

Введение
Привет! Меня зовут Максим, я управляющий партнёр в KTS.
Недавно мы автоматизировали общение пользователей с поддержкой в банке ДОМ.РФ. Мы внедрили чат-бота на основе своего конструктора Smartbot Pro, и за время работы вместе с командой банка выстроили логику по обработке 550 разных сценариев. В итоге сейчас наш сервис успешно обрабатывает 40% входящих обращений клиентов.
Ниже расскажу подробнее про наш конструктор, задачу клиента и как мы её решали.
О продукте
Smartbot Pro – low code платформа для создания чат-ботов в виде блок-схем с возможностью интеграции с другими системами прямо из интерфейса. Выбор подходящего сценария взаимодействия с пользователем происходит с помощью нейросети.

Блок-схемы. Основное поле работы — дерево блоков сценария, где администратор выстраивает логику общения с пользователем.
В конструкторе доступны 3 вида блоков:
События: сообщение от пользователя.
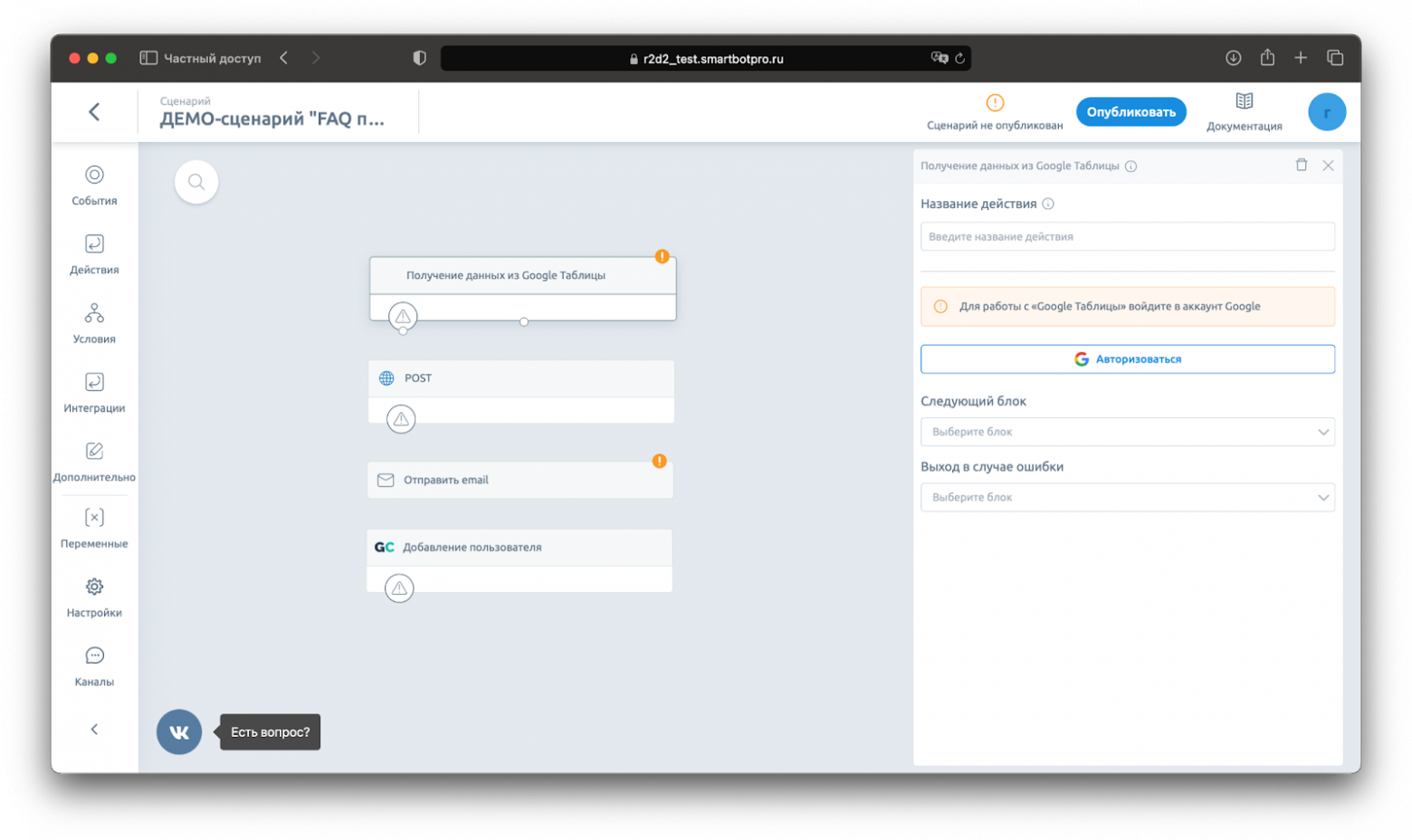
Действия: отправить сообщение, установить переменную, сохранить данные от клиента, записать в статистику, выполнить SmarQuery, добавить пользователя в список или удалить, перейти в другой сценарий и запланировать выполнение события.
