

Привет, Хабр! Меня зовут Миша и я фронтенд-разработчик в Сравни. Сегодня расскажу историю об одном рефакторинге. Как мы сначала копили джентльменский набор: лишние запросы и библиотеки, спагетти из кода и обещаний, пелена гигабайт в Docker-билде и отсутствие времени даже на размышления. Потом рефакторили, а теперь стараемся не допустить повторения проблем.
Самая сложная часть всего этого процесса оказалась не там, где мы предполагали изначально. Отсюда и идея для этой статьи – подсветить частный опыт, который, возможно, натолкнёт вас на какие-нибудь полезные идеи. В общем, тут не каузация, не агитация, а история одного рефакторинга. Давайте обо всём по порядку.
Откуда вообще берётся рефакторинг
Эта история началась примерно полгода назад, когда я пришёл в команду ОСАГО. Я нажал заветную кнопку для клонирования репозитория и увидел достаточно классическую картину. Это был проект, который тяжело вздыхал, но всё ещё подавал признаки жизни. Там была куча библиотек, зависимостей, компонентов, функций – значительная часть этого выглядела лишней.
Некоторое время на встречах с фронтендерами мы тягостно вздыхали о состоянии проекта, но в какой-то момент сделали следующий шаг: завели роадмап улучшений. Это не было чем-то глобальным, состоящим сплошь из диаграмм Ганта и отсортированного по RICE бэклога — было больше похоже на список доработок, если не для увеличения, то хотя бы для удержания уровня дофамина во время работы.

Одной из проблем была малая прозрачность состояния проекта. Малая прозрачность – большая ошибка. Во-первых, если прозрачности нет, о проблеме знаете только вы, а значит, лучше сразу забыть о времени на улучшения. Время даруется нам свыше, нельзя просто так взять и пойти что-то там чинить, когда захочется. Во-вторых, закон Мерфи никто не отменял: что может сломаться, сломается – прозрачности нет, знаете об этом только вы, ответственность за косяки ложится на ваши и без того загруженные плечи.
Поэтому всегда, в любое время, в любой непонятной ситуации нужно сразу оповещать команду и бизнес обо всех слабых местах проекта, которые видишь.
И тут сразу же на всякий случай дисклеймер: даже со списком доработок, оповещением всех причастных о проблемах и имея возможность оперативно устранять часть косяков – факапов всё равно будет не избежать.
Один из кейсов – разработка новой версии анкеты ОСАГО. Специфика бизнес-процессов наших продуктов такова, что анкета – довольно важная штука. Пользователь вносит свои данные, мы это всё валидируем, проверяем, подсказываем варианты и в итоге предлагаем лучшие предложения по страхованию.

Изначально анкета была построена на нашей первой дизайн-системе, проект был полностью на styled-components, сама анкета сделана на обычных формах. Потом начали делать вторую версию анкеты с улучшенным, как казалось в то время, вариантом самописных форм.
Во время разработки вышла новая дизайн-система, которая не оптимально взаимодействовала с нашими технологиями. В итоге этого кастомизированного франкенштейна должным образом запустить не удалось. Но зато анкета содержала в себе все дизайн-системы, кастомные компоненты и впитала в себя абсолютно всё, до чего удалось дотянуться.
Мы взялись за разработку новой версии анкеты. Для ускорения разработки мы переиспользовали архитектуру и часть контроллеров от предыдущей версии. Это оказалось фатальной ошибкой. В процессе запуска всплыли недочеты: косяки архитектуры, необходимость поддержки нескольких версий анкет, активное развитие новой версии, синхронизация хранилищ и так далее.
В итоге всё вылилось в то, что цикломатическая сложность нашего проекта с каждым коммитом росла в геометрической прогрессии.
Обидно! Вроде работа работается, какие-то боли устраняются, на Code Review никто не филонит, но проект по сути всё равно находится на уровне “хотелось бы получше”, а разработчики ни на секунду не покидают темпоральную ловушку с бесконечным техдолгом.
Как мы продавали идею рефакторинга бизнесу
Вопросы есть, пора искать ответы. Мы решили изучить следствия проблем, по ним выявить причину, составить план решения и с этим сходить к бизнесу. Я полетел в Питер к одному неравнодушному коллеге. Ключевая и самая продуктивная часть мозгового штурма выглядела примерно так:

