастет. По умолчанию JMS настроен на то, что ActiveMQ из коробки обеспечивает надежность. Существует множество механизмов, которые позволяют настроить брокер и взаимодействие с ним на позицию в этом спектре, которая лучше всего подходит для конкретных сценариев использования системы обмена сообщений.
Этот компромисс применяется на уровне отдельных брокеров. Тем не менее, по завершении настройки отдельного брокера, возможно масштабировать систему обмена сообщениями за пределы этой точки путем тщательного исследования потоков сообщений и разделения трафика между несколькими брокерами. Этого можно достичь, предоставив определенным адресатам их собственные брокеры или разделив общий поток сообщений либо на уровне приложения, либо с помощью промежуточного компонента. Позже, мы рассмотрим более подробно, как учесть топологии брокеров.
ActiveMQ поставляется с рядом подключаемых стратегий сохранения сообщений. Они идут в форме адаптеров персистентности (сохраняемости), которые можно рассматривать, как движки сохранения сообщений. К ним относятся решения, основанные на записи на диск, такие как KahaDB и LevelDB, а также на возможности использования базы данных через JDBC. Поскольку первые наиболее часто используются, мы сосредоточим наше обсуждение на них.
Когда брокер получает персистентные сообщения, они сначала записываются на диск в журнал. Журнал — это структура данных на диске, в которую можно только добавлять данные и состоящая из нескольких файлов. Входящие сообщения сериализуются брокером в независимое от протокола представление объекта, а затем маршализируются в двоичную форму, которая затем записывается в конец журнала. Журнал содержит лог всех входящих сообщений, а также сведения о тех сообщениях, которые были подтверждены, как прочитанные клиентом.
Дисковые адаптеры персистентности поддерживают индексные файлы, которые отслеживают, где в журнале расположены следующие пересылаемые сообщения. Когда все сообщения из файла журнала будут прочитаны, они будут либо удалены, либо заархивированы фоновым рабочим потоком ActiveMQ. Если этот журнал поврежден во время сбоя брокера, ActiveMQ перестроит его на основе информации в файлах журнала.
Сообщения из всех очередей записываются в одни и те же файлы журнала, что означает, что, если одно сообщение не прочитано, то весь файл (обычно по умолчанию 32 МБ или 100 МБ, в зависимости от адаптера персистентности) не может быть очищен. Это может со временем вызвать проблемы с нехваткой дискового пространства.
Существует ряд факторов, определяющих скорость, с которой может работать диск. Чтобы понять это, рассмотрим способ записи на диск через упрощенную мысленную модель трубы (pipe) (Figure 2-2).
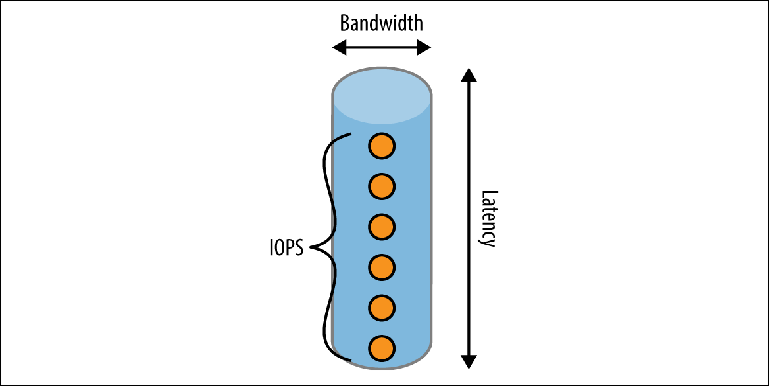
Figure 2-2. Модель трубы производительности диска
У трубы есть три измерения:
Длина
Соответствует задержке (latency), ожидаемой для завершения одной операции. Для большинства локальных дисков она довольно неплоха, но может стать основным ограничивающим фактором в облачных средах, где локальный диск фактически находится в сети. Например, на момент написания статьи (апрель 2017 г.) Amazon гарантирует, что запись в их EBS хранилище будет выполняться «менее чем за 2 мс». Если мы выполняем запись последовательно, то это дает максимальную пропускную способность 500 записей в секунду.
Ширина
Определяет пропускную способность (carrying capacity or bandwidth) одиночной операции. Кэши файловой системы используют это свойство, объединяя множество небольших записей в меньший набор более крупных операций записи, выполняемых на диске.
Пропускная способность за период времени
Идея представляется в виде ряда событий, которые могут находиться в трубе одновременно, выражается метрикой, называемой IOPS (количество операций ввода-вывода в секунду). IOPS обычно используется производителями хранилищ и облачными провайдерами для измерения производительности. Жесткий диск будет иметь разные значения IOPS в разных контекстах: состоит ли рабочая нагрузка в основном из операций чтения, записи или их комбинации и являются ли эти операции последовательными, произвольными или смешанными. Измерения IOPS, которые наиболее интересны с точки зрения брокера, являются последовательными операциями чтения и записи, поскольку они соответствуют чтению и записи логов журнала.
Максимальная пропускная способность брокера сообщений определяется достижением первого из этих ограничений и настройка брокера во многом зависит от способа взаимодействия с дисками. Это не только фактор того, как, к примеру, настроен брокер, но также зависит от того, как продьюсеры взаимодействуют с брокером. Как и во всем, что связано с производительностью, необходимо протестировать брокер на репрезентативной рабочей нагрузке (т. е. как можно ближе к реальным сообщениям) и на фактической настройке хранилища, которая будет использоваться в ПРОМе. Это сделано для того, чтобы понять, как система будет вести себя в реальности.
Прежде чем мы перейдем к деталям того, как ActiveMQ обменивается сообщениями с клиентами, нам сначала нужно изучить API JMS. API определяет набор программных интерфейсов, используемых клиентским кодом:
ConnectionFactory
Это интерфейс верхнего уровня, используемый для установления соединений с брокером. В типичном приложении обмена сообщениями существует единственный экземпляр этого интерфейса. В ActiveMQ — это ActiveMQConnectionFactory. На верхнем уровне эта конструкция сообщает местонахождение брокера сообщений, вместе с низкоуровневыми деталями того, как следует взаимодействовать с ним. Как следует из названия, ConnectionFactory — это механизм, с помощью которого создаются объекты Connection.
Connection
Это долгоживущий объект, который грубо похож на TCP-соединение — после создания он обычно существует в течение всего жизненного цикла приложения до его закрытия. Connection — потокобезопасный и может работать с несколькими потоками одновременно. Объекты Connection позволяют создавать объекты Session.
Session
Это дескриптор потока при взаимодействии с брокером. Объекты Session не являются потокобезопасными, что означает, что они не могут быть доступны нескольким потокам одновременно. Session — это основной транзакционный дескриптор, с помощью которого программист может закоммитить и откатить (rollback) операции обмена сообщениями, если он работает в транзакционном режиме. Используя этот объект, вы создаете объекты Message, MessageConsumer и MessageProducer, а также получаете указатели (дескрипторы) на объекты Topic и Queue.
MessageProducer
Этот интерфейс позволяет отправлять сообщение адресату.
MessageConsumer
Этот интерфейс позволяет разработчику получать сообщения. Существует два механизма извлечения сообщения:
Message
Это, вероятно, самая важная структура, поскольку она переносит ваши данные. Сообщения в JMS состоят из двух аспектов:
Полезная, хотя и неточная, модель работы ActiveMQ — это модель двух половинок мозга. Одна часть отвечает за прием сообщений от продюсера, а другая отправляет эти сообщения потребителям. На самом деле, отношения являются более сложными для целей оптимизации производительности, но модель достаточна для базового понимания.
Давайте рассмотрим взаимодействие, которое происходит при отправке сообщения. Figure 2-3 показывает нам упрощенную модель процесса, с помощью которого сообщения принимаются брокером. Он не полностью соответствует поведению в каждом случае, но вполне подходит, чтобы получить базовое понимание.

Figure 2-3. Отправка сообщений в JMS
В клиентском приложении поток получает указатель на MessageProducer. Он создает Message с предполагаемым пейлоадом сообщения и вызывает MessageProducer.send («orders», message), при этом конечным адресатом сообщения является очередь. Поскольку программист не хочет потерять сообщение, если бы сломался брокер, то заголовок сообщенияJMSDeliveryMode был установлен в значение PERSISTENT (поведение по умолчанию).
На этом этапе (1) отправляющий поток вызывает клиентскую библиотеку и маршализирует сообщение в формат OpenWire. Затем сообщение отправляется брокеру.
В брокере, принимающий поток снимает сообщение с линии и анмаршаллит его во внутренний объект. Затем объект-сообщение передается персистенс-адаптеру, который маршализирует сообщение, используя формат Google Protocol Buffers, и записывает его в хранилище (2).
После записи сообщения в хранилище персистенс-адаптер должен получить подтверждение того, что сообщение действительно было записано (3). Это, как правило, самая медленная часть всего взаимодействия; подробнее об этом позже.
Как только брокер удостоверится, что сообщение сохранено, он отправит клиенту ответ-подтверждение (4). После чего, поток клиента, первоначально вызвавший операцию send (), может продолжить свою работу.
Это ожидание подтверждения персистентных сообщений является базой гарантии, предоставляемой JMS API — если вы хотите, чтобы сообщение было сохранено, для вас, вероятно, также важно, было ли сообщение принято брокером в первую очередь. Существует ряд причин, по которым это может оказаться невозможным, например, достигнут предел памяти или диска. Вместо сбоя, брокер либо приостанавливает операцию отправки, заставляя продюсер ждать, пока не появится достаточно системных ресурсов для обработки сообщения (процесс называется Producer Flow Control), либо он отправит негативное подтверждение продюсеру, бросая исключение. Точное поведение настраивается для каждого брокера.
В этой простой операции происходит значительное количество взаимодействий ввода-вывода: две сетевые операции между продюсером и брокером, одна операция сохранения и шаг подтверждения. Операция сохранения может быть простой записью на диск или еще одним сетевым переходом на сервер хранения.
Это поднимает важный вопрос о брокерах сообщений: их работа сопряжена с крайне интенсивным потоком операций ввода-вывода и они очень чувствительны к используемой инфраструктуре, в особенности к дискам.
Давайте подробнее рассмотрим этап подтверждения (3) в приведенном выше взаимодействии. Если персистенс-адаптер основан на файлах, то сохранение сообщения включает запись в файловую систему. Если это так, то зачем нужно подтверждение того, что операция записи была завершена? Действительно ли акт завершения записи означает, что запись произошла?
Не совсем. Как это обычно бывает, чем глубже вы изучаете что-то, тем более сложным оно оказывается. В данном конкретном случае виновником является кэширование.
