Я расскажу вам сегодня историю. Историю эволюции вычислительной техники и появления удаленных рабочих мест с древнейших времен и до наших дней.
Главное, что можно вынести из истории ИТ — это…

Разумеется то, что ИТ развивается по спирали. Одни и те же решения и концепции, которые были отброшены десятки лет назад, обретают новый смысл и успешно начинают работать в новых условиях, при новых задачах и новых мощностях. В этом ИТ ничем не отличается от любой другой области человеческого знания и истории Земли в целом.


Этот модуль имеет размер 11 см * 11 см, и емкость в 512 байт (4096 бит). Шкаф, полностью набитый этими модулями, едва ли имел емкость древней уже на сегодня дискеты 3,5” (1.44 МБ = 2950 модулей), при этом потреблял весьма ощутимую электрическую мощность и грелся как паровоз.
Именно с огромными размерами связано и англоязычное название отладки программного кода — “debugging”. Одна из первых в истории программистов, Грейс Хоппер (да-да, женщина), офицер военно-морских сил, сделала в 1945 году запись в журнале действий после расследования неполадки с программой.

Поскольку moth (мотылек) в общем случае это bug (насекомое), все дальнейшие проблемы и действия по решению персонал докладывал начальству как “debugging” (буквально обезжучивание), то за сбоем программы и ошибкой в коде намертво закрепилось название баг, а отладка стала дебагом.
По мере развития электроники и полупроводниковой электроники в особенности, физические размеры машин стали уменьшаться, а вычислительная мощность, напротив, расти. Но даже в этом случае нельзя было поставить каждому по компьютеру персонально.

Мини — он только по сравнению с огромными машинными залами, но это все еще несколько шкафов с оборудованием ценой в сотни тысяч и миллионы долларов. Однако вычислительная мощность уже возросла настолько, что не всегда была загружена на 100%, и при этом компьютеры начали быть доступны студентам и преподавателям университетов.
И тут пришел ОН!

Немногие задумываются над латинскими корнями в английском языке, но именно он принес нам удаленный доступ, как мы знаем его сейчас. Terminus (лат) — конец, граница, цель. Целью Терминатора Т800 была окончить жизнь Джона Коннора. Так же мы знаем, что транспортные станции, на которых производится посадка-высадка пассажиров или погрузка-разгрузка грузов, называются терминалами — конечными целями маршрутов.
Соответственно появилась концепция терминального доступа, и вы можете увидеть самый известный в мире терминал, до сих пор живущий в наших сердцах.

DEC VT100 называется терминалом, поскольку оканчивает информационную линию. Имеет фактически нулевую вычислительную мощность, и его единственная задача — отобразить полученную с большой машины информацию, и передать на машину ввод с клавиатуры. И хотя VT100 физически давно умерли, мы все еще пользуемся ими в полной мере.
“Наши дни” я бы стал отсчитывать с начала 80-х, с момента появления первых доступных широкому кругу процессоров со сколько нибудь значимой вычислительной мощью. Традиционно считается, что главным процессором эпохи стал Intel 8088 (семейство x86) как родоначальник победившей архитектуры. В чем же принципиальная разница с концепцией 70х?
Впервые появляется тенденция переноса обработки информации из центра на периферию. Далеко не все задачи требуют безумных (по сравнению со слабеньким x86) мощностей мейнфрейма или даже мини-компьютера. Intel не стоит на месте, в 90х выпускает семейство Pentium, ставшем по-настоящему первым массовым домашним в России. Эти процессоры уже способны на многое, не только написать письмо — но и мультимедиа, и работать с небольшими базами данных. Фактически для малого бизнеса полностью отпадает необходимость в серверах — все можно выполнять на периферии, на клиентских машинах. С каждым годом процессоры все мощнее, а разница между серверами и персоналками все меньше и меньше с точки зрения вычислительной мощности, зачастую оставаясь только в резервировании питания, поддержки горячей замены и особых корпусах для монтажа в стойки.
Если сравнивать современные клиентские процессоры “смешной” для администраторов тяжелых серверов в 90е компании Intel с суперкомпьютерами прошлого, то и вовсе становится слегка не по себе.
Давайте взглянем на старичка, всего-то практически моего ровесника. Cray X-MP/24 1984 года.

Эта машина входила в топ суперкомпьютеров 1984, имея 2 процессора по 105 MHz с пиковой вычислительной мощностью 400 MFlops (миллионов операций с плавающей точкой). Конкретно та машина, что изображена на фото, стояла в лаборатории криптографии АНБ США, и занималась взломом шифров. Если перевести 15 млн долларов 1984 года в доллары 2020, то стоимость составит 37,4 млн, или 93 500 долларов / MFlops.

В той машине, на которой я пишу эти строки, стоит процессор Core i5-7400 2017 года, те совсем не новый, и даже в год своего выхода бывший самым младшим 4-ядерным из всех десктопных процессоров среднего уровня. 4 ядра по 3.0 GHz базовой частоты (3.5 с Turbo Boost) и удвоение потоков HyperThreading дают от 19 до 47 GFlops мощности по разным тестам при цене 16 тыс руб за процессор. Если собрать машинку целиком, то можно принять ее стоимость за 750 долларов (по ценам и курсу на 1 марта 2020).
В конечном итоге получаем превосходство вполне среднего десктопного процессора наших дней в 50-120 раз над суперкомпьютером из топ10 вполне обозримого прошлого, а падение удельной стоимости MFlops становится совсем чудовищными 93500 / 25 = 3700 раз.
Зачем нам все еще нужны серверы и централизация вычислений при подобных мощностях на периферии — решительно непонятно!
Первым сигналом, что вынос вычислений на периферию не будет окончательным, стало появление технологии бездисковых рабочих станций. При значительном распределении рабочих станций по территории предприятия, и в особенности в загрязненных помещениях, очень жестко встает вопрос управления и поддержки этих станций.

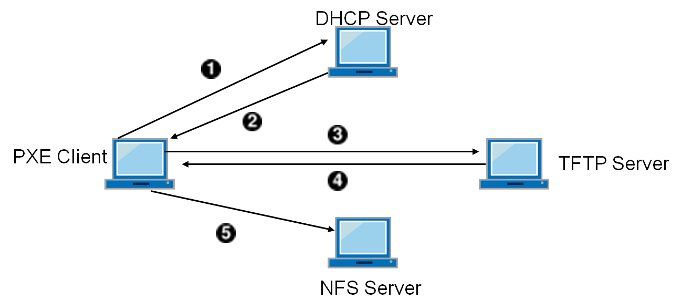
Появляется понятие “коридорное время” — те процент времени, что сотрудник техподдержки находится в коридоре, по дороге к сотруднику с проблемой. Это время оплачиваемое, но совершенно непродуктивное. Далеко не последнюю роль, и в особенности в загрязненных помещениях, составляли выходы из строя жестких дисков. Давайте уберем из рабочей станции диск, а все остальное сделаем по сети, в том числе загрузку. Сетевой адаптер получает помимо адреса от DHCP сервера так же дополнительную информацию — адрес сервера TFTP (упрощенный файловый сервис) и имя загрузочного образа, загружает его в оперативную память и стартует машину.
Помимо меньшего количество поломок и снижения коридорного времени, машину теперь можно не отлаживать на месте, а просто принести новую, и забрать старую на диагностику на оборудованное рабочее место. Но и это еще не все!
Бездисковая станция становится значительно безопаснее — если вдруг кто-то вломится в помещение и вынесет все компьютеры, это лишь потери оборудования. Никаких данных не хранится на бездисковых станциях.
Запомним этот момент, ИБ начинает играть все большую роль после “беспечного детства” информационных технологий. А в ИТ все сильнее вторгаются страшные и важные 3 буквы — GRC (Governance, Risk, Compliance), или по-русски «Управляемость, Риск, Соответствие».
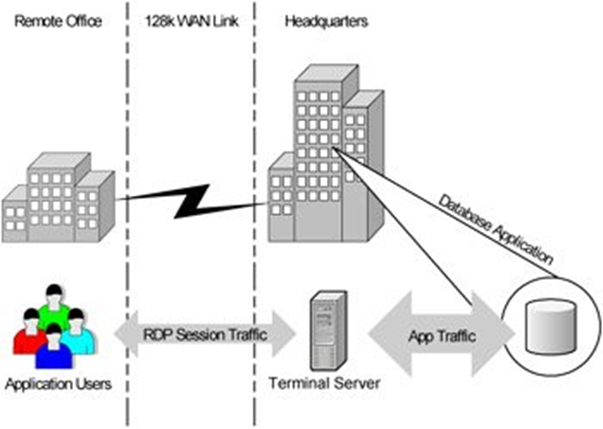
Повсеместное распространение все более и более мощных персоналок на периферии значительно опережало развитие сетей общего доступа. Классические для 90-начала 00 клиент-серверные приложения не очень хорошо работали по тонкому каналу, если обмен данными составлял сколько нибудь значимые значения. Особенно это было тяжело для удаленных офисов, подключавшихся по модему и телефонной линии, которая к тому же периодически подвисала или обрывалась. И…
Спираль сделала виток и оказалась снова в терминальном режиме с концепцией терминальных серверов.
Фактически мы вернулись к 70м с их нулевыми клиентами и централизацией вычислительной мощности. Очень быстро стало очевидно, что помимо чисто экономической подоплеки с каналами терминальный доступ дает огромные возможности по организации безопасного доступа снаруж��, в том числе работы из дома для сотрудников, или крайне ограниченного и подконтрольного доступа контракторам из недоверенных сетей и недоверенных/неконтролируемых устройств.
Однако терминальные серверы при всех их плюсах и прогрессивности, обладали также и рядом минусов — низкая гибкость, проблема шумного соседа, строго серверная Windows и тд.

