Привет, читатель! Меня зовут Артём Сайгин, я веду телеграм канал «Growth Lab», в котором делюсь опытом роста IT-продуктов.
Наблюдая за работой множества маркетинговых команд, заметил, что многие допускают одни и те же ошибки в процессе поиска, приоритизации и тестирование гипотез.
В этой статье я расскажу о Growth-процессе, постараюсь дать сложный материал максимально просто.
1. Идея ≠ гипотеза.
2. Формируем бэклог гипотез.
3. Приоритизация гипотез и скоринг по ICEs и PXL-фреймворку.
4. Дизайн эксперимента.
5. Подготовка к тестированию.
6. Проведение эксперимента.
7. Анализ и статистическая значимость.
8. Внедрение.
Приступим.

Дисклеймер: в материале основные мысли и схема работы, но без углубления в тонкости, полагая, что читатель поймет куда копать, так как основной фреймворк уже будет дан.
При написании я ориентировался на маркетинговые и Growth-команды, учтите, что для других команд процесс может не подойти.
Перед тем как приступить к основному процессу, нужно внедрить в команду мышление, основанное на гипотезах. Важно понимать, что идея, в первоначальном своем виде, еще не является гипотезой.
Основной плюс гипотез в том, что они измеримы. Вы точно понимаете, какие метрики вы улучшите, если начнете тестировать гипотезу.
«Действие [X] позволит увеличить метрику [Y] на величину [Z], потому что [N]».
Давайте на примере разберем отличия.
Идея:
«Нужно сократить форму онлайн-заявки с 5 до 4 шагов, я думаю, что мы увеличим конверсию в регистрацию».
Гипотеза:
«Если мы сократим форму онлайн-заявки с 5 до 4 пунктов, то увеличим конверсию в регистрацию на 1 процентный пункт с 2% до 3%, потому что в системе аналитики мы видим, что часть пользователей уходит на шаге 4, так и не завершив регистрацию».
Если идею не получается привести в вид гипотезы, то от неё стоит отказаться. Правильно составленная гипотеза убивает бессмысленные действия, которые никак не влияют на метрики.
Идём дальше.

Мы определились, что такое гипотеза, и чем она отличается от идеи.
Теперь пришло время наполнять бэклог гипотезами.
Бэклог гипотез — единая база, где находятся наши гипотезы в упорядоченном виде.
Помните, что тест гипотез стоит денег (время разработчика, аналитика, маркетолога, дизайнера и т.д.), и если вы понимаете, что гипотеза никак не влияет на метрики, не добавляйте её.
Все гипотезы, если мы говорим про IT-продукты, можно вписать в воронку AAARRR (на иллюстрации выше я её схематически изобразил).
Анализируя каждый шаг воронки, мы сможем найти большее количество точек роста по каждому из шагов.
К примеру, берем шаг acqusition и анализируем все каналы привлечения в разрезе по каналам/кампаниям/группам/креативам и т.д., в ходе анализа записываем гипотезы, которые значимо могут улучшить привлечение новых пользователей.
Какие еще инструменты нам помогут в поиске точек роста:
Подробнее про каждый из способов расписывать не буду, так как темы очень обширны и стоят отдельных статей.
Рекомендация по формированию бэклога:
Мы наполнили бэклог и распределили гипотезы по шагам воронки AAARRR, теперь важно понять, какие гипотезы мы тестируем в первую очередь.
Итак, мы плавно приходим к приоритизации и скорингу.
Представьте, что гипотезы в бэклог добавляют все сотрудники отдела и каждый хочет, чтобы его гипотеза была первой в очереди на тестирование. Чтобы избежать недопонимания и конфликтов, процесс приоритизации и скоринга гипотез должен быть максимально прозрачным. В этом поможет фрейморк ICE Score.
ICE Score — это:
Impact (Влияние) — демонстрирует, насколько идея положительно повлияет на ключевой показатель, который вы пытаетесь улучшить.
Confidence (Уверенность) — демонстрирует, насколько вы уверены в оценках влияния и легкости реализации.
Ease (Легкость реализации) — это оценка того, сколько усилий и ресурсов требуется для реализации этой идеи.
Формула ICEs:
ICE Score = Impact х Confidence х Ease
Как это работает.
Команда собирается вместе, и каждый её участник оценивает Impact, Confidence и Ease по шкале от 1 до 10. Далее оценки каждого сотрудника умножаются между собой и складываются со значениями других сотрудников, так мы получаем ICE Score по каждой гипотезе.
Ниже приведена таблица для примера.

Подробнее разберем, как распределяются оценки по шкале от 1 до 10.
Impact:
Тут все просто, чем больше влияние на ключевые метрики — тем выше оценка в таблице.