Когда процесс операционной системы, например брокер, записывает данные на диск, он взаимодействует с файловой системой. Файловая система — это процесс, который абстрагирует детали взаимодействия с используемым носителем данных, предоставляя API для файловых операций, таких как ОТКРЫТЬ, ЗАКРЫТЬ, ПРОЧИТАТЬ и ЗАПИСАТЬ. Одна из этих функций заключается в минимизации количества операций записи путем буферизации данных, записываемых операционной системой в блоки, которые могут быть сохранены на диск в один подход. Операции записи файловой системы, которые выглядят так, будто взаимодействуют с дисками, на самом деле записываются в этот буферный кэш.
Кстати, именно поэтому ваш компьютер жалуется, когда вы небезопасно извлекаете USB-накопитель — файлы, которые вы скопировали, на самом деле, возможно, не были записаны!
Как только данные выходят за пределы буферного кэша, они попадают на следующий уровень кэширования, на этот раз на аппаратном уровне — кэш контроллера диска. Они особенно важны для систем на основе RAID и выполняют ту же функцию, что и кэширование на уровне операционной системы: минимизировать количество взаимодействий, необходимых для самих дисков. Эти кэши делятся на две категории:
Сквозная запись (write-through)
Записи передаются на диск сразу при поступлении.
Обратная запись (write-back)
Запись выполняется на диски только тогда, когда заполнение буфера достигло определенного порогового значения.
Данные, хранящиеся в этих кэшах, могут быть легко потеряны при сбое питания, поскольку используемая ими память обычно энергозависимая (волатильная, volatile). Более дорогие карты имеют резервные блоки батарей (BBU), которые поддерживают питание кэшей, пока вся система не сможет восстановить питание, после чего данные будут записаны на диск.
Последний уровень кэшей находится на самих дисках. Дисковые кэши расположены на жестких дисках (как на стандартных жестких дисках, так и на твердотельных накопителях) и могут быть как со сквозной записью, так и с обратной. Большинство коммерческих накопителей используют кэши с обратной записью и являются энергозависимыми, что опять же означает, что данные могут быть потеряны в случае сбоя питания.
Возвращаясь к брокеру сообщений, необходимо выполнить шаг подтверждения, чтобы убедиться, что данные действительно дошли до диска. К сожалению, взаимодействие с этими аппаратными буферами зависит от файловой системы, поэтому все, что может сделать процесс, такой как ActiveMQ — это послать файловой системе сигнал о том, что она хочет синхронизировать все системные буферы с используемым устройством. Для этого брокер вызывает метод java.io.FileDescriptor.sync (), который, в свою очередь, запускает POSIX операцию fsync ().
Такое поведение синхронизации является требованием JMS, чтобы гарантировать, что все сообщения, помеченные как персистентные, действительно сохранялись на диск и, следовательно, выполняется после получения каждого сообщения или набора связанных сообщений в транзакции. Таким образом, скорость, с которой диск может выполнять sync (), имеет решающее значение для производительности брокера.
Использование одного журнала для всех очередей добавляет дополнительную сложность. В любой момент времени может существовать несколько продюсеров, одновременно отправляющих сообщения. У брокера есть несколько потоков, которые получают эти сообщения из входящих сокетов. Каждый поток должен сохранить свое сообщение в журнал. Поскольку несколько потоков не могут одновременно писать в один и тот же файл, т.к. записи будут конфликтовать друг с другом, то записи должны быть поставлены в очередь с помощью механизма взаимного исключения. Мы называем это конфликтом потоков.
Каждое сообщение должно быть полностью записано и синхронизировано перед обработкой следующего сообщения. Это ограничение влияет на все очереди в брокере одновременно. Таким образом, скорость того, как быстро сообщение может быть принято — это время записи на диск плюс любое время ожидания других потоков для завершения ими записи.
ActiveMQ включает в себя буфер записи, в который принимающие потоки записывают свои сообщения, ожидая завершения предыдущей записи. Затем буфер записывается в одно действие, когда сообщение становится доступным. После завершения потоки получают уведомление. Таким образом, брокер максимизирует использование пропускной способности хранилища.
Чтобы свести к минимуму влияние конфликта потоков, наборам очередей можно назначить (assign) их собственные журналы с помощью адаптера mKahaDB. Этот подход сокращает время ожидания записи, так как в любой момент времени потоки, скорее всего, будут писать в разные журналы и им не нужно будет конкурировать друг с другом за эксклюзивный доступ к одному файлу журнала.
Преимущество использования единого журнала для всех очередей в том, что с точки зрения авторов брокера, гораздо проще реализовать транзакции.
Давайте рассмотрим пример, когда несколько сообщений отправляются продюсером в несколько очередей. Использование транзакции означает, что весь набор отправляемых сообщений должен рассматриваться, как одна атомарная операция. В этом взаимодействии клиентская библиотека ActiveMQ способна сделать некоторые оптимизации, которые значительно повысят скорость отправки.
В операции, показанной на Figure 2-4, продюсер отправляет три сообщения, все в разные очереди. Вместо обычного взаимодействия с брокером, когда подтверждается каждое сообщение, клиент отправляет все три сообщения асинхронно, то есть без ожидания ответа. Эти сообщения хранятся в памяти брокера. Как только операция завершена, продюсер сообщает своим сессиям о необходимости выполнить коммит, что в свою очередь, заставляет брокер выполнять одну большую запись с одной операцией синхронизации.

Figure 2-4. Отправка сообщений в транзакции
В этом типе операций ActiveMQ использует две оптимизации для повышения скорости:
Если сравнить это с ситуацией, когда каждая очередь хранится в своем собственном журнале, то брокер должен был бы обеспечить что-то типа координации транзакций между всеми записями.
Процесс вычитывания сообщений начинается, когда потребитель выражает готовность их принять либо настраивая MessageListener для обработки сообщений по мере их поступления, либо вызывая метод MessageConsumer.receive () (Figure 2-5).
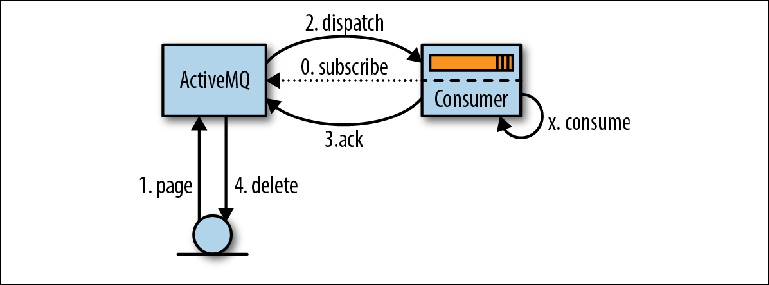
Figure 2-5. Вычитывание сообщений посредством JMS
Когда ActiveMQ становится известно о консюмере, он (ActiveMQ) постранично читает (pages) сообщения из хранилища в память для распространения (1). Затем эти сообщения перенаправляются (dispatched) консюмеру (2), часто несколькими частями для снижения объема сетевого взаимодействия. Брокер отслеживает, какие сообщения были перенаправлены и какому консьюмеру.
Сообщения, полученные консюмером, не обрабатываются сразу приложением, а помещаются в область памяти, известную как буфер предварительной выборки (prefetch buffer). Цель этого буфера состоит в том, чтобы выровнять поток сообщений, чтобы брокер мог выдавать сообщения консюмеру по мере того, как они становятся доступными для отправки, в то время, как консьюмер мог получать их упорядоченно, по одному.
В какой-то момент после попадания в буфер предварительной выборки, сообщения вычитываются логикой приложения (X) и брокеру отправляется подтверждение о вычитке (3). Упорядочивание времени между обработкой сообщения и его подтверждением настраивается с помощью параметра сессии JMS, называемого acknowledgement mode, который мы обсудим чуть позже.
Как только брокер принимает подтверждение доставки сообщения, оно удаляется из памяти и из хранилища сообщений (4). Термин «удаление» в некоторой степени вводит в заблуждение, так как в действительности в журнал записывается запись о подтверждении и увеличивается указатель в индексе. Фактическое удаление файла журнала, содержащего сообщение, будет выполнено Сборщиком мусора (Garbage collector) в фоновым потоке на основе этой информации.
Описанное выше поведение является упрощением для облегчения понимания. В действительности, ActiveMQ не просто постранично читает (page) данные с диска, а вместо этого использует механизм курсора между принимающей и перенаправляющей частями брокера для минимизации взаимодействия с хранилищем брокера везде, где это возможно. Постраничное чтение, как описано выше, является одним из режимов, используемым в этом механизме. Курсоры можно рассматривать, как кэш уровня приложения, который необходимо поддерживать в синхронизированном состоянии с хранилищем брокера. Используемый протокол согласования (coherency) — значительная часть того, что делает механизм диспетчеризации ActiveMQ намного более сложным, чем механизм Kafka, описанный в следующей главе.
Различные режимы подтверждения, которые определяют порядок между вычиткой и подтверждением, оказывают существенное влияние на то, какую логику необходимо реализовать в клиенте. Они бывают следующими:
AUTO_ACKNOWLEDGE
Это наиболее часто используемый режим, возможно потому, что в нем есть слово AUTO. Этот режим заставляет клиентскую библиотеку подтверждать сообщение в то же время, когда сообщение вычитывается вызовом receive (). Это означает, что, если бизнес-логика, инициированная сообщением, вызывает исключение, то сообщение теряется, так как оно уже было удалено на брокере. Если чтение сообщений осуществляется через слушатель, то сообщение будет подтверждено только после успешного завершения работы слушателя.
CLIENT_ACKNOWLEDGE
Подтверждение будет отправлено только тогда, когда код консюмера в явном виде вызовет метод Message.acknowledge ().
DUPS_OK_ACKNOWLEDGE
Здесь подтверждения будут буферизованы в консюмере перед их одновременной отправкой с целью уменьшения объема сетевого трафика. Однако, если клиентская система завершит работу, то подтверждения будут потеряны, а сообщения будут повторно отправлены и обработаны во второй раз. Поэтому код должен учитывать вероятность дублирования сообщений.
Режимы подтверждения дополняются инструментами транзакционного чтения. При создании Session он может быть помечен, как транзакционный. Это означает, что программист должен явно вызывать Session.commit () или Session.rollback (). На стороне потребителя транзакции расширяют спектр взаимодействий, которые может выполнять код, как одну атомарную операцию. Например, можно вычитывать и обрабатывать несколько сообщений, как единое целое, или вычитывать сообщение из одной очереди, а затем отправлять в другую, используя тот же объект Session.
До сих пор мы обсуждали поведение при чтении сообщений одним консюмером. Давайте теперь рассмотрим, как эта модель применима к нескольким консюмерам.
Когда несколько консюмеров подписываются на очередь, дефолтное поведение брокера заключается в циклической (round-robin) отправке сообщений тем консюмерам, у которых есть место в буферах предварительной выборки. Сообщения будут отправлены в том порядке, в котором они поступили в очередь — это единственная предоставляемая гарантия FIFO (first in, first out; первым вошел, первым вышел).