Правда в начале-середине 00х уже вовсю выходила на сцену промышленная виртуализация x86 платформы. И кто-то озвучил попросту витавшую в воздухе идею: а давайте вместо централизации всех клиентов на серверных терминальных фермах дадим каждому его персональную ВМ с клиентской Windows и даже администраторским доступом?
Параллельно с виртуализацией сессий и ОС развивался подход, связанный с облегчением функции клиента на уровне приложения.
Логика за этим была довольно простая, ведь персональные ноутбуки были все еще далеко не у всех, интернет точно так же был не у всех, и многие могли подключиться только из интернет кафе с очень ограниченными, мягко говоря, правами. Фактически, все что можно было запустить — это браузер. Браузер стал непременным атрибутом ОС, интернет прочно заходил в нашу жизнь.
Иными словами, параллельно шел тренд на перенос логики с клиента в центр в виде веб-приложений, для доступа к которым нужен только самый простой клиент, интернет и браузер.
И мы оказались не просто там же, с чего начинали — с нулевых клиентов и центральных серверов. Мы пришли туда несколькими независимыми путями.

В 2007 лидер рынка промышленной виртуализации, VMware, выпустила первую версию своего продукта VDM (Virtual Desktop Manager), ставшего фактически первым на только рождающемся рынке виртуальных десктопов. Разумеется долго ждать ответа от лидера терминальных серверов Citrix не пришлось и в 2008 с приобретением XenSource появляется XenDesktop. Безусловно были и другие вендоры со своими предложениями, но не будем слишком углубляться в историю, отходя от концепции.
И до сих пор концепция сохраняется. Ключевой компонент VDI — это брокер соединений.
Именно это сердце инфраструктуры виртуальных десктопов.
Брокер отвечает за самые главные процессы работы VDI:
Сегодня клиентом (терминалом) для VDI может быть фактически вообще все, что имеет экран — ноутбук, смартфон, планшет, киоск, тонкий или нулевой клиент. А ответной частью, той самой что исполняет продуктивную нагрузку — сессия терминального сервера, физическая машина, виртуальная машина. Современные зрелые продукты VDI тесно интегрированы с виртуальной инфраструктурой и самостоятельно управляют ей в автоматическом режиме, развертывая или, наборот, удаляя уже ненужные виртуальные машины.
Немного в стороне, но для некоторых клиентов крайне важной технологией VDI, стоит поддержка аппаратного ускорения 3D графики для работы проектировщиков или дизайнеров.
Второй чрезвычайно важной частью зрелого решения VDI является протокол доступа к виртуальным ресурсам. Если речь идет о работе внутри корпоративной локальной сети с отличной надежной сетью 1 Gbps до рабочего места и задержкой в 1 ms, то можно брать фактически любой и вообще не думать.
Думать нужно когда подключение идет по неконтролируемой сети, а качество этой сети может совершенно любым, вплоть до скоростей в десятки килобит и непредсказуемыми задержками. Те как раз для организации настоящей удаленной работы, с дач, из дома, из аэропортов и закусочных.
При появлении VDI казалось, что пора прощаться с терминальными серверами. Зачем они нужны, если у каждого есть своя персональная ВМ?
Однако с точки зрения чистой экономики оказалось, что для типовых массовых рабочих мест, одинаковых до тошноты — пока нет ничего эффективнее терминальных серверов по соотношению цена / сессия. При всех своих достоинствах подход “1 пользователь = 1 ВМ” расходует значительно больше ресурсов на виртуальное железо и полноценную ОС, что ухудшает экономику на типовых рабочих местах.
В случае же рабочих мест топ-менеджеров, нестандартных и нагруженных рабочих мест, необходимости иметь высокие права (вплоть до администратора), преимущество имеет выделенная ВМ на пользователя. В рамках этой ВМ можно выделять ресурсы индивидуально, выдавать права любого уровня, и балансировать ВМ между хостами виртуализации при высокой нагрузке.
Годами я слышу один и тот же вопрос — а как, VDI дешевле чем просто ноутбуки всем раздать? И годами мне приходится отвечать ровно одно и то же: в случае с обычными офисными сотрудниками VDI не дешевле, если считать чистые затраты на обеспечение оборудованием. Как ни крути, ноутбуки дешевеют, а вот серверы, СХД и системный софт стоят довольно ощутимых денег. Если вам пришла пора обновлять парк и вы думаете сэкономить за счет VDI — нет, не сэкономите.
Я выше приводил страшные три буквы GRC — так вот, VDI это про GRC. Это про управление рисками, это про безопасность и удобство контролируемого доступа к данным. И это все стоит обычно довольно немалых денег для внедрения на куче разнородной техники. При помощи VDI контроль упрощается, безопасность повышается, а волосы становятся мягкими и шелковистыми.
Компания HPE является далеко не новичком в удаленном управлении серверной инфраструктурой, шутка ли — в марте исполнилось 18 лет легендарному iLO (Integrated Lights Out). Вспоминая свои админские времена в 00-е, лично не мог нарадоваться. Первичный монтаж в стойки и подключение кабелей — вот все, что нужно было сделать в шумном и холодном ЦОД. Все остальное конфигурирование, включая заливку ОС, можно было уже делать с рабочего места, двух мониторов и с кружкой горячего кофе. И это 13-то лет назад!