Confidence:
Есть только один способ рассчитать confidence — это поиск подтверждающих доказательств. Для этого вы можете создать собственную карту по распределению оценок по шкале от 1 до 10, это поможет команде выставлять оценки более прозрачно и исключить разброс оценок, когда один сотрудник ставит 1, а другой сотрудник — 10.
В карте перечислены общие типы тестов и доказательств, которые могут быть у вас, и уровень уверенности, который они предоставляют: результаты тестов, дата лонча, собственная уверенность, данные рынка, мнение других людей и др.
Карта ниже сделана на Product Idea Confidence Calculator

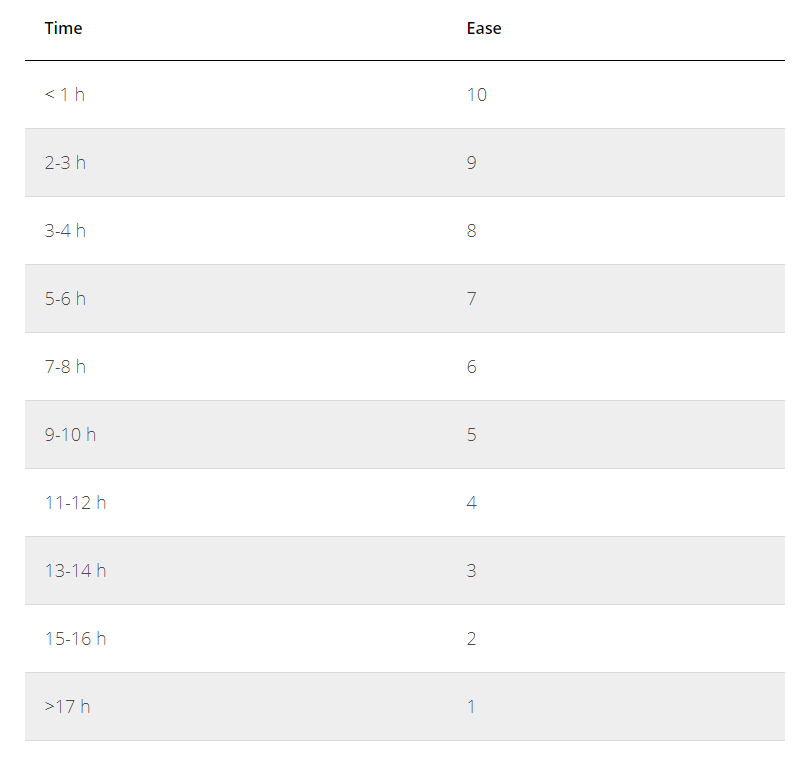
Ease:
Легкость реализации вы оцениваете в соответствии со скоростью работы вашей команды.
Учтите, что время и оценки для каждой команды указываются индивидуально, если у вас реализация гипотезы рассчитывается в днях, а не в часах — указывайте дни.
Пример расчета Ease:
Как опробуете ICEs и захотите сделать скоринг более точным, то можете перейти к PXL-фреймворку. Подробнее про PXL-фреймворк можете почитать по ссылке.
Видов скоринга и приоритизаций много, вы можете подстроить уже имеющийся или сделать свой фреймворк, который подойдет именно вашей команде. Главное тут, чтобы скоринг помог вам в работе, использовать фреймворк ради самого фреймворка не нужно.
Мы приоритизировали гипотезы, и теперь нужно составить дизайн эксперимента.
Дизайн эксперимента — подробное техническое задание по тестированию нашей гипотезы, и нужен он для того, чтобы понимать, что мы тестируем, на какой выборке и какие метрики считаем.
Дизайн эксперимента строится по такому шаблону:
Разберём подробнее на примере:
Гипотеза:
Берем гипотезу из бэклога.
В нашем случае она выглядит так:
Если мы сократим форму онлайн-заявки с 5 до 4 пунктов, то увеличим конверсию в регистрацию на 1 процентный пункт с 2% до 3%, потому что в системе аналитики мы видим, что часть пользователей уходит на шаге 4, так и не завершив регистрацию.
Что делаем:
Контрольная версия: оставляем все, как есть.
Тестовая версия: сокращаем форму онлайн-заявки с 5 до 4 пунктов.
На каких пользователях тестируем:
Только на новых пользователях.
Метрики:
Конверсия в регистрацию.
План действий:
Если наш эксперимент будет положительным, и мы увидим улучшение в метриках (CR в регистрацию будет > 3%) — масштабируем на всех пользователей.
Если метрики падают, то откатываем.
Если метрики не меняются, то оставляем, как есть.
Перед запуском эксперимента обязательно обговорите и согласуйте план дальнейших действий, что собираетесь предпринять по факту получения результатов. Так вы избавитесь от ситуаций, когда тест прошел, а Product Owner в итоге не собирается внедрять эксперимент.