Когда консюмер неожиданно отключается, все сообщения, отправленные ему, но еще не подтвержденные, будут повторно отправлены другому доступному консюмеру.
Это поднимает важный вопрос: даже там, где используются транзакции консюмера, нет никаких гарантий, что сообщение не будет обработано несколько раз.
Рассмотрим следующую логику обработки внутри консюмера:
Если клиент завершает работу между этапами 2 и 3, то вычитка сообщения уже повлияла на какую-то другую систему посредством вызова веб-сервиса. Вызовы веб-сервисов — это HTTP-запросы и, как таковые, не являются транзакционными.
Такое поведение справедливо для всех систем организации очередей — даже если они транзакционные, они не могут гарантировать, что при обработке в них сообщений не возникнет побочных эффектов. Рассмотрев обработку сообщений в деталях, мы можем уверенно сказать, что:
Нет такого понятия, как доставка сообщений только один раз.
Очереди предоставляют гарантию доставки по крайней мере один раз и чувствительные части кода всегда должны учитывать возможность получения повторных сообщений. Позже мы обсудим, как клиент системы обмена сообщениями может применять идемпотентное чтение для отслеживания уже просмотренных сообщений и исключения дубликатов.
Для набора сообщений, поступающих в порядке [A, B, C, D], и для двух потребителей C1 и C2, нормальное распределение сообщений будет следующим:
Поскольку брокер не контролирует работу процессов чтения и порядок обработки является параллельным, то он недетерминирован. Если С1 происходит медленнее, чем С2, то первоначальный набор сообщений может быть обработан как [В, D, A, C].
Такое поведение может удивить новичков, ожидающих, что сообщения будут обрабатываться по порядку и на этой основе разрабатывают свое приложение для обмена сообщениями. Требование, чтобы сообщения, отправленные одним и тем же отправителем, обрабатывались в порядке относительно друг друга, также известное как причинно-следственное упорядочивание (causal ordering), является довольно распространенным.
Возьмем в качестве примера следующий вариант использования, взятый из онлайн-ставок:
Здесь имеет смысл, чтобы сообщения обрабатывались в том порядке, в котором они были отправлены, чтобы учитывалось общее состояние счета. Могут произойти странные вещи, если система попытается удалить деньги со счета, на котором нет средств. Есть, конечно, способы обойти это.
Модель монопольного консюмера включает отправку всех сообщений из очереди одному консюмеру. Используя этот подход, при подключении нескольких экземпляров приложений или потоков к очереди, они подписываются с помощью специального параметра адресата:
Недостатком этого подхода является то, что, хотя обработка сообщений последовательна, она является узким местом производительности, поскольку все сообщения должны обрабатываться одним консюмером.
Чтобы разобраться с этим сценарием использования более толково, необходимо пересмотреть проблему. Требуется ли обработка всех сообщений по порядку? В вышеописанном случае обработки ставок необходимо последовательно обрабатывать только сообщения, относящиеся к одному счету. ActiveMQ предоставляет механизм для решения этой ситуации, который называется группы сообщений JMS.
Группы сообщений — это разновидность механизма партиционирования, позволяющая продюсерам распределять сообщения по группам, которые будут последовательно обрабатываться в соответствии с бизнес-ключом. Этот бизнес-ключ задается в свойстве сообщения под названием
Естественным ключом в случае обработки ставок будет идентификатор учетной записи.
Чтобы проиллюстрировать, как работает отправка, рассмотрим набор сообщений, поступающих в следующем порядке:
Когда сообщение обрабатывается механизмом диспетчеризации в ActiveMQ и он видит
Здесь группы будут назначаться между двумя потребителями: С1 и С2, следующим образом:
Сообщения будут перенаправлены и обработаны следующим образом:
Если консюмер ломается, то все группы, назначенные ему, будут перераспределены между остальными консюмерами и любые неподтвержденные сообщения будут перенаправлены повторно. Поэтому, хотя мы и можем гарантировать, что все связанные сообщения будут обработаны по порядку, мы не можем утверждать, что они будут обработаны одним и тем же консюмером.
ActiveMQ обеспечивает высокую доступность с помощью схемы «ведущий-ведомый», основанной на общем хранилище. В этой схеме два или более брокера (хотя обычно два) настраиваются на отдельных серверах, а их сообщения сохраняются в хранилище сообщений, расположенном во внешнем расположении. Хранилище сообщений не может одновременно использоваться несколькими экземплярами брокера, поэтому его (хранилища) вторичная функция заключается в том, чтобы действовать как механизм блокировки, чтобы определить, какой брокер получит монопольный доступ (Figure 2-6).
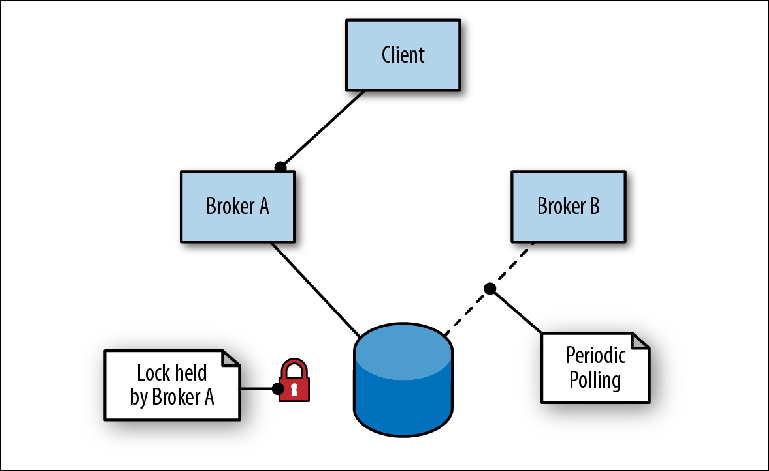
Figure 2-6. Брокер A — ведущий, брокер B находится в режиме ожидания, как ведомый
Для подключения к хранилищу первый брокер (Брокер A) берет на себя роль ведущего и открывает свои порты для трафика сообщений. Когда второй брокер (Брокер B) подключается к хранилищу, он пытается получить блокировку и, поскольку у него это не получается, приостанавливается на короткий период, прежде чем снова попытаться получить блокировку. Это называется сдерживание в ведомом состоянии.
В то же время, клиент чередует адреса двух брокеров в попытке подключиться к входящему порту, известному, как транспортный соединитель. Как только главный брокер становится доступен, клиент подключается к его порту и может отправлять и читать сообщения.
Когда Брокер A, выполнявший роль ведущего, выходит из строя из-за сбоя процесса (Figure 2-7), происходят следующие события:

Figure 2-7. Брокер A завершает работу, теряя соединение с хранилищем. Брокер B берет на себя роль ведущего
Этот подход также имеет дополнительную сложность, заключающуюся в том, что используемое хранилище брокера, будь то разделяемая сетевая файловая система или база данных, также должно быть высокодоступным. Это ведет к дополнительным расходам на оборудование и администрирование настройки брокера. В этом сценарии заманчиво переиспользовать существующие высокодоступные хранилища, используемые другими частями инфраструктуры, например базой данных, но это ошибка.
Важно помнить, что диск является основным ограничителем общей производительности брокера. Если сам диск одновременно используется процессом, отличным от брокера сообщений, то взаимодействие этого процесса с диском, вероятно, замедляет запись от брокера и, следовательно, скорость, с которой сообщения могут проходить через систему. Такие замедления трудно диагностировать и единственный способ их обойти — разделить два процесса на разные тома хранилищ.
Для обеспечения стабильной работы брокера требуется выделенное (dedicated) и эксклюзивное (exclusive) хранилище.
В какой-то момент жизни проекта можно столкнуться с ограничением производительности брокера сообщений. Эти ограничения обычно касаются ресурсов, в частности, взаимодействия ActiveMQ с используемым хранилищем. Эти проблемы обычно возникают из-за объема сообщений или конфликтов пропускной способности между адресатами, например, когда одна очередь переполняет брокер в пиковый период.
Существует ряд способов получения большей производительности от инфраструктуры брокера:
Одна из наиболее распространенных причин проблем с производительностью брокера — это просто попытка сделать слишком много с одним экземпляром. Как правило, это возникает в ситуациях, когда брокер наивно разделяется между несколькими приложениями без учета существующей нагрузки на брокер или понимания объемов. Со временем, один брокер нагружается все больше и больше, пока он не перестает вести себя адекватно.
Проблема часто возникает на этапе проектирования системы, когда системный архитектор может предложить такую схему, как на Figure 2-8.
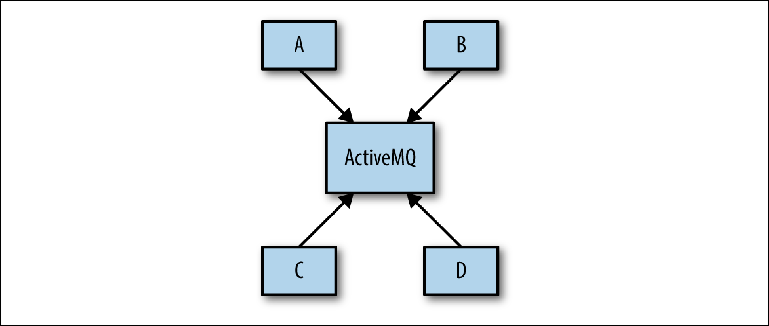
Figure 2-8. Концептуальное представление инфраструктуры обмена сообщениями
Цель состоит в том, чтобы несколько приложений взаимодействовали друг с другом асинхронно через ActiveMQ. Цель больше не уточняется и тогда схема определяет основу реальной конфигурации брокера. Этот подход имеет название — Универсальный Конвейер Данных.
Он не учитывает фундаментальный шаг анализа между концептуальным дизайном, упомянутым выше, и физической реализацией. Прежде чем приступить к построению конкретной конфигурации, необходимо выполнить анализ, который затем будет использован для обоснования физического проекта. Первым шагом этого процесса должно быть определение того, какие системы взаимодействуют друг с другом — достаточно простой диаграммы с прямоугольниками и стрелками (Figure 2-9).
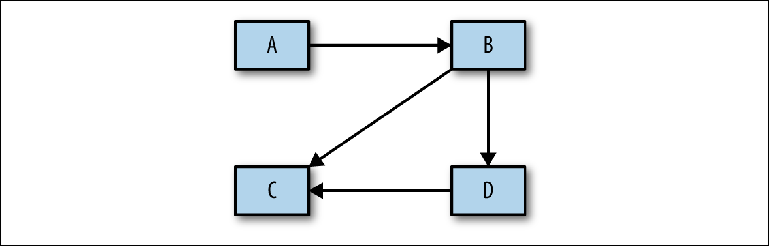
Figure 2-9. Набросок потоков сообщений между системами
После её утверждения можно перейти к деталям для ответа на следующие вопросы:
Идея состоит в том, чтобы определить отдельные сценарии обмена сообщениями, которые можно объединить или разделить по отдельным брокерам (Figure 2-10).