На сегодня серверы HPE неспроста являются неоспоримым многолетним ��тандартом качества — и далеко не последнюю роль в этом играет золотой стандарт системы удаленного управления — iLO.
Хочется отдельно отметить действия HPE в удержании контроля человечества над коронавирусом. HPE объявила, что до конца 2020 (как минимум) лицензия iLO Advanced доступна всем бесплатно.
Если у вас больше 10 серверов в инфраструктуре, и администратор не изнывает от скуки, то конечно отличным дополнением к стандартным средствам мониторинга будет облачная система HPE Infosight на основе искусственного интеллекта. Система не просто мониторит состояние и строит графики, но и самостоятельно рекомендует дальнейшие действия на основе текущей ситуации и трендов.
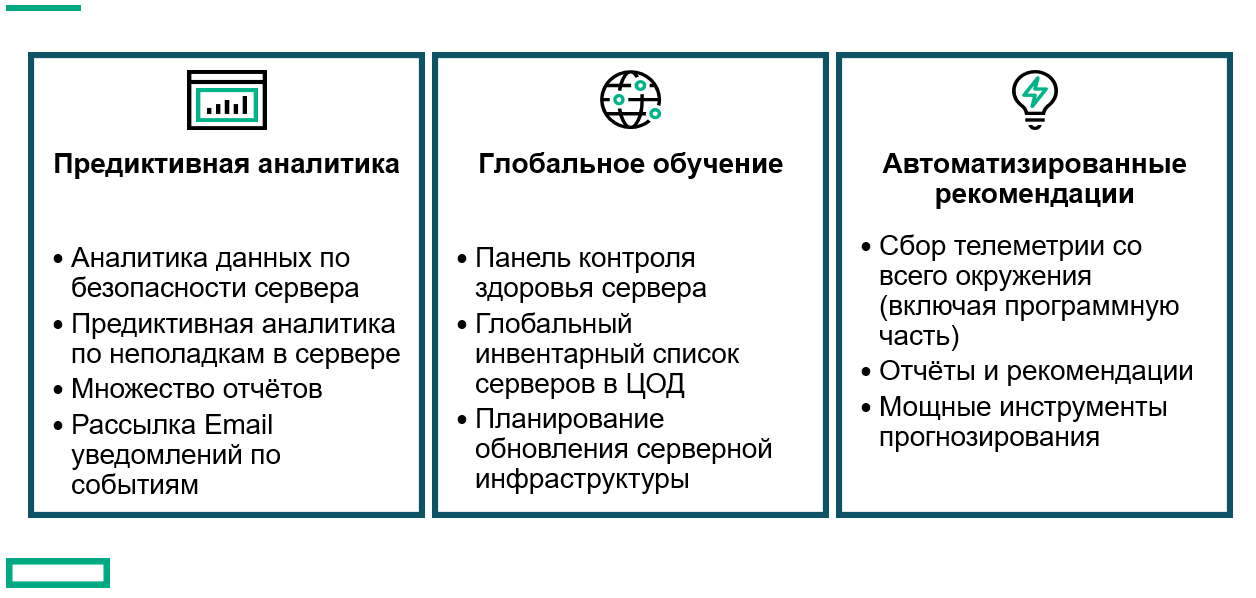
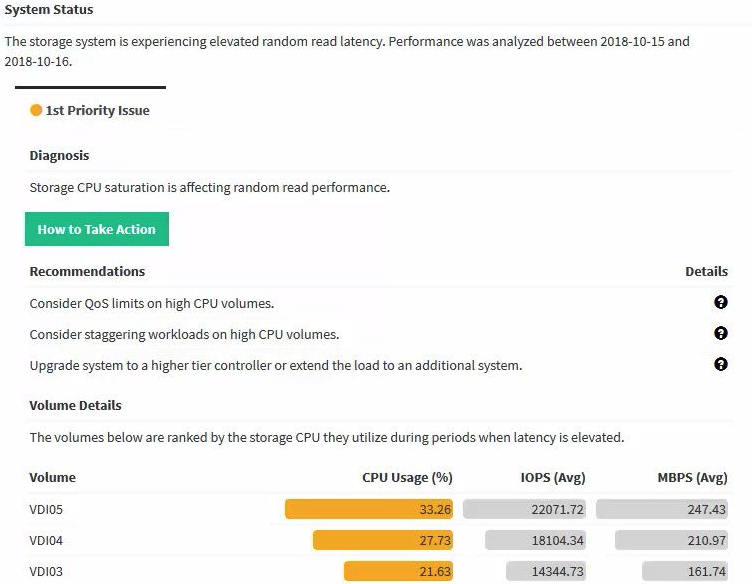
Будь умным, будь как банк “Открытие”, попробуй Infosight!
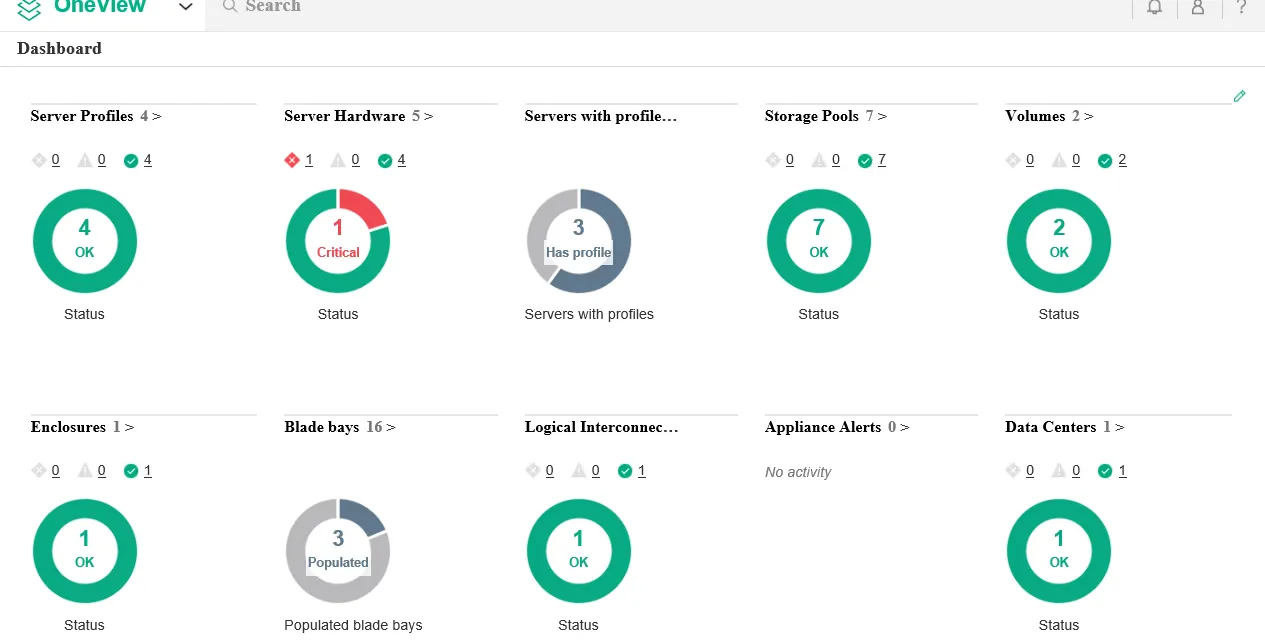
Последним по очереди, но не по значению, хочу отметить HPE OneView — целый продуктовый портфель с огромными возможностями по мониторингу и управлению всей инфраструктурой. И все это не вставая из-за рабочего стола, который возможно у вас находится в текущей ситуации вообще на даче.
Разумеется, все СХД удаленно управляются, мониторятся — так было еще много лет назад. Поэтому хочу поговорить сегодня о другом, а именно метро-кластерах.
Метро-кластеры совсем не новинка на рынке, но именно благодаря этому они до сих не слишком популярны — сказывается инерционность мышления и первые впечатления. Конечно, 10 лет назад они уже были, но вот стоили как чугунный мост. Годы, прошедшие с первых метрокластеров, поменяли индустрию и доступность технологии широкой публике.
Я помню проекты, где специально разносили части СХД — отдельно под сверхкритичные сервисы в метрокластер, отдельно на синхронную репликацию (в разы дешевле).
Фактически, в 2020 метрокластер вам не стоит ничего, если вы способны организовать две площадки и каналы. А ведь каналы под синхронную репликацию требуются ровно те же самые, что и под метрокластеры. Лицензирование софта давно уже идет пакетами — и синхронная репликация идет сразу комплектом с метрокластером, и единственное, что пока сохраняет жизнь однонаправленной репликации — это необходимость организации растянутой L2 сети. Да и то, L2 over L3 вовсю уже шагает по стране.
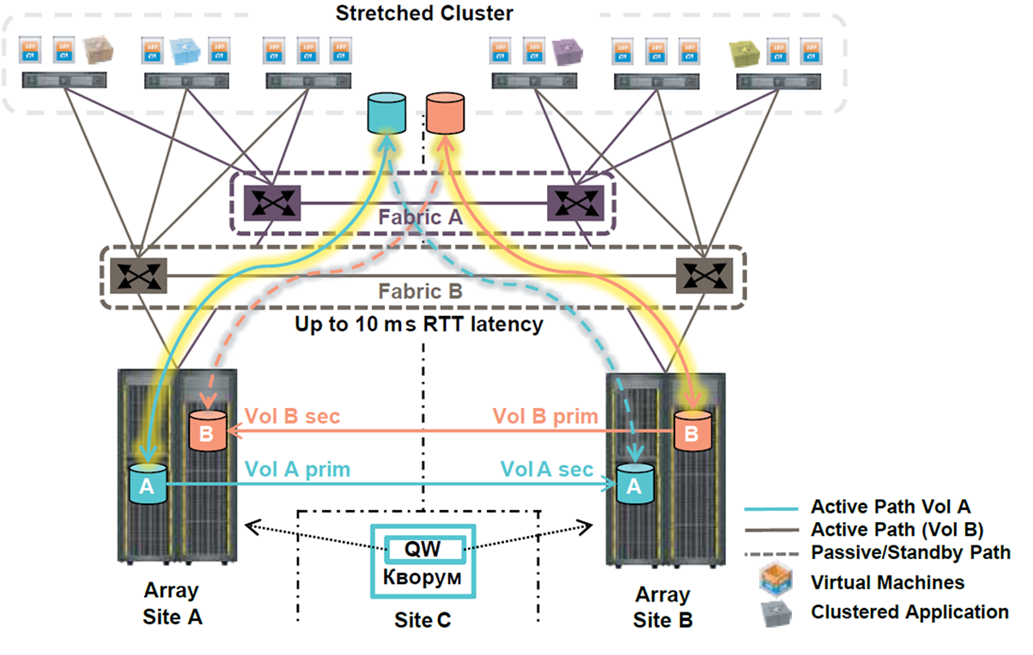
Так в чем же принципиальная разница между синхронной репликацией и метрокластером с точки зрения удаленной работы?
Все очень просто. Метрокластер работает сам, автоматически, всегда, практически мгновенно.
Как выглядит процесс переключения нагрузки на синхронной репликации на инфраструктуре хотя бы в несколько сотен ВМ?
Итого RTO (время до восстановления бизнес процессов) можно смело оценивать в 4 часа.
Сравним с ситуацией на метрокластере.
Итого: RTO = 0 для отдельных сервисов, 10-15 минут в общем случае.
Почему же перезапуск только от половины до трети ВМ? Смотрите в чем дело:
При грамотно построенной инфраструктуре с растянутыми метрокластерами бизнес пользователи работают с минимальными задержками из любой точки, даже в случае аварии на уровне ЦОД. В худшем случае задержка составит время на одну чашку кофе.
И, разумеется, метрокластеры отлично работают как на уходящих в сторону Валинора HPE 3Par, так и на новеньких Primera!