Прежде чем запустить эксперимент, нужно сделать несколько подготовительных шагов.
Давайте разберем все шаги по порядку.
Выберите, какой вариант тестирования подойдет вам.
Вот несколько возможных вариантов:
В нашем примере мы рассмотрим самый часто используемый из вариантов — A/B-тестирование.
Перед запуском определите, сколько пользователей нужно привлечь на каждый из вариантов А/B-теста, чтобы данные в итоге получились статистически значимыми.
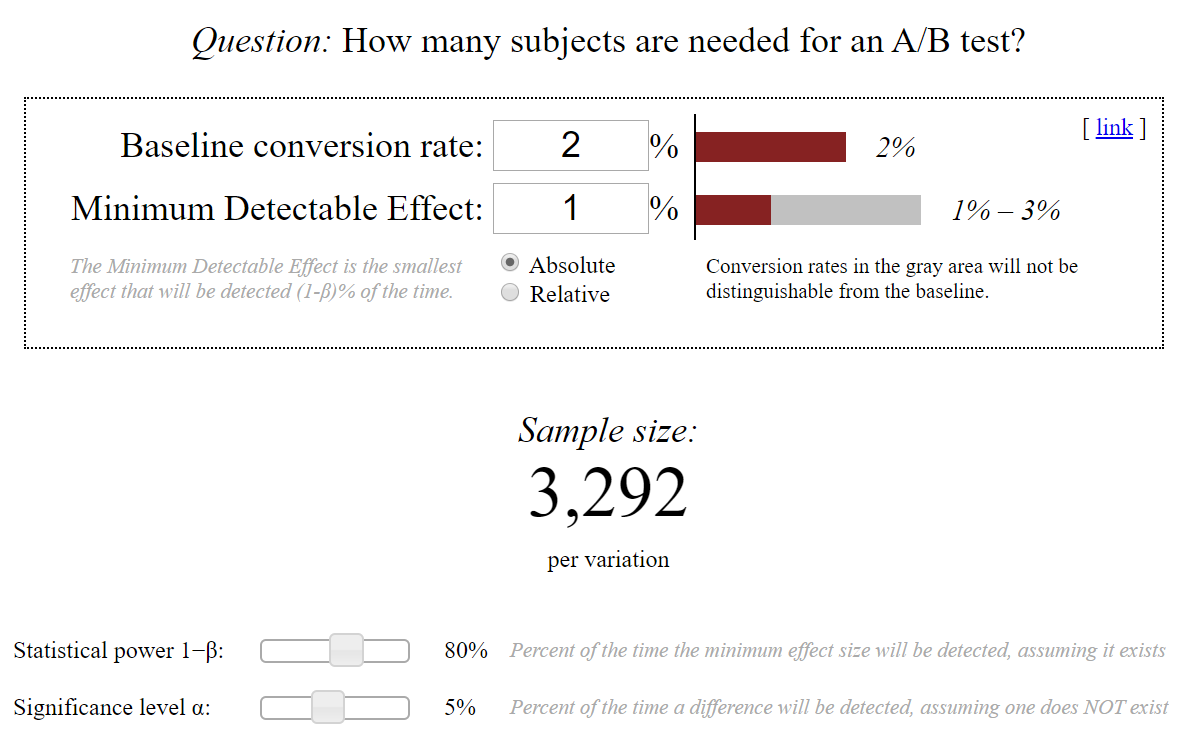
Воспользуемся калькулятором Эвана Миллера для расчёта выборки (смотрите скриншот ниже).
В «Baseline conversion rate» указываем конверсию контрольной версии, в нашем случае 2%.
В «Minimum Detectable Effect» указываем на сколько процентов увеличится конверсия контрольной версии, в нашем случае на +1%.
Significance level α (уровень доверия) — это уровень риска, который вы принимаете при ошибках первого рода (отклонение контрольной версии теста, если она верна), обычно α = 0.05.
Это означает, что в 5% случаев вы будете обнаруживать разницу между A и B, которая на самом деле обусловлена случайностью.
Чем ниже выбранный вами уровень значимости, тем ниже риск того, что вы обнаружите разницу, вызванную случайностью.
Statistical power 1−β (статистическая мощность) — это ошибки второго рода, вероятность того, что мы на выборке примем тестовую версию, если на самом деле она верна (шанс обнаружить эффект, если он на самом деле есть). При планировании эксперимента нужно помнить, что мощность должна быть разумно высокой, чтобы обнаружить отклонения от контрольной версии. Если вы не знаете, какой процент показателя стоит указать, оставьте значения по умолчанию (80%).
В итоге мы понимаем, что для корректного теста нам нужно по 3 292 пользователей на каждый из вариантов А/B-теста.
