
Тестирование производительности — это непрерывный процесс оптимизации, контроля быстродействия систем и подтверждения их отказоустойчивости как на стадии моделирования и проектирования, так и на каждой итерации внесения изменений.
Сейчас в Тинькофф мы активно занимаемся развитием тестирования производительности наших сервисов, в том числе развиваем инструменты для тестирования. В качестве основного инструмента для генерации нагрузки используем Gatling. Вот его основные преимущества:
- Плагин Gatling SBT позволяет очень просто запускать тесты из CI-систем.
- Gatling хорошо подходит для командной работы над проектами. Cкрипты представляют собой человекочитаемый код на Gatling DSL, его удобно хранить в git и версионировать.
- В дополнение к стандартному функционалу Gatling существует возможность использовать любой Scala/Java-код внутри проекта, а также подключать зависимости от любых доступных библиотек Scala/Java, что позволяет создавать тесты для специфичных протоколов и выполнять дополнительные действия по подготовке тестовых данных или расширенному анализу результатов.
В этой статье расскажу о двух проектах, которые позволяют нам переиспользовать часто применяемые типовые решения и ускорить разработку проектов Gatling.

Какие проблемы решаем
Активное развитие подразумевает рост числа проектов. Поэтому мы стараемся максимально автоматизировать наши процессы, предоставлять тестирование производительности как сервис и обеспечить стабильный и удобный запуск тестов. Всё новые и новые проекты хотят получить процесс тестирования, разработчики и специалисты по тестированию сами пишут тесты, получая новые скиллы для развития себя как технических специалистов. В зависимости от специализации команды писали тесты с различной структурой. Весь код проекта мог быть собран в одном файле, для работоспособности скриптов не требуется их структурировать и разбивать по отдельным объектам, однако это большая проблема при чтении кода таких проектов и при командной работе над скриптами. К тому же такой подход приводил к дублированию кода. Вместо описания повторяющегося запроса в одном месте, группировки запросов по модулям и только потом сборки общего сценария из модулей, код запроса копировался для каждого вызова, а таких запросов могло быть очень много. Для внесения изменений в один запрос требовалось искать все места его использования, что могло приводить к ошибкам. Такие проекты требовали отнимающего время рефакторинга. Нам нужно было решение, позволяющее всем командам разрабатывать проекты Gatling с однообразной структурой.
Запуск тестов проводился неорганизованно, применялись три различных CI-инструмента, а на некоторых проектах тесты запускались локально или вручную с генераторов нагрузки. Подключать новый проект к тестированию или контролировать тестирование на старых проектах было затруднительно: приходилось смотреть, как именно запускается тест на конкретном проекте, а иногда и получать доступ к генераторам нагрузки, чтобы вручную запускать тест и собирать результаты. Для организации и контроля запусков тестов в одном месте нам требовалось общее решение, позволяющее быстро подключать новые проекты. Мы выбрали Jenkins pipeline — гибкий и удобный инструмент, позволяющий максимально автоматизировать процесс тестирования. Для запуска тестов из CI необходимо знать, какие параметры требуется передать в него. Нужно запустить тест на 30 минут, какой параметр передать? testDuration, test-duration, а может TEST_DURATION? Или в этом проекте значение не параметризовано и нужно вносить изменения в код? Пока не посмотришь в репозиторий — не узнаешь. Это приводило к тому, что CI-пайплайны настраивались отдельно для каждого проекта. Получая большой поток разнородных по структуре проектов, мы не могли создать единый пайплайн для запуска всех тестов, требовалась шаблонизация проектов Gatling.
Для тестов производительности зачастую используются однотипные тестовые данные: ID пользователя или запроса, номер телефона, e-mail и много других. Сторонние системы обычно заменяем эмуляторами, и становится возможным применять случайные данные, сгенерированные на лету, без необходимости читать их из подготовленного файла или генерировать в базе данных. Gatling позволяет использовать для этого любой Scala/Java-код в своих проектах. Наша кодовая база генераторов росла, появлялись решения распространенных задач, которые можно было переиспользовать в других проектах. Однако мы столкнулись с проблемой обучения новых сотрудников и специалистов из других команд. Изучить Gatling достаточно просто — можно через неделю-две начать разрабатывать скрипты. Выучить Scala так же быстро не получится, поэтому, чтобы предоставить командам удобный сервис по разработке тестов и подключению наших наработок в свои проекты, нам нужно было собрать код в библиотеку для переиспользования.
