
Привет, меня зовут Татьяна Лабчук, я работаю full-stack QA в Альфа-Банке: пишу автотесты и тестирую руками. Автотесты пишу на Java, поэтому примеры в статье, в основном, будут на этом ЯП, но их можно переложить на другие языки.
План статьи:
Проблематика: проблема черного ящика и почему это вообще нужно решать.
Варианты решения проблемы.
Подробно про мок-сервер, как один из вариантов решения проблемы: как выбрать и в чём польза.
Самописный мок-сервер в реальной задаче.
Закрепляем материал в блоке «Польза мок-сервера».
Начнём с проблематики.
Проблема, или Что я тестирую?
Я тестирую документооборот. У нас он разделен на два микросервиса:
API внутреннего документооборота, который отвечает за внутреннюю обработку документов.
Шина, которая отвечает за преобразование данных из внешнего формата во внутренний и обратно.
Общение между микросервисами идет через брокер сообщений Kafka, в которую один микросервис передает документ во внутреннем формате, а другой забирает. Ещё есть внешний провайдер, который отправляет документы во внешнюю сеть. Общение с внешним провайдером идет по API с помощью протофайлов. Шина общается с внешним провайдером, забирает и отдаёт документы во внешнем формате, в зависимости от направления документа.
Покажу на примере получения входящего документа, как это работает.

Шина для преобразования данных спрашивает внешнего провайдера: «Есть ли новые документы?»
Если они есть, провайдер их отдаёт.
В Шине происходит какая-то магия.
Документ в преобразованном формате кладется в Kafka. Если вы знакомы с Kafka, то вы знаете, что она не отдает документы, а просто их хранит, грубо говоря.
API внутреннего документооборота запрашивает эти документы.
И получает от Kafka.
Я тестирую, собственно, магию, которая происходит в Шине. Небольшое пояснение — с чем мы вообще работаем при тестировании Шины:
Шина общается с провайдером.
Получить доступ к обработанных в Шине данным можно через базу данных и через Kibana, где складываются логи.
Шина также отдает данные в Kafka.
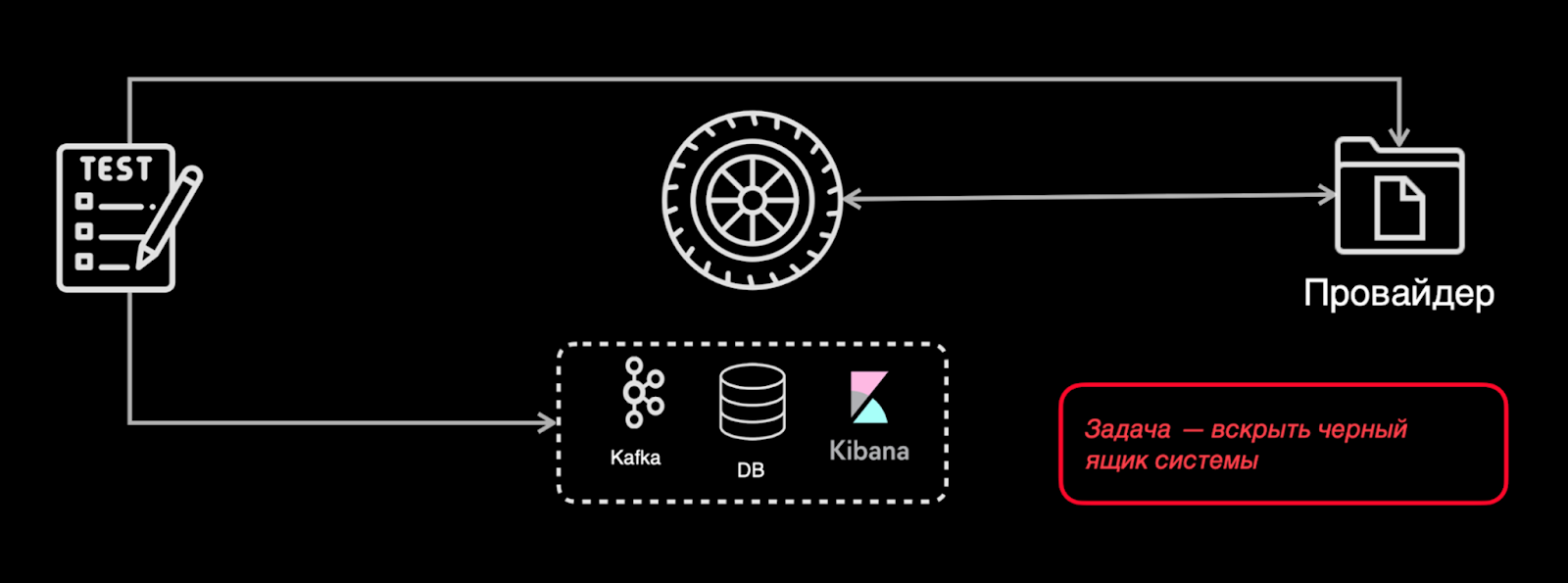
Тесты могут обращаться к провайдеру, потому что они могут посмотреть в ящик. Тесты могут обратиться к Kafka, базе данных, а ручной тестировщик еще может изучить логи в Kibana.
Здесь возникают проблемы, объединённые в две группы.
Мы не можем проверить, что происходит в Шине. Не получится подробно посмотреть этапы преобразования и очередность запросов, потому что логи очень ограничены и часто их вообще нет из-за того, что некоторые данные пользователей нельзя показывать.
Провайдер. У нас есть тестовый стенд, но на нём нет возможности гибко менять какие-то данные, изменять его коды ответов и тестировать логику, которая затрагивает платный функционал.
Как следствие, мы не можем взаимодействовать с Шиной напрямую. Мы видим её как «чёрный ящик» — систему, которую не понимаем.
Как вскрыть чёрный ящик и понять, правильно ли он работает?
Варианты решения: проксирование или мокирование?
Посмотрим ещё раз на проблему, с другой стороны. У нас есть наш сервер, внешний сервер, запросы и, соответственно, ответы. Вскрыть ящик можно узнав, что в запросе, и что происходит в ответе.