Далее можем рассчитать, сколько конверсий мы должны получить, и какая разница между ними должна быть, для получения статистически значимого результата.
Воспользуемся калькулятором Sequential Sampling

Для корректного анализа мы должны получить 170 конверсий, и разница между версиями A/B-теста должна быть более 26 конверсий.
Возьмите размер выборки, полученный при расчете для тестирования каждой версии, и разделите его на ваш ежедневный трафик, так вы получите количество дней, необходимое для проведения теста.
Тест проводите как минимум одну полную неделю, т.к. данные в выходные могут отличаться от будней.
Мы рассчитали, сколько нужно трафика и конверсий для статистически значимого эксперимента, теперь нужно выбрать сам инструментарий для тестирования.
Инструментарий состоит из двух основных блоков:
1. Источник трафика.
Подготовьте источник трафика, настройте рекламные кампании.
2. Системы распределения трафика между версиями A и B.
Тут можно пойти двумя путями: сделать собственный инструмент по распределению трафика между версиями, прибегнув к помощи разработчиков, или воспользоваться сторонними сервисами, такими как:

Перед запуском теста убедитесь, что между двумя тестовыми версиями нет разницы.
Не должно быть технических различий в версиях или в трафике, так как любые различия влияют на чистоту эксперимента.
Для максимальной чистоты перед стартом проводят A/A-тестирование. В отличии от A/B-тестирования, в A/A мы тестируем две одинаковые страницы (элементы). Цель эксперимента — не увидеть различий в их показателях.
Перепроверьте системы аналитики, убедитесь, что все нужные для эксперимента метрики работают корректно.
Частая ошибка — запуск теста без проверки систем аналитик и метрик, в итоге тратится время специалистов, бюджеты, и всё проводится зря.
Возвращаясь к дизайну эксперимента вспомним, на каких пользователях проводим эксперимент.
У нас было указано: «Только на новых пользователях».
В системе распределения трафика или рекламной системы мы должны отминусовать повторно вернувшихся пользователей.
И сделать абсолютно идентичные рекламные кампании (если вы проводите тест не на органике).
Перед стартом проверьте, действительно ли всё корректно работает. Перепроверьте всё еще раз и запускайте эксперимент.
По ходу эксперимента отслеживайте проблемы с трафиком и с системами тестирования, устраняйте их по мере появления.
Рекомендации по проведению эксперимента.
Доводите эксперимент до конца, даже если вы в первый день видите статистически значимое улучшение в тестовой версии.
Проблема принятия преждевременных решений называется «Peeking problem» или «Проблема подглядывания».
Чем чаще вы смотрите на промежуточные результаты A/B-теста с готовностью принять на их основе решение, тем выше становится вероятность, что критерий покажет значимую разницу, когда ее нет.
Посмотрите картинку ниже, она отлично иллюстрирует всю суть «Peeking problem».

Если бы мы не знали о проблеме подглядывания, то завершили эксперимент на четвертый день, решив, что тестовая версия значительно лучше, и проводить эксперимент дальше нет смысла.
Но доведя эксперимент до конца мы поймем, что устойчивой измеримой разницы между группами нет.
Нужно понимать, что разница конверсий может периодически выходить за границы зоны неразличимости по мере накопления наблюдений, даже если мы тестируем идентичные версии.
Это совершенно нормально, так как границы сформированы таким образом, чтобы при тестировании одинаковых версий лишь в 95% случаев разница оказывалась в их пределах.
Для того чтобы не попасться на крючок «Peeking problem», перед стартом мы рассчитываем размер выборки и длительность проведения эксперимента. Следуйте намеченному плану.
Если проводите тестирование на самописном сервисе, то желательно иметь систему экстренного отключения тестирования и анализа аномалий, так как эксперимент может сломать продукт.
Мы провели эксперимент и получили данные.
Теперь нам нужно понять, изменение, которое мы получили в метриках между версиями А и B, связано с нашей гипотезой или со случайностью.
Другими словами, является ли изменение статистически значимым или нет.
В нашем примере мы получили такие данные:
Выборка A: 3 292 сеансов, 67 конверсий.
Выборка B: 3 200 сеансов, 99 конверсий.
Воспользуемся калькулятором для расчёта статистической значимости.

P-value = 0.000691, то есть вероятность увидеть наблюдаемое различие при идентичных тестовых группах очень мала. Значит, можно с высокой степенью уверенности связать рост метрики с нашими изменениями.
A/B-тест подтвердил нашу гипотезу, тестовая версия статистически значимо лучше контрольной.
Получив статистически значимый результат, не спешите масштабировать его на всех пользователей. Не рискуйте и проверьте еще раз полученные данные.