Интеграционные блоки, которые позволяют обмениваться данными с внутренними системами банка (микросервисами): Новая Афина, кредитный конвейер АПИКС.
Подбор сценария нейросетью. Наша архитектура построена таким образом, что нейросеть помогает системе выбрать наиболее подходящий сценарий, по которому пользователь дальше предсказуемо идет. Точные формулировки не требуются, пользователю достаточно ввести что-то похожее на вопрос в базе.
Интеграции. Обычно при общении чат-бота с пользователем требуется отправить данные о пользователе в CRM-систему. Для таких случаев в продукте есть готовые интеграции, а также возможность отправить любой HTTP-запрос в любую систему. Например, с помощью блока HTTP-запросов мы сделали бота для создания комнаты в Zoom.
Low code. Для использования Smartbot Pro не нужно быть программистом. При этом для большей кастомизации и уменьшения размера дерева можно использовать блоки выполнения скриптов на языке SmartQuery — это наш собственный python-подобный язык. Кроме этого, на нем можно конструировать сложные условия.

Задача клиента
Банк ДОМ.РФ входит в топ-15 по капиталу и активам среди всех российских банков. Это большой банк, в котором только сотрудников 3300 человек. Продуктов много, соответственно, много сценариев общения с клиентами.
Задача банка была отвечать на вопросы по 200 продуктам и автоматизировать около 20 уникальных сценариев ведения пользователя «по скрипту». Сейчас бот содержит 550 сценариев, в которых собраны 3100 блоков. При этом время ответа продолжает укладываться в нормативные 3 секунды.
Что позволило организовать так много сценариев