Наша задача состояла в том, чтобы выявить проблемные места и сформулировать конкретные точки приложения усилий. Мы накидали 16 пунктов, показали этот материал ещё одному коллеге-разработчику, и он по доброте душевной добавил нам добрую дюжину проблемных мест. Что ж, материалы собраны, можно изучать.
Причина оказалась не самой оригинальной на свете. Проект нашей команды — по сути, стартап. Разработка ведется конвейерным потоком, перевести дух особо некогда, макеты и требования к функциональности легко могут измениться во время тестирования задачи, а пока ты вносишь новые правки, всё становится неактуальным, так что в итоге всё сделанное тобой радостно удаляется. Времени на развитие инфраструктуры особо нет, времени на рефакторинг – тем более. Все новые фичи, по-хорошему, должны быть готовы вчера. Что-то в задачах делается на скорую руку, и впоследствии остается в таком виде.
Такова специфика стартапов.
В ходе мозгового штурма мы насобирали довольно много информации, но для похода к бизнесу одного списка проблем было мало, нужен был план по их устранению – туда мы включили собственно проблемы, причины и варианты решений.
С нашим предложением мы собрались в уютной компании с продакт-оунером, delivery-менеджером и лидом направления – и стали думать. Переписывать весь проект изначально не было нашей задачей. Это могло бы решить проблемы с “наследством”, но потенциально порождало кучу новых вопросов. Наш план был составлен примерно на год, больший упор делался на рефакторинг.
Однако лид команды и delivery-менеджер поддержали идею дать новую жизнь проекту – и мы посчитали, что отказываться не пристало. Началась работа по созданию ОСАГО 2.0. Настал тот момент, когда казалось, что мы решили все наши проблемы, но на деле оказалось, что нет. Да, мы разобрались с причинами проблем, выбили время на рефакторинг, учли особенности разработки, но нам ещё необходимо было каким-то образом не скатиться обратно.
Перестройка процессов в общем и распределение ролей в частности
На этом этапе истории давайте обратимся к жизненному циклу задачи. Нужно учитывать, что над задачей работает не один разработчик, а целая команда. И как она будет выполнена по части скорости и качества – зависит от работы, проделанной на каждом этапе цикла разработки.
В качестве примера можно вспомнить Формулу-1, где процессы выстроены идеально и всё работает как единый слаженный механизм. Там счёт идёт даже не на секунды, а на доли секунд. Поэтому если мы хотим наладить процесс разработки, просто поправить один из пунктов не получится.

