
Если вы закончили школу уже во времена ЕГЭ, то вам известно, что все задания в нём имеют набор стандартных формулировок и упорядочены по типам. С одной стороны, это облегчает подготовку к экзамену: школьник уже знает, что нужно делать в задании, даже не читая его условия. С другой, любое изменение порядка вопросов может вызвать у него проблемы. Грубо говоря, на результат начинает больше влиять то, насколько человек довёл решения до автоматизма, а не то, как он рассуждает. Экзамен становится похож на работу скрипта.

В рамках конференции AI Journey мы решили провести конкурс на разработку алгоритма, который сможет сдать экзамен не хуже человека. Участникам предоставляются тестовые варианты заданий, которые можно использовать для валидации решений и для обучения. Мы как сотрудники Сбера не можем претендовать на призовой фонд, но тем не менее попробовали решить эту задачу и хотим рассказать о том, как мы это сделали. Спойлер — аттестат мы получили.
Немного теории
Применение нейросетей к любым задачам сегодня – это уже история из серии: «Никогда такого не было, и вот опять». Но к каким новым задачам нейросети действительно стоит применять?
В понятие Artificial General Intelligence исторически теоретики закладывают следующие способности:
- принятие решений в условиях неопределенности
- самообучение
- оперирование базой знаний о мире
- мультидисциплинарность, совместная обработка информации из разных источников (текст, картинки, звук)
Метафора “мозг как компьютер” во многом определила эти требования, и ни одно из них, кроме обучения, пока толком не реализовано ИИ ¯\(ツ)/¯
Последние годы можно наблюдать первые попытки создать более сложные системы — например, Aristo от Allen Institute на 90% выполнила тест на общие знания для восьмого класса.
В выпускном экзамене по русскому языку 27 заданий, из которых 26 – задания с выбором ответа или открытым ответом, в котором можно вписать свой вариант, а последнее – сочинение по тексту. То есть первое задание всегда про смысл текста, четвертое – про постановку ударения, седьмое – про распространенные речевые ошибки и т.д. Это задание ставит ML-системы в ситуацию “среднего школьника”, где нужно заранее получить базовый набор умений и знаний, а затем правильно отвечать на вопросы, используя их.
Чтобы сдать русский язык, школьнику необходимо:
- научиться грамотно писать и говорить,
- научиться структурировать свои мысли,
- понимать логические связи в тексте, знать стилистику, орфографию, орфоэпию и пр.,
- прочитать внушительный список литературы от самых известных памятников древнерусской литературы до современной и оперировать основными произведениями, сюжетами, проблемами или
списать.
Зная, что современные методы NLP все же могут справляться со многими такими задачами, мы решили их и опробовать.
Все полученные нами данные представлены в json-формате, стандартизованы и содержат четкую формулировку и текст, по которому нужно выполнить задание, варианты ответа, если они предусмотрены вопросом.

Скриншот из Яндекс.Репетитора
Вопросы в заданиях сформулированы слишком витиевато для машины – нужно не только сделать задание – найти ошибки в тексте и исправить их, расставить пропущенные буквы, найти предложения, отвечающие заданным условиям, но и правильно записать ответ. Это может быть само выражение с ошибкой или, наоборот, примеры без ошибок, номера этих примеров, номера предложений в порядке возрастания и т.д. И тут мы вспомнили классика:
В искусстве ставить вопросы законоучитель Горачек был настоящий виртуоз. Он заставлял учеников перечислять в обратном порядке десять заповедей господних или требовал:
— Людвик, отвечай быстро, негодяй, какая заповедь на третьем месте от конца, перед «Не убий»?
Ярослав Гашек, «Урок закона божьего»
Как мы с этим справились в baseline?
Ответ: ¡ɯǝɓn̯оɔ ʞɐɯ и

Так как типов заданий более 27 не предусмотрено, на обучающих данных мы создали парсер json’ов, который выбирал из всего текста задания конкретно формулировку – что и как нужно сделать, – и создали на таких формулировках простейший линейный классификатор на n-грамах слов и SVM (support vector machines), который предсказывал номер задания, и система получала задание и формат ответа: https://github.com/sberbank-ai/ai-journey-2019 .