Убедитесь, что не было пересечения выборок и аномалий.
Не должно быть такого, что один и тот же пользователь попал в две выборки, иначе вы рискуете достоверностью полученных данных.
Но что, если между версиями нет разницы, или тестовая версия значимо хуже?
Готовьтесь к тому, что наша версия эксперимента может проиграть, что вполне нормально при частом тестировании.
По окончании эксперимента проведите ретроспективу, проанализируйте, почему ваша гипотеза проиграла.
Углубитесь в данные, проведите исследование пользователей, постарайтесь понять, почему тестовая версия не работает так, как ожидалось. Ведите общую с командой базу знаний (Confluence), место, в котором вы расписываете изначальные ожидания от эксперимента и последующий результат. Все эти данные, в свою очередь, помогут вам в следующих экспериментах.
Все мы ошибаемся, и это нормально.
Людям вообще свойственно переоценивать свою способность к рациональным и правильным решениям.
Есть отличный афоризм по этому поводу: «Ошибки — налог на развитие.»
После положительного эксперимента должно идти его внедрение (замена контрольной версии на тестовую).
Проведение эксперимента без последующих действий бессмысленно.
Часто бывает такое, что получив статистически значимый результат (наша гипотеза подтвердилась), мы не можем её внедрить, т.к. изначально не прошли все стадии согласования. Заранее обдумайте все возможные проблемы при внедрении.
Независимо от того, был ли ваш тест успешным или нет, относитесь к каждому эксперименту, как к возможности для обучения.
Используйте то, чему вы научились, в работе со следующими гипотезами.
Удачи вам в дальнейших экспериментах!
Наблюдая за работой множества маркетинговых команд, заметил, что многие допускают одни и те же ошибки в процессе поиска, приоритизации и тестирование гипотез.
В этой статье я расскажу о Growth-процессе, постараюсь дать сложный материал максимально просто.
О чем поговорим в статье
1. Идея ≠ гипотеза.
2. Формируем бэклог гипотез.
3. Приоритизация гипотез и скоринг по ICEs и PXL-фреймворку.
4. Дизайн эксперимента.
5. Подготовка к тестированию.
6. Проведение эксперимента.
7. Анализ и статистическая значимость.
8. Внедрение.
Приступим.
Дисклеймер: в материале основные мысли и схема работы, но без углубления в тонкости, полагая, что читатель поймет куда копать, так как основной фреймворк уже будет дан.
При написании я ориентировался на маркетинговые и Growth-команды, учтите, что для других команд процесс может не подойти.
Идея ≠ гипотеза
Перед тем как приступить к основному процессу, нужно внедрить в команду мышление, основанное на гипотезах. Важно понимать, что идея, в первоначальном своем виде, еще не является гипотезой.
Основной плюс гипотез в том, что они измеримы. Вы точно понимаете, какие метрики вы улучшите, если начнете тестировать гипотезу.
Формула гипотезы
«Действие [X] позволит увеличить метрику [Y] на величину [Z], потому что [N]».
Давайте на примере разберем отличия.
Идея:
«Нужно сократить форму онлайн-заявки с 5 до 4 шагов, я думаю, что мы увеличим конверсию в регистрацию».
Гипотеза:
«Если мы сократим форму онлайн-заявки с 5 до 4 пунктов, то увеличим конверсию в регистрацию на 1 процентный пункт с 2% до 3%, потому что в системе аналитики мы видим, что часть пользователей уходит на шаге 4, так и не завершив регистрацию».
Если идею не получается привести в вид гипотезы, то от неё стоит отказаться. Правильно составленная гипотеза убивает бессмысленные действия, которые никак не влияют на метрики.
Идём дальше.
Формируем бэклог гипотез
Мы определились, что такое гипотеза, и чем она отличается от идеи.
Теперь пришло время наполнять бэклог гипотезами.
Бэклог гипотез — единая база, где находятся наши гипотезы в упорядоченном виде.
Помните, что тест гипотез стоит денег (время разработчика, аналитика, маркетолога, дизайнера и т.д.), и если вы понимаете, что гипотеза никак не влияет на метрики, не добавляйте её.
Все гипотезы, если мы говорим про IT-продукты, можно вписать в воронку AAARRR (на иллюстрации выше я её схематически изобразил).
Анализируя каждый шаг воронки, мы сможем найти большее количество точек роста по каждому из шагов.
К примеру, берем шаг acqusition и анализируем все каналы привлечения в разрезе по каналам/кампаниям/группам/креативам и т.д., в ходе анализа записываем гипотезы, которые значимо могут улучшить привлечение новых пользователей.
Какие еще инструменты нам помогут в поиске точек роста:
- CJM (путь клиента в вашем продукте).
- JTBD.