Если обобщить, при сервисном подходе по подготовке тестов к запуску необходимо решить две задачи:
- Шаблонизировать проекты для возможности быстро встраивать их в CI пайплайн.
- Вынести общие наработки и интеграции в библиотеку для переиспользования.
Шаблонизация проектов
У Gatling есть некоторые рекомендации по организации структуры проекта: операции группируются по объектам в зависимости от бизнес-сценария, из этих объектов композируется сценарий в другом объекте, тест-план описывается в третьем. Такое разделение повышает скорость восприятия скриптов, а поддерживать и дорабатывать их становится значительно проще. Из набора операций можно собрать сценарий любой сложности, а при необходимости — несколько сценариев.
Однако, если нет общего шаблона, каждая команда разрабатывает проект со своей структурой, приходится долго разбираться даже в своих собственных проектах, созданных полгода назад, где что лежит, почему при запуске возникает ошибка? Много времени уходит на дебаг старого кода и поиск причин ошибок.
Первым решением был шаблон проекта в Git. Для создания нового проекта теперь требовалось переименовывать файлы, менять конфигурацию теста, удалять ненужное и, наконец, заливать изменения в отдельный репозиторий. Это работало, но требовало дополнительных действий.
Тогда мы обратились к giter8 — специальной утилите для генерации файлов и директорий по шаблону — и разработали шаблон со своей структурой проекта и конфигурациями.
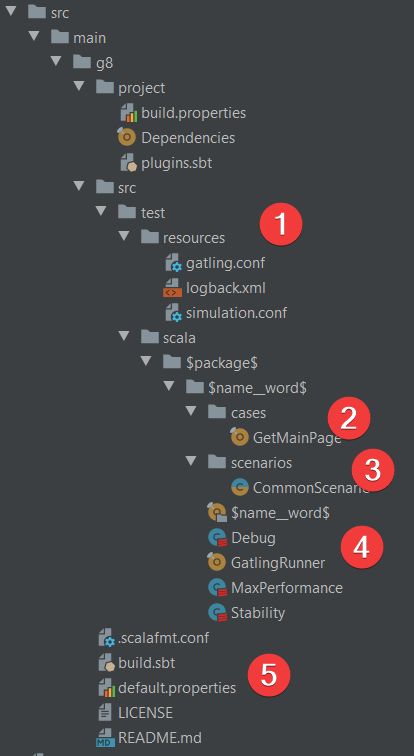
- Ресурсы проекта и конфигурация теста
- Отдельные операции
- Бизнес-сценарии
- Файлы для запуска различных видов тестов
- Зависимости от других библиотек и базовые значения параметров проекта
Как использовать:
- Установить SBT
- Выполнить в консоли
sbt new TinkoffCreditSystems/gatling-template.g8 - Ввести запрашиваемые параметры — название проекта, структура пакетов, версии зависимостей — или оставить значения по умолчанию.
- Для запуска симуляции требуется передать в ENV или JAVA_OPTS определенные параметры:
- В файле gatling.conf, по пути gatling.data.graphite, параметризованы настройки Graphite, необходимые для записи метрик Gatling в InfluxDB. При необходимости можно указать их явно или определить значение по умолчанию.
- В файле logback.xml настроена запись логов Gatling в файл, консоль и graylog. По умолчанию все три выключены, для включения необходимо передать соответствующие параметры.
$sbt new TinkoffCreditSystems/gatling-template.g8 Creates a Gatling project with sample performance test. name [myservice]: service package [ru.tinkoff.load]: org.organisation scala_version [2.12.10]: sbt_version [1.3.9]: gatling_version [3.3.1]: sbt_gatling_version [3.1.0]: gatling_picatinny_version [0.5.0]:
создает такой проект:

Теперь у нас есть удобный инструмент, позволяющий одной командой создавать новый проект, уже готовый к пушу в git и запуску из CI.