Потенциально хотелось бы реализовать в этой части решения attention-механизм или что-то подобное, чтобы найти связи между формулировками и типами вопросов. Мы надеемся, что кто-нибудь из участников подобное решение реализует.
Оценка решений
В оценке такого решения для сравнения с человеком не используются привычные метрики классификации (accuracy, f-measure.), а берется стобалльная шкала оценивания, где суммируются баллы за правильно выполненные задания.
Решения задач проверяются автоматически, а что делать с итоговым сочинением? В оценке сочинений в рамках конкурса принимают участия учителя и методологи из Москвы и Новосибирска. Они оценивают полученные сочинения по независимым критериям, среди которых орфографическая грамотность, пунктуация, логическая связность текста, наличие литературных аргументов, авторской позиции. В общем, все как в школе.
Проектировка baseline
После реализации json-парсер и классификатора вопросов мы получили конкретные типы заданий. Они сводятся к такому списку:
- проверить орфографию, вставить буквы, исправить ошибки (Н и НН, НЕ и НИ, слитно — раздельно, корни с чередованием и т.д.);
- понять по контексту значение многозначного слова (выбор ответа по контексту);
- выделить основные мысли в тексте (выбор из списка предложений);
- проставить знаки препинаний (выбрать места, где нужны запятые, тире и т.д.);
- поставить ударения в словах (найти ошибку);
- найти грамматические ошибки в примерах и указать их тип (соотнести);
- списать союзы между частями текста (основываясь на логике текста);
- написание сочинения по тексту (найти проблему и раскрыть ее).
Методом пристального вглядывания далее все типы заданий мы свели к известным методам обработки текста.
Эмбеддеры (embedders)
Эмбеддеры (word2vec, fasttext, GloVe) используются для получения векторных представлений отдельных слов, предложений и текстов. Мы используем BERT на pytorch – универсальный трансформер, чаще применяется для получения свойств слов (от Google). Такой трансформер дает высокий результат на заданиях, где нужно понять смысл многозначного слова, выделить самые содержательные предложения в тексте и т.д. – задания сводятся к выбору ближайшего эмбеддинга по косинусной мере.
Языковые модели (language models)
Языковые модели могут давать полезную информацию о вероятности следующего слова, перплексии предложения. В привязке к экзаменам их можно использовать для обнаружения и исправления речевых ошибок (нечастотные фрагменты заменять на похожие частотные) и для генерации текстов. В baseline мы использовали базу частот n-грам национального корпуса русского языка, выбирая по ней нормативные слова, а отсутствующие считали кандидатами на ошибку. Эту базу мы также используем для подстановки пропущенных букв в слова. Для генерации текстов сочинение мы также взяли “универсальную модель” – ULMFit. Это LSTM с множественным дропаутом от fast.ai, очень хорошо для генерации последовательностей. Ее мы натренировали на школьных сочинениях по литературе, которые собрали в сети. Получилось хоть и бессмысленно, зато почти без ошибок.
Парсеры морфологии и синтаксиса
Для определения части речи, падежей, числа, рода, нормальной формы слова и связей между словами мы использовали pymorphy2 и UDPipe.
Классификаторы
Задачи по пунктуации можно свести к классификации – ставить запятую в конкретном месте или нет, по какому правилу поставлено тире и т.д.
Два типа задач мы решали следующими типами архитектур:
Siamese neural network получает на вход два BERT-эмбеддинга пары предложений, решает, по одному правилу в них ставятся тире, двоеточия или нет.
Классификатор на CatBoost получает на вход окно тэгов части речи длины 6 (вида “NOUN VERB NOUN ADJ NOUN NOUN”) и принимает решение ставить или не ставить в середине запятую.