- Количественная аналитика из продукта.
- UX-анализы и CustDev.
Подробнее про каждый из способов расписывать не буду, так как темы очень обширны и стоят отдельных статей.
Рекомендация по формированию бэклога:
- У команды должен быть единый бэклог гипотез для прозрачной работы и избежание дублей.
- Указывайте к какой части воронки AAARRR относится гипотеза.
- Так, вы с первого взгляда будете понимать, на какой из уровней воронки она влияет.
Приоритизация гипотез и скоринг по ICEs и PXL
Мы наполнили бэклог и распределили гипотезы по шагам воронки AAARRR, теперь важно понять, какие гипотезы мы тестируем в первую очередь.
Итак, мы плавно приходим к приоритизации и скорингу.
Представьте, что гипотезы в бэклог добавляют все сотрудники отдела и каждый хочет, чтобы его гипотеза была первой в очереди на тестирование. Чтобы избежать недопонимания и конфликтов, процесс приоритизации и скоринга гипотез должен быть максимально прозрачным. В этом поможет фрейморк ICE Score.
ICE Score — это:
Impact (Влияние) — демонстрирует, насколько идея положительно повлияет на ключевой показатель, который вы пытаетесь улучшить.
Confidence (Уверенность) — демонстрирует, насколько вы уверены в оценках влияния и легкости реализации.
Ease (Легкость реализации) — это оценка того, сколько усилий и ресурсов требуется для реализации этой идеи.
Формула ICEs:
ICE Score = Impact х Confidence х Ease
Как это работает.
Команда собирается вместе, и каждый её участник оценивает Impact, Confidence и Ease по шкале от 1 до 10. Далее оценки каждого сотрудника умножаются между собой и складываются со значениями других сотрудников, так мы получаем ICE Score по каждой гипотезе.
Ниже приведена таблица для примера.
Подробнее разберем, как распределяются оценки по шкале от 1 до 10.
Impact:
Тут все просто, чем больше влияние на ключевые метрики — тем выше оценка в таблице.
Confidence:
Есть только один способ рассчитать confidence — это поиск подтверждающих доказательств. Для этого вы можете создать собственную карту по распределению оценок по шкале от 1 до 10, это поможет команде выставлять оценки более прозрачно и исключить разброс оценок, когда один сотрудник ставит 1, а другой сотрудник — 10.
В карте перечислены общие типы тестов и доказательств, которые могут быть у вас, и уровень уверенности, который они предоставляют: результаты тестов, дата лонча, собственная уверенность, данные рынка, мнение других людей и др.
Карта ниже сделана на Product Idea Confidence Calculator
Ease:
Легкость реализации вы оцениваете в соответствии со скоростью работы вашей команды.
Учтите, что время и оценки для каждой команды указываются индивидуально, если у вас реализация гипотезы рассчитывается в днях, а не в часах — указывайте дни.
Пример расчета Ease:
Как опробуете ICEs и захотите сделать скоринг более точным, то можете перейти к PXL-фреймворку. Подробнее про PXL-фреймворк можете почитать по ссылке.
Видов скоринга и приоритизаций много, вы можете подстроить уже имеющийся или сделать свой фреймворк, который подойдет именно вашей команде. Главное тут, чтобы скоринг помог вам в работе, использовать фреймворк ради самого фреймворка не нужно.
Дизайн эксперимента
Мы приоритизировали гипотезы, и теперь нужно составить дизайн эксперимента.
Дизайн эксперимента — подробное техническое задание по тестированию нашей гипотезы, и нужен он для того, чтобы понимать, что мы тестируем, на какой выборке и какие метрики считаем.
Дизайн эксперимента строится по такому шаблону:
- Гипотеза.
- Что делаем.
- На каких пользователях тестируем.
- Ключевые метрики для оценки эксперимента.
- Ожидаемый эффект.
- План действий в зависимости от результатов эксперимента.
Разберём подробнее на примере:
Гипотеза:
Берем гипотезу из бэклога.
В нашем случае она выглядит так:
Если мы сократим форму онлайн-заявки с 5 до 4 пунктов, то увеличим конверсию в регистрацию на 1 процентный пункт с 2% до 3%, потому что в системе аналитики мы видим, что часть пользователей уходит на шаге 4, так и не завершив регистрацию.
Что делаем:
Контрольная версия: оставляем все, как есть.
Тестовая версия: сокращаем форму онлайн-заявки с 5 до 4 пунктов.
На каких пользователях тестируем:
Только на новых пользователях.
Метрики:
Конверсия в регистрацию.
План действий:
Если наш эксперимент будет положительным, и мы увидим улучшение в метриках (CR в регистрацию будет > 3%) — масштабируем на всех пользователей.
Если метрики падают, то откатываем.