После такого разбиения сценарии использования можно моделировать, сочетая друг с другом с помощью Модуля Производительности (Performance Module) ActiveMQ для выявления любых проблем.
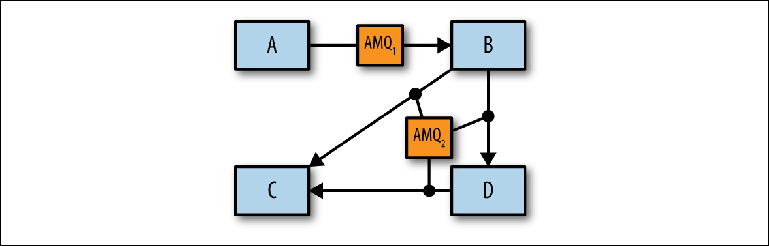
Figure 2-10. Идентификация отдельных брокеров
После определения соответствующего количества логических брокеров, можно определить способы их реализации на физическом уровне с помощью высокодоступных конфигураций и сетей брокеров.
В этой главе мы изучили механизм, с помощью которого ActiveMQ получает и распределяет сообщения. Мы обсудили функции, которые поддерживаются этой архитектурой, включая балансировку нагрузки (sticky load-balancing) связанных сообщений и транзакции. При этом мы ввели набор понятий, общих для всех систем обмена сообщениями, в том числе протоколы связи и журналы. Мы также подробно рассмотрели сложности, возникающие при записи на диск и то, как брокеры могут использовать такие техники, как пакетная запись для повышения производительности. Наконец, мы изучили, как можно сделать ActiveMQ высокодоступным и как его масштабировать за пределы возможностей отдельного брокера.
В следующей главе мы рассмотрим Apache Kafka и то, как её архитектура переосмысливает отношения между клиентами и брокерами для обеспечения невероятно устойчивого конвейера сообщений с пропускной способностью, во много раз большей, чем обычный брокер сообщений. Мы обсудим функциональность, которую она использует для достижения этой цели, и кратко рассмотрим архитектуру приложений, обеспечивающих эту функциональность.
Следущая часть: Понимание брокеров сообщений. Изучение механики обмена сообщениями посредством ActiveMQ и Kafka. Глава 3. Kafka
Перевод выполнен: t.me/middle_java
«Understanding Message Brokers»,
автор: Jakub Korab, издательство: O'Reilly Media, Inc., дата издания: June 2017, ISBN: 9781492049296.
Предыдущая часть: Понимание брокеров сообщений. Изучение механики обмена сообщениями посредством ActiveMQ и Kafka. Глава 1. Введение
ГЛАВА 2
ActiveMQ
ActiveMQ лучше всего описать, как классическую систему обмена сообщениями. Она была написана в 2004 году, восполняя потребность в брокере сообщений с открытым исходным кодом. В то время, если вы хотели использовать обмен сообщениями в своих приложениях, единственным выбором были дорогие коммерческие продукты.
ActiveMQ была разработана как реализация спецификации Java Message Service (JMS). Это решение было принято, чтобы удовлетворить требования к реализации JMS-совместимого обмена сообщениями в проекте Apache Geronimo — сервере приложений J2EE с открытым исходным кодом.
Система обмена сообщениями (или промежуточное ПО, ориентированное на сообщения, как ее иногда называют), реализующая спецификацию JMS, состоит из следующих компонентов:
Брокер
Центральная часть промежуточного программного обеспечения, распределяющая сообщения.
Клиент
Часть программного обеспечения, которая перебрасывает сообщения с помощью брокера. Она, в свою очередь, состоит из следующих артефактов:
- Код, использующий API JMS.
- JMS API — это набор интерфейсов для взаимодействия с брокером в соответствии с гарантиями, изложенными в спецификации JMS.
- Клиентская библиотека системы, которая обеспечивает реализацию API и взаимодействует с брокером.
Клиент и брокер общаются друг с другом через протокол прикладного уровня, также известный, как протокол взаимодействия (Figure. 2-1). Спецификация JMS оставила детали этого протокола конкретным реализациям.
Figure 2-1. Обзор JMS
JMS использует термин провайдер для описания реализации вендором системы обмена сообщениями, лежащей в основе API JMS, которая включает брокер, а также ее клиентские библиотеки.
Выбор в пользу внедрения JMS имел далеко идущие последствия для имплементационных решений, принятых авторами ActiveMQ. В самой спецификации изложены четкие указания по обязанностям клиента системы обмена сообщениями и брокера, с которым он общается, отдавая предпочтение обязательству брокера распределять и доставлять сообщения. Основная обязанность клиента — взаимодействовать с адресатом (очередью или топиком) отправляемых им сообщений. Сама спецификация направлена на то, чтобы сделать взаимодействие API с брокером относительно простым.
Это направление, как мы увидим позже, сильно повлияло на производительность ActiveMQ. В дополнение к сложностям брокера, пакет совместимости для спецификации, предоставленной Sun Microsystems, имел множество нюансов, с их собственным влиянием на производительность. Данные нюансы должны были все быть учтены, чтобы ActiveMQ считалась совместимой с JMS.
Связь
Хотя API и ожидаемое поведение были хорошо определены в спецификации JMS, фактический протокол связи между клиентом и брокером был намеренно исключен из спецификации, чтобы существующие брокеры могли быть сделаны JMS-совместимыми. Таким образом, ActiveMQ был свободен в определении своего собственного протокола взаимодействия — OpenWire. OpenWire используется реализацией клиентской библиотеки ActiveMQ JMS, а также ее аналогами в .Net и C++: NMS и CMS, которые являются подпроектами ActiveMQ, размещенными в Apache Software Foundation.
Со временем в ActiveMQ была добавлена поддержка других протоколов взаимодействия, что увеличило возможности взаимодействия с другими языками и средами:
AMQP 1.0
Расширенный протокол очереди сообщений (Advanced Message Queuing Protocol) (ISO / IEC 19464:2014) не следует путать с его предшественником 0.X, который реализован в других системах обмена сообщениями, в частности в RabbitMQ, использующий 0.9.1. AMQP 1.0 является двоичным протоколом общего назначения для обмена сообщениями между двумя узлами. Он не имеет понятия клиентов или брокеров и включает в себя такие функции, как управление потоками, транзакции и различные QoS (не более одного раза, не менее одного раза и точно один раз).
STOMP
Простой / потоковый текстовый протокол обмена сообщениями (Simple/Streaming Text Oriented Messaging Protocol), простой в реализации протокол, который имеет десятки клиентских реализаций на разных языках.
XMPP
Расширяемый протокол обмена сообщениями и присутствия. (Extensible Messaging and Presence Protocol). Ранее называемый Jabber, этот протокол, основанный на XML, был первоначально разработан для систем чатов, но был расширен за пределы его первоначальных сценариев использования для включения обмена сообщениями типа «публикация-подписка».
MQTT
Легковесный протокол «публикация-подписка» (ISO / IEC 20922:2016), используемый для приложений «Машина-Машина» (M2M) и «Интернет вещей» (IoT).
ActiveMQ также поддерживает наложение вышеуказанных протоколов на WebSockets, что обеспечивает полнодуплексный обмен данными между приложениями в веб-браузере и адресатами в брокере.
Учитывая это, сейчас, когда мы говорим об ActiveMQ, мы больше не ссылаемся исключительно на стек взаимодействия, основанный на библиотеках JMS / NMS / CMS и протоколе OpenWire. Становится все более популярным сочетание и подбор языков, платформ и внешних библиотек, которые лучше всего подходят для данного приложения. Например, возможно, чтобы приложение JavaScript выполнялось в браузере с использованием MQTT библиотеки Eclipse Paho для отправки сообщений в ActiveMQ через веб-сокеты и эти сообщения читались серверным процессом C++, который использует AMQP посредством библиотеки Apache Qpid Proton. С этой точки зрения ландшафт обмена сообщениями становится все более разнообразным.
Заглядывая в будущее, AMQP, в частности, будет иметь гораздо больше возможностей, чем сейчас, поскольку компоненты, которые не являются ни клиентами, ни брокерами, становятся более знакомой частью ландшафта системы обмена сообщениями. Например, Apache Qpid Dispatch Router выступает в роли маршрутизатора сообщений, к которому клиенты подключаются напрямую, позволяя различным адресатам обрабатывать разные адреса, а также предоставляя возможность шардинга (разделения).
При работе со сторонними библиотеками и внешними компонентами необходимо учитывать, что они имеют переменное качество и могут быть несовместимы с функциями, предоставляемыми в ActiveMQ. Как очень простой пример — невозможно отправить сообщения в очередь через MQTT (без настройки маршрутизации в брокере). Таким образом, вам нужно будет потратить некоторое время на работу с опциями, чтобы определить стек системы обмена сообщений, наиболее подходящий для требований вашего приложения.
Компромисс между производительностью и надежностью
Прежде чем мы углубимся в детали того, как работает обмен сообщениями «точка-точка» в ActiveMQ, нам нужно немного поговорить о том, с чем сталкиваются все системы с интенсивной обработкой данных: компромисс между производительностью и надежностью.
Любая система, принимающая данные, будь то брокер сообщений или база данных, должна быть проинструктирована о том, как следует обрабатывать эти данные в случае сбоев. Сбой может принимать различные формы, но для простоты мы сузим его до ситуации, когда система теряет питание и немедленно отключается. В такой ситуации нам нужно порассуждать о том, что случится с данными, которые были в системе. Если данные (в данном случае сообщения) находились в памяти или в энергозависимой части железа, например в кэше, то эти данные будут потеряны. Однако, если данные были отправлены в энергонезависимое хранилище, например на диск, они снова будут доступны, когда система вернется в работу.
С этой точки зрения имеет смысл, что, если мы не хотим потерять сообщения в случае сбоя брокера, нам нужно записать их в постоянное хранилище. Стоимость этого конкретного решения, к сожалению, довольно высока.
Учтите, что разница между записью мегабайта данных на диск в 100-1000 раз медленнее, чем запись в память. Таким образом, разработчик приложения должен принять решение относительно того, стоит ли надежность сообщения потери производительности. Решения, подобные этим, должны приниматься на основе сценария использования.
Компромисс между производительностью и надежностью основан на спектре вариантов. Чем выше надежность, тем ниже производительность. Если вы решите сделать систему менее надежной, например, сохраняя сообщения только в памяти, ваша производительность значительно возрастет. По умолчанию JMS настроен на то, что ActiveMQ из коробки обеспечивает надежность. Существует множество механизмов, которые позволяют настроить брокер и взаимодействие с ним на позицию в этом спектре, которая лучше всего подходит для конкретных сценариев использования системы обмена сообщений.