Для терминальных серверов не нужно придумывать ничего нового, уже много лет HPE поставляет одни из лучших серверов в мире для них. Нестареющая классика — DL360 (1U) или DL380 (2U) или для любителей AMD — DL385. Конечно, есть и блейд серверы, как классические C7000, так и новая компонуемая платформа Synergy.

На любой вкус, на любой цвет, максимум сессий на сервер!
В данном случае говоря “классическим VDI” я подразумеваю концепцию 1 пользователь = 1 ВМ с клиентской Windows. И конечно же, нет ближе и роднее VDI нагрузки для гиперконвергентных систем, тем более с дедупликацией и компрессией.

Здесь HPE может предложить как собственную гиперконвергентную платформу Simplivity, так и серверы / сертифицированные узлы под решения партнеров, как например VSAN Ready Nodes для построения VDI на инфраструктуре VMware VSAN.
Давайте поговорим чуть больше о собственном решении Simplivity. Во главу угла, как нам мягко намекает название, поставлена простота (англ simple — простой). Простота развертывания, простота управления, простота масштабирования.
Гиперконвергентные системы на сегодня — одна из самых горячих тем в ИТ, а количество вендоров разного уровня составляет около 40. Согласно магическому квадрату Gartner, компания HPE находится в Тор5 глобально, и входит в квадрат лидеров — те понимает и куда развивается индустрия, и способна это понимание воплотить в железе.
Архитектурно Simplivity является классической гиперконвергентной системой с контроллерными виртуальными машинами, а значит мождет поддерживать различные гипервизоры, в отличие от интегрированных в гипервизор систем. И действительно, на апрель 2020 поддерживаются VMware vSphere и Microsoft Hyper-V, и озвучены планы по поддержке KVM. Ключевой фишкой Simplivity с момента ее появления на рынке было аппаратное ускорение компрессии и дедупликации с помощью специальной карты-акселератора.
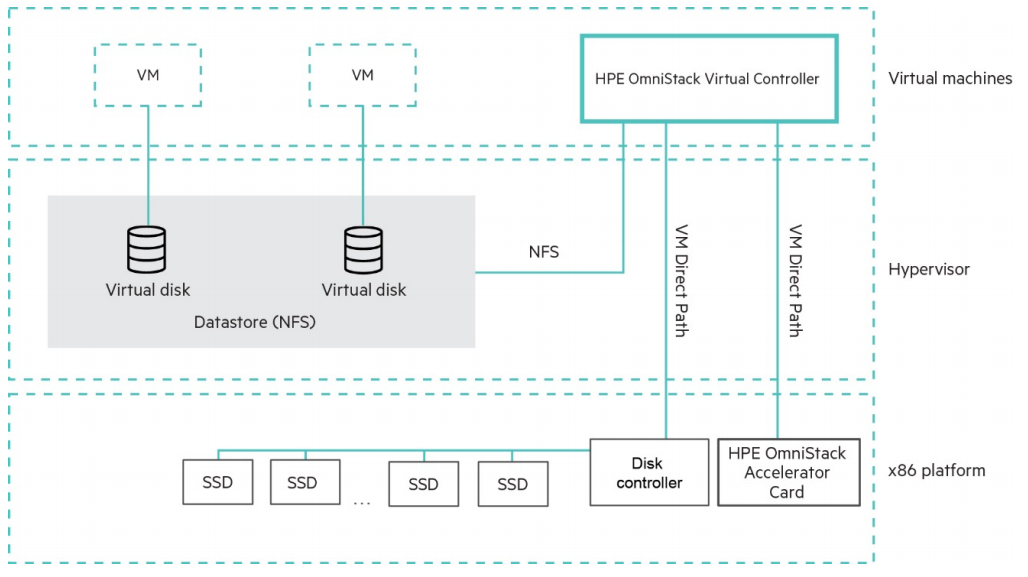
Нужно отметить, что компрессия с дедупликацией являются глобальными и постоянно включенными, те это не опциональная фича, а архитектура решения.
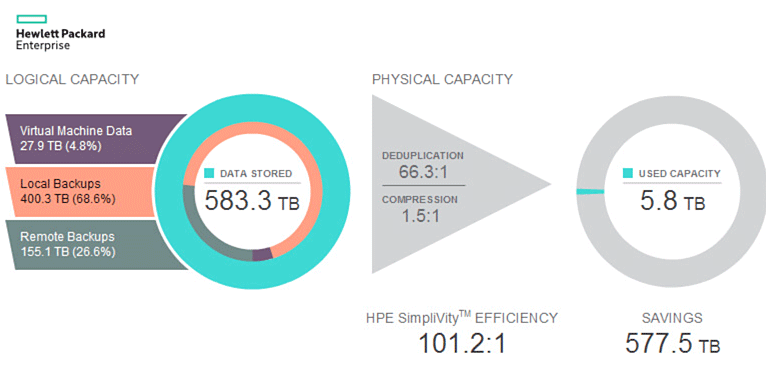
HPE конечно несколько лукавит, утверждая эффективность 100:1, посчитав особым образом, но эффективность использования пространства действительно очень высока. Просто цифра 100:1 уж больно красивая. Давайте разберемся, как же реализована Simplivity технически, чтобы показать такие цифры.
Snapshot. Снэпшоты (мгновенные снимки) — 100% правильно реализованы как RoW (Redirect-on-Write), а следовательно происходят моментально и не дают штрафа к произво��ительности. Чем например отличаются от некоторых других систем. Зачем нам нужны локальные снэпшоты без штрафов? Да очень просто, для снижения RPO с 24 часов (среднее RPO для резервного копирования) до десятков или даже единиц минут.
Backup. Снэпшот от бэкапа отличается только тем, как его воспринимает система управления виртуальными машинами. Если при удалении машины удаляется и все остальное — значит это был снапшот. Если осталось — значит бэкап (резервная копия). Таким образом любой снапшот может считаться и полным бэкапом, если его пометить в системе и не удалять.
Конечно, многие возразят — какой же это бэкап, если он на той же системе хранится? А здесь есть очень простой ответ в виде встречного вопроса: скажите, а у вас есть формальная модель угроз, устанавливающая правила хранения резервной копии? Это абсолютно честный бэкап против удаления файла внутри ВМ, это бэкап против удаления самой ВМ. В случае же небоходимости хранения резервной копии исключительно на отдельно стоящей системе есть на выбор: репликация этого снэпшота на второй кластер Simplivity или на HPE StoreOnce.
И вот именно здесь оказывается, что подобная архитектура просто идеально подходит под любого вида VDI. Ведь VDI — это сотни или даже тысячи крайне похожих машин с одной и той же ОС, с одними и теми же приложениями. Глобальная дедупликация все это пережует и сожмет даже не 100:1, а куда лучше. Развернуть 1000 ВМ из одного шаблона? Вообще не проблема, эти машины будут дольше регистрироваться в vCenter, чем клонироваться.
Специально для пользователей с особыми требованиями к производительности, и для тех, кому нужно 3D ускорители, была создана линейка Simplivity G.

