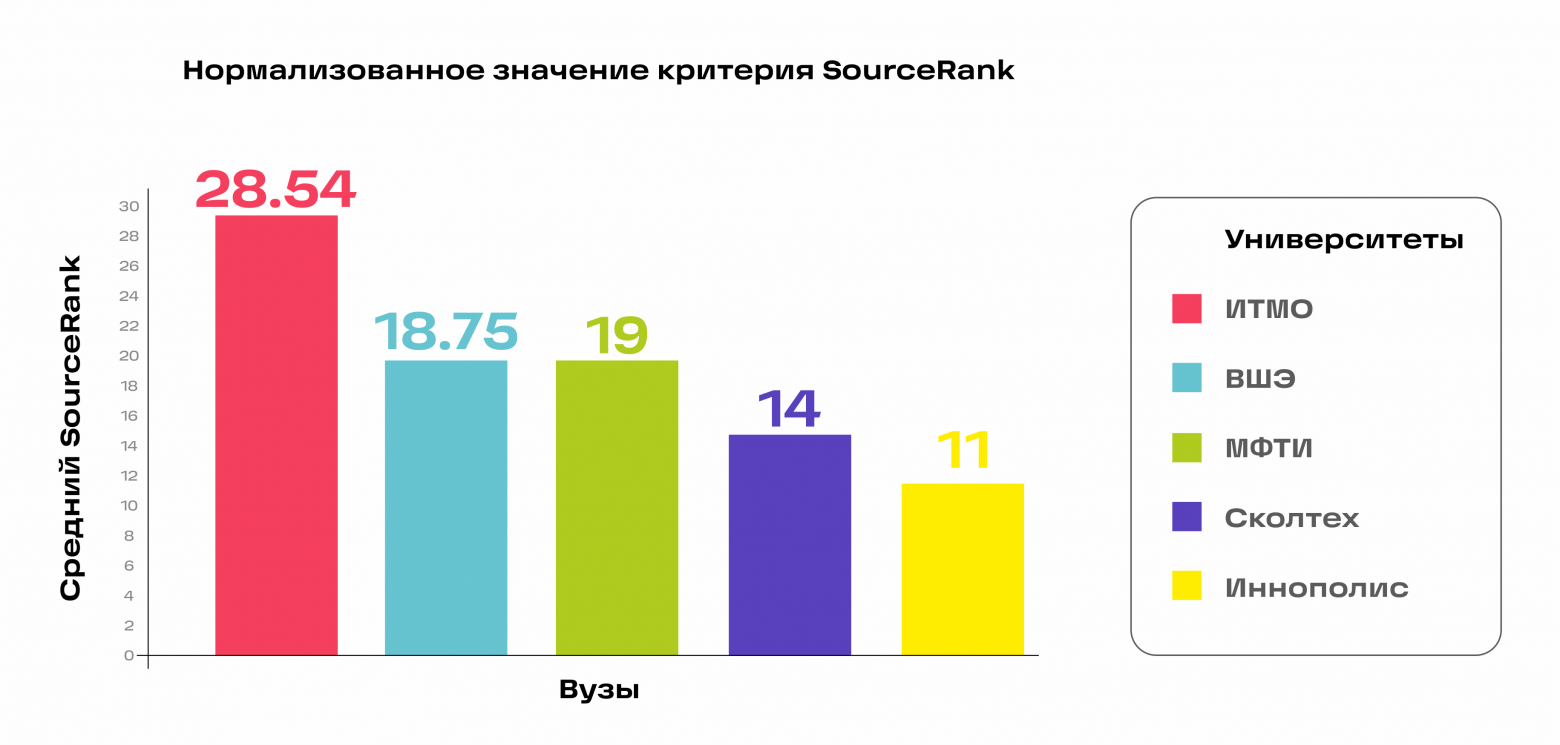
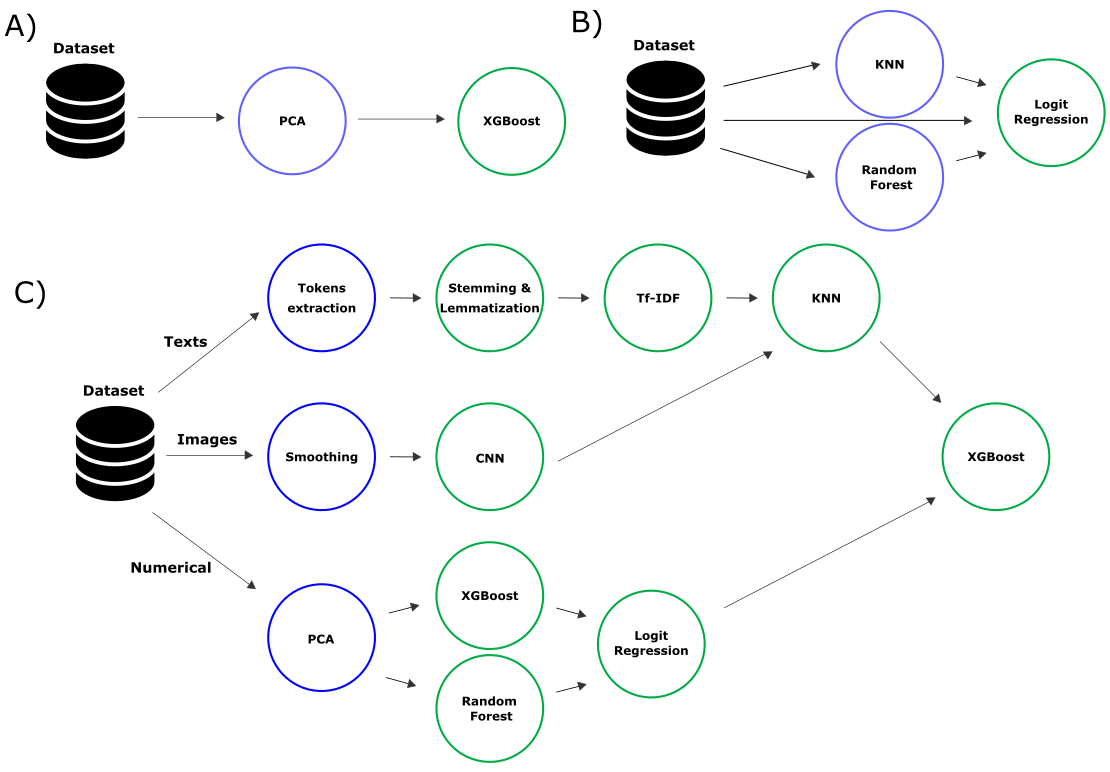
OSA: ИИ-помощник для разработчиков научного open source кода
Простой
7 мин

Привет, Хабр! Меня зовут Андрей Гетманов, я работаю ML-инженером в Исследовательском центре “Сильный ИИ в промышленности” в ИТМО, а кроме того являюсь энтузиастом open source. В этой статье хочу рассказать о нашей новой разработке ― ИИ-инструменте, который помогает репозиторию стать лучшей версией себя.
Разнообразных «улучшателей» много, но все они фокусируются преимущественно на качестве самого кода. Мы же смотрим шире ― на репозиторий в целом, насколько он понятен стороннему наблюдателю. Инструмент нацелен на наших коллег от науки ― например, биологов и химиков ― которые не обладают опытом коммерческой разработки и соответствующего оформления кода. Он поможет в несколько кликов сделать репозиторий более читаемым и воспроизводимым.