Этот компромисс применяется на уровне отдельных брокеров. Тем не менее, по завершении настройки отдельного брокера, возможно масштабировать систему обмена сообщениями за пределы этой точки путем тщательного исследования потоков сообщений и разделения трафика между несколькими брокерами. Этого можно достичь, предоставив определенным адресатам их собственные брокеры или разделив общий поток сообщений либо на уровне приложения, либо с помощью промежуточного компонента. Позже, мы рассмотрим более подробно, как учесть топологии брокеров.
Сохранение сообщений
ActiveMQ поставляется с рядом подключаемых стратегий сохранения сообщений. Они идут в форме адаптеров персистентности (сохраняемости), которые можно рассматривать, как движки сохранения сообщений. К ним относятся решения, основанные на записи на диск, такие как KahaDB и LevelDB, а также на возможности использования базы данных через JDBC. Поскольку первые наиболее часто используются, мы сосредоточим наше обсуждение на них.
Когда брокер получает персистентные сообщения, они сначала записываются на диск в журнал. Журнал — это структура данных на диске, в которую можно только добавлять данные и состоящая из нескольких файлов. Входящие сообщения сериализуются брокером в независимое от протокола представление объекта, а затем маршализируются в двоичную форму, которая затем записывается в конец журнала. Журнал содержит лог всех входящих сообщений, а также сведения о тех сообщениях, которые были подтверждены, как прочитанные клиентом.
Дисковые адаптеры персистентности поддерживают индексные файлы, которые отслеживают, где в журнале расположены следующие пересылаемые сообщения. Когда все сообщения из файла журнала будут прочитаны, они будут либо удалены, либо заархивированы фоновым рабочим потоком ActiveMQ. Если этот журнал поврежден во время сбоя брокера, ActiveMQ перестроит его на основе информации в файлах журнала.
Сообщения из всех очередей записываются в одни и те же файлы журнала, что означает, что, если одно сообщение не прочитано, то весь файл (обычно по умолчанию 32 МБ или 100 МБ, в зависимости от адаптера персистентности) не может быть очищен. Это может со временем вызвать проблемы с нехваткой дискового пространства.
Классические брокеры сообщений не предназначены для долгосрочного хранения — вычитывайте ваши сообщения!Журналы являются чрезвычайно эффективным механизмом для хранения и последующего извлечения сообщений, поскольку доступ к диску для обеих операций является последовательным. На обычных жестких дисках это сводит к минимуму количество операций поиска дисков по цилиндрам, так как головки на диске просто продолжают читать или записывать сектора на вращающуюся подложку диска. Аналогично, на SSD накопителях последовательный доступ намного быстрее, чем произвольный доступ, поскольку первый лучше использует страницы памяти накопителя.
Факторы производительности диска
Существует ряд факторов, определяющих скорость, с которой может работать диск. Чтобы понять это, рассмотрим способ записи на диск через упрощенную мысленную модель трубы (pipe) (Figure 2-2).
Figure 2-2. Модель трубы производительности диска
У трубы есть три измерения:
Длина
Соответствует задержке (latency), ожидаемой для завершения одной операции. Для большинства локальных дисков она довольно неплоха, но может стать основным ограничивающим фактором в облачных средах, где локальный диск фактически находится в сети. Например, на момент написания статьи (апрель 2017 г.) Amazon гарантирует, что запись в их EBS хранилище будет выполняться «менее чем за 2 мс». Если мы выполняем запись последовательно, то это дает максимальную пропускную способность 500 записей в секунду.
Ширина
Определяет пропускную способность (carrying capacity or bandwidth) одиночной операции. Кэши файловой системы используют это свойство, объединяя множество небольших записей в меньший набор более крупных операций записи, выполняемых на диске.
Пропускная способность за период времени
Идея представляется в виде ряда событий, которые могут находиться в трубе одновременно, выражается метрикой, называемой IOPS (количество операций ввода-вывода в секунду). IOPS обычно используется производителями хранилищ и облачными провайдерами для измерения производительности. Жесткий диск будет иметь разные значения IOPS в разных контекстах: состоит ли рабочая нагрузка в основном из операций чтения, записи или их комбинации и являются ли эти операции последовательными, произвольными или смешанными. Измерения IOPS, которые наиболее интересны с точки зрения брокера, являются последовательными операциями чтения и записи, поскольку они соответствуют чтению и записи логов журнала.
Максимальная пропускная способность брокера сообщений определяется достижением первого из этих ограничений и настройка брокера во многом зависит от способа взаимодействия с дисками. Это не только фактор того, как, к примеру, настроен брокер, но также зависит от того, как продьюсеры взаимодействуют с брокером. Как и во всем, что связано с производительностью, необходимо протестировать брокер на репрезентативной рабочей нагрузке (т. е. как можно ближе к реальным сообщениям) и на фактической настройке хранилища, которая будет использоваться в ПРОМе. Это сделано для того, чтобы понять, как система будет вести себя в реальности.
JMS API
Прежде чем мы перейдем к деталям того, как ActiveMQ обменивается сообщениями с клиентами, нам сначала нужно изучить API JMS. API определяет набор программных интерфейсов, используемых клиентским кодом:
ConnectionFactory
Это интерфейс верхнего уровня, используемый для установления соединений с брокером. В типичном приложении обмена сообщениями существует единственный экземпляр этого интерфейса. В ActiveMQ — это ActiveMQConnectionFactory. На верхнем уровне эта конструкция сообщает местонахождение брокера сообщений, вместе с низкоуровневыми деталями того, как следует взаимодействовать с ним. Как следует из названия, ConnectionFactory — это механизм, с помощью которого создаются объекты Connection.
Connection
Это долгоживущий объект, который грубо похож на TCP-соединение — после создания он обычно существует в течение всего жизненного цикла приложения до его закрытия. Connection — потокобезопасный и может работать с несколькими потоками одновременно. Объекты Connection позволяют создавать объекты Session.
Session
Это дескриптор потока при взаимодействии с брокером. Объекты Session не являются потокобезопасными, что означает, что они не могут быть доступны нескольким потокам одновременно. Session — это основной транзакционный дескриптор, с помощью которого программист может закоммитить и откатить (rollback) операции обмена сообщениями, если он работает в транзакционном режиме. Используя этот объект, вы создаете объекты Message, MessageConsumer и MessageProducer, а также получаете указатели (дескрипторы) на объекты Topic и Queue.
MessageProducer
Этот интерфейс позволяет отправлять сообщение адресату.
MessageConsumer
Этот интерфейс позволяет разработчику получать сообщения. Существует два механизма извлечения сообщения:
- Регистрация MessageListener. Это реализованный вами интерфейс обработчика сообщений, который будет последовательно обрабатывать любые сообщения, выдаваемые брокером, используя один поток.
- Опрос (polling) на наличие сообщений с помощью метода receive ().
Message
Это, вероятно, самая важная структура, поскольку она переносит ваши данные. Сообщения в JMS состоят из двух аспектов:
- Метаданные сообщения. Сообщение содержит заголовки и свойства. И то, и то может рассматриваться, как элементы мапы. Заголовки — это хорошо известные элементы, определенные спецификацией JMS и доступные напрямую через API, такие как JMSDestination и JMSTimestamp. Свойства — это произвольные фрагменты информации о сообщении, которые задаются для упрощения обработки или маршрутизации сообщений без необходимости считывания самого пейлоада сообщения. Вы можете, например, задать заголовок AccountID или OrderType.
- Тело сообщения. Из Session может быть создано несколько различных типов сообщений в зависимости от типа содержимого, которое будет отправлено в теле, наиболее распространенными из которых являются TextMessage для строк и BytesMessage для двоичных данных.
Как работают очереди: история о двух мозгах
Полезная, хотя и неточная, модель работы ActiveMQ — это модель двух половинок мозга. Одна часть отвечает за прием сообщений от продюсера, а другая отправляет эти сообщения потребителям. На самом деле, отношения являются более сложными для целей оптимизации производительности, но модель достаточна для базового понимания.
Отправка сообщений в очередь
Давайте рассмотрим взаимодействие, которое происходит при отправке сообщения. Figure 2-3 показывает нам упрощенную модель процесса, с помощью которого сообщения принимаются брокером. Он не полностью соответствует поведению в каждом случае, но вполне подходит, чтобы получить базовое понимание.
Figure 2-3. Отправка сообщений в JMS
В клиентском приложении поток получает указатель на MessageProducer. Он создает Message с предполагаемым пейлоадом сообщения и вызывает MessageProducer.send («orders», message), при этом конечным адресатом сообщения является очередь. Поскольку программист не хочет потерять сообщение, если бы сломался брокер, то заголовок сообщенияJMSDeliveryMode был установлен в значение PERSISTENT (поведение по умолчанию).
На этом этапе (1) отправляющий поток вызывает клиентскую библиотеку и маршализирует сообщение в формат OpenWire. Затем сообщение отправляется брокеру.
В брокере, принимающий поток снимает сообщение с линии и анмаршаллит его во внутренний объект. Затем объект-сообщение передается персистенс-адаптеру, который маршализирует сообщение, используя формат Google Protocol Buffers, и записывает его в хранилище (2).
После записи сообщения в хранилище персистенс-адаптер должен получить подтверждение того, что сообщение действительно было записано (3). Это, как правило, самая медленная часть всего взаимодействия; подробнее об этом позже.
Как только брокер удостоверится, что сообщение сохранено, он отправит клиенту ответ-подтверждение (4). После чего, поток клиента, первоначально вызвавший операцию send (), может продолжить свою работу.
Это ожидание подтверждения персистентных сообщений является базой гарантии, предоставляемой JMS API — если вы хотите, чтобы сообщение было сохранено, для вас, вероятно, также важно, было ли сообщение принято брокером в первую очередь. Существует ряд причин, по которым это может оказаться невозможным, например, достигнут предел памяти или диска. Вместо сбоя, брокер либо приостанавливает операцию отправки, заставляя продюсер ждать, пока не появится достаточно системных ресурсов для обработки сообщения (процесс называется Producer Flow Control), либо он отправит негативное подтверждение продюсеру, бросая исключение. Точное поведение настраивается для каждого брокера.
В этой простой операции происходит значительное количество взаимодействий ввода-вывода: две сетевые операции между продюсером и брокером, одна операция сохранения и шаг подтверждения. Операция сохранения может быть простой записью на диск или еще одним сетевым переходом на сервер хранения.
Это поднимает важный вопрос о брокерах сообщений: их работа сопряжена с крайне интенсивным потоком операций ввода-вывода и они очень чувствительны к используемой инфраструктуре, в особенности к дискам.
Давайте подробнее рассмотрим этап подтверждения (3) в приведенном выше взаимодействии. Если персистенс-адаптер основан на файлах, то сохранение сообщения включает запись в файловую систему. Если это так, то зачем нужно подтверждение того, что операция записи была завершена? Действительно ли акт завершения записи означает, что запись произошла?
Не совсем. Как это обычно бывает, чем глубже вы изучаете что-то, тем более сложным оно оказывается. В данном конкретном случае виновником является кэширование.
