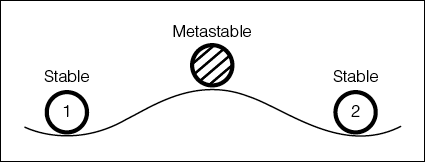
Программировать с нуля. «Сейчас» — самое подходящее время, чтобы начать
7 мин

(Иллюстрации к статье А.П. Ершова «Программирование — вторая грамотность»)
Стив Джобс не написал ни строчки кода, Билл Гейтс — написал. Пол Грэм — первоклассный программист, Питер Тиль — юрист по образованию, сооснователь PayPal и владелец Palantir (написал ли он что-нибудь?), а Илон Маск в детстве написал свою игру и успешно её продал.
Никита truesnow из #tceh сказал мне, что на курсе «Врубаемся в Ruby» они научат программировать любого человека, даже с нуля. Я спросил его: «А с гуманитарием справитесь?» И мы задумались, были ли случаи, когда «гуманитарий» выучил язык программирования?
На ум сразу пришел бомж-программист, но после успеха с его приложением он предпочёл остаться «дзен-монахом». Есть ли еще примеры? Вдохновляющий пример, что научиться кодить может каждый — слепой программист. Когда я прочитал статью на Хабре «Смотря на код с закрытыми глазами», то понял, что нет преград, кроме собственных отмазок.
А у меня для вас есть три истории из моей жизни. Просто три истории.
История первая — ламер
Слово «ламер» я прочитал в «Компьютерре». Там давалось такое определение: «Ламер — отнюдь не безграмотный человек, не умеющий (как бы это помягче выразиться?) программировать». Окрылённый истиной я побежал и рассказал об этом друзьям-одноклассникам, но они предпочли поиграть в футбол, вместо того чтобы освоить суперспособности. Забавно, что потом все они зарабатывали программированием деньги, а я нет. Через неделю я записался в краевую станцию юных техников (КСЮТ), где был кружок по программированию. Там для новичков давали qbasic. А боги прогали на C.

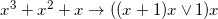 , которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам.
, которая на 6 джаве с выключенным JIT у меня давала около 10% ускорения, при этом на первый взгляд даже не очевидно что эти формулы эквивалентны (ОТКУДА ТУТ OR? ЭТО ВООБЩЕ ЗАКОННО?!), хотя это так. Под катом я расскажу, как именно получались такие результаты и каким образом компьютер придумывал лучший код чем тот, который мог написать я сам. Кевин Поулсен, редактор журнала WIRED, а в детстве blackhat хакер Dark Dante, написал книгу про «
Кевин Поулсен, редактор журнала WIRED, а в детстве blackhat хакер Dark Dante, написал книгу про «







 Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.