Отлично, проблема сужается до задачи «Вскрыть запросы и ответы». У неё есть пара вариантов решения.
Первый вариант — проксирование. Отправляем запрос с нашего сервера на внешний сервис, а между ними ставим прокси и преобразуем запрос и ответ.
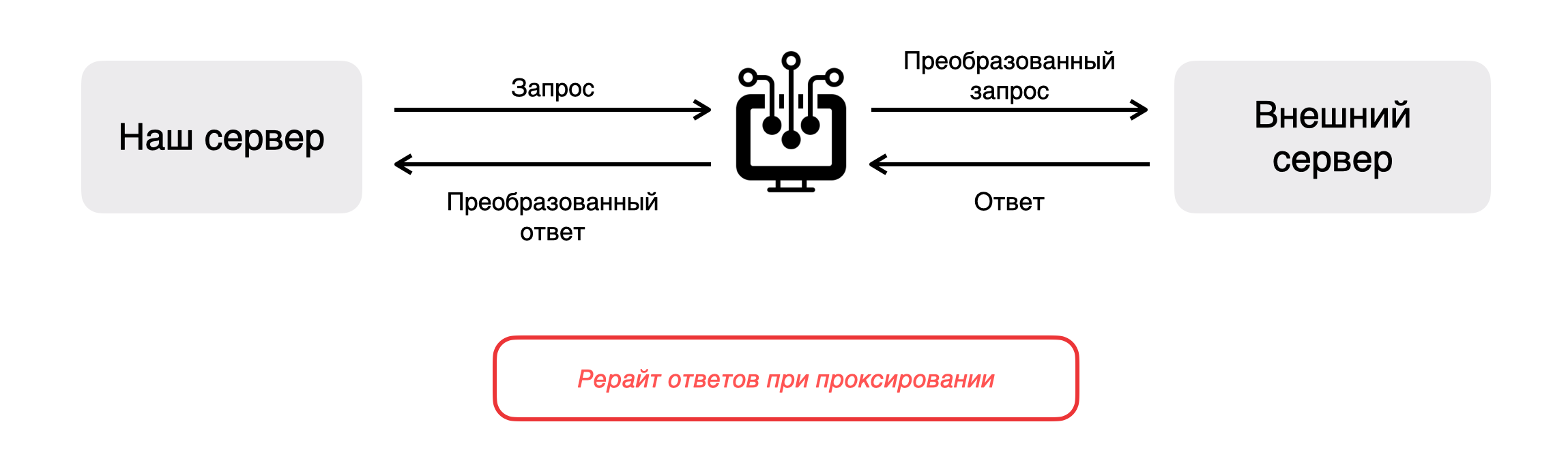
Второй вариант — мок-сервер, который заменяет наш внешний сервер. Мы сможем смотреть запросы и ответы, которые он отправляет и управлять ответами.

И, в случае с автотестами, или даже с ручными тестами, это выглядит как то, что:
первоначально устанавливаем ожидаемые ответы;
триггерим систему тестами: она делает запрос не к реальному серверу, а к моку;
отправляет ответ, который мы настроили;
после проверяем тестами, что происходит, в том числе, проверяем запросы.

Примечание. Также я рассматривала вариант «Отдать тестирование разработчику», но он быстро отпал. Взаимодействие шины с внешними сервисами тяжело покрыть юнит-тестами — это всё-таки интеграционное тестирование, если посмотреть на тот же провайдер. А отдавать писать интеграционные тесты разработчику было бы долго и не эффективно.
И в проксировании, и в мокировании есть плюсы
Прокси работает с реальным сервером — работа с реальными данными всегда важна, поэтому это практически всегда плюс.
Мокирование не работает с реальными данными, но позволяет избавиться от зависимости от реального сервера. При этом большинство задач на моках покрывает то, что нельзя решить на реальном серваке.
При проксировании ответ зависит от работы реального сервера.
Простота настройки. Если у вас сложная система — выбирайте мокирование, потому что прокси чуть сложнее настраивается, нужно разбираться в инструментах чуть глубже. А в моках надо построить запрос, отдать его и всё, вы великолепны.
Если вдруг вы рассматриваете вариант создания своего инструмента, то в моках это реально. В прокси тяжелее, если вообще возможно — нужно обладать очень глубокими знаниями.
Преимущество проксирования — это возможность работы с несколькими API, а под каждый мок-сервер вам нужно создавать отдельный мок-сервер.
Чтобы не запутаться и принять окончательное решение, я собрала таблицу критериев и зелёным выделила те, что важны мне.