Кэши, кэши повсюду
Когда процесс операционной системы, например брокер, записывает данные на диск, он взаимодействует с файловой системой. Файловая система — это процесс, который абстрагирует детали взаимодействия с используемым носителем данных, предоставляя API для файловых операций, таких как ОТКРЫТЬ, ЗАКРЫТЬ, ПРОЧИТАТЬ и ЗАПИСАТЬ. Одна из этих функций заключается в минимизации количества операций записи путем буферизации данных, записываемых операционной системой в блоки, которые могут быть сохранены на диск в один подход. Операции записи файловой системы, которые выглядят так, будто взаимодействуют с дисками, на самом деле записываются в этот буферный кэш.
Кстати, именно поэтому ваш компьютер жалуется, когда вы небезопасно извлекаете USB-накопитель — файлы, которые вы скопировали, на самом деле, возможно, не были записаны!
Как только данные выходят за пределы буферного кэша, они попадают на следующий уровень кэширования, на этот раз на аппаратном уровне — кэш контроллера диска. Они особенно важны для систем на основе RAID и выполняют ту же функцию, что и кэширование на уровне операционной системы: минимизировать количество взаимодействий, необходимых для самих дисков. Эти кэши делятся на две категории:
Сквозная запись (write-through)
Записи передаются на диск сразу при поступлении.
Обратная запись (write-back)
Запись выполняется на диски только тогда, когда заполнение буфера достигло определенного порогового значения.
Данные, хранящиеся в этих кэшах, могут быть легко потеряны при сбое питания, поскольку используемая ими память обычно энергозависимая (волатильная, volatile). Более дорогие карты имеют резервные блоки батарей (BBU), которые поддерживают питание кэшей, пока вся система не сможет восстановить питание, после чего данные будут записаны на диск.
Последний уровень кэшей находится на самих дисках. Дисковые кэши расположены на жестких дисках (как на стандартных жестких дисках, так и на твердотельных накопителях) и могут быть как со сквозной записью, так и с обратной. Большинство коммерческих накопителей используют кэши с обратной записью и являются энергозависимыми, что опять же означает, что данные могут быть потеряны в случае сбоя питания.
Возвращаясь к брокеру сообщений, необходимо выполнить шаг подтверждения, чтобы убедиться, что данные действительно дошли до диска. К сожалению, взаимодействие с этими аппаратными буферами зависит от файловой системы, поэтому все, что может сделать процесс, такой как ActiveMQ — это послать файловой системе сигнал о том, что она хочет синхронизировать все системные буферы с используемым устройством. Для этого брокер вызывает метод java.io.FileDescriptor.sync (), который, в свою очередь, запускает POSIX операцию fsync ().
Такое поведение синхронизации является требованием JMS, чтобы гарантировать, что все сообщения, помеченные как персистентные, действительно сохранялись на диск и, следовательно, выполняется после получения каждого сообщения или набора связанных сообщений в транзакции. Таким образом, скорость, с которой диск может выполнять sync (), имеет решающее значение для производительности брокера.
Внутренние конфликты
Использование одного журнала для всех очередей добавляет дополнительную сложность. В любой момент времени может существовать несколько продюсеров, одновременно отправляющих сообщения. У брокера есть несколько потоков, которые получают эти сообщения из входящих сокетов. Каждый поток должен сохранить свое сообщение в журнал. Поскольку несколько потоков не могут одновременно писать в один и тот же файл, т.к. записи будут конфликтовать друг с другом, то записи должны быть поставлены в очередь с помощью механизма взаимного исключения. Мы называем это конфликтом потоков.
Каждое сообщение должно быть полностью записано и синхронизировано перед обработкой следующего сообщения. Это ограничение влияет на все очереди в брокере одновременно. Таким образом, скорость того, как быстро сообщение может быть принято — это время записи на диск плюс любое время ожидания других потоков для завершения ими записи.
ActiveMQ включает в себя буфер записи, в который принимающие потоки записывают свои сообщения, ожидая завершения предыдущей записи. Затем буфер записывается в одно действие, когда сообщение становится доступным. После завершения потоки получают уведомление. Таким образом, брокер максимизирует использование пропускной способности хранилища.
Чтобы свести к минимуму влияние конфликта потоков, наборам очередей можно назначить (assign) их собственные журналы с помощью адаптера mKahaDB. Этот подход сокращает время ожидания записи, так как в любой момент времени потоки, скорее всего, будут писать в разные журналы и им не нужно будет конкурировать друг с другом за эксклюзивный доступ к одному файлу журнала.
Транзакции
Преимущество использования единого журнала для всех очередей в том, что с точки зрения авторов брокера, гораздо проще реализовать транзакции.
Давайте рассмотрим пример, когда несколько сообщений отправляются продюсером в несколько очередей. Использование транзакции означает, что весь набор отправляемых сообщений должен рассматриваться, как одна атомарная операция. В этом взаимодействии клиентская библиотека ActiveMQ способна сделать некоторые оптимизации, которые значительно повысят скорость отправки.
В операции, показанной на Figure 2-4, продюсер отправляет три сообщения, все в разные очереди. Вместо обычного взаимодействия с брокером, когда подтверждается каждое сообщение, клиент отправляет все три сообщения асинхронно, то есть без ожидания ответа. Эти сообщения хранятся в памяти брокера. Как только операция завершена, продюсер сообщает своим сессиям о необходимости выполнить коммит, что в свою очередь, заставляет брокер выполнять одну большую запись с одной операцией синхронизации.
Figure 2-4. Отправка сообщений в транзакции
В этом типе операций ActiveMQ использует две оптимизации для повышения скорости:
- Удаление времени ожидания перед тем, как становится возможна следующая отправка продюсером
- Объединение множества небольших дисковых операций в одну большую — это позволяет использовать всю полосу пропускания шины дисков
Если сравнить это с ситуацией, когда каждая очередь хранится в своем собственном журнале, то брокер должен был бы обеспечить что-то типа координации транзакций между всеми записями.
Вычитка сообщений из очереди
Процесс вычитывания сообщений начинается, когда потребитель выражает готовность их принять либо настраивая MessageListener для обработки сообщений по мере их поступления, либо вызывая метод MessageConsumer.receive () (Figure 2-5).
Figure 2-5. Вычитывание сообщений посредством JMS
Когда ActiveMQ становится известно о консюмере, он (ActiveMQ) постранично читает (pages) сообщения из хранилища в память для распространения (1). Затем эти сообщения перенаправляются (dispatched) консюмеру (2), часто несколькими частями для снижения объема сетевого взаимодействия. Брокер отслеживает, какие сообщения были перенаправлены и какому консьюмеру.
Сообщения, полученные консюмером, не обрабатываются сразу приложением, а помещаются в область памяти, известную как буфер предварительной выборки (prefetch buffer). Цель этого буфера состоит в том, чтобы выровнять поток сообщений, чтобы брокер мог выдавать сообщения консюмеру по мере того, как они становятся доступными для отправки, в то время, как консьюмер мог получать их упорядоченно, по одному.
В какой-то момент после попадания в буфер предварительной выборки, сообщения вычитываются логикой приложения (X) и брокеру отправляется подтверждение о вычитке (3). Упорядочивание времени между обработкой сообщения и его подтверждением настраивается с помощью параметра сессии JMS, называемого acknowledgement mode, который мы обсудим чуть позже.
Как только брокер принимает подтверждение доставки сообщения, оно удаляется из памяти и из хранилища сообщений (4). Термин «удаление» в некоторой степени вводит в заблуждение, так как в действительности в журнал записывается запись о подтверждении и увеличивается указатель в индексе. Фактическое удаление файла журнала, содержащего сообщение, будет выполнено Сборщиком мусора (Garbage collector) в фоновым потоке на основе этой информации.
Описанное выше поведение является упрощением для облегчения понимания. В действительности, ActiveMQ не просто постранично читает (page) данные с диска, а вместо этого использует механизм курсора между принимающей и перенаправляющей частями брокера для минимизации взаимодействия с хранилищем брокера везде, где это возможно. Постраничное чтение, как описано выше, является одним из режимов, используемым в этом механизме. Курсоры можно рассматривать, как кэш уровня приложения, который необходимо поддерживать в синхронизированном состоянии с хранилищем брокера. Используемый протокол согласования (coherency) — значительная часть того, что делает механизм диспетчеризации ActiveMQ намного более сложным, чем механизм Kafka, описанный в следующей главе.
Режимы подтверждения и транзакции
Различные режимы подтверждения, которые определяют порядок между вычиткой и подтверждением, оказывают существенное влияние на то, какую логику необходимо реализовать в клиенте. Они бывают следующими:
AUTO_ACKNOWLEDGE
Это наиболее часто используемый режим, возможно потому, что в нем есть слово AUTO. Этот режим заставляет клиентскую библиотеку подтверждать сообщение в то же время, когда сообщение вычитывается вызовом receive (). Это означает, что, если бизнес-логика, инициированная сообщением, вызывает исключение, то сообщение теряется, так как оно уже было удалено на брокере. Если чтение сообщений осуществляется через слушатель, то сообщение будет подтверждено только после успешного завершения работы слушателя.
CLIENT_ACKNOWLEDGE
Подтверждение будет отправлено только тогда, когда код консюмера в явном виде вызовет метод Message.acknowledge ().
DUPS_OK_ACKNOWLEDGE
Здесь подтверждения будут буферизованы в консюмере перед их одновременной отправкой с целью уменьшения объема сетевого трафика. Однако, если клиентская система завершит работу, то подтверждения будут потеряны, а сообщения будут повторно отправлены и обработаны во второй раз. Поэтому код должен учитывать вероятность дублирования сообщений.
Режимы подтверждения дополняются инструментами транзакционного чтения. При создании Session он может быть помечен, как транзакционный. Это означает, что программист должен явно вызывать Session.commit () или Session.rollback (). На стороне потребителя транзакции расширяют спектр взаимодействий, которые может выполнять код, как одну атомарную операцию. Например, можно вычитывать и обрабатывать несколько сообщений, как единое целое, или вычитывать сообщение из одной очереди, а затем отправлять в другую, используя тот же объект Session.
Отправка и несколько консюмеров
До сих пор мы обсуждали поведение при чтении сообщений одним консюмером. Давайте теперь рассмотрим, как эта модель применима к нескольким консюмерам.
Когда несколько консюмеров подписываются на очередь, дефолтное поведение брокера заключается в циклической (round-robin) отправке сообщений тем консюмерам, у которых есть место в буферах предварительной выборки. Сообщения будут отправлены в том порядке, в котором они поступили в очередь — это единственная предоставляемая гарантия FIFO (first in, first out; первым вошел, первым вышел).
Когда консюмер неожиданно отключается, все сообщения, отправленные ему, но еще не подтвержденные, будут повторно отправлены другому доступному консюмеру.