Базы знаний
То, что школьникам нужно запомнить и выучить, мы собрали из открытых источников:
1 Орфоэпический словарь (ударения) – как в школьной программе.
2 Словарь тропов – литературных средств: синонимов, антонимов, паронимов, фразеологизмов и т.д., собранный с сайтов по литературе.
3 Сборник школьных сочинений по литературе — для дообучения генеративной модели.
Модели для сочинения
Генерация текста, суммаризация, тематическое моделирование. Здесь простор для мысли был большой. В итоге мы взяли, как уже упоминалось, ULMFit для генерации текста. Но сочинение должно быть по тексту и отвечать множеству критериев. Если считать, что орфографию и связность текста мы получаем за счет ULMFit, то остается еще как минимум авторская позиция и тематическая связность нашего сочинения и данного текста.
Эти подзадачи мы решили так:
- LDA + заготовленная первая фраза. Собранные варианты школьных сочинений группируются на основании word n-грам на 30 тем, которые были нами проинтерпретированы. Каждая из тем оказалась связана с творчеством одного-двух писателей в смежной теме – сочинения про судьбу России, про положение народа, про произведения Достоевского, про творчество А. Ахматовой и ее значение для русской культуры XX века и т.д.
- TextRank + шаблоны. Алгоритм суммаризации вытаскивает 2-3 самых содержательных предложения из данного текста, и эти предложения вставляются в набор шаблонов, обрамляющих цитаты с авторской позицией.
Итоговый пайплайн: тематическая модель определяет тему текста и выдает генеративной модели первую фразу. Генеративная модель получает первую фразу и продолжает ее до конца сочинения. Затем модель суммаризации вставляет в этот текст второй абзац, в котором “отражена” авторская позиция.
Вот пример типичного сочинения, который у нас получился на такой модели (шаблоны выделены курсивом, первая фраза из тематической модели — жирным).
Судьба человека на войне, любовь к родине, любовь к матери – темы, интересующие Толстого, те, кто его оставил. и два князя Андрея Толстого — Пьер и Андрей — прошли через войну. Зла человеческие отношения суть тоже не в их ход, а в жизни, гражданских и нравственных норм. Свобода заключается и в том, что они доброго и страшного человека, чувство открытость и предательство. Они свободу — от богу — до Наполеона, для него — Наполеон. Приносит им добро и зло, поэтому великие герои составляют то, что являются представителями одних и тех же людей.
Автор иллюстрирует данную проблему на примере предложений “Когда я говорю о том, что человек не должен идти против своей совести, не должен совершать с ней сделку, я вовсе не имею в виду, что человек не может или не должен ошибаться, оступаться.” и “Я ей ответил, что не только можно, но и нужно писать об ошибках великих людей, что велик человек не тем, что он ни в чём не ошибался.”. На мой взгляд, читатель наблюдает авторскую позицию в предложении: “Но, если даже не удалось сберечь честь смолоду, её нужно и можно вернуть себе в зрелом возрасте, переломить себя, найти в себе смелость и мужество признать ошибки.”
Война — это та часть личности, которая должна дать человеку возможность иного всеобщего служения. Будущее — это освобождение, стремление к свободе, горячая любовь к родине. Это — вера в возможность Отечества. Можно сказать, что, несмотря на христианство, Пьер не может нарушить ход истории, но сделала это и в самом деле. Войну 1812 года Толстой показывает, как борьбу нового Наполеона с простым народной средой и с народом.
Перед нами предстает вся Россия, и Новгород — это часть России. Главная мысль, которая им имеет, — это связь русского народа с природой. Роман Толстого «Война и мир» — это произведение, в котором социальные проблемы тесно связаны между собой, жизнь состоит в том, что голоса, добро и зло — все это не скрывает Толстой. Достоевский писал, что для Толстого это политическая позиция. Автор вкладывает в романе свое место: здесь писатель показывает людей, которые стоят за стенами отечества. Толстой ставит пример этого и приводит в пример первый и главный герой.