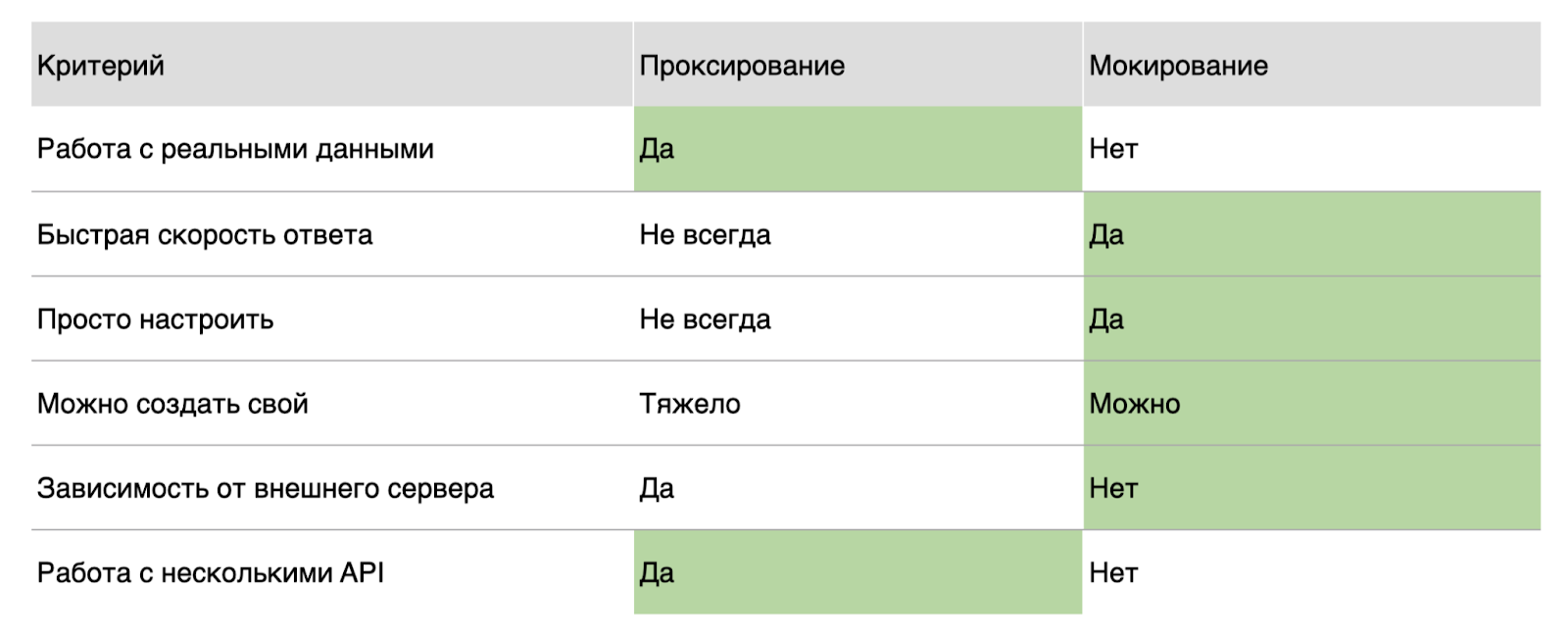
В итоге я выбрала мокирование — для меня у него намного больше преимуществ. Но возникает дилемма — писать самой или выбрать из множества готовых решений. Опять выбор и сравнение.
Готовое решение или самописный мок-сервер?
Опять же, выписала все преимущества и недостатки обоих решений в сводную таблицу. Зеленым обозначила то, что было важно, жёлтым — наоборот.
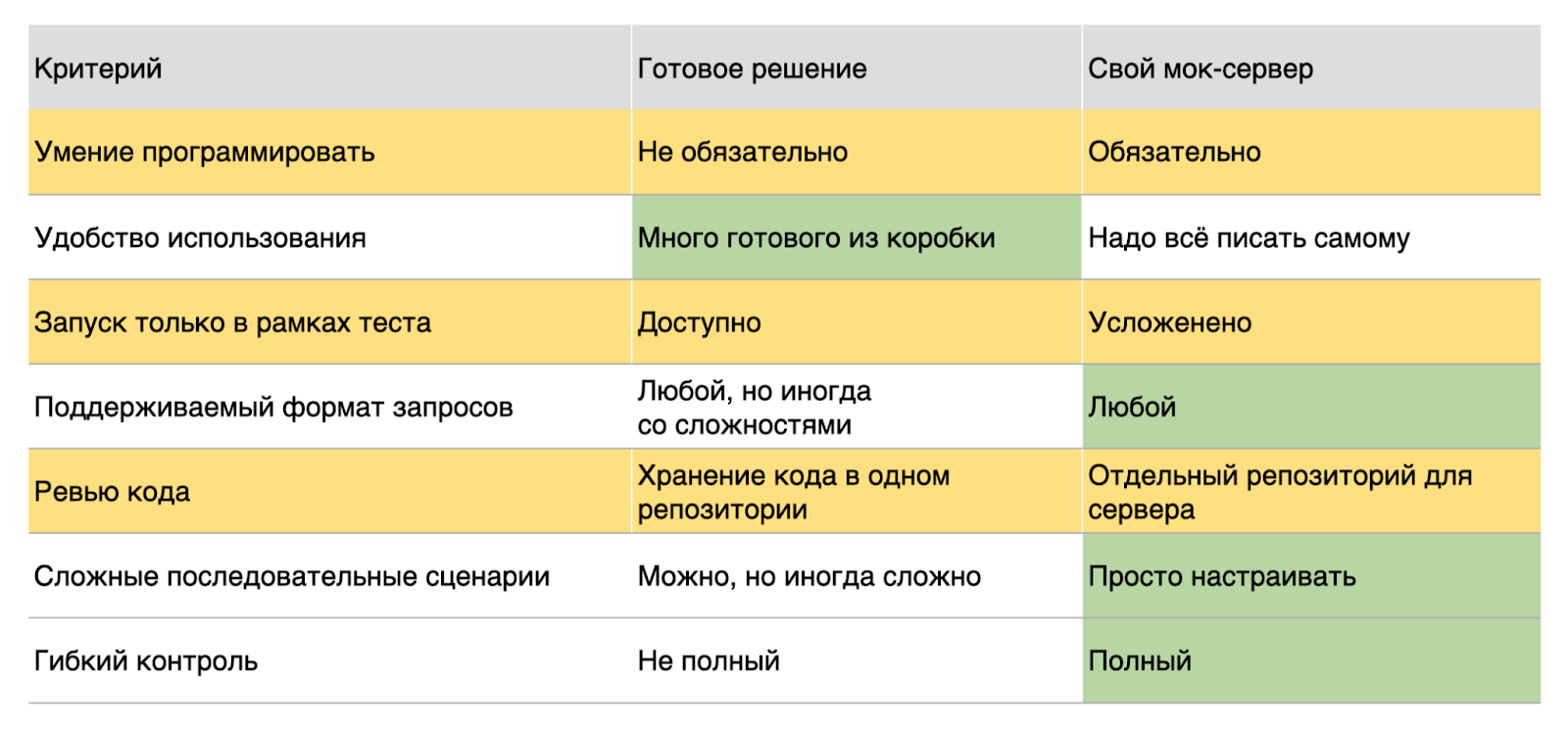
Теперь разберём, что в ней есть.
Программирование:
Минус самописного решения — требуется навык программирования. Даже если умеешь программировать, чтобы дорабатывать под себя, то столкнешься со спецификой, при этом не все решения можно дорабатывать, придётся подобрать подходящий инструмент, и на всё это нужно время.