Сейчас у нас ведётся работа по выстраиванию процессов по всем направлениям, но сегодня я сосредоточусь на этапе поддержки – именно она является основой для того, чтобы не допустить повторения ситуации, от который мы уходили с помощью рефакторинга.
На всякий случай: тут речь не о пользовательской поддержке, в духе того, что мы всей толпой пошли общаться с клиентами, а о поддержке кода, который мы создали, как разработчики.
Здесь у нас было несколько вариантов развития событий. Первый — работать больше и усерднее. Если наша основная задача — дать полную нагрузку разработчикам, а не ускорить время проверки гипотез и принести профит пользователям, то это лучший вариант. Если нет, то будет немного сложнее.
Так как мы смирились, что наш проект в рамках компании – “стартап”, и не всегда есть возможность и время на полноценную поддержку окружения в момент разработки, мы договорились с бизнесом на один человеко-день в спринте на технические задачи. Договорённость предполагала, что это не просто какой-то сферический день в вакууме, а полноценный процесс, в рамках которого мы заранее планируем задачи, а затем выполняем. Если нет задачи на планирование предстоящего спринта, тогда мы работаем дальше просто по целевым задачам.
Следующий шаг – это разделение по ролям в команде. Выглядит это примерно следующим образом:
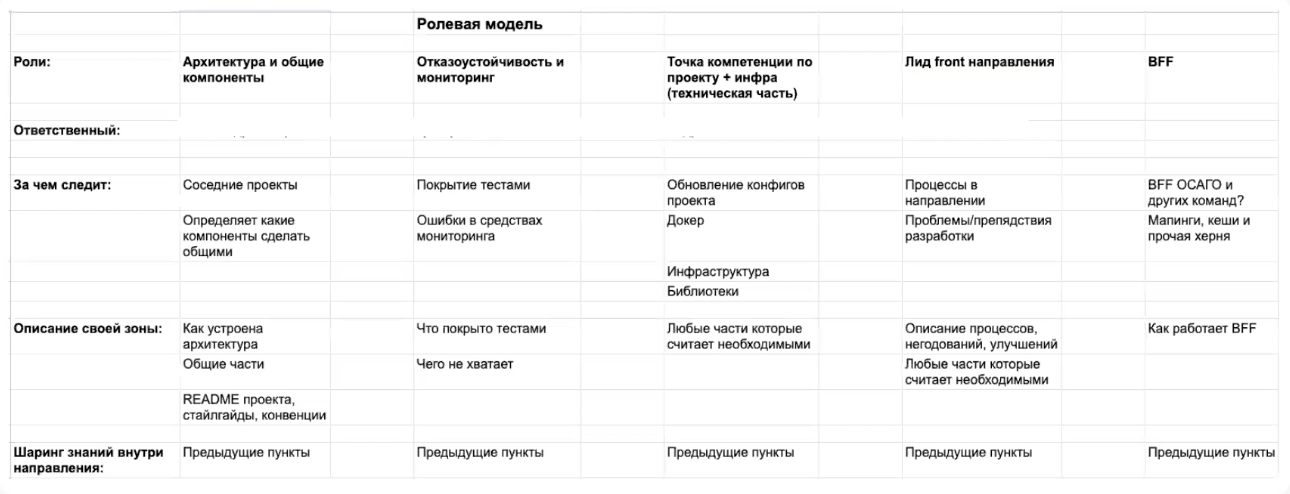
Это не совсем про должности, матрицу компетенций или зону ответственности в классическом понимании. Предназначение этой модели – разбить проект на некоторые области и выделить сотрудника, который в эту область будет погружен сильнее остальных, будет её развивать, следить за улучшениями, распространять знания на команду, описывать нужное в документации.
Один из плюсов такого разделения — появляется возможность быстрее получать экспертное мнение по тематическим вопросам. Плюс, так как мы обращаемся к конкретному человеку за информацией, то уменьшается риск срабатывания фактора “должен сделать непонятно кто из команды”. Такое случается: приходят люди из соседней команды, тегают всю команду, просят, например, сменить текст на какой-нибудь вьюшке. И вот четыре человека останавливают свою работу, смотрят этот текст, а нового текста ещё нет, и вообще, все эти данные идут откуда-то из SEO, так что разработчики тут вообще не при чем. Но при этом все дружно теряют много времени.
Описываемую модель разделения ответственности можно рассматривать как задел для индивидуального плана развития. При этом сотрудник развивается в направлении, не только интересном для себя, но и полезном для проекта. Также идёт развитие команды за счёт шаринга знаний. Учитывая темп разработки, не всегда есть возможность самому уследить за всеми изменениями вокруг, а тут есть выделенные люди, которые гарантированно этим займутся.
Еще одно преимущество разделения ролей — больше эффективности на Code Review. Многие вещи могут ускользать от взгляда разработчиков, для этого достаточно много причин. Но погруженный в свою область коллега будет тщательнее обращать внимание на свою часть кода.
А появление документации помогает делать более аккуратный онбординг, и соответственно, мы облегчаем вход в команду новым разработчиком и уменьшаем бас-фактор.
Важно понимать, что как внедрение ролевой модели, так и остальные изменения – это комплекс мер, а не отдельно взятые независимые активности. Например, возьмём Code Review. Есть такие процессы, когда его нет, а качество кода не страдает; экономится время, которое раньше тратили на просмотр. Но чтобы такое работало, нужно сделать большую подготовительную работу, внедрить разные вспомогательные процессы, вроде более активного дизайн-ревью, эксперт-ревью и прочего. Так что вопрос не в том, делать или не делать Code Review, а как выстроить комплекс взаимосвязанных мер для достижения наших целей по качеству кода.
Естественно, в этом подходе есть и минусы, и, возможно, один из главных побочных эффектов наших изменений – это всё не бесплатно. Любая поддержка, любое развитие требует времени, которое при других обстоятельствах мы могли бы потратить на реализацию новых фичей.
Ещё один минус – пересечение зон развития, где гипотетически могут появиться конфликты интересов людей из команды, но мы пока с таким не сталкивались.
Тут важно помнить, что модель не высечена в камне – при необходимости она адаптируется, расширяется, меняется, поэтому что-то придумать можно всегда.
Давайте расскажу о проблемах, с которыми мы столкнулись, на примере. Довольно нетривиальным делом оказалось сформулировать область ответственности архитектора. Когда мы только составляли роадмап, мы накидали модель директории нашего проекта, которая исключала бы существующие недостатки. По итогам встречи с бизнесом по переписыванию проекта, одним из условий было защитить архитектуру нашего лида.
Мы примерно расписали архитектуру из документации, но помимо этого, нам была нужна схема взаимодействия компонентов. Конечно, на слух всё казалось легко, пока не начали делать. В общем, у нас появилась модель инициализации и модель взаимодействия, на которой тоже далеко не всё было понятно.