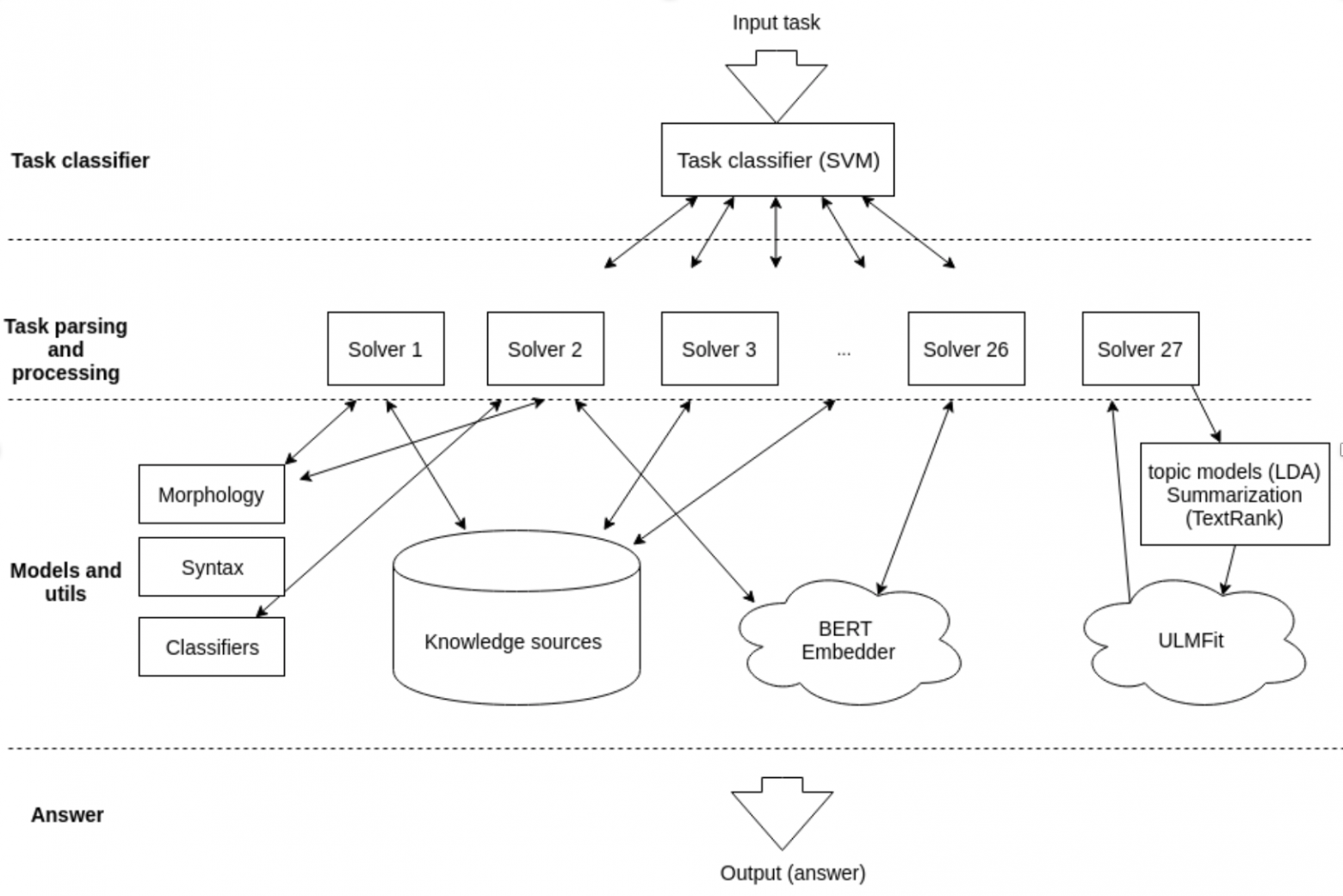
Итоговая архитектура baseline
Итоговое решение имеет следующую логику:
- Поступающее на вход задание типируется классификатором – получает тип от 1 до 27.