Переиспользование кода скриптов
Разработка
Основные решения, которые мы в первую очередь вынесли в отдельную библиотеку для переиспользования и унификации.
Конфигурация теста
Можно указывать параметры тестов прямо в коде, однако при любых изменениях профиля или тест-плана потребуется вносить изменения в проект, что очень долго и неудобно, нам хотелось иметь возможность передавать параметры в тест из нашего CI пайплайна.
Эта проблема решалась средствами Scala:
//получаем значение из ENV переменной baseUrl=.. val baseUrl = sys.env.getOrElse("baseUrl", "https://tinkoff.ru/") //получаем значение из JAVA_OPTS -DbaseUrl=.. val baseUrl1 = sys.props.getOrElse("baseUrl", "https://tinkoff.ru/")
Однако существовала необходимость передавать значения различных типов (Int, Double, FiniteDuration), не только строки.
//ошибка при компиляции val intensity = sys.env.getOrElse[Double]("intensity", 10.0) val rampDuration = sys.env.getOrElse[FiniteDuration]("rampDuration", 10 seconds)
env и props это Map[String, String], соответственно метод get не может получить параметр типа не являющегося String или его наследником.
Для получения параметра определенного типа мы пользовались библиотекой typesafe config, которая используется Gatling для чтения своих конфигураций:
val config = io.gatling.core.Predef.configuration.config val intensity: Double = config.getDouble("intensity") val rampDuration: FiniteDuration = config.getDuration("rampDuration", TimeUnit.SECONDS).seconds
Так мы получали сразу три преимущества:
- Можно передавать параметры любого необходимого типа.
- Можно читать переменные и из ENV, и из JAVA_OPTS.
- Можно определять значения по умолчанию в файлах конфигурации, к примеру в gatling.conf или других.
Генерация тестовых данных
В Gatling предусмотрена гибкая система фидеров, они дают нам возможность передавать параметры в тест из csv-файлов, получать параметры по JDBC из базы, читать параметры из json/xml файла конфигурации. Однако не всегда необходимо заранее генерировать пул данных, например, при необходимости передавать случайные значения. В таком случае мы пользуемся тем, что Feeder[A] alias Iterator[Map[String, A]].
Например, для создания фидера случайных строк можно воспользоваться встроенной в scala.collection.Iterator функцией continually, которая создает бесконечный итератор, где каждый элемент — это результат выполнения переданной функции:
import scala.util.Random val feeder = Iterator.continually(Map("rndStr" -> Random.alphanumeric.take(20).mkString))
Получить значение из фидера в сценарии можно с помощью Gatling expression:
val scn = scenario("Scenario") .feed(feeder) //передаем фидер в сценарий .exec(http("GET /{rndStr}") .get("/${rndStr}")) //получаем значение из фидера
Тестовые данные повторяются из проекта в проект: случайные строки, случайные даты в интервале, случайные номера телефонов и многое другое. Нам хотелось иметь набор готовых генераторов для переиспользования.
И мы начали собирать их в библиотеку gatling-picatinny.
Унифицированные системы рельсового интерфейса разработали инженеры для решения проблемы крепления к оружию дополнительных аксессуаров. Существуют различные варианты: Планка Вивера, Планка аксессуаров НАТО, Планка Пикатинни.
Наша библиотека gatling-picatinny решает подобную задачу и позволяет «крепить» к пушке Gatling дополнительный функционал.
Установка
Библиотека доступна в Maven и на GitHub.
Зависимость подключается в файле сборки вашего проекта, например в build.sbt:
libraryDependencies += "ru.tinkoff" %% "gatling-picatinny" % "0.5.0"
Если вы используете наш giter8 шаблон, то библиотека gatling-picatinny уже подключена.
Текущие возможности библиотеки
Для удобства использования мы разбили код на пакеты:
- config — позволяет удобно настраивать конфигурацию теста;
- feeders — набор генераторов тестовых данных;
- influxdb — утилиты для работы с InfluxDB;
- profile — предоставляет возможность генерировать сценарии из описания в HOCON формате;
- templates — предоставляет возможность генерации json/xml тела запроса в коде скрипта.