В этой серии не используется аппаратный ускоритель дедупликации, и поэтому снижено количество дисков на узел, чтобы контроллер справлялся программно. Благодаря этому освобождаются слоты PCIe под любые другие ускорители. Так же удвоен объем доступной памяти на узел до 3ТБ для самых требовательных нагрузок.

Simplivity идеально подходит для организации географически распределенных VDI инфраструктур с репликацией данных в центральный ЦОД.
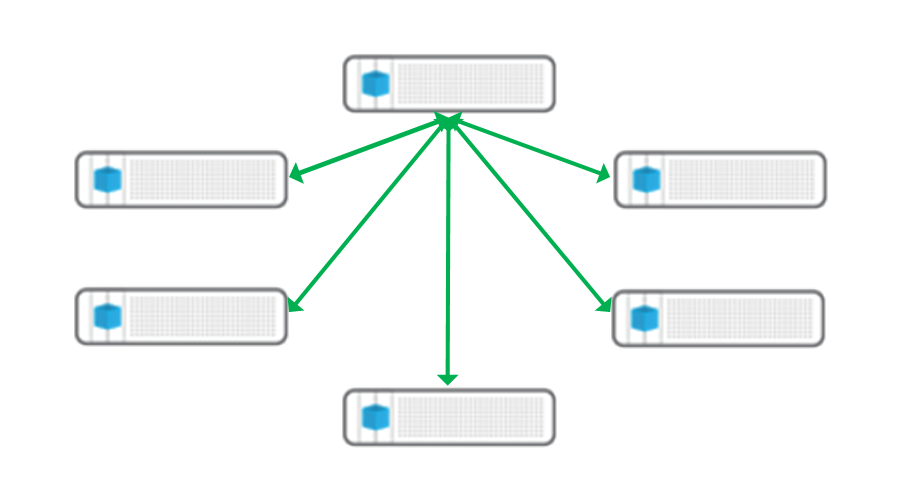
Подобная архитектура VDI (а впрочем и не только VDI) особенно интересна в условиях российских реалий — огромные расстояния (и следовательно задержки) и далеко не идеальные каналы. Создаются региональные центры (а даже и просто 1-2 узла Simplivity в совсем удаленный офис), куда подключаются местные пользователи по быстрым каналам, сохраняется полный контроль и управление из центра, а в центр реплицируется только незначительное количество уже настоящих, ценных, а не мусорных данных.
Разумеется, Simplivity полностью подключается к OneView и InfoSight.
Тонкие клиенты — специализированные решения для применения исключительно в качестве терминалов. Поскольку на клиент фактически нет нагрузки кроме поддержания канала и декодирования видео — практически всегда стоит процессор с пассивным охлаждением, небольшой загрузочный диск только для старта специальной встраиваемой ОС, да в общем-то и все. Ломаться в нем практически нечему, а красть бесполезно. Стоимость невелика и никаких данных в нем не сохраняется.
Существует особая категория тонких клиентов, так называемые нулевые клиенты. Их основное отличие от тонких — отсутствие даже встраиваемой ОС общего назначения, и работа исключительно с микрочипа с прошивкой. Зачастую в них ставят специальные аппаратные ускорители для декодирования видеопотока в терминальных протоколах, таких как PCoIP или HDX.
Несмотря на разделение большого “Хьюлетт Паккард” на отдельные HPE и HP, нельзя не упомянуть тонкие клиенты производства HP.
Выбор широк, на любой вкус и потребности — вплоть до многомониторных рабочих мест с аппаратным ускорением видеопотока.