Преимущество готовых решений, в том, что если не пишете тесты, не программируете и не хотите углубляться в эту тему, то и не надо — берёте готовое решение, запускаете, настраиваете и счастливо живете.
Для меня что то, что это не так важно — я программирую, в целом, и этого не боялась. Даже наоборот, задача запрограммировать свой мок-сервер — это интересно. А когда пишешь свой мок-сервер, то глубже погружаешься в документацию внешнего сервиса, который тестируешь — ведь ты должен его скопировать, должен понимать, как он работает. Как следствие, находишь недостатки, преимущества, особенности, хедеры, которые аналитик не замечал.
Удобство использования:
Здесь выигрывает готовое решение — за тебя всё сделали, просто пользуйтесь благами чужого кода.
А у мок-сервера преимущество в удобном добавлении логирования. Дорабатывать логирование придётся самостоятельно, но можно сделать его настолько гибким, насколько позволят ваши навыки — например, вывести одно значение из какого-то огромного запроса и видеть только его
Запуск только в рамках теста:
В готовом решении добавляете библиотеку, запускаете, переписываете у своего тестируемого сервера адрес, куда он теперь стучится вместо реального сервака, и тестируете. Тест запускается — запускается мок-сервер, заканчивается тест — мок-сервер выключается. Удобно.
В самописном варианте запуск в рамках теста усложнен. И я даже не знаю, как этому подойти — у меня в этом потребности нет — мне было важно тестировать руками.
Поддерживаемый формат запроса:
Мне подойдёт любой, потому что у меня протофайл. Запрос к серверу и его ответ в формате protobuf в коде похож на JSON, но каждое поле имеет свою последовательность.

Если утрировать, то первое поле обязательно будет ID, второе поле обязательно будет ИНН, и так далее. Общение между серверами посредство этого формата происходит в bytearray — массиве байтов. В Postman такой запрос будет выглядеть как на картинке справа — в основном, ничего не понятно.
Готовое решение отлично поддерживает почти любые форматы, но если его не дописывать, это выглядело бы так же нечитаемо и неудобно настраивать руками. Ты же как-то должен найти место, где изменить данные? В общем, работать стало абсолютно неудобно. Свой мок-сервер работает с любым форматом, потому что сам настраиваешь как хочешь, а дописывать уже готовое решение порой трудно и неудобно, особенно, если у тебя большой объем данных.
Ревью кода:
Взаимодействие с готовым решением можно написать в одном репозитории. Это преимущество, в том числе для автотестов, потому что один репозиторий — одно ревью, нет нужды выделять дополнительные ресурсы.
Для отдельного сервера нужен отдельный репозиторий, отдельное ревью, и выделенное на это время. Но для меня этот «минус» не имел значения — мне даже хотелось, чтобы меня поревьюировала мой техлид и я прокачала скилл программирования.
Сложные последовательные сценарии:
Мой сервер взаимодействует с внешним сервером по очень сложным последовательным сценариям. Один запрос начинает за собой тянуть десять, и настраивать руками готовые решения было бы неудобно, плюс их нужно где-то хранить, переустанавливать.
Если у тебя сервер, где ты всё прописал сам, то просто берёшь переменную и, не напрягаясь, прокидываешь её в любой следующий запрос.
Гибкий контроль:
Это важный пункт — что хочу, то и делаю.
Также для меня было важно удобство в тестировании руками — я фулстек и не только автоматизирую, а провожу и мануальное тестирование некоторых задач, поэтому мне хочется нажать одну кнопочку и запустить преднастроенный сервер. Или я хочу заменить одно значение всего ответа и запросом заменяю только его. Тестировать руками становится в разы удобнее, проще и приятнее.
Суммируя все плюсы и минусы, я выбрала писать мок-сервер самостоятельно.
Если же вы выберете готовые решения, присмотритесь к WireMock, MockServer и Mountebank. У них есть комьюнити, хорошая поддержка и их удобно использовать.
Готовим и внедряем мок-сервер
Время от MVP до прода
По времени всё заняло:
Один день — разобраться с библиотекой для API (используется Spring). Помогла великолепно написанная статья, которая за один день позволила погрузиться в среду написания серверов и ускорила меня в разы.
5 дней — работающий мок-сервер с минимальным количеством запросов. У меня было примерно 7 эндпойнтов и столько же дополнительных. Чтобы всё это описать, поднять сервер и наладить взаимодействие с тестируемым сервером понадобилось пять дней.
2 дня — логи, реализацию задержек, и, обязательно, тестирование мок-сервера (это важно)
Чтобы вы могли сравнить, то когда я начала писать сервер, на Java я программировала всего 7 месяцев, а работала автотестировщиком — 6. Я знала и использовала Java Core, lombok (плагин для Java, который упрощает жизнь) и Spring, который упростил написание сервера раз в 20.
Сейчас времени на доработку уходит 1-2 часа, если просто допилить небольшую функцию (ещё надо тесты написать), а если сложная логика или новая ручка — 1-2 дня.
Раз я смогла, то и вы сможете. Вас ждут три этапа.
Первый — написать мок-сервер. Если таки используете готовые решения, то поднять его, настроить.
Второй — доработать тесты, если у вас автотесты.
Третий — научиться запускать все это вместе: сервер, который вы тестируете и ваш мок-сервер.
Начнём с первого.
Как писать мок-сервер?
Я программирую на Java, поэтому и примеры будут на Java. Мы всегда начинаем программирование с библиотек. Выбираем библиотеки:
Для написания мок-сервера (библиотеку из семейства Spring).
Для работы с запросами/ответами.
Для сериализации/десериализации, если вам удобнее работать со структурами, а пересыл происходит с помощью string, например.
Для рандомных данных. В моём случае многие данные не важны и я их просто рандомизирую. К тому же это просто удобно, когда у тебя много рандомных данных, которые исполняются и сервер точно сработает, даже если данные поменяются.