Если метрики не меняются, то оставляем, как есть.
Перед запуском эксперимента обязательно обговорите и согласуйте план дальнейших действий, что собираетесь предпринять по факту получения результатов. Так вы избавитесь от ситуаций, когда тест прошел, а Product Owner в итоге не собирается внедрять эксперимент.
Подготовка к тестированию
Прежде чем запустить эксперимент, нужно сделать несколько подготовительных шагов.
- Определитесь с видом тестирования.
- Рассчитайте размер выборки, доверительный интервал и мощность.
- Рассчитайте длительность эксперимента.
- Подготовьте инструментарий для тестирования.
- Убедитесь в чистоте эксперимента.
- Настройте системы аналитики.
- Настройте сегменты для тестирования.
Давайте разберем все шаги по порядку.
1. Определитесь с видом тестирования
Выберите, какой вариант тестирования подойдет вам.
Вот несколько возможных вариантов:
- A/B-тестирование.
- MVT (мультивариативное тестирование).
- Ухудшающее A/B-тестирование.
- A/A/B-тестирование.
В нашем примере мы рассмотрим самый часто используемый из вариантов — A/B-тестирование.
2. Рассчитайте размер выборки, доверительный интервал и мощность
Перед запуском определите, сколько пользователей нужно привлечь на каждый из вариантов А/B-теста, чтобы данные в итоге получились статистически значимыми.
Воспользуемся калькулятором Эвана Миллера для расчёта выборки (смотрите скриншот ниже).
В «Baseline conversion rate» указываем конверсию контрольной версии, в нашем случае 2%.
В «Minimum Detectable Effect» указываем на сколько процентов увеличится конверсия контрольной версии, в нашем случае на +1%.
Significance level α (уровень доверия) — это уровень риска, который вы принимаете при ошибках первого рода (отклонение контрольной версии теста, если она верна), обычно α = 0.05.
Это означает, что в 5% случаев вы будете обнаруживать разницу между A и B, которая на самом деле обусловлена случайностью.
Чем ниже выбранный вами уровень значимости, тем ниже риск того, что вы обнаружите разницу, вызванную случайностью.
Statistical power 1−β (статистическая мощность) — это ошибки второго рода, вероятность того, что мы на выборке примем тестовую версию, если на самом деле она верна (шанс обнаружить эффект, если он на самом деле есть). При планировании эксперимента нужно помнить, что мощность должна быть разумно высокой, чтобы обнаружить отклонения от контрольной версии. Если вы не знаете, какой процент показателя стоит указать, оставьте значения по умолчанию (80%).
В итоге мы понимаем, что для корректного теста нам нужно по 3 292 пользователей на каждый из вариантов А/B-теста.
Далее можем рассчитать, сколько конверсий мы должны получить, и какая разница между ними должна быть, для получения статистически значимого результата.
Воспользуемся калькулятором Sequential Sampling
Для корректного анализа мы должны получить 170 конверсий, и разница между версиями A/B-теста должна быть более 26 конверсий.
4. Рассчитайте длительность эксперимента
Возьмите размер выборки, полученный при расчете для тестирования каждой версии, и разделите его на ваш ежедневный трафик, так вы получите количество дней, необходимое для проведения теста.
Тест проводите как минимум одну полную неделю, т.к. данные в выходные могут отличаться от будней.
5. Подготовьте инструментарий для тестирования
Мы рассчитали, сколько нужно трафика и конверсий для статистически значимого эксперимента, теперь нужно выбрать сам инструментарий для тестирования.
Инструментарий состоит из двух основных блоков:
1. Источник трафика.
Подготовьте источник трафика, настройте рекламные кампании.
2. Системы распределения трафика между версиями A и B.
Тут можно пойти двумя путями: сделать собственный инструмент по распределению трафика между версиями, прибегнув к помощи разработчиков, или воспользоваться сторонними сервисами, такими как:
- Google Optimize (бесплатный сервис, находится в GA)
- Kameleoon.
- Optimizely.
6. Убедитесь в чистоте эксперимента
Перед запуском теста убедитесь, что между двумя тестовыми версиями нет разницы.
Не должно быть технических различий в версиях или в трафике, так как любые различия влияют на чистоту эксперимента.
Для максимальной чистоты перед стартом проводят A/A-тестирование. В отличии от A/B-тестирования, в A/A мы тестируем две одинаковые страницы (элементы). Цель эксперимента — не увидеть различий в их показателях.
7. Настройте системы аналитики
Перепроверьте системы аналитики, убедитесь, что все нужные для эксперимента метрики работают корректно.
Частая ошибка — запуск теста без проверки систем аналитик и метрик, в итоге тратится время специалистов, бюджеты, и всё проводится зря.