- На каждый из 27 заданий создан свой solver – скрипт с парсингом формулировок задания, получающий из пула доступных ML-моделей и баз знаний нужную информацию и выдающий ответ в правильном формате.
Пул моделей и баз знаний у всех solver’ов общий, загружается в память один раз.
Что же в итоге?
Baseline (пока без проверки сочинений) дает 27 баллов из 100 — базовым решением воспользовалось более 60 команд. По критериям выпускного экзамена, чтобы получить аттестат, нужно набрать 24, но, чтобы подать документы в вуз нужно минимум 36 баллов. Эту отметку сейчас прошли 2 лучших команды.
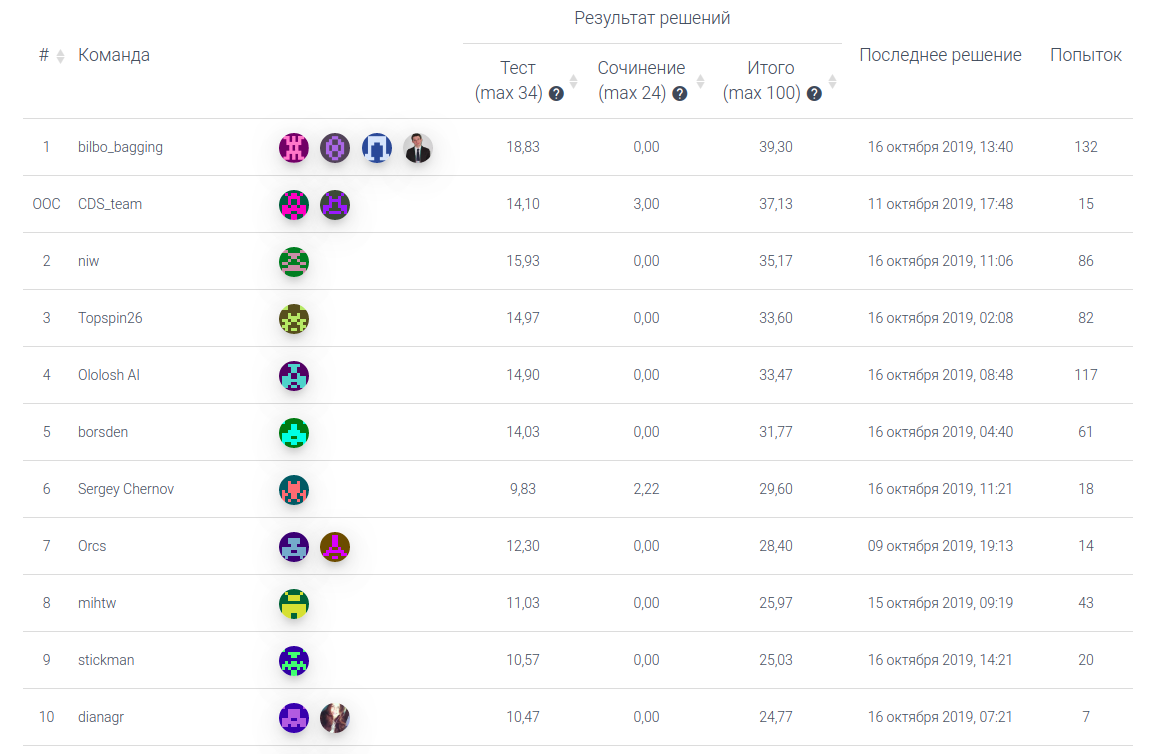
Многие участники используют наше решение как базовое, улучшая и дорабатывая подходы. Если вы интересуетесь искусственным интеллектом и готовы попробовать свои силы в такой интересной задаче, то у вас есть еще пара недель! А мы сами продолжаем улучшать модели, подаваясь вне конкурса под ником CDS_team
Финал соревнования пройдет 8 и 9 ноября на конференции AI Journey в Москве. Зарегистрироваться на соревнование и на конференцию можно здесь.