И последним по списку, но не по значению, хочу упомянуть сервис HPE. Было бы слишком долго перечислять все уровни сервиса HPE и его возможности, но как минимум есть одно крайне важное предложение в условиях удаленной работы. А именно — сервисный инженер от HPE/авторизованного сервис-центра. Вы продолжаете работать удаленно, с любимой дачи, слушая шмелей, пока пчелка от HPE, приехав в датацентр, заменяет в ваших серверах диски или вышедший из строя блок питания.
В условиях сегодняшего дня, при ограничении передвижений, как никогда актуальной становится функция Call Home. Любая система HPE с данной функцией может самостоятельно сообщить об аппаратном или программном сбое в центр поддержки HPE. И вполне вероятно, деталь на замену и/или сервисный инженер к вам прибудет еще задолго до того, как вы заметите неполадки и проблемы с продуктивными сервисами.
Лично я функцию эту включать настоятельно рекомендую.
Развитие ИТ
Главное, что можно вынести из истории ИТ — это…
Разумеется то, что ИТ развивается по спирали. Одни и те же решения и концепции, которые были отброшены десятки лет назад, обретают новый смысл и успешно начинают работать в новых условиях, при новых задачах и новых мощностях. В этом ИТ ничем не отличается от любой другой области человеческого знания и истории Земли в целом.
Давным-давно, когда компьютеры были большими
“Я думаю, в мире есть рынок примерно для пяти компьютеров”, глава IBM Томас Уотсон в 1943.Ранняя компьютерная техника была большой. Нет, неправильно, ранняя техника была чудовищной, циклопической. Полностью вычислительная машина занимала площадь, сравнимую со спортивным залом, а стоила совершенно нереальных денег. В качестве примера комплектующих можно привести модуль оперативной памяти на ферритовых кольцах (1964).
Этот модуль имеет размер 11 см * 11 см, и емкость в 512 байт (4096 бит). Шкаф, полностью набитый этими модулями, едва ли имел емкость древней уже на сегодня дискеты 3,5” (1.44 МБ = 2950 модулей), при этом потреблял весьма ощутимую электрическую мощность и грелся как паровоз.
Именно с огромными размерами связано и англоязычное название отладки программного кода — “debugging”. Одна из первых в истории программистов, Грейс Хоппер (да-да, женщина), офицер военно-морских сил, сделала в 1945 году запись в журнале действий после расследования неполадки с программой.
Поскольку moth (мотылек) в общем случае это bug (насекомое), все дальнейшие проблемы и действия по решению персонал докладывал начальству как “debugging” (буквально обезжучивание), то за сбоем программы и ошибкой в коде намертво закрепилось название баг, а отладка стала дебагом.
По мере развития электроники и полупроводниковой электроники в особенности, физические размеры машин стали уменьшаться, а вычислительная мощность, напротив, расти. Но даже в этом случае нельзя было поставить каждому по компьютеру персонально.
“Нет никаких причин, чтобы кто-то захотел держать компьютер у себя дома” — Кен Олсен, основатель DEC, 1977.В 70е появляется термин мини-компьютер. Помню, что когда впервые прочитал этот термин много лет назад, мне представилось что-то типа нетбука, практически наладонник. Я ��е мог быть дальше от истины.
Мини — он только по сравнению с огромными машинными залами, но это все еще несколько шкафов с оборудованием ценой в сотни тысяч и миллионы долларов. Однако вычислительная мощность уже возросла настолько, что не всегда была загружена на 100%, и при этом компьютеры начали быть доступны студентам и преподавателям университетов.
И тут пришел ОН!
Немногие задумываются над латинскими корнями в английском языке, но именно он принес нам удаленный доступ, как мы знаем его сейчас. Terminus (лат) — конец, граница, цель. Целью Терминатора Т800 была окончить жизнь Джона Коннора. Так же мы знаем, что транспортные станции, на которых производится посадка-высадка пассажиров или погрузка-разгрузка грузов, называются терминалами — конечными целями маршрутов.
Соответственно появилась концепция терминального доступа, и вы можете увидеть самый известный в мире терминал, до сих пор живущий в наших сердцах.
DEC VT100 называется терминалом, поскольку оканчивает информационную линию. Имеет фактически нулевую вычислительную мощность, и его единственная задача — отобразить полученную с большой машины информацию, и передать на машину ввод с клавиатуры. И хотя VT100 физически давно умерли, мы все еще пользуемся ими в полной мере.
Наши дни
“Наши дни” я бы стал отсчитывать с начала 80-х, с момента появления первых доступных широкому кругу процессоров со сколько нибудь значимой вычислительной мощью. Традиционно считается, что главным процессором эпохи стал Intel 8088 (семейство x86) как родоначальник победившей архитектуры. В чем же принципиальная разница с концепцией 70х?
Впервые появляется тенденция переноса обработки информации из центра на периферию. Далеко не все задачи требуют безумных (по сравнению со слабеньким x86) мощностей мейнфрейма или даже мини-компьютера. Intel не стоит на месте, в 90х выпускает семейство Pentium, ставшем по-настоящему первым массовым домашним в России. Эти процессоры уже способны на многое, не только написать письмо — но и мультимедиа, и работать с небольшими базами данных. Фактически для малого бизнеса полностью отпадает необходимость в серверах — все можно выполнять на периферии, на клиентских машинах. С каждым годом процессоры все мощнее, а разница между серверами и персоналками все меньше и меньше с точки зрения вычислительной мощности, зачастую оставаясь только в резервировании питания, поддержки горячей замены и особых корпусах для монтажа в стойки.
Если сравнивать современные клиентские процессоры “смешной” для администраторов тяжелых серверов в 90е компании Intel с суперкомпьютерами прошлого, то и вовсе становится слегка не по себе.
Давайте взглянем на старичка, всего-то практически моего ровесника. Cray X-MP/24 1984 года.
Эта машина входила в топ суперкомпьютеров 1984, имея 2 процессора по 105 MHz с пиковой вычислительной мощностью 400 MFlops (миллионов операций с плавающей точкой). Конкретно та машина, что изображена на фото, стояла в лаборатории криптографии АНБ США, и занималась взломом шифров. Если перевести 15 млн долларов 1984 года в доллары 2020, то стоимость составит 37,4 млн, или 93 500 долларов / MFlops.
В той машине, на которой я пишу эти строки, стоит процессор Core i5-7400 2017 года, те совсем не новый, и даже в год своего выхода бывший самым младшим 4-ядерным из всех десктопных процессоров среднего уровня. 4 ядра по 3.0 GHz базовой частоты (3.5 с Turbo Boost) и удвоение потоков HyperThreading дают от 19 до 47 GFlops мощности по разным тестам при цене 16 тыс руб за процессор. Если собрать машинку целиком, то можно принять ее стоимость за 750 долларов (по ценам и курсу на 1 марта 2020).
В конечном итоге получаем превосходство вполне среднего десктопного процессора наших дней в 50-120 раз над суперкомпьютером из топ10 вполне обозримого прошлого, а падение удельной стоимости MFlops становится совсем чудовищными 93500 / 25 = 3700 раз.
Зачем нам все еще нужны серверы и централизация вычислений при подобных мощностях на периферии — решительно непонятно!
Обратный скачок — спираль сделала виток
Бездисковые станции
Первым сигналом, что вынос вычислений на периферию не будет окончательным, стало появление технологии бездисковых рабочих станций. При значительном распределении рабочих станций по территории предприятия, и в особенности в загрязненных помещениях, очень жестко встает вопрос управления и поддержки этих станций.
Появляется понятие “коридорное время” — те процент времени, что сотрудник техподдержки находится в коридоре, по дороге к сотруднику с проблемой. Это время оплачиваемое, но совершенно непродуктивное. Далеко не последнюю роль, и в особенности в загрязненных помещениях, составляли выходы из строя жестких дисков. Давайте уберем из рабочей станции диск, а все остальное сделаем по сети, в том числе загрузку. Сетевой адаптер получает помимо адреса от DHCP сервера так же дополнительную информацию — адрес сервера TFTP (упрощенный файловый сервис) и имя загрузочного образа, загружает его в оперативную память и стартует машину.
Помимо меньшего количество поломок и снижения коридорного времени, машину теперь можно не отлаживать на месте, а просто принести новую, и забрать старую на диагностику на оборудованное рабочее место. Но и это еще не все!
Бездисковая станция становится значительно безопаснее — если вдруг кто-то вломится в помещение и вынесет все компьютеры, это лишь потери оборудования. Никаких данных не хранится на бездисковых станциях.
Запомним этот момент, ИБ начинает играть все большую роль после “беспечного детства” информационных технологий. А в ИТ все сильнее вторгаются страшные и важные 3 буквы — GRC (Governance, Risk, Compliance), или по-русски «Управляемость, Риск, Соответствие».
Терминальные серверы
Повсеместное распространение все более и более мощных персоналок на периферии значительно опережало развитие сетей общего доступа. Классические для 90-начала 00 клиент-серверные приложения не очень хорошо работали по тонкому каналу, если обмен данными составлял сколько нибудь значимые значения. Особенно это было тяжело для удаленных офисов, подключавшихся по модему и телефонной линии, которая к тому же периодически подвисала или обрывалась. И…