Для тестирования сервера. Не ленитесь это делать — мы тестировщики, мы также тестируем свой сервер.
dependencies {
implementation group: ‘org.springframework.boot’, name: ‘spring-boot-starter-web’, version: ‘2.5.3’
implementation ‘org.apache.commons-text:1.9’
implementation ‘com.google.protobuf:protobuf-java:4.0.0-rc-2’
implementation ‘com.fasterxml.jackson.dataformat:jackson-dataformat-protobuf:2.13.4’
testImplementation(‘org.springframework.boot:spring-boot-starter-test’) {
exclude group: ‘org.junit.vintage’, module: ‘junit-vintage-engine’
}
}Теперь переходим к коду.
Из чего состоит код мок-сервера?
Из нескольких папок.
Билдеры ответов. Это паттерн проектирования, который позволяет упростить процесс создания объекта: можно заполнять не весь объект, а выбрать какое-то поле, закинуть значение и всё, объект создан. В этой папке лежат все билдеры ответов, которые используются в контроллерах.
Конфигурация. Я создала файл (класс), который позволяет во все контроллеры пробрасывать настройки ответов, задержки, специфические данные, если они повторяются у всех контроллеров. Помогает экономить время — не настраивать каждый контроллер заново.
Util — папка с файлами для рандомизирования данных.
Контроллеры — ручки (эндпойнты): и те, которые запрашивают тестируемый сервер, и те, что я использую в тестах для настройки полей.
Application — класс для запуска сервера.
Сделали сервер, доработали, теперь научим тесты работать с мок-сервером. Для этого их надо допилить.
Что допилить в тестах?
Вот пример того, как в тестовый проект прописывается API мок-сервера.
@FeignClient(name = “diadoc-mock-client”, url = “${multiedo.diadoc-mock.url}”)
public interface DiadocMockClient {
@PostMapping(value = “V3/Authenticate/config”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
String authenticateConfig(@RequestParam(“statusCode”) Integer statusCode,
@RequestParam(value = “retry”, required = false) Boolean retry);
Существует ручка V3/Authenticate, с которой работает тестируемый сервер.
Создадим ручку настройки конфигурации (V3/Authenticate/config), которая позволяет настраивать ответ от V3/Authenticate.
Мы хотим, чтобы ручка V3/Authenticate отдавала 400.
На ручку настройки конфигурации мы отправляем “statusCode” параметр 400 и всё, теперь мок-сервер будет на ручку V3/Authenticate отдавать 400.
Также мы её можем обвесить логированием, если нам это нужно в тестах.
@Slf4j
@Service
@RequiredArgsConstructor
public class DiadocMockService {
private final DiadocMockClient diadocClient;
public String changeAuthConfig(Integer statusCode) {
log.info(“Изменили код ответа authenticate на {}”, statusCode);
return diadocClient
.authenticateConfig(statusCode, null);
}
Теперь можем просто запустить тест, посмотреть логи теста, увидеть: «Здесь меняем код ответа authenticate на такой-то» и счастливо живем, не возвращаемся к коду теста, не смотрим какая там абракадабра. А если все же абракадабра есть, то в логах её смотреть приятнее.
Для запуска тестов под локальную работу в Java можем настроить профиль:
либо запускать файл профиля через настройки запуска;
либо, как у меня, прописать profile непосредственно в application.yaml и активировать профиль, который нужен, в зависимости от текущего окружения.
spring:
application.name:
profiles:
active: “local”
- - -
spring:
profiles: local
Это вся настройка автотестов. Теперь научимся запускать всё вместе.
Как запускать?
Например, нам нужно запускать сервер, который мы тестируем. В моем случае, мне было важно и запускать Kafka, и MinlO (это объектное хранилище, система хранения файлов), и базу данных, локально, чтобы избавиться от последствий того, что на сервере что-то может упасть, так как слишком загрузится другими системами и прочим. Для этого я использую Docker, файл запуска под который мне написал мой любимый разработчик.
Важно напомнить, что когда вы поднимаете свой сервер, который вы тестируете, вам нужно переписать и изменить адрес внешнего сервиса, чтобы он стучался не на реальный внешний сервис, а на ваш мок.
Мок-сервер я запускала локально, у меня не было потребности ни переносить его в Docker, ни запускать удаленно, поэтому запускала через IJ. И дебажить удобно.
Мок-сервер на реальной задаче
Теперь покажу, как работает мок-сервер на реальной задаче.
Представим, что мы тестируем документооборот. Прилетает задача «Протестировать поведение системы, когда отправитель содержит в поле ИНН разное количество цифр». Если вы не тестировали документооборот или что-то связанное с документами, вам, возможно, сейчас ничего не понятно. Сейчас объясню.
Документы — это просто входящий документ, например, письмо в ящике. У письма есть содержание, отправитель и получатель, обычно e-mail.
В случае с документооборотом у отправителя и получателя есть много других полей, например, КПП, ИНН и прочее.
Эта информация получается ручкой GetOrganization, в моем случае. Поле ИНН у получателя может содержать 10 или 12 символов. Количество цифр зависит от типа контрагента: 10 цифр — юридическое лицо, 12 — ИП.

В зависимости от количества цифр, система будет по-разному реагировать.
Если цифр 10 — сохраняем информацию в таблицу LegalCounterparty, а название организации записывается в поле FullName.
Если цифр 12 — информацию сохраняем в таблицу EntrepreneurCounterparty, а название организации разделяется на три поля: Фамилия — Имя — Отчество (если есть).
Почему вообще для этого нам нужно использовать мок-сервер? Ведь по-хорошему, такое мы должны тестировать на тестовом стенде? Но тестовый стенд есть только для ИНН с 10 цифрами. ИНН в 12 цифр проверять можно только на проде, что делать мы, конечно же, не будем.
Соответственно, дорабатываем мок-сервер так, чтобы он мог отдавать ответ с определённым количеством цифр в ИНН, и пишем тесты на ожидаемое поведение.
