В предыдущей части мы рассматривали вероятностную постановку задачи машинного обучения, статистические модели, модель регрессии как частный случай и ее обучение методом максимизации правдоподобия.
В данной части рассмотрим метод максимизации правдоподобия в классификации: в чем роль кроссэнтропии, функций сигмоиды и softmax, как кроссэнтропия связана с "расстоянием" между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии. Данная часть содержит много отсылок к формулам и понятиям, введенным в первой части, поэтому рекомендуется читать их последовательно.
В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям.
Данная серия статей не является введением в машинное обучение и предполагает знакомство читателя с основными понятиями. Задача статей - рассмотреть машинное обучение с точки зрения теории вероятностей, что позволит по новому взглянуть на проблему, понять связь машинного обучения со статистикой и лучше понимать формулы из научных статей. Также на описанном материале строятся более сложные темы, такие как вариационные автокодировщики (Kingma and Welling, 2013), нейробайесовские методы (Müller et al., 2021) и даже некоторые теории сознания (Friston et al., 2022).



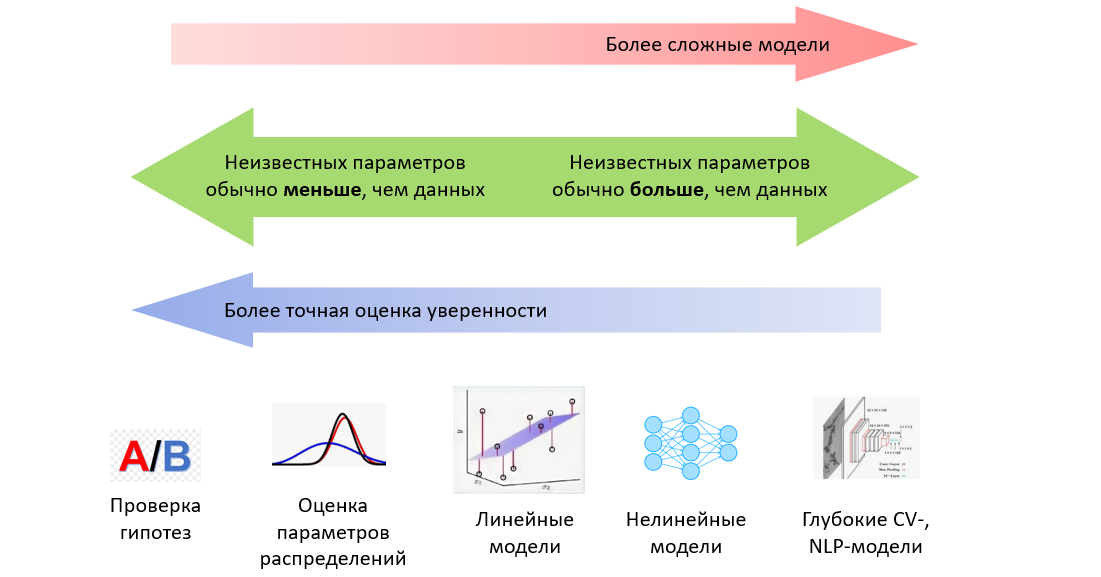

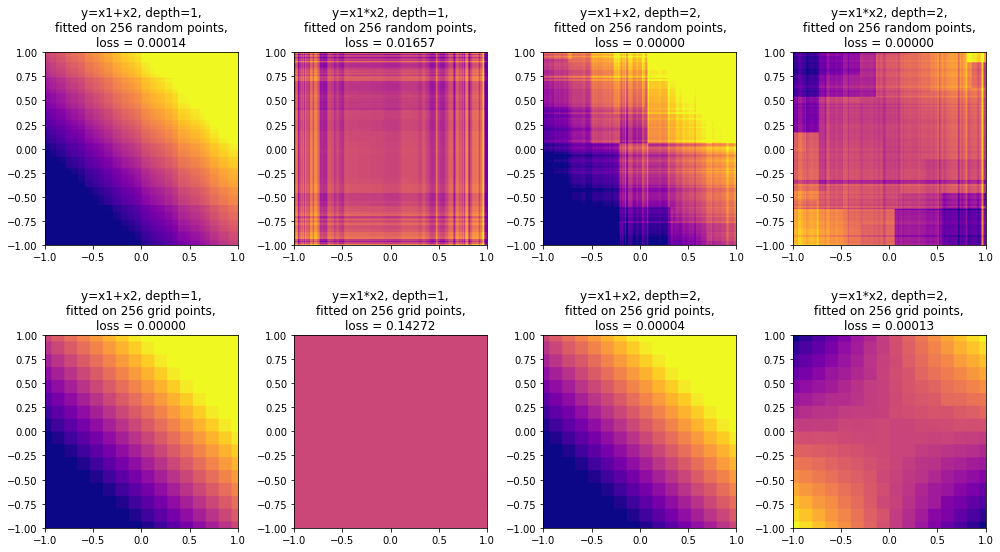
 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.