Если просто создавать новые сценарии на каждый случай, то рано или поздно большое количество сценариев будет сложно поддерживать и модифицировать. Чтобы справиться с таким объемом, мы использовали несколько основных фичей:
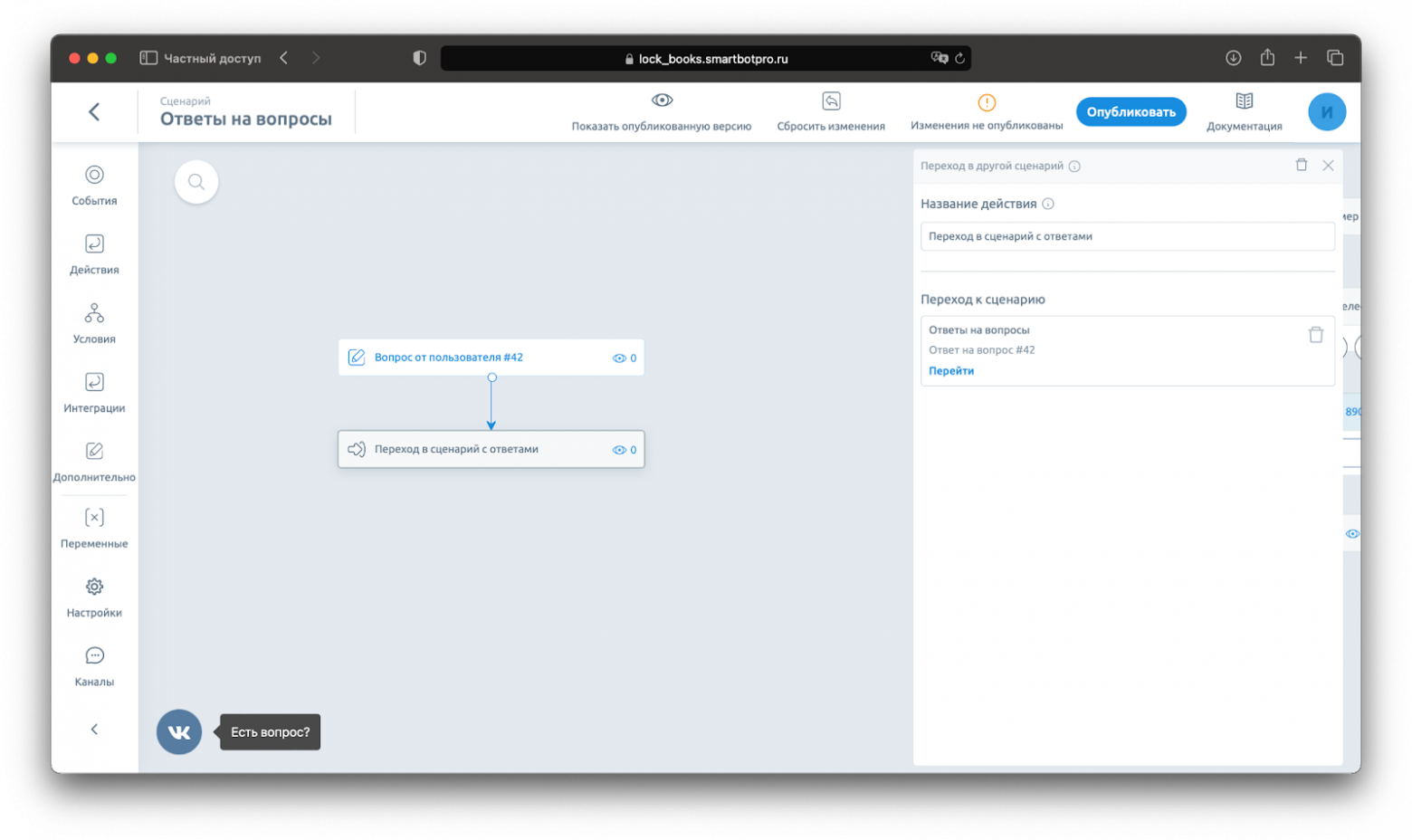
Порталы. Повторяющуюся логику мы не дублируем, а выделяем в отдельный сценарий, в который делаем переходы из других сценариев с помощью блока-портала. Например, если каждое взаимодействие нужно заканчивать сбором фидбека с пользователя.
Вывод близких по смыслу вариантов. Сценариев много, поэтому если бот не достаточно «уверен» в выборе сценария, он предлагает список ближайших, отсекая варианты, которые совсем не подходят.
Приоритет выбора сценария. Иногда может произойти так, что срабатывают сразу несколько условий событий. Например, у нас есть условия по ипотеке и условия по кредиту. Пользователь пишет: «условия». В стандартном случае бот выберет случайный сценарий из наиболее подходящих. Если банк хочет продвинуть свои ипотечные продукты, то можно настроить приоритет сценария условий по ипотеке. Тогда пользователи чаще будут узнавать именно об условиях по ипотеке.
Оптимизация Frontend
К работе с объемными графами сценариев можно подойти фундаментально и написать своё решение с нуля, используя WebGL. Этот способ требует много времени на разработку, так как надо программировать с нуля всю логику графа и отображения блоков.
Второй вариант — взять готовую библиотеку, которая реализована с помощью обычных HTML-элементов. Этот вариант мы и выбрали, взяв за основу JSPlumb. Она легко кастомизировалась под наш дизайн и давала хорошие показатели производительности.