Начнём с того, что доработаем сервер запросами, которые позволят менять inn и fullName организации. Для этого создаём две переменных и три ручки. Первая ручка — changeInn, она будет изменять ИНН на конкретное значение: мы можем передать ей ИНН 123, и она теперь будет ИНН отдавать равным 123.
private String fullName = RandomValue.RANDOM_VALUE_ENG.generate( length: 12);
private String inn = RandomValue.RANDOM_VALUE_ENG.generate( length: 10);
@PostMapping(value = “inn”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
public ResponseEntity<String> changeInn(@RequestParam(value = “inn”) String inn) {
log.info(“Поле inn изменено на {}”, inn);
this.inn = inn;
return new ResponseEntity<>(String.valueOf(this.inn), HttpStatus.OK);
}
Вторая ручка — typeInn. Мы передаем ей тип ИНН, потому что типы всегда известны. Например, есть тип ENTREPRENEUR — это индивидуальный предприниматель. Если нам передадут этот тип, мы всегда создадим рандомный ИНН с двенадцатью цифрами. Если другой тип, то количество цифр будет 10.
@PostMapping(value = “typeInn”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
public ResponseEntity<String> changeTypeOfInn(@RequestParam(value = “typeInn”) CounterpartyDto.TypeEnum typeInn) {
log.info(“Тип контрагента изменен на {}”, typeInn);
if (typeInn.equals(ENTREPRENEUR)) {
this.inn = RandomValue.RANDOM_VALUE_ENG.generate(12);
} else {
this.inn = RandomValue.RANDOM_VALUE_ENG.generate(10);
}
return new ResponseEntity<>(inn, HttpStatus.OK);
}
@PostMapping(value = “fullName”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
public ResponseEntity<String> changeFullName(@RequestParam(value = “fullName”) String fullName) {
log.info(“Поле fullName изменено на {}”, fullName);
this.fullName = fullName;
return new ResponseEntity<>(String.valueOf(this.fullName), HttpStatus.OK);
}
Также есть ручка fullName, чтобы мы могли менять имя организации и проверять, что оно разбивается на три поля.
Дальше дорабатываем билдер ответа в соответствии с новым значением inn и fullName, потому что раньше мы отдавали рандомные значения, а теперь — конкретные. В этот билдер отправляем два добавленных поля fullName и inn и записываем соответствующие поля.
public static OrganizationOuterClass.Organization buildOrganization(String fullName,
String inn,
String boxId) {
return OrganizationOuterClass.Organization
.newBuilder()
.setFullName(fullName)
.setShortName(fullName)
.setKpp(RandomValue.RANDOM_VALUE_ENG.generate(9))
.setFnsParticipantId(RandomValue.RANDOM_VALUE_ENG.generate(10))
.setInn(inn)
.addBoxes(OrganizationOuterClass.Box
.newBuilder()
.setBoxId(boxId)
.setTitle(RandomValue.RANDOM_VALUE_ENG.generate(10))
.build())
.addDepartments(buildDepartment(RandomValue.RANDOM_VALUE_ENG.generate(9),
.RandomValue.RANDOM_VALUE_ENG.generate(9)))
.addDepartments(buildDepartment(departmentIdSender, departmentNameSender))
.addDepartments(buildDepartment(departmentIdReceiver, departmentNameReceiver))
.build();
}
Дорабатываем тесты: мы создали три ручки и нам нужно научить тесты с ними работать.
Первая ручка inn — название первоначальной ручки и поле, которое мы хотим изменить.
@PostMapping(value = “GetOrganization/inn”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
String getOrganizationInn(@RequestParam(“inn”) String inn);
Вторая — typeInn.
@PostMapping(value = “GetOrganization/typeInn”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
String getOrganizationTypeOfInn(@RequestParam(“typeInn”) CounterpartyDto.TypeEnum typeInn);
Третья ручка — fullName.
@PostMapping(value = “GetOrganization/fullName”, produces = APPLICATION_JSON_VALUE, consumes = APPLICATION_JSON_VALUE)
String getOrganizationFullName(@RequestParam(“fullName”) String fullName);
Если используем их в автотестах, сможем изменять эти поля.
Добавляем ручкам логирование. Но это опционально.
public String changeGetOrganizationTypeInn(CounterpartyDto.TypeEnum typeInn) {
log.info(“Изменяем inn в GetOrganization: тип = {}”, typeInn);
return diadocClient
.getOrganizationTypeOfInn(typeInn);
}
public String changeGetOrganizationInn(String inn) {
log.info(“Изменяем inn в GetOrganization: значение = {}”, inn);
return diadocClient
.getOrganizationInn(inn);
}
public String changeGetOrganizationFullName(String fullName) {
log.info(“Изменяем fullName в GetOrganization: значение = {}”, fullName);
return diadocClient
.getOrganizationFullName(fullName);
}
Добавляем ручки в сброс до начального состояния. У меня есть метод, который позволяет сбрасывать всё до начального состояния, например, если я решу тестировать руками, а мок-сервер отдаёт все время Entrepreneur, когда у ИНН 12 цифр. Чтобы этого избежать, я подготовила метод, который сбрасывает состояние мок-сервера до начального. Начальное состояние — когда у ИНН 10 цифр, стандартное имя и прочее.
public void resetToDefault() {
this.changeAuthConfig( statusCode: 200);
this.changeGetDocflowEventConfig( statusCode: 200);
this.changeGetDocflowEventCount(0);
this.changeGetDocflowEventPacketId(false);
this.changeGetOrganizationConfig(statusCode: 200);
this.changeGetOrganizationTypeInn(LEGAL_ENTITY);
this.changeGetOrganizationFullName(FULL_NAME_RECEIVER);
this.changeGetEntityContentConfig(statusCode: 200);
}Вот мы всё и дописали.