8. Настройте сегменты для тестирования
Возвращаясь к дизайну эксперимента вспомним, на каких пользователях проводим эксперимент.
У нас было указано: «Только на новых пользователях».
В системе распределения трафика или рекламной системы мы должны отминусовать повторно вернувшихся пользователей.
И сделать абсолютно идентичные рекламные кампании (если вы проводите тест не на органике).
Проведение эксперимента
Перед стартом проверьте, действительно ли всё корректно работает. Перепроверьте всё еще раз и запускайте эксперимент.
По ходу эксперимента отслеживайте проблемы с трафиком и с системами тестирования, устраняйте их по мере появления.
Рекомендации по проведению эксперимента.
1. Не делайте преждевременных выводов.
Доводите эксперимент до конца, даже если вы в первый день видите статистически значимое улучшение в тестовой версии.
Проблема принятия преждевременных решений называется «Peeking problem» или «Проблема подглядывания».
Чем чаще вы смотрите на промежуточные результаты A/B-теста с готовностью принять на их основе решение, тем выше становится вероятность, что критерий покажет значимую разницу, когда ее нет.
Посмотрите картинку ниже, она отлично иллюстрирует всю суть «Peeking problem».
Если бы мы не знали о проблеме подглядывания, то завершили эксперимент на четвертый день, решив, что тестовая версия значительно лучше, и проводить эксперимент дальше нет смысла.
Но доведя эксперимент до конца мы поймем, что устойчивой измеримой разницы между группами нет.
Нужно понимать, что разница конверсий может периодически выходить за границы зоны неразличимости по мере накопления наблюдений, даже если мы тестируем идентичные версии.
Это совершенно нормально, так как границы сформированы таким образом, чтобы при тестировании одинаковых версий лишь в 95% случаев разница оказывалась в их пределах.
Для того чтобы не попасться на крючок «Peeking problem», перед стартом мы рассчитываем размер выборки и длительность проведения эксперимента. Следуйте намеченному плану.
2. Имейте систему экстренного отключения тестирования
Если проводите тестирование на самописном сервисе, то желательно иметь систему экстренного отключения тестирования и анализа аномалий, так как эксперимент может сломать продукт.
Анализ и статистическая значимость
Мы провели эксперимент и получили данные.
Теперь нам нужно понять, изменение, которое мы получили в метриках между версиями А и B, связано с нашей гипотезой или со случайностью.
Другими словами, является ли изменение статистически значимым или нет.
В нашем примере мы получили такие данные:
Выборка A: 3 292 сеансов, 67 конверсий.
Выборка B: 3 200 сеансов, 99 конверсий.
Воспользуемся калькулятором для расчёта статистической значимости.
P-value = 0.000691, то есть вероятность увидеть наблюдаемое различие при идентичных тестовых группах очень мала. Значит, можно с высокой степенью уверенности связать рост метрики с нашими изменениями.
A/B-тест подтвердил нашу гипотезу, тестовая версия статистически значимо лучше контрольной.
Получив статистически значимый результат, не спешите масштабировать его на всех пользователей. Не рискуйте и проверьте еще раз полученные данные.
Убедитесь, что не было пересечения выборок и аномалий.
Не должно быть такого, что один и тот же пользователь попал в две выборки, иначе вы рискуете достоверностью полученных данных.
Но что, если между версиями нет разницы, или тестовая версия значимо хуже?
Готовьтесь к тому, что наша версия эксперимента может проиграть, что вполне нормально при частом тестировании.
По окончании эксперимента проведите ретроспективу, проанализируйте, почему ваша гипотеза проиграла.
Углубитесь в данные, проведите исследование пользователей, постарайтесь понять, почему тестовая версия не работает так, как ожидалось. Ведите общую с командой базу знаний (Confluence), место, в котором вы расписываете изначальные ожидания от эксперимента и последующий результат. Все эти данные, в свою очередь, помогут вам в следующих экспериментах.
Все мы ошибаемся, и это нормально.
Людям вообще свойственно переоценивать свою способность к рациональным и правильным решениям.
Есть отличный афоризм по этому поводу: «Ошибки — налог на развитие.»
Внедрение эксперимента
После положительного эксперимента должно идти его внедрение (замена контрольной версии на тестовую).
Проведение эксперимента без последующих действий бессмысленно.
Часто бывает такое, что получив статистически значимый результат (наша гипотеза подтвердилась), мы не можем её внедрить, т.к. изначально не прошли все стадии согласования. Заранее обдумайте все возможные проблемы при внедрении.
Вместо заключения
Независимо от того, был ли ваш тест успешным или нет, относитесь к каждому эксперименту, как к возможности для обучения.
Используйте то, чему вы научились, в работе со следующими гипотезами.
Удачи вам в дальнейших экспериментах!