После долгих обсуждений и более детального разбора, на примере нашего лендинга мы собрали уже более что-то связное и наглядное:

Данная схема помогла нам более подробно погрузиться в итоговый вариант взаимодействия элементов, заранее подумать над некоторыми неочевидными моментами в слоях приложения. Ну и, собственно, в таком виде человек в роли архитектора может описывать трудные для понимания места. При этом лучше, чтобы они были малоизменяемыми, потому что всё равно у нас уходит ресурс на поддержку.
***
Итого, к этому моменту история одного рефакторинга пришла к следующему: шаги придуманы, первые из них сделаны. Что дальше? Во-первых, дополнительно увеличить время на технические задачи до двух-трёх дней. Далее — закрепить и модифицировать имеющиеся процессы. Тут можно сравнить с диетой. Чтобы она помогала, нужно следовать ей постоянно.
Прямые и побочные эффекты рефакторинга
Итак, какие выводы мы можем сделать в результате всей этой истории?
Первое и самое важное – повышение прозрачности проекта. В жизни бывает всякое, проектам случается находиться в разных состояниях — от успешного и процветающего до дёргающегося в конвульсиях. В любой ситуации текущее состояние проекта должно быть максимально прозрачным. Если у проекта скелетов в шкафу больше, чем в парижских катакомбах, то это очень серьёзная проблема. Если о проблеме никто не знает, она увеличивается многократно.
Второе — это осознание неизбежности факапов. Рано или поздно происходит “та самая” встреча, на которой всё тайное становится явным. И лучше, конечно, чтобы у вас в тот момент был листок с планами, с предложениями, как чинить. А ещё лучше, чтобы все эти замечания и предложения вы уже освещали ранее. Гораздо разумнее реализовывать их в более спокойной обстановке, чем потом тормозить развитие бизнес-фичей и пытаться в объятиях пламени мостить из костылей дорогу в светлое будущее.
Третье — наличие целей и планов. Они должны быть всегда. Как сказал Михаил Чигорин, сильнейший шахматист России XIX века, «лучше плохой план, чем отсутствие плана». В планах также должна быть прозрачность, как со стороны разработчика, так и со стороны бизнеса. Таким образом, можно подготовиться к каким-либо изменениям, например, архитектурным, и заранее найти баланс между временем на техдолг и на фичи.
Четвёртое – процессы. Тут мы в очередной раз убедились в правильности капитанской мудрости: важно выстраивать процессы, исходя из реалий и специфики проекта и команды. Да, нельзя выстроить всё идеально и купаться в купели блаженства, окруженной радужными единорогами, но большую часть рисков можно минимизировать. При этом нельзя забывать, что нет универсального процесса — это только инструмент, и важно непрерывно адаптировать его под свою специфику.
Закончить рассказ об истории одного рефакторинга хотелось бы вот на чём. В наших реалиях нет таких ситуаций, что разработчики всегда шикарны, а менеджмент плохой (впрочем, как нет и обратной ситуации). Нет безоговорочно раз и навсегда правильного или неправильного решения: вчерашняя отличная архитектура может сегодня застопорить всю разработку, прекрасная фича – внезапно оттолкнуть клиента, а тихая и незаметная – привлечь (помните, как было с селфи-палкой?).
Да, то, как инженеры и бизнес смотрят на одни и те же вещи, может отличаться. Но по факту мы все стремимся к одному – стабильному и работающему продукту, а также балансу скорости и качества в развитии продукта.
Да, проблемы и разногласия будут случаться, но помните: любые проблемы подсвечивают слабые стороны, дают возможности к развитию, а также позволяют детальнее прогнозировать будущие шаги. Поэтому не нужно бояться проблем – из них часто можно получить больше позитива, не только негатив.
