

Всем привет! Я из команды по анализу уязвимостей распределенных систем Positive Technologies. Мы занимаемся исследованием безопасности в области блокчейн-технологий и хотим поделиться обзором фреймворка для статического анализа кода, написанного на Solidity, — Slither. Он разработан компанией Trail of Bits, релиз состоялся в 2018 году. Slither написан на Python 3.
Как это работает: инструмент запускает набор предустановленных детекторов уязвимостей, проверяет указанные смарт-контракты, выводит визуальную информацию о деталях контракта. Это позволяет разработчикам находить уязвимости, улучшать понимание кода и быстро создавать прототипы новых детекторов. Slither предоставляет информацию о коде смарт-контракта и обладает необходимой гибкостью для настройки и добавления пользовательского набора функций (например, для отображения артефактов типа графа наследования). Ссылка на github проекта.
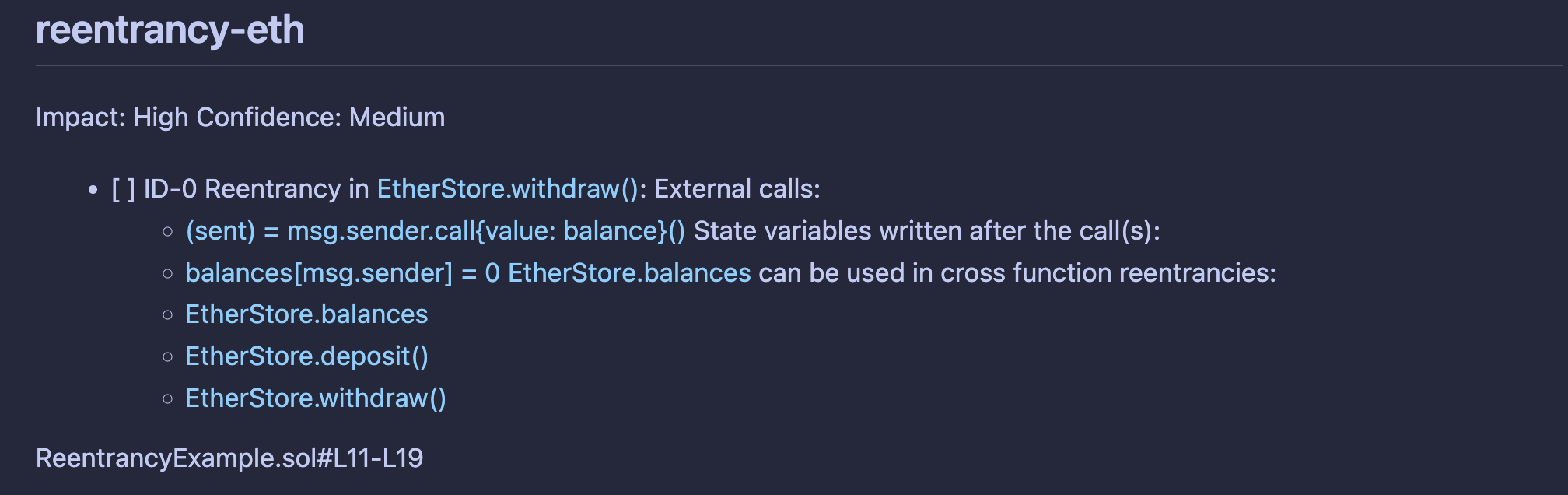
Давайте рассмотрим пример использования Slither. Ниже представлен фрагмент кода, функция withdraw() уязвима к атакам типа cross-function reentrancy. Злоумышленник может создать атакующий смарт-контракт, который несколько раз произведет вызов этой функции до момента изменения баланса, тем самым получив больше средств, чем полагалось.
function withdraw() public {
uint balance = balances [msg.sender];
require (balance > 0, “”);
(bool sent, ) = msg.sender. call{value: balance}("");
require (sent, "Failed to send Ether");
balances [msg.sender] = 0;
}
Среди детекторов Slither есть те, которые определяют потенциальное наличие reentrancy. В этом случае сработает детектор reentrancy-eth. Помимо типа уязвимости в отчете отражаются уровень воздействия, вероятность возникновения и уязвимые строчки кода. Сам отчет можно просматривать в командной строке или в MD-файле.
Принципы работы
Для лучшего понимания работы Slither мы последовательно пройдем алгоритм анализа смарт-контракта от начала до конца.