Спираль сделала виток и оказалась снова в терминальном режиме с концепцией терминальных серверов.
Фактически мы вернулись к 70м с их нулевыми клиентами и централизацией вычислительной мощности. Очень быстро стало очевидно, что помимо чисто экономической подоплеки с каналами терминальный доступ дает огромные возможности по организации безопасного доступа снаруж��, в том числе работы из дома для сотрудников, или крайне ограниченного и подконтрольного доступа контракторам из недоверенных сетей и недоверенных/неконтролируемых устройств.
Однако терминальные серверы при всех их плюсах и прогрессивности, обладали также и рядом минусов — низкая гибкость, проблема шумного соседа, строго серверная Windows и тд.
Рождение прото VDI
Правда в начале-середине 00х уже вовсю выходила на сцену промышленная виртуализация x86 платформы. И кто-то озвучил попросту витавшую в воздухе идею: а давайте вместо централизации всех клиентов на серверных терминальных фермах дадим каждому его персональную ВМ с клиентской Windows и даже администраторским доступом?
Отказ от толстых клиентов
Параллельно с виртуализацией сессий и ОС развивался подход, связанный с облегчением функции клиента на уровне приложения.
Логика за этим была довольно простая, ведь персональные ноутбуки были все еще далеко не у всех, интернет точно так же был не у всех, и многие могли подключиться только из интернет кафе с очень ограниченными, мягко говоря, правами. Фактически, все что можно было запустить — это браузер. Браузер стал непременным атрибутом ОС, интернет прочно заходил в нашу жизнь.
Иными словами, параллельно шел тренд на перенос логики с клиента в центр в виде веб-приложений, для доступа к которым нужен только самый простой клиент, интернет и браузер.
И мы оказались не просто там же, с чего начинали — с нулевых клиентов и центральных серверов. Мы пришли туда несколькими независимыми путями.
Virtual Desktop Infrastructure
Брокер
В 2007 лидер рынка промышленной виртуализации, VMware, выпустила первую версию своего продукта VDM (Virtual Desktop Manager), ставшего фактически первым на только рождающемся рынке виртуальных десктопов. Разумеется долго ждать ответа от лидера терминальных серверов Citrix не пришлось и в 2008 с приобретением XenSource появляется XenDesktop. Безусловно были и другие вендоры со своими предложениями, но не будем слишком углубляться в историю, отходя от концепции.
И до сих пор концепция сохраняется. Ключевой компонент VDI — это брокер соединений.
Именно это сердце инфраструктуры виртуальных десктопов.
Брокер отвечает за самые главные процессы работы VDI:
- Определяет доступные для подключившегося клиента ресурсы (машины/сессии);
- Балансирует при необходимости клиентов по пулам машин/сессий;
- Пробрасывает клиента на выбранный ресурс.
Сегодня клиентом (терминалом) для VDI может быть фактически вообще все, что имеет экран — ноутбук, смартфон, планшет, киоск, тонкий или нулевой клиент. А ответной частью, той самой что исполняет продуктивную нагрузку — сессия терминального сервера, физическая машина, виртуальная машина. Современные зрелые продукты VDI тесно интегрированы с виртуальной инфраструктурой и самостоятельно управляют ей в автоматическом режиме, развертывая или, наборот, удаляя уже ненужные виртуальные машины.
Немного в стороне, но для некоторых клиентов крайне важной технологией VDI, стоит поддержка аппаратного ускорения 3D графики для работы проектировщиков или дизайнеров.
Протокол
Второй чрезвычайно важной частью зрелого решения VDI является протокол доступа к виртуальным ресурсам. Если речь идет о работе внутри корпоративной локальной сети с отличной надежной сетью 1 Gbps до рабочего места и задержкой в 1 ms, то можно брать фактически любой и вообще не думать.
Думать нужно когда подключение идет по неконтролируемой сети, а качество этой сети может совершенно любым, вплоть до скоростей в десятки килобит и непредсказуемыми задержками. Те как раз для организации настоящей удаленной работы, с дач, из дома, из аэропортов и закусочных.
Терминальные серверы vs клиентские ВМ
При появлении VDI казалось, что пора прощаться с терминальными серверами. Зачем они нужны, если у каждого есть своя персональная ВМ?
Однако с точки зрения чистой экономики оказалось, что для типовых массовых рабочих мест, одинаковых до тошноты — пока нет ничего эффективнее терминальных серверов по соотношению цена / сессия. При всех своих достоинствах подход “1 пользователь = 1 ВМ” расходует значительно больше ресурсов на виртуальное железо и полноценную ОС, что ухудшает экономику на типовых рабочих местах.
В случае же рабочих мест топ-менеджеров, нестандартных и нагруженных рабочих мест, необходимости иметь высокие права (вплоть до администратора), преимущество имеет выделенная ВМ на пользователя. В рамках этой ВМ можно выделять ресурсы индивидуально, выдавать права любого уровня, и балансировать ВМ между хостами виртуализации при высокой нагрузке.
VDI и экономика
Годами я слышу один и тот же вопрос — а как, VDI дешевле чем просто ноутбуки всем раздать? И годами мне приходится отвечать ровно одно и то же: в случае с обычными офисными сотрудниками VDI не дешевле, если считать чистые затраты на обеспечение оборудованием. Как ни крути, ноутбуки дешевеют, а вот серверы, СХД и системный софт стоят довольно ощутимых денег. Если вам пришла пора обновлять парк и вы думаете сэкономить за счет VDI — нет, не сэкономите.
Я выше приводил страшные три буквы GRC — так вот, VDI это про GRC. Это про управление рисками, это про безопасность и удобство контролируемого доступа к данным. И это все стоит обычно довольно немалых денег для внедрения на куче разнородной техники. При помощи VDI контроль упрощается, безопасность повышается, а волосы становятся мягкими и шелковистыми.
Решения HPE для удаленной работы
Удаленное и облачное управление
iLO
Компания HPE является далеко не новичком в удаленном управлении серверной инфраструктурой, шутка ли — в марте исполнилось 18 лет легендарному iLO (Integrated Lights Out). Вспоминая свои админские времена в 00-е, лично не мог нарадоваться. Первичный монтаж в стойки и подключение кабелей — вот все, что нужно было сделать в шумном и холодном ЦОД. Все остальное конфигурирование, включая заливку ОС, можно было уже делать с рабочего места, двух мониторов и с кружкой горячего кофе. И это 13-то лет назад!
На сегодня серверы HPE неспроста являются неоспоримым многолетним ��тандартом качества — и далеко не последнюю роль в этом играет золотой стандарт системы удаленного управления — iLO.
Хочется отдельно отметить действия HPE в удержании контроля человечества над коронавирусом. HPE объявила, что до конца 2020 (как минимум) лицензия iLO Advanced доступна всем бесплатно.
Infosight
Если у вас больше 10 серверов в инфраструктуре, и администратор не изнывает от скуки, то конечно отличным дополнением к стандартным средствам мониторинга будет облачная система HPE Infosight на основе искусственного интеллекта. Система не просто мониторит состояние и строит графики, но и самостоятельно рекомендует дальнейшие действия на основе текущей ситуации и трендов.
Будь умным, будь как банк “Открытие”, попробуй Infosight!
OneView
Последним по очереди, но не по значению, хочу отметить HPE OneView — целый продуктовый портфель с огромными возможностями по мониторингу и управлению всей инфраструктурой. И все это не вставая из-за рабочего стола, который возможно у вас находится в текущей ситуации вообще на даче.
СХД тоже не лыком шиты!
Разумеется, все СХД удаленно управляются, мониторятся — так было еще много лет назад. Поэтому хочу поговорить сегодня о другом, а именно метро-кластерах.
Метро-кластеры совсем не новинка на рынке, но именно благодаря этому они до сих не слишком популярны — сказывается инерционность мышления и первые впечатления. Конечно, 10 лет назад они уже были, но вот стоили как чугунный мост. Годы, прошедшие с первых метрокластеров, поменяли индустрию и доступность технологии широкой публике.
Я помню проекты, где специально разносили части СХД — отдельно под сверхкритичные сервисы в метрокластер, отдельно на синхронную репликацию (в разы дешевле).
Фактически, в 2020 метрокластер вам не стоит ничего, если вы способны организовать две площадки и каналы. А ведь каналы под синхронную репликацию требуются ровно те же самые, что и под метрокластеры. Лицензирование софта давно уже идет пакетами — и синхронная репликация идет сразу комплектом с метрокластером, и единственное, что пока сохраняет жизнь однонаправленной репликации — это необходимость организации растянутой L2 сети. Да и то, L2 over L3 вовсю уже шагает по стране.
Так в чем же принципиальная разница между синхронной репликацией и метрокластером с точки зрения удаленной работы?
Все очень просто. Метрокластер работает сам, автоматически, всегда, практически мгновенно.
Как выглядит процесс переключения нагрузки на синхронной репликации на инфраструктуре хотя бы в несколько сотен ВМ?
- Поступает сигнал об аварии.
- Дежурная смена анализирует обстановку — можно смело закладывать от 10 до 30 минут только на получение сигнала и принятие решения.
