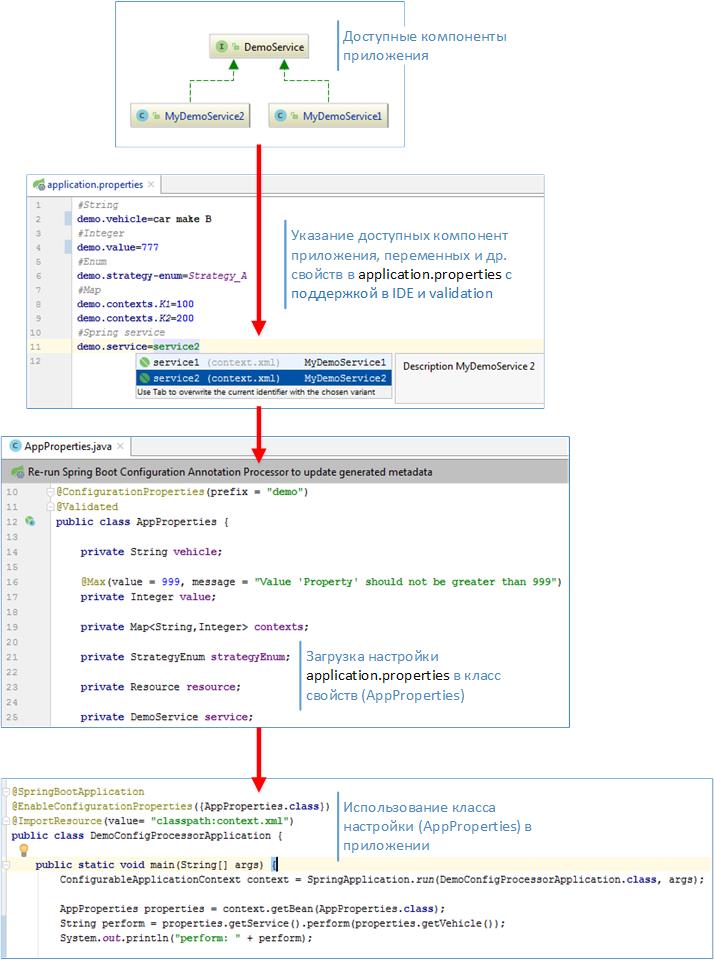
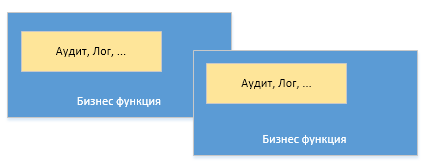
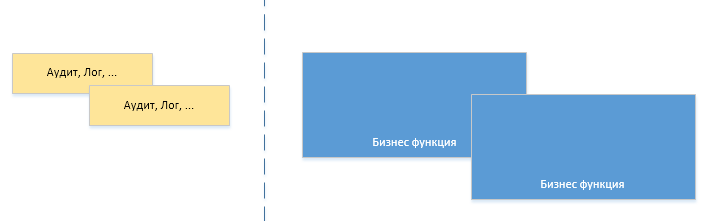
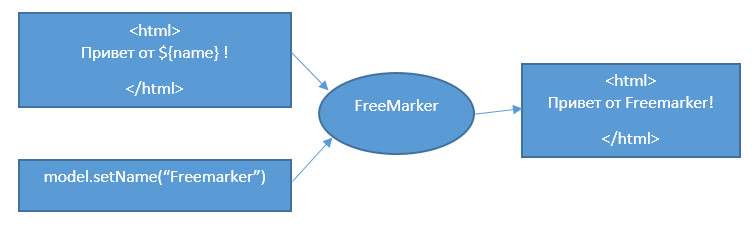
Казалось бы что здесь такого? подключаем к проекту fabric8-maven-plugin и вперед: сборка, запуск приложения в OpenShift. Но когда изучал хотелось большего понимания этого процесса, а затем хотелось большего контроля и свободы над процессом сборки и развертывания приложения в OpenShift. Таким образом получился следующий сценарий и с такими особенностями.
- Сборку артефакта произвожу сам, своим инструментом (maven, gradle и др.)
- Контролирую создание Docker Image через Dockerfile
- Build и Deployment процесс в Openshift настраивается в шаблоне, т.е. любые характеристики контейнера, pod настраиваются.
- Таким образом сам процесс можно перенести во внешнюю систему сборки, развертывания