С чего начинается работа любой программы? Конечно, с входных данных. На вход Slither получает абстрактное синтаксическое дерево, которое генерирует компилятор solc из исходного кода контракта.
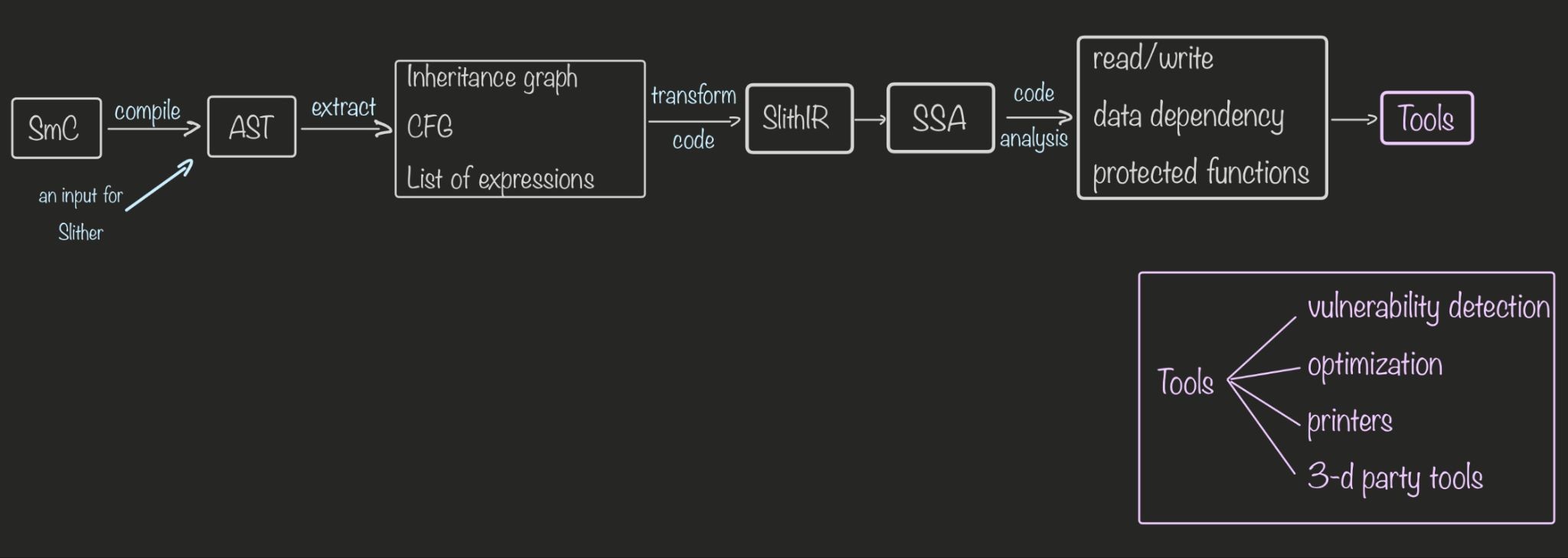
Абстрактное синтаксическое дерево (AST) — конечное ориентированное дерево, в листьях которого содержатся операнды, а внутренние вершины сопоставлены с операторами языка.

По синтаксическому дереву восстанавливаются такие представления, как граф потока управления, граф наследования, который отражает связи между классами-родителями и классами-наследниками, и список выражений для перевода в язык представления.
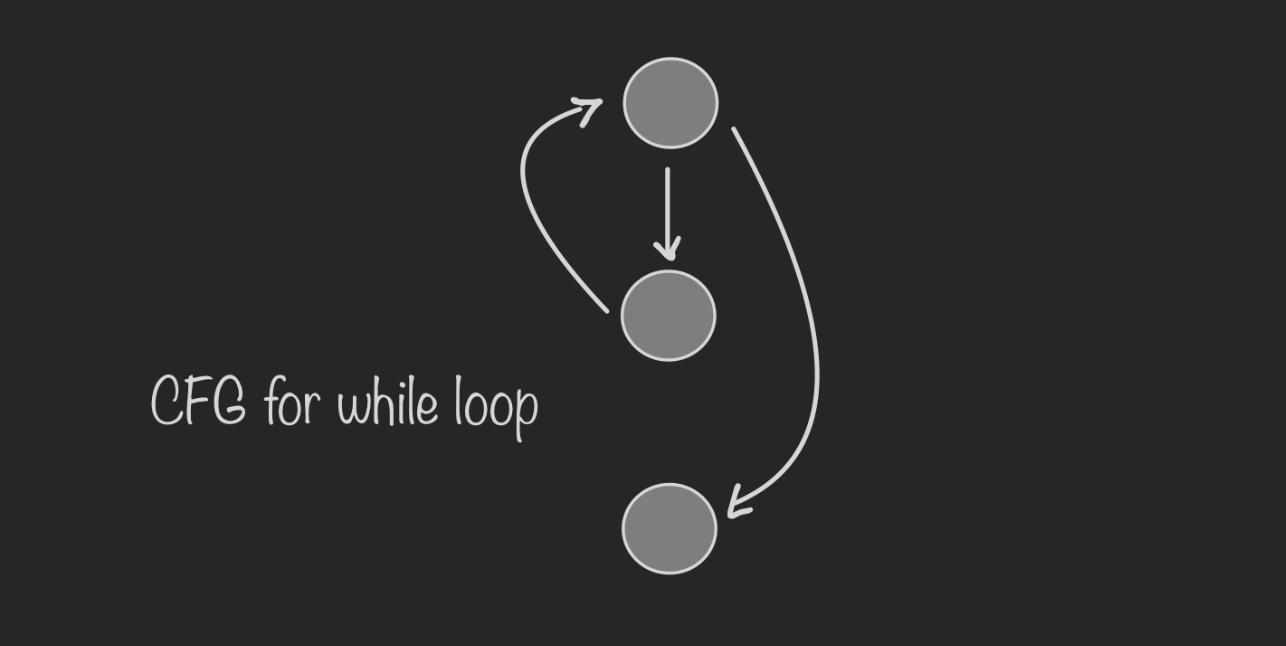
Граф потока управления (CFG) — это множество всех возможных путей исполнения программы.
Далее происходит преобразование всего исходного кода в промежуточную форму SlithIR.
SlithIR — это язык промежуточного представления кода на Solidity, созданный разработчиками Slither. При трансформации кода он опирается на граф потока управления и использует менее 40 инструкций. Понимание SlithIR не является необходимым, если вы хотите писать кастомные детекторы, однако оно пригодится, если вы планируете писать продвинутые семантические проверки.
SlithIR сохраняет две версии смарт-контракта — с SSA и без него.
SSA (static single assignment) — это еще одно промежуточное представление, в котором каждой переменной присваивается значение лишь единожды, все значения разделяются на версии. Таким образом, в представлении есть все возможные значения переменных.
Третий этап обработки кода состоит из трех видов анализа. Давайте рассмотрим подробнее каждый из них.
1. Чтение и запись
Slither определяет, какие функции или узлы CFG читают или записывают переменные, и разбивает их все на два типа — переменные состояния и локальные переменные.
2. Зависимость данных
Анализ того, как переменные зависят друг от друга. Некоторые переменные приобретают статус tainted, то есть переменная зависит от пользовательского ввода.
3. Защищенные функции
Проверка модификаторов доступа функций и привилегированных операций.
После подключаются прочие инструменты, например:
инструмент обнаружения уязвимостей;
инструмент поиска конструкций, которые можно оптимизировать;
принтеры для отображения найденной информации;
другие сторонние приложения.
Детекторы
На момент написания статьи в Slither существует 92 детектора. Оценка риска происходит по двум параметрам — impact (воздействие) и confidence (вероятность).
Воздействие классифицируется пятью типами:
optimization (оптимизационное);
informational (информационное);
low (низкое);
medium (среднее);
high (высокое).
Вероятность может быть трех типов:
low (низкая);
medium (средняя);
high (высокая).
Здесь можно найти весь список детекторов и примеры к ним.
Синтаксические детекторы
Slither перемещается по различным компонентам кода и их представлениям, чтобы найти несоответствия и недостатки, используя подход, похожий на сопоставление с шаблоном. Эти шаблоны называют детекторами. Например, синтаксический детектор проверяет затенение переменных состояния.
Семантические детекторы
В отличие от синтаксического анализа, семантический углубляется и разбирает «смысл» кода. Это семейство включает в себя несколько широких типов проверок. Они приводят к более мощным и полезным результатам, но при этом сложнее в написании. Семантический анализ используется для наиболее продвинутого обнаружения уязвимостей.
Зависимость данных
Считается, что variable_a зависит от variable_b, если существует путь, на котором значение variable_a зависит от variable_b.
В следующем коде variable_a зависит от variable_b:
variable_a = variable_b + 1Slither поставляется со встроенной проверкой зависимостей данных (data dependency) благодаря своему промежуточному представлению.
Пример использования зависимости данных можно найти в dangerous strict equalities. Здесь Slither будет искать сравнение строгого равенства с опасным значением и сообщит пользователю, что следует использовать «>=» или «<=», а не «==», чтобы злоумышленник не смог сломать контракт.
Кастомные детекторы
Slither также поддерживает добавление собственных детекторов. Вот здесь можно найти инструкцию, как это сделать.
Использование
slither target --options
Target
my-file.sol— путь до файла с исходным кодом;my-project— путь до папки с проектом Hardhat/Truffle/Foundry/Brownie/Dapp/Embark/Etherlime;0x..— адрес смарт-контракта в основной сети Ethereum;network:0x..— адрес смарт-контракта в определенной сети, где network: mainnet, sepolia, rinkeby, goerli, arbi, testnet.arbi, poly, mumbai, avax, testnet.avax, ftm, bsc, testnet.bsc.
Важная особенность: тестирование по адресу не сработает, если смарт-контракт не верифицирован, так как код берется с API Etherscan.
Options
Давайте разберем, на мой взгляд, наиболее полезные функции Slither. Чтобы ознакомиться с полным списком, выполните команду: slither -h
Solc
Можно пробовать разные версии компилятора с помощью флага:
--solc-solcs-select solc1, solc2 # зависит от solc-select
--solc-solcs-bin solc1, solc2
Если нужно подтянуть зависимости к файлу и скомпилировать его через solc, то можно добавить remappings:
--solc--remaps my-remap
Выбор детекторов
По умолчанию Slither запускает все детекторы, но есть возможность как включить, так и исключить их из сценария тестирования:
slither file.sol --detect d1, d2
slither file.sol --exclude d1, d2
Кроме того, можно настроить игнорирование определенных уровней риска:
slither file.sol --exclude-low
Есть возможность убрать из отчета результаты анализа зависимостей:
slither file.sol --exclude-dependencies
Выбор принтеров
slither file.sol --print p1, p2
С помощью принтеров можно получить следующие артефакты:
call-graph— граф вызовов;inheritance-graph— граф наследования;cfg— граф потока управления;evm— опкоды evm для каждой функции.
Чтобы получить полный список принтеров выполните команду: slither --list-printers
Сохранение отчетов
Чтобы сохранить отчет в формате MD, выполните команду:
slither my-file.sol --checklist >> my-report.md
Создание отчета в формате JSON: --json my-json
Кроме того, есть вариант создать ZIP-архив с JSON-файлом: --zip my-zip
Фильтрация путей
Когда тестируется целый проект, в нем могут находиться файлы, которые нам не нужно пропускать через анализатор (например, тесты, заглушки).
Чтобы исключить файлы из сценария тестирования, можно воспользоваться флагом --filter-paths my-path.
Конфигурационный файл
При желании большинство параметров можно описать в конфигурационном файле my-config.config.json.
Передать свой конфиг можно с помощью команды: --config-file my-config.config.json
{
"detectors_to_run": "detector1,detector2",
"printers_to_run": "printer1,printer2",
"detectors_to_exclude": "detector1,detector2",
"exclude_informational": false,
"exclude_low": false,
"exclude_medium": false,
"exclude_high": false,
"json": "",
"disable_color": false,
"filter_paths": "(mocks/|test/)", # regex
"legacy_ast": false
}
Заключение
Итак, мы рассмотрели основные функции Slither. Он прекрасно подходит для быстрого тестирования большого объема кода и нахождения известных уязвимостей. Но не стоит забывать о том, что возможности статического анализа достаточно ограничены, поэтому существует вероятность, что какие-то баги не будут выявлены.
В Slither случаются и ложные срабатывания: уязвимость вроде бы и есть в отчете, но ее невозможно эксплуатировать ввиду каких-то дополнительных условий. Иногда возникают проблемы с преобразованием сложных конструкций (вроде пользовательских операторов) в промежуточное представление. В связи с этим необходимо помнить, что функциональность Slither обновляется и не стоит пренебрегать другими видами и инструментами тестирования.
А вы сталкивались со Slither в своей практике или, возможно, использовали другие статические анализаторы? Вместе с командой будем рады обсудить в комментариях, насколько эффективным вам кажется использование этого типа анализа кода для поиска уязвимостей.