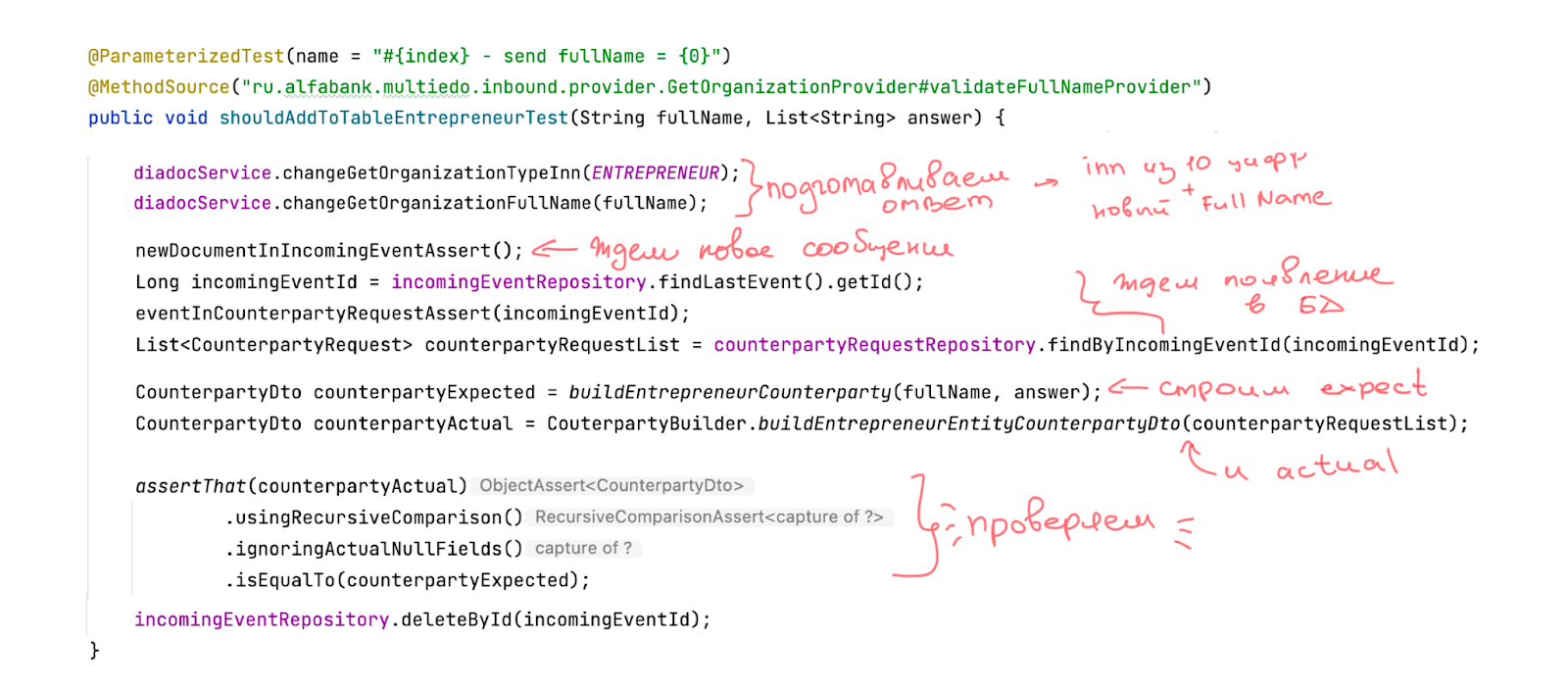
Приступим к написанию позитивного теста. Создаём тест, который должен правильно разбивать имя организации и записывать данные в таблицу, если приходит Entrepreneur, то есть 12 цифр в ИНН.
@ParameterizedTest(name = “#{index) - send fullName = {0}”)
@MethodSource(“ru.alfabank.multiedo.inbound.provider.GetOrganizationProvider#validateFullNameProvider”)
public void shouldAddToTableEntrepreneurTest(String fullName, List<String> answer) {
Подготавливаем ответ: обращаемся к мок-серверу и говорим: «Теперь ты должен давать всегда TypeInn(Entrepreneur), то есть 12 цифр и fullName, которые тебе скажу».
diadocService.changeGetOrganizationTypeInn(ENTREPRENEUR);
diadocService.changeGetOrganizationFullName(fullName);
Мок-сервер мы настроили. Теперь ждём действия сервера. У меня просто ожидание из-за того, что раз в 30 секунд сервер опрашивает мок-сервер, чтобы ему отдали новое письмо, входящий документ.
newDocumentInIncomingEventAssert();
Long incomingEventId = incomingEventRepository.findLastEvent().getId();
eventInCounterpartyRequestAssert(incomingEventId);
List<CounterpartyRequest> counterpartyRequestList = counterpartyRequestRepository.findByIncomingEventId(incomingEventId);
Документ получили, построили ожидаемой объект, построили реальный объект — обратились в базу данных, вытащили данные и проверили, соответствует ли ожидаемое поведение реальному.
CounterpartyDto counterpartyExpected = buildEntrepreneurCounterparty(fullName, answer);
CounterpartyDto counterpartyActual = CounterpartyBuilder.buildEntrepreneurEntityCounterpartyDto(counterpartyRequestList);
assertThat(counterpartyActual)
.usingRecursiveComparison()
.ignoringActualNullFields()
.isEqualTo(counterpartyExpected);
И очистили за собой все артефакты (если нужно).
incomingEventRepository.deleteById(incomingEventId);
}
Собрав всё вместе, получим такой тест.
Тестовые данные можно варьировать — убрать отчество, отправить только строчку «Татьяна» или добавить пробел в начало и посмотреть, обработается такой кейс или запишет пробел в базу данных, что у аналитики было бы неправильно.
public static Stream<Arguments> validateFullNameProvider() {
List<String> answerFull = List.of(“Labchuk”, “Tatiana”, “Sergeevna”);
List<String> answerHalf = answerFull.sublist(0, 2);
return Stream.of(
arguments(“ Labchuk Tatiana Sergeevna ”, answerFull),
arguments(“Labchuk Tatiana ”, answerFull),
arguments(“ Labchuk Tatiana Sergeevna”, answerFull),
Негативный тест. Представим ситуацию, когда появляется новое юридическое лицо и у него 9 или 11 цифр в ИНН. Когда в системе появится такой контрагент, нам важно, чтобы она не падала и не выдавала ошибки, даже если мы не добавили нововведение. Соответственно, проверяем этот кейс.
@DisplayName(“invalid inn”)
@ParameterizedTest(name = “inn = {0}”)
@ValueSource(ints = { 9, 11 })
public void shouldTurnStatusToErrorIfInnIsInvalidTest(int len) {
diadocService.changeGetOrganizationInn(RANDOM_VALUE_NUM.generate(len));
newDocumentInInomingEventAssert();
statusErrorAssert(incomingEventRepository.findLastEvent().getId());
}
Сообщаем мок-серверу, что теперь, отдавая ИНН, например, с девятью числами в ИНН, ожидаем появление нового документа и проверяем, что этот документ ушел в error. Система увидела, что количество цифр в ИНН 9, поняла, что ей это не подходит и сказала, что с таким не работает.
