В 21 веке лавинообразно распространяется телефонное мошенничество, а доля разоблачения и поимки таких преступников мала. Можно ли определять мошенников в первые минуты разговора, если их телефонные номера постоянно меняются? Рассмотрим в статье.
В какой-то момент устав от проблемы телефонных мошенников, мы задались вопросом их идентификации до того момента, когда они полностью завладеют нашим вниманием и нашими средствами. Да, крупные компании предлагают установить бесплатные определители номера, которые оповещают о подозрительных номерах. Но принимая во внимание, что телефонные номера у мошенников постоянно меняются, обозначенные определители не дают высокого уровня защиты.
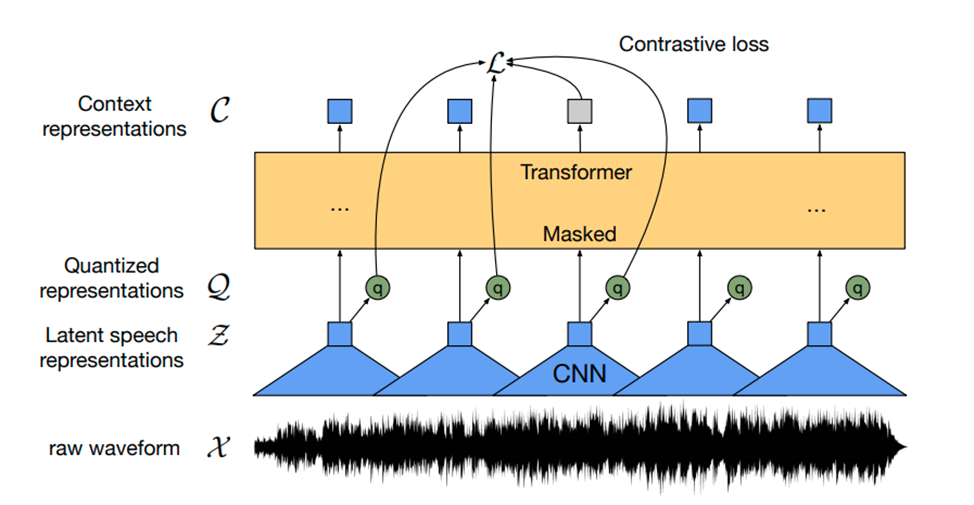
Помимо номера есть ещё голос мошенников. В данном ключе неопределённость о том, что мошенник может намеренно менять голос с помощью технических средств, мы опускаем в связи со сложностью их технической реализации, а навыки подражателя для ML моделей не страшны. Поэтому мы хотим создать модель, которая будет работать параллельно разговору и идентифицировать говорящего.
Так, набрав базу из записанных телефонных разговоров и выбрав точно определённые беседы, мы сможем обучить модель на нужных голосах.
Базовый подход к работе со звуковыми данными в ML заключается в предобработке записей: