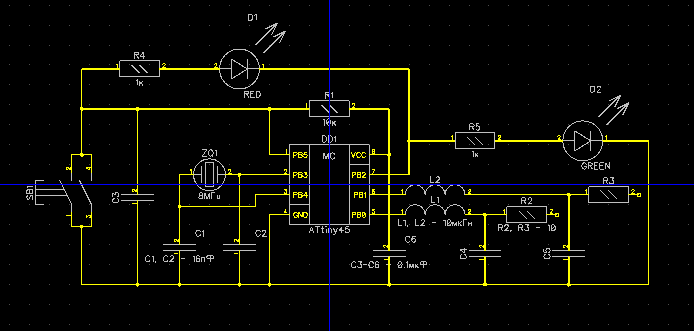
Move semantics в C++11 и STL-контейнеры
2 мин
Эта небольшая заметка о том, как с приходом нового стандарта C++11 изменились требования стандартных контейнеров к своим элементам. В C++98 от элемента контейнера требовалось, по сути, наличие «разумных» конструктора копирования и оператора присваивания. Если, например, объект вашего класса владеет каким-либо ресурсом, копирование обычно становится невозможным (по крайней мере, без «глубокого» копирования ресурса). В качестве примера давайте рассмотрим следующий класс-обертку вокруг
FILE*, написанную на C++98:class File
{
FILE* handle;
public:
File(const char* filename) {
if ( !(handle = fopen(filename, "r")) )
throw std::runtime_error("blah blah blah");
}
~File() { if (handle) fclose(handle); }
// ...
private:
File(const File&); //запретить копирование
void operator=(const File&); //запретить присваивание
};

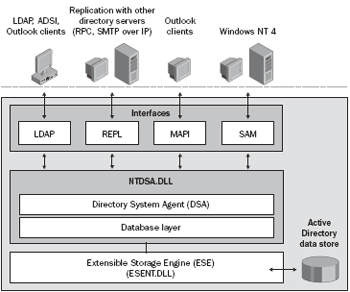
 В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект
В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект 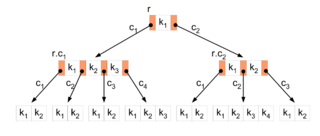 Один из сотрудников Google в 20% свободного времени разработал и выложил под свободной лицензией библиотеку
Один из сотрудников Google в 20% свободного времени разработал и выложил под свободной лицензией библиотеку