Давайте рассмотрим каждый.
config
Для запуска простого теста теперь можно использовать типовые параметры, которые применяются на большинстве проектов: интенсивность, время нарастания нагрузки, длительность теста, базовый URL и несколько других. Они уже определены в библиотеке.
Дополнительно добавили методы для получения значений любых определенных параметров в зависимости от их типа. Также есть возможность определить/переопределить значения по умолчанию для всех параметров в файле resources/simulation.conf.
Минимальный приоритет — у переменных, определенных в simulation.conf, затем JAVA_OPTS, максимальный приоритет у переменных в ENV.
Большая часть параметров получается из SimulationConfig:
import ru.tinkoff.gatling.config.SimulationConfig._ class SampleSimulation extends Simulation { val stageWeight = getDoubleParam("stageWeight") //получаем Double значение параметра val startIntensity = getDoubleParam("startIntensity") val warmUpDuration = getDurationParam("warmUp") //получаем FiniteDuration значение setUp( CommonScenario().inject( rampUsersPerSec(0) to startIntensity during warmUpDuration, incrementUsersPerSec(intensity * stageWeight) .times(stagesNumber) .eachLevelLasting(stageDuration) .separatedByRampsLasting(rampDuration) .startingFrom(startIntensity) ) ).protocols(httpProtocol).maxDuration(testDuration) }
Если config не найдет переменную в ENV, JAVA_OPTS или в файле simulation.conf, симуляция остановится, а в логах будет запись о необходимости указать используемый параметр.
feeders
В пакете feeders собраны часто используемые генераторы тестовых данных, примеры использования собраны в репозитории.
Дополнительно предоставляется функционал создания собственного фидера, который принимает на вход имя переменной для использования в скриптах и функцию для генерации тестовых данных.
val feeder = CustomFeeder("myParam", Random.alphanumeric.take(20).mkString)
Также добавили функционал композиции двух и более фидеров.
Например, у вас есть несколько источников данных о пользователе, запросом из БД вы получаете список логинов:
val login = jdbcFeeder(dbUrl, dbUserName, dbPassword, loginsQuery).circular
Из файла читаете список адресов:
val address = ssv("addresses.csv").circular
Генерируете ID в виде случайной строки:
val ids = RandomStringFeeder("id", 20)
И дальше можно «склеить» все три фидера в один общий с информацией о пользователе:
import ru.tinkoff.gatling.feeders._ val login = jdbcFeeder(dbUrl, dbUserName, dbPassword, loginsQuery).circular.apply() //необходимо вызвать метод apply val address = ssv("addresses.csv").circular.apply() //необходимо вызвать метод apply val ids: Feeder[String] = RandomStringFeeder("id", 20) val users = login ** address ** ids //подключаем фидер в сценарии //раньше //scenario(...).feed(login).feed(address).feed(ids) //сейчас scenario(...).feed(users)
На каждой итерации фидер будет хранить все три переменные ${login};${address};${id}
influxdb
Gatling поддерживает запись своих метрик в Graphite, мы используем это на всех проектах для онлайн-мониторинга тестов и предварительного анализа результатов. Для InfluxDB есть Graphite-плагин, который умеет обрабатывать данные по шаблону и сохранять их в InfluxDB.
С ростом числа тестов мы столкнулись с необходимостью программно определять начало/конец теста для автоматического сбора метрик и анализа. Мы подготовили механизм записи аннотаций в InfluxDB в секции before() и after(). Также это оказалось удобным при анализе большого числа тестов в grafana.
Для использования достаточно наследовать класс с настройками симуляции от trait Annotations, и аннотации автоматически запишутся в InfluxDB.
import ru.tinkoff.gatling.influxdb.Annotations class MaxPerformance extends Simulation with Annotations { ... }
SELECT "annotation_value" FROM "${Prefix}" where "annotation" = 'Start' SELECT "annotation_value" FROM "${Prefix}" where "annotation" = 'Stop'
profile
В пакете собран функционал для генерации сценариев из конфигурационного файла. Необходимость в таком функционале возникала на проектах с сервисами, не сохраняющими своего состояния. Для таких проектов достаточно hit-based-подхода подачи нагрузки: профиль представляет собой набор отдельных запросов с различными вероятностями вызова.
Наш пример использования:
- Получаем лог приложения.
- Обрабатываем лог скриптом и получаем интенсивность по операциям.
- Генерируем файл .conf с описанием операций и указанием вероятности вызова каждой операции в сценарии.
- Подключаем volume с этим файлом в готовый docker image с проектом Gatling, который умеет генерировать сценарии из файла.
Таким образом без нашего участия автоматически собирается профиль и запускаются тесты, остается только поддержка функционала.
templates
Предоставляет расширенный DSL для работы с телами запросов формата json/xml.
- Позволяет генерировать json/xml-тело запроса в коде скрипта, полезно при составлении сложного тела запроса или при генерации частей по отдельности.
import ru.tinkoff.gatling.templates.HttpBodyExt._ import ru.tinkoff.gatling.templates.Syntax._ val project: Field = "project" - ( "projectId" ~ "projectId", "name" - "Super Project", "sub" > (1, 2, 3, 4, 5, 6) ) val req = http("PostData") .post("/") .jsonBody( "id" - 42, "name", project )
В результате будет сформировано такое тело запроса:
{ "id": 42, "name": ${name}, "project": { "projectId": ${projectId}, "name": "Super Project", "sub" : [1,2,3,4,5,6] } }
${name}, ${projectId} — значения будут подставлены из сессии Gatling.
- Позволяет отправить по указанному адресу тела запросов из директории resources/templates.
Вместо
class MaxPerformance extends Simulation { val firstRequest: HttpRequestBuilder = http("firstRequest") .post("https://tinkoff.ru/") .body(ElFileBody("templates/firstRequest.json")) val secondRequest: HttpRequestBuilder = http("secondRequest") .post("https://tinkoff.ru/") .body(ElFileBody("templates/secondRequest.json")) }
Можно писать
class MaxPerformance extends Simulation with Templates { val firstRequest: HttpRequestBuilder = postTemplate("firstRequest", "https://tinkoff.ru/") val secondRequest: HttpRequestBuilder = postTemplate("secondRequest", "https://tinkoff.ru/") }
Что значительно сокращает объем кода на некоторых проектах.
Планы по развитию
Ближайшие планы по развитию связаны с доработкой существующих возможностей.
feeders
Планируем добавлять новые генераторы данных по необходимости или по запросу, в ближайших планах сделать генератор JWT-токенов с возможностью параметризовать отдельные поля значениями из других фидеров.
influxdb
Добавить функционал записи дополнительной информации в аннотации, сделать возможным запись аннотаций в определенных местах симуляции.
profile
Добавим опциональные параметры, например заголовки и тела запросов. Также есть необходимость описания вложенных сценариев.
Заключение
Подход по разработке и переиспользованию универсальных решений хорошо зарекомендовал себя в нашей команде. В частности, с gatling-picatinny и шаблоном giter8 это привело к снижению трудозатрат на подготовку скриптов для тестирования производительности, позволило нам унифицировать проекты, использовать протестированные и проверенные на реальных тестах части скриптов, а также снизить порог входа в разработку скриптов для специалистов по тестированию без опыта разработки.
Шаблон проекта giter8 уже включает в себя все необходимые зависимости и параметры для тестов, а вместе с шаблоном CI-пайплайна, в котором определены основные параметры тест-плана, параметры логирования, параметры InfluxDB для записи метрик Gatling, это позволяет нам предоставлять продуктовым командам удобный и быстрый сервис по написанию и запуску тестов производительности.
Интеграция этих двух проектов — решение часто встречающихся при работе с Gatling проблем и один из шагов к автоматизации процесса тестирования производительности.
Если вы тоже заинтересованы в развитии и автоматизации процесса тестирования и у вас есть идеи по доработкам — заводите issues и кидайте PR. Если у вас есть общие вопросы по тестированию производительности — приходите в чат.
Ссылки
https://github.com/TinkoffCreditSystems/gatling-template.g8