Что я получила от этой практики?
Я определила, правильно ли обрабатываются ошибки от внешнего сервиса. Например, мок-сервер помог выявить причину неверного поведения системы. Логика поведения системы определена кодом, но отличалась от заложенной. Оказалось, что причина в одной библиотеке. Возможно мы бы словили ошибку на проде и ещё долго искали причину, если бы не провели тесты на мок-сервере, а возможности протестировать на реальном сервере не было.
Смоделировала ответы, недоступные на тестовом стенде. Например, на тестовом стенде отсутствует определенное поле, а на проде оно есть.
Смоделировала поведение системы при медленной работе внешнего сервиса. Заложила задержку, посмотрела, как реагирует система, как ждёт, зависает или нет.
Проверила работу настройки ограничения количества запросов. В аналитике есть ограничения на количество запросов, например, если возвращается 400, ведь мы не хотим внешний сервер закидывать запросами. На реальном сервисе такой ответ не протестировать — он никогда не вернет 400, а на мок-сервисе всё получится.
Вскрыла черный ящик. Исходная задача была решена — я, наконец, увидела, что отправляет наш сервер, какой запрос шлёт ко внешнему сервису, посмотрела все поля, посмотрела направление, их заполнение. Вскрыла черный ящик полностью, потому что в логах такой информации нет.
Как это мне помогает в ручном тестировании?
Потому что я все-таки продолжаю тестировать руками.
Мок-сервер позволяет не зависеть от внутренних и внешних сервисов. У меня все развернуто локально, и я могу даже без интернета провести тесты, и не зависеть от того, подключается сейчас Kafka или нет.
Проверяю редкие узкие задачи — нет смысла их автоматизировать, но проверять надо.
Быстро создаю рандомные тестовые данные. Мне полезно, когда проверяю правильно ли сервер обрабатывает запросы, потому что на тестовом стенде они постоянны.
Проверяю негативные сценарии. Например, что будет, если отвалится мой сервис или Kafka, как себя будет вести система? Я могу запустить любые негативные сценарии — в Docker подключаю какие-то серверы и смотрю, как реагирует система.
Чем будет полезно вам?
У мок-сервера много сценариев использования. У нас всегда есть две зависимости: внешняя и внутренняя. Внутренняя — все, что относится к нашему мок- сервису и к нашему тестированию: UI, Backend, внутренние микросервисы. Внешняя — платежные системы или просто внешний сервер, как у меня.
Внутренняя интеграция:
Во внутренней интеграции мок-сервер очень может пригодиться, например, при тестировании UI при неготовом бэкенде. Если вам нужно протестировать UI, но бэкенд ещё не готов, то вы можете бэк заменить мок-сервером, сымитировать ответы с бэкенда, и так проверить UI.
А если важный критерий — не менять реальные данные в БД, то можно замокировать ответ, изменить его на тот, который хотите получить, и счастливо жить, используя мок.
Если у вас не разработан до конца соседней микросервис, а вам нужно что-то протестировать, также заменяете микросервис мок-сервером.
Внешняя интеграция:
Когда есть внешний сервис, которым вы не можете управлять, но при этом стоит задача протестировать какие-то кейсы.
Можно проводить нагрузочное не загружая внешний сервер. ДДОСьте свой мок-сервер.
Тестирование многопоточности. Например, если вы хотите протестировать много инстансов своего приложения, но тестовый стенд может вас забанить, когда вы будете направлять много запросов к тестовому стенду. Тогда заменяете внешний сервер на мок, и всё замечательно — вы никого не ДДОСите.
Платежная система — её тоже можно заменить мок-сервером.
В целом, у мок-сервера много плюсов. Он позволяет сделать гибкое решение под себя, если у вас есть внешний сервис, которыё вы не можете изменить, то мок-сервер точно поможет увеличить покрытие, сможете глубже познакомиться со своей системой, а ещё вы будете менее зависимы.
Что улучшить в мок-сервере?
Идеального продукта я не создала — есть над чем работать, и могу вам подсказать в какую сторону посмотреть, когда будете создавать свой мок-сервер.
Глубже погрузиться в тематику, например, параллельных тестов. Когда я настраиваю в одном тесте 12 символов, а в другом — 10, то параллельно тесты я не запущу, а ускорить работу тестов хочется. Пока что эта проблема у меня остаётся. Если вы её уже решили — напишите в комментариях.
Дополнительные плюшки. Некоторые вещи, которые я потом дописывала, я изначально не предусмотрела.
Встроить в CI/CD. Такой потребности у меня не было, поэтому, к сожалению, ничего не подскажу.
Проверки на реальном сервере. Даже если вы все сделали идеально, ответы реального сервера могут отличаться от тестовых. Если есть возможность протестировать на реальном сервере — тестируйте на нём, а всё остальное — на моках.
Тестировать ваш мок-сервер. Это важно. Один раз был случай, когда я думала, что не работает сервер моего разработчика. Оказалось, ошибка на моей стороне — покрывала тестами, но не идеально, потому что иногда ленилась — «На деле проверю» Сразу тестируйте ваш мок-сервер.
Полезные ссылки
Крутой туториал по популярным мокам и даже как создавать свой — Иван Пономарёв — Mocks vs Testcontainers (видео).
Подробно про WireMock:
WireMock – швейцарский нож в арсенале тестировщика. Часть 1
WireMock – швейцарский нож в арсенале тестировщика. Часть 2
Пример использования wireMock при интеграции с внешним API
Про MockServer:
Видео, которое покажет азы работа с mockServer: запуск в рамках теста (java)
Видео про то, как запустить mockServer с помощью докера и настроить его ответы запросами к API
Про Mountebank:
Пример использования (python)
Spring для ленивых. Основы, базовые концепции и примеры с кодом..
Что такое Spring Framework? От внедрения зависимостей до Web MVC
Spring MVC: создание веб-сайтов и RESTful сервисов
Рекомендованные статьи:
Также подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