Это поднимает важный вопрос: даже там, где используются транзакции консюмера, нет никаких гарантий, что сообщение не будет обработано несколько раз.
Рассмотрим следующую логику обработки внутри консюмера:
- Сообщение вычитывается из очереди. Начинается транзакция.
- Вызывается веб-сервис с содержимым сообщения.
- Транзакция коммитится. Брокеру отправляется подтверждение.
Если клиент завершает работу между этапами 2 и 3, то вычитка сообщения уже повлияла на какую-то другую систему посредством вызова веб-сервиса. Вызовы веб-сервисов — это HTTP-запросы и, как таковые, не являются транзакционными.
Такое поведение справедливо для всех систем организации очередей — даже если они транзакционные, они не могут гарантировать, что при обработке в них сообщений не возникнет побочных эффектов. Рассмотрев обработку сообщений в деталях, мы можем уверенно сказать, что:
Нет такого понятия, как доставка сообщений только один раз.
Очереди предоставляют гарантию доставки по крайней мере один раз и чувствительные части кода всегда должны учитывать возможность получения повторных сообщений. Позже мы обсудим, как клиент системы обмена сообщениями может применять идемпотентное чтение для отслеживания уже просмотренных сообщений и исключения дубликатов.
Сортировка сообщений
Для набора сообщений, поступающих в порядке [A, B, C, D], и для двух потребителей C1 и C2, нормальное распределение сообщений будет следующим:
C1: [A, C]
C2: [B, D]Поскольку брокер не контролирует работу процессов чтения и порядок обработки является параллельным, то он недетерминирован. Если С1 происходит медленнее, чем С2, то первоначальный набор сообщений может быть обработан как [В, D, A, C].
Такое поведение может удивить новичков, ожидающих, что сообщения будут обрабатываться по порядку и на этой основе разрабатывают свое приложение для обмена сообщениями. Требование, чтобы сообщения, отправленные одним и тем же отправителем, обрабатывались в порядке относительно друг друга, также известное как причинно-следственное упорядочивание (causal ordering), является довольно распространенным.
Возьмем в качестве примера следующий вариант использования, взятый из онлайн-ставок:
- Учетная запись пользователя настроена.
- Деньги зачисляются на счет.
- Делается ставка, которая выводит деньги со счета.
Здесь имеет смысл, чтобы сообщения обрабатывались в том порядке, в котором они были отправлены, чтобы учитывалось общее состояние счета. Могут произойти странные вещи, если система попытается удалить деньги со счета, на котором нет средств. Есть, конечно, способы обойти это.
Модель монопольного консюмера включает отправку всех сообщений из очереди одному консюмеру. Используя этот подход, при подключении нескольких экземпляров приложений или потоков к очереди, они подписываются с помощью специального параметра адресата:
my.queue?consumer.exclusive=true. При подключении монопольного консюмера он получает все сообщения. Когда подключается второй консюмер, он не будет получать никаких сообщений, пока первый не отключится. Этот второй консюмер фактически является горячим резервом, в то время, как первый потребитель теперь будет получать сообщения точно в том порядке, в котором они были записаны в журнал — в причинно-следственном порядке.Недостатком этого подхода является то, что, хотя обработка сообщений последовательна, она является узким местом производительности, поскольку все сообщения должны обрабатываться одним консюмером.
Чтобы разобраться с этим сценарием использования более толково, необходимо пересмотреть проблему. Требуется ли обработка всех сообщений по порядку? В вышеописанном случае обработки ставок необходимо последовательно обрабатывать только сообщения, относящиеся к одному счету. ActiveMQ предоставляет механизм для решения этой ситуации, который называется группы сообщений JMS.
Группы сообщений — это разновидность механизма партиционирования, позволяющая продюсерам распределять сообщения по группам, которые будут последовательно обрабатываться в соответствии с бизнес-ключом. Этот бизнес-ключ задается в свойстве сообщения под названием
JMSXGroupID.Естественным ключом в случае обработки ставок будет идентификатор учетной записи.
Чтобы проиллюстрировать, как работает отправка, рассмотрим набор сообщений, поступающих в следующем порядке:
[(A, Group1), (B, Group1), (C, Group2), (D, Group3), (E, Group2)]
Когда сообщение обрабатывается механизмом диспетчеризации в ActiveMQ и он видит
JMSXGroupID, которого раньше не было, этот ключ назначается консюмеру на циклической основе. С этого момента все сообщения с этим ключом будут отправляться этому консюмеру.Здесь группы будут назначаться между двумя потребителями: С1 и С2, следующим образом:
C1: [Group1, Group3] C2: [Group2]
Сообщения будут перенаправлены и обработаны следующим образом:
C2: [B, D] C2: [(C, Group2), (E, Group2)]
Если консюмер ломается, то все группы, назначенные ему, будут перераспределены между остальными консюмерами и любые неподтвержденные сообщения будут перенаправлены повторно. Поэтому, хотя мы и можем гарантировать, что все связанные сообщения будут обработаны по порядку, мы не можем утверждать, что они будут обработаны одним и тем же консюмером.
Высокая доступность (High Availability)
ActiveMQ обеспечивает высокую доступность с помощью схемы «ведущий-ведомый», основанной на общем хранилище. В этой схеме два или более брокера (хотя обычно два) настраиваются на отдельных серверах, а их сообщения сохраняются в хранилище сообщений, расположенном во внешнем расположении. Хранилище сообщений не может одновременно использоваться несколькими экземплярами брокера, поэтому его (хранилища) вторичная функция заключается в том, чтобы действовать как механизм блокировки, чтобы определить, какой брокер получит монопольный доступ (Figure 2-6).
Figure 2-6. Брокер A — ведущий, брокер B находится в режиме ожидания, как ведомый
Для подключения к хранилищу первый брокер (Брокер A) берет на себя роль ведущего и открывает свои порты для трафика сообщений. Когда второй брокер (Брокер B) подключается к хранилищу, он пытается получить блокировку и, поскольку у него это не получается, приостанавливается на короткий период, прежде чем снова попытаться получить блокировку. Это называется сдерживание в ведомом состоянии.
В то же время, клиент чередует адреса двух брокеров в попытке подключиться к входящему порту, известному, как транспортный соединитель. Как только главный брокер становится доступен, клиент подключается к его порту и может отправлять и читать сообщения.
Когда Брокер A, выполнявший роль ведущего, выходит из строя из-за сбоя процесса (Figure 2-7), происходят следующие события:
- Клиент отключается и сразу же пытается переподключиться, чередуя адреса двух брокеров.
- Блокировка в сообщении снимается. Время этого зависит от реализации хранилища.
- Брокер B, находившийся в подчиненном режиме, периодически пытаясь получить блокировку, наконец, добивается успеха и берет на себя роль ведущего, открывая свои порты.
- Клиент подключается к Брокеру B и продолжает свою работу.
Figure 2-7. Брокер A завершает работу, теряя соединение с хранилищем. Брокер B берет на себя роль ведущего
Логика чередования между несколькими адресами брокера не встроена гарантированно в клиентскую библиотеку, как это происходит в реализациях JMS/NMS/CMS. Если библиотека обеспечивает только переподключение к одному адресу, то может потребоваться разместить пару брокеров за балансировщиком нагрузки, который также должен быть высокодоступным (highly available).Основным недостатком этого подхода является то, что для упрощения работы одного логического брокера требуется несколько физических серверов. В этом случае один из двух серверов брокера простаивает, ожидая отключения своего партнера, прежде чем он сможет начать работу.
Этот подход также имеет дополнительную сложность, заключающуюся в том, что используемое хранилище брокера, будь то разделяемая сетевая файловая система или база данных, также должно быть высокодоступным. Это ведет к дополнительным расходам на оборудование и администрирование настройки брокера. В этом сценарии заманчиво переиспользовать существующие высокодоступные хранилища, используемые другими частями инфраструктуры, например базой данных, но это ошибка.
Важно помнить, что диск является основным ограничителем общей производительности брокера. Если сам диск одновременно используется процессом, отличным от брокера сообщений, то взаимодействие этого процесса с диском, вероятно, замедляет запись от брокера и, следовательно, скорость, с которой сообщения могут проходить через систему. Такие замедления трудно диагностировать и единственный способ их обойти — разделить два процесса на разные тома хранилищ.
Для обеспечения стабильной работы брокера требуется выделенное (dedicated) и эксклюзивное (exclusive) хранилище.
Вертикальное и горизонтальное масштабирование
В какой-то момент жизни проекта можно столкнуться с ограничением производительности брокера сообщений. Эти ограничения обычно касаются ресурсов, в частности, взаимодействия ActiveMQ с используемым хранилищем. Эти проблемы обычно возникают из-за объема сообщений или конфликтов пропускной способности между адресатами, например, когда одна очередь переполняет брокер в пиковый период.
Существует ряд способов получения большей производительности от инфраструктуры брокера:
- Не используйте персистентность, если она не требуется. Некоторые сценарии использования допускают потерю сообщений при сбоях, особенно когда одна система передает другой полное состояние снэпшота через очередь, либо периодически, либо по запросу.
- Запустите брокер на более быстрых дисках. В реальных условиях были отмечены значительные различия в пропускной способности записи между стандартными HDD и memory-based альтернативами.
- Добивайтесь лучшего использования размеров диска. Как показано в модели конвейерного взаимодействия дисков, описанной выше, можно достичь более высокой пропускной способности, используя транзакции для отправки групп сообщений, тем самым, объединяя несколько операций записи в одну более крупную.
- Используйте партиционирование трафика. Можно достичь более высокой пропускной способности путем разделения адресатов одним из следующих способов:
- Несколько дисков в рамках одного брокера, например с помощью адаптера персистентности mKahaDB для нескольких каталогов, каждый из которых смонтирован на отдельный диск.
- Несколько брокеров, причем партиционирование трафика осуществляется вручную клиентским приложением. ActiveMQ не предоставляет для этой цели никаких собственных функций.
Одна из наиболее распространенных причин проблем с производительностью брокера — это просто попытка сделать слишком много с одним экземпляром. Как правило, это возникает в ситуациях, когда брокер наивно разделяется между несколькими приложениями без учета существующей нагрузки на брокер или понимания объемов. Со временем, один брокер нагружается все больше и больше, пока он не перестает вести себя адекватно.
Проблема часто возникает на этапе проектирования системы, когда системный архитектор может предложить такую схему, как на Figure 2-8.
Figure 2-8. Концептуальное представление инфраструктуры обмена сообщениями
Цель состоит в том, чтобы несколько приложений взаимодействовали друг с другом асинхронно через ActiveMQ. Цель больше не уточняется и тогда схема определяет основу реальной конфигурации брокера. Этот подход имеет название — Универсальный Конвейер Данных.