В среднем в сценариях банка около 50 блоков. При этом всё-таки есть отдельные сценарии, которые сильно выходят за средние показатели. На таких сценариях интерфейс немного лагал. Чтобы оптимизировать его работу для таких сценариев, мы действовали так:
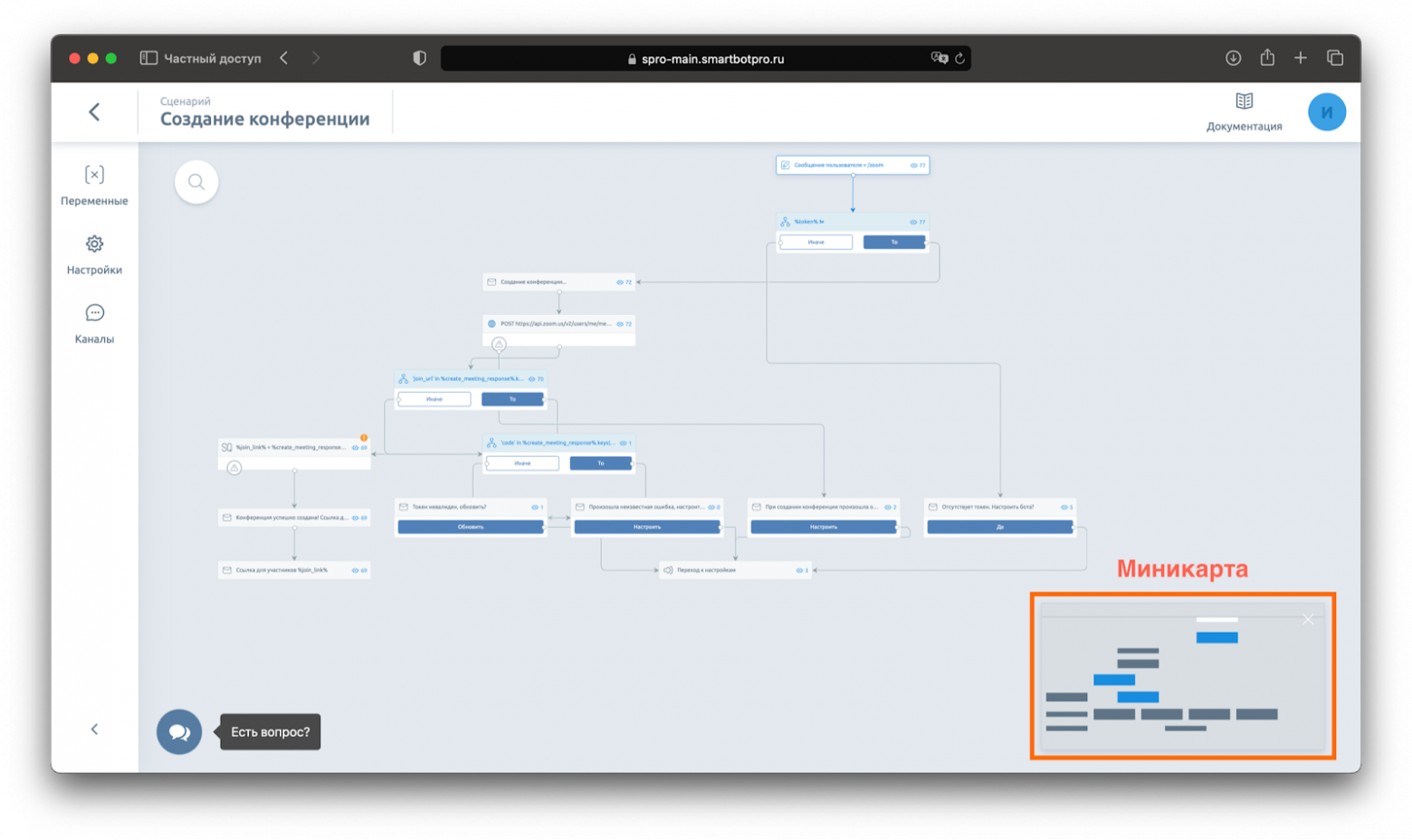
Шаг 1. Зум. Больше всего времени уходило на перерисовку блоков при движении по дереву. При этом, если на экране видно только небольшое количество блоков, то обработка идёт быстрее. Поэтому мы ограничили зум, а для более удобной ориентации по графу добавили миникарту.
Шаг 2. Анимации. Когда пользователь двигает карту, запускается рендеринг, на котором есть этап пересчёта. Если при этом включена анимация плавного движения, при работе начинаются лаги, потому что нужно делать много пересчётов.
Производительность интерфейса зависит от мощности устройства, и в идеале ограничение нужно рассчитывать индивидуально под каждое. Но браузер не даёт всю нужную информацию. Поэтому мы остановились на эмпирически вычисленном числе в 300 блоков, после которого анимация отключается.