- В случае отсутствия полномочий у дежурных инженеров на самостоятельный старт переключения — еще смело 30 минут на связь с лицом, имеющим полномочия, и формальное подтверждение начала переключения.
- Нажатие Большой Красной Кнопки.
- 10-15 минут на таймауты и перемонтирование томов, перерегистрацию ВМ.
- 30 минут на смену IP адресации — оптимистичная оценка.
- И наконец старт ВМ и запуск продуктивных сервисов.
Итого RTO (время до восстановления бизнес процессов) можно смело оценивать в 4 часа.
Сравним с ситуацией на метрокластере.
- СХД понимает, что связь с плечом метрокластера утеряна — 15-30 секунд.
- Хосты виртуализации понимают, что первый ЦОД утерян — 15-30 секунд (одновременно с п 1).
- Автоматический перезапуск от половины до трети ВМ во втором ЦОД — 10-15 минут до загрузки сервисов.
- Примерно в это время дежурная смена понимает что произошло.
Итого: RTO = 0 для отдельных сервисов, 10-15 минут в общем случае.
Почему же перезапуск только от половины до трети ВМ? Смотрите в чем дело:
- Вы же все делаете умно, и включаете автоматическую балансировку ВМ. В итоге в среднем только половина ВМ исполняется в одном из ЦОДов. Ведь весь смысл метрокластера в минимизации простоев, а следовательно в ваших интересах минимизировать и количество ВМ под ударом.
- Часть сервисов можно кластеризовать на уровне приложения, разнеся по разным ВМ. Соответственно эти парные ВМ по одной прибиваются гвоздями, или привязываются ленточкой к разным ЦОДам, чтобы сервис вообще не ждал перезапуска ВМ в случае аварии.
При грамотно построенной инфраструктуре с растянутыми метрокластерами бизнес пользователи работают с минимальными задержками из любой точки, даже в случае аварии на уровне ЦОД. В худшем случае задержка составит время на одну чашку кофе.
И, разумеется, метрокластеры отлично работают как на уходящих в сторону Валинора HPE 3Par, так и на новеньких Primera!
Инфраструктура удаленных рабочих мест
Терминальные серверы
Для терминальных серверов не нужно придумывать ничего нового, уже много лет HPE поставляет одни из лучших серверов в мире для них. Нестареющая классика — DL360 (1U) или DL380 (2U) или для любителей AMD — DL385. Конечно, есть и блейд серверы, как классические C7000, так и новая компонуемая платформа Synergy.
На любой вкус, на любой цвет, максимум сессий на сервер!
“Классический” VDI + HPE Simplivity
В данном случае говоря “классическим VDI” я подразумеваю концепцию 1 пользователь = 1 ВМ с клиентской Windows. И конечно же, нет ближе и роднее VDI нагрузки для гиперконвергентных систем, тем более с дедупликацией и компрессией.
Здесь HPE может предложить как собственную гиперконвергентную платформу Simplivity, так и серверы / сертифицированные узлы под решения партнеров, как например VSAN Ready Nodes для построения VDI на инфраструктуре VMware VSAN.
Давайте поговорим чуть больше о собственном решении Simplivity. Во главу угла, как нам мягко намекает название, поставлена простота (англ simple — простой). Простота развертывания, простота управления, простота масштабирования.
Гиперконвергентные системы на сегодня — одна из самых горячих тем в ИТ, а количество вендоров разного уровня составляет около 40. Согласно магическому квадрату Gartner, компания HPE находится в Тор5 глобально, и входит в квадрат лидеров — те понимает и куда развивается индустрия, и способна это понимание воплотить в железе.
Архитектурно Simplivity является классической гиперконвергентной системой с контроллерными виртуальными машинами, а значит мождет поддерживать различные гипервизоры, в отличие от интегрированных в гипервизор систем. И действительно, на апрель 2020 поддерживаются VMware vSphere и Microsoft Hyper-V, и озвучены планы по поддержке KVM. Ключевой фишкой Simplivity с момента ее появления на рынке было аппаратное ускорение компрессии и дедупликации с помощью специальной карты-акселератора.
Нужно отметить, что компрессия с дедупликацией являются глобальными и постоянно включенными, те это не опциональная фича, а архитектура решения.
HPE конечно несколько лукавит, утверждая эффективность 100:1, посчитав особым образом, но эффективность использования пространства действительно очень высока. Просто цифра 100:1 уж больно красивая. Давайте разберемся, как же реализована Simplivity технически, чтобы показать такие цифры.
Snapshot. Снэпшоты (мгновенные снимки) — 100% правильно реализованы как RoW (Redirect-on-Write), а следовательно происходят моментально и не дают штрафа к произво��ительности. Чем например отличаются от некоторых других систем. Зачем нам нужны локальные снэпшоты без штрафов? Да очень просто, для снижения RPO с 24 часов (среднее RPO для резервного копирования) до десятков или даже единиц минут.
Backup. Снэпшот от бэкапа отличается только тем, как его воспринимает система управления виртуальными машинами. Если при удалении машины удаляется и все остальное — значит это был снапшот. Если осталось — значит бэкап (резервная копия). Таким образом любой снапшот может считаться и полным бэкапом, если его пометить в системе и не удалять.
Конечно, многие возразят — какой же это бэкап, если он на той же системе хранится? А здесь есть очень простой ответ в виде встречного вопроса: скажите, а у вас есть формальная модель угроз, устанавливающая правила хранения резервной копии? Это абсолютно честный бэкап против удаления файла внутри ВМ, это бэкап против удаления самой ВМ. В случае же небоходимости хранения резервной копии исключительно на отдельно стоящей системе есть на выбор: репликация этого снэпшота на второй кластер Simplivity или на HPE StoreOnce.
И вот именно здесь оказывается, что подобная архитектура просто идеально подходит под любого вида VDI. Ведь VDI — это сотни или даже тысячи крайне похожих машин с одной и той же ОС, с одними и теми же приложениями. Глобальная дедупликация все это пережует и сожмет даже не 100:1, а куда лучше. Развернуть 1000 ВМ из одного шаблона? Вообще не проблема, эти машины будут дольше регистрироваться в vCenter, чем клонироваться.
Специально для пользователей с особыми требованиями к производительности, и для тех, кому нужно 3D ускорители, была создана линейка Simplivity G.
В этой серии не используется аппаратный ускоритель дедупликации, и поэтому снижено количество дисков на узел, чтобы контроллер справлялся программно. Благодаря этому освобождаются слоты PCIe под любые другие ускорители. Так же удвоен объем доступной памяти на узел до 3ТБ для самых требовательных нагрузок.
Simplivity идеально подходит для организации географически распределенных VDI инфраструктур с репликацией данных в центральный ЦОД.
Подобная архитектура VDI (а впрочем и не только VDI) особенно интересна в условиях российских реалий — огромные расстояния (и следовательно задержки) и далеко не идеальные каналы. Создаются региональные центры (а даже и просто 1-2 узла Simplivity в совсем удаленный офис), куда подключаются местные пользователи по быстрым каналам, сохраняется полный контроль и управление из центра, а в центр реплицируется только незначительное количество уже настоящих, ценных, а не мусорных данных.
Разумеется, Simplivity полностью подключается к OneView и InfoSight.
Тонкие и нулевые клиенты
Тонкие клиенты — специализированные решения для применения исключительно в качестве терминалов. Поскольку на клиент фактически нет нагрузки кроме поддержания канала и декодирования видео — практически всегда стоит процессор с пассивным охлаждением, небольшой загрузочный диск только для старта специальной встраиваемой ОС, да в общем-то и все. Ломаться в нем практически нечему, а красть бесполезно. Стоимость невелика и никаких данных в нем не сохраняется.
Существует особая категория тонких клиентов, так называемые нулевые клиенты. Их основное отличие от тонких — отсутствие даже встраиваемой ОС общего назначения, и работа исключительно с микрочипа с прошивкой. Зачастую в них ставят специальные аппаратные ускорители для декодирования видеопотока в терминальных протоколах, таких как PCoIP или HDX.
Несмотря на разделение большого “Хьюлетт Паккард” на отдельные HPE и HP, нельзя не упомянуть тонкие клиенты производства HP.
Выбор широк, на любой вкус и потребности — вплоть до многомониторных рабочих мест с аппаратным ускорением видеопотока.
Сервис HPE для вашей удаленной работы
И последним по списку, но не по значению, хочу упомянуть сервис HPE. Было бы слишком долго перечислять все уровни сервиса HPE и его возможности, но как минимум есть одно крайне важное предложение в условиях удаленной работы. А именно — сервисный инженер от HPE/авторизованного сервис-центра. Вы продолжаете работать удаленно, с любимой дачи, слушая шмелей, пока пчелка от HPE, приехав в датацентр, заменяет в ваших серверах диски или вышедший из строя блок питания.
HPE CallHome
В условиях сегодняшего дня, при ограничении передвижений, как никогда актуальной становится функция Call Home. Любая система HPE с данной функцией может самостоятельно сообщить об аппаратном или программном сбое в центр поддержки HPE. И вполне вероятно, деталь на замену и/или сервисный инженер к вам прибудет еще задолго до того, как вы заметите неполадки и проблемы с продуктивными сервисами.
Лично я функцию эту включать настоятельно рекомендую.