Он не учитывает фундаментальный шаг анализа между концептуальным дизайном, упомянутым выше, и физической реализацией. Прежде чем приступить к построению конкретной конфигурации, необходимо выполнить анализ, который затем будет использован для обоснования физического проекта. Первым шагом этого процесса должно быть определение того, какие системы взаимодействуют друг с другом — достаточно простой диаграммы с прямоугольниками и стрелками (Figure 2-9).
Figure 2-9. Набросок потоков сообщений между системами
После её утверждения можно перейти к деталям для ответа на следующие вопросы:
- Сколько очередей и топиков будет использоваться?
- Какие объемы сообщений ожидаются по каждому из них?
- Насколько велики сообщения в каждом адресате? Большие сообщения могут вызвать проблемы в процессе пейджинга, приводя к превышению лимитов по памяти и блокировке брокера.
- Будут ли потоки сообщений однородными в течение дня или будут всплески из-за пакетных заданий? Большие пачки в одной менее используемой очереди могут мешать своевременной записи на диск для высокопроизводительных адресатов.
- Находятся ли системы в одном датацентре или в разных? Удаленная коммуникация подразумевает какое-либо объединение брокеров в сеть.
Идея состоит в том, чтобы определить отдельные сценарии обмена сообщениями, которые можно объединить или разделить по отдельным брокерам (Figure 2-10).
После такого разбиения сценарии использования можно моделировать, сочетая друг с другом с помощью Модуля Производительности (Performance Module) ActiveMQ для выявления любых проблем.
Figure 2-10. Идентификация отдельных брокеров
После определения соответствующего количества логических брокеров, можно определить способы их реализации на физическом уровне с помощью высокодоступных конфигураций и сетей брокеров.
Итоги
В этой главе мы изучили механизм, с помощью которого ActiveMQ получает и распределяет сообщения. Мы обсудили функции, которые поддерживаются этой архитектурой, включая балансировку нагрузки (sticky load-balancing) связанных сообщений и транзакции. При этом мы ввели набор понятий, общих для всех систем обмена сообщениями, в том числе протоколы связи и журналы. Мы также подробно рассмотрели сложности, возникающие при записи на диск и то, как брокеры могут использовать такие техники, как пакетная запись для повышения производительности. Наконец, мы изучили, как можно сделать ActiveMQ высокодоступным и как его масштабировать за пределы возможностей отдельного брокера.
В следующей главе мы рассмотрим Apache Kafka и то, как её архитектура переосмысливает отношения между клиентами и брокерами для обеспечения невероятно устойчивого конвейера сообщений с пропускной способностью, во много раз большей, чем обычный брокер сообщений. Мы обсудим функциональность, которую она использует для достижения этой цели, и кратко рассмотрим архитектуру приложений, обеспечивающих эту функциональность.
Следущая часть: Понимание брокеров сообщений. Изучение механики обмена сообщениями посредством ActiveMQ и Kafka. Глава 3. Kafka
Перевод выполнен: t.me/middle_java
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Используется ли Apache ActiveMQ в вашей организации?
53.74%Да79
29.93%Нет44
8.84%Раньше использовалась, сейчас нет13
7.48%Планируем использовать11
Проголосовали 147 пользователей. Воздержались 22 пользователя.


{kind=link}
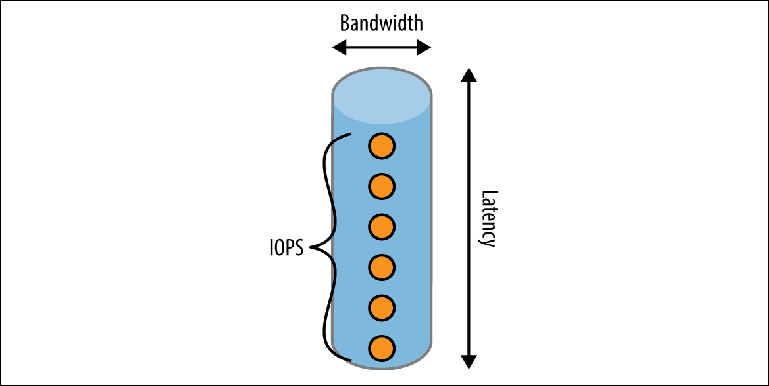{kind=link}
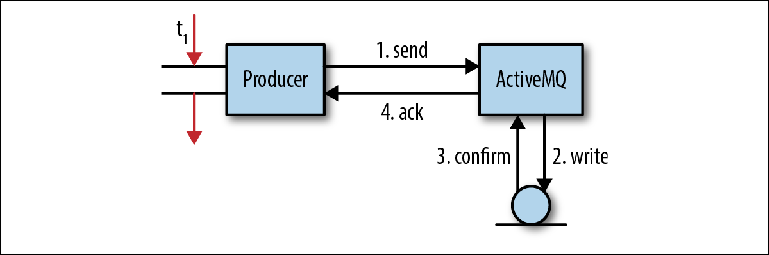{kind=link}
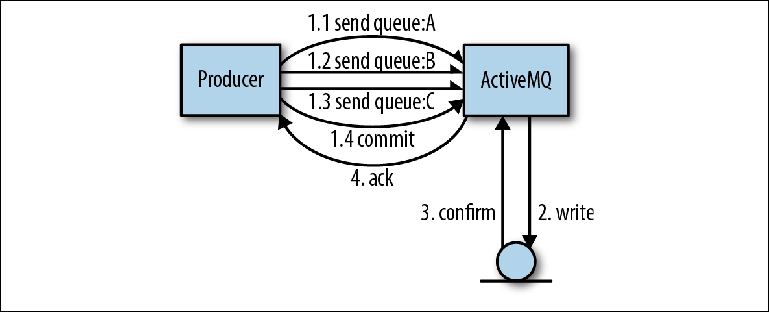{kind=link}
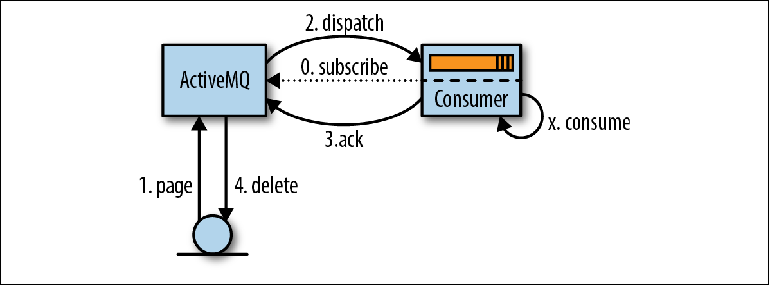{kind=link}
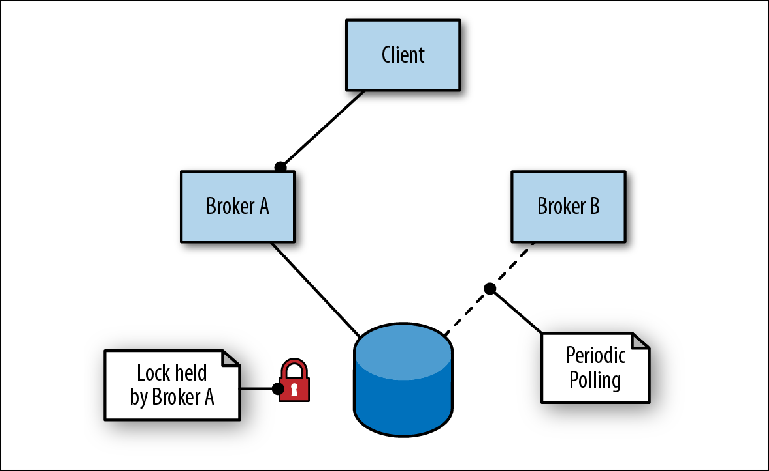{kind=link}
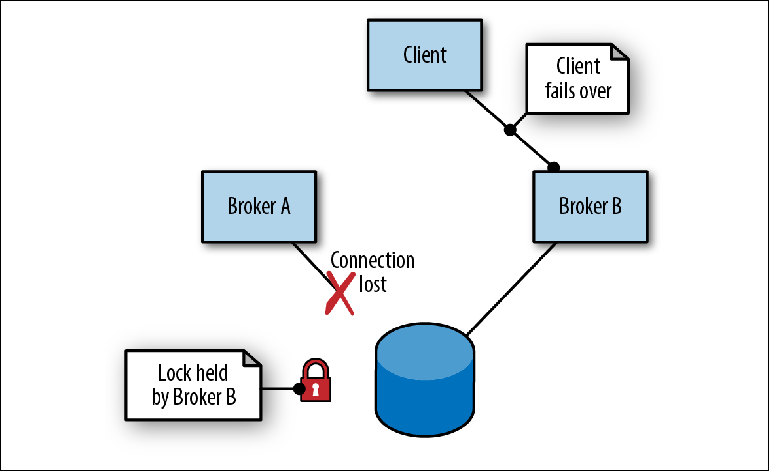{kind=link}
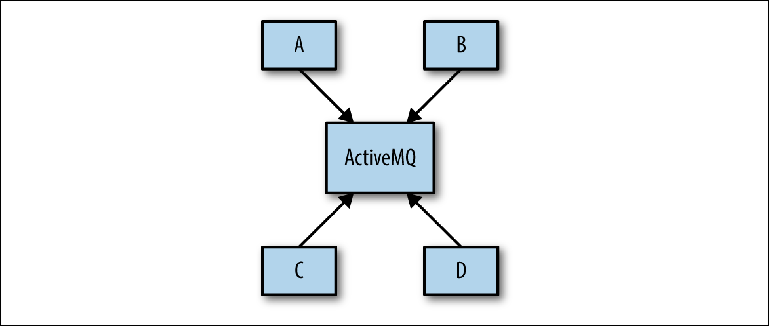{kind=link}
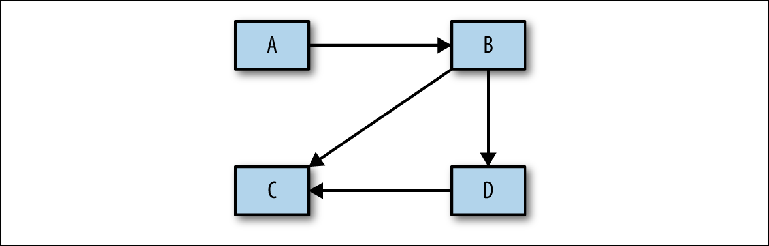{kind=link}
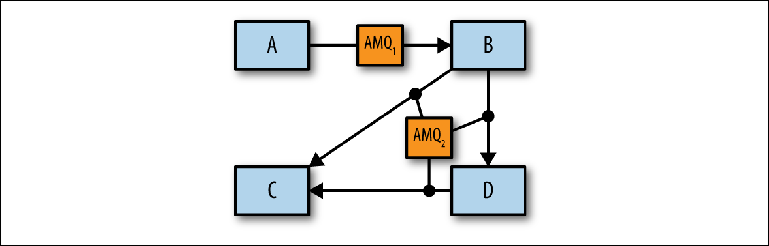{kind=link}