Кэширование блоков
Кэш блоков — одноступенчатый и хранится только в памяти приложения, так как это самое быстрое хранилище.
При получении события в канал, который относится к проекту, в память приложения выполняется загрузка всех блоков этого сценария, канала, проекта и этой версии. Версии делятся на опубликованную — аналог production, и неопубликованную — аналог stage.
Дальше все блоки раскладываются на категории: например, все блоки входов, реакции, глобального поиска и остальные. Благодаря этому осуществляется более быстрый доступ к необходимой категории.
Кэш является вытесняющим, то есть в нем хранится N последних запрошенных пар каналов/проектов/версий. При любом изменении — публикации новой версии, перезапуске или изменении блока — кэш инвалидируется.
Нюансы запуска и внедрения
Кластеризация. Чтобы запустить первую версию бота, мы обработали исторические данные. Кластеризация вопросов помогла нам объединить похожие вопросы в «пачки» и выявить из них наиболее частые.
Близость вопросов определяется алгоритмом OPTICS (Ordering Points To Identify the Clustering Structure) на основе модели LaBSE: текст преобразовывается в векторы, которые сравниваются между собой по косинусному расстоянию. Наиболее близкие по смыслу группируются, и мы получаем заранее заданное число кластеров с очень похожими вопросами.
Таким образом, мы использовали реальные вопросы клиентов для формирования сценариев общения пользователей с ботом. С помощью кластеризации мы сделали это быстро и качественно: за 4-5 дней мы разобрали все реальные запросы от пользователей. Переработать такой объём работы вручную практически невозможно.
Интеграция с Keycloak. Для начала мы использовали готовую систему OAuth2-proxy, которую разложили в кластер Kubernetes. Затем через эту систему и Ingress-контроллер настроили проверку авторизации для всего входящего трафика.
Затем интегрировали систему банковский ролей в Keycloak в наш сервис и сделали нативное наследование прав: если у сотрудника в Keycloak есть права администратора на наш сервис — создаем внутренний аккаунт пользователя в нашем сервисе с равнозначным правом.
Видеокарты в Kubernetes. Пробросить железную видеокарту в виртуальную машину не так просто, в этом нам помогла команда банка.
У банка были видеокарты Nvidia. Чтобы активировать их, нужны лицензии. Лицензии бывают разные в зависимости от целей работы и активируются только в каком-то определённом режиме. После этого их надо поставить на серверы, которые находятся в разных ЦОД. На серверах нет прямого доступа в Интернет, поэтому драйверы подбирали вручную: необходимо было найти тот драйвер, который подходил бы под требования — модель видеокарты, тип лицензии, поддержка виртуальных машин и работы в Docker.
Нюансы поддержки
Локализация ошибок. Сообщения с сайта передаются в CRM-систему, которая решает: перевести диалог на оператора или на чат-бота. Если диалог переводился на бота, сообщение поступало к нам. Дальше мы отдавали ответ на это сообщение CRM-системе, а та отдавала ответ на сайт по Websocket в реальном времени.
В итоге сообщение проходило 4 отрезка, прежде чем ответ возвращался к пользователю — если случалась ошибка, она могла произойти на любом из этих четырех отрезков.
Так как наша система была крайней в этом процессе взаимодействия, при возникновении ошибки было важно быстро определять источник ошибки, и если она была не нашей стороне, оперативно сообщать об этом коллегам.
Оптимизация точности распознавания. Для повышения точности распознавания по основным тематикам продакт-менеджер со стороны банка смотрит в Tableau и дописывает тренировочные фразы, если средняя вероятность по частым вопросам слишком низкая.
Результаты
Количество диалогов в чат-боте — 7 000 в месяц.
Бот успешно обрабатывает 40% из них — это 2 800 диалогов.
97% пользовательских запросов обрабатываются быстрее 3 секунд. В нашем случае чат-бот работает не напрямую с каналами, а через CRM, поэтому это хороший результат.
Команда банка ДОМ.РФ поделилась советами по развитию бота-ассистента на первые месяцы после запуска и полезными фичами, которые влияют на основные метрики:
«Как воспитать приличного виртуального ассистента»
