Как работают нейронные генераторы картинок (в формате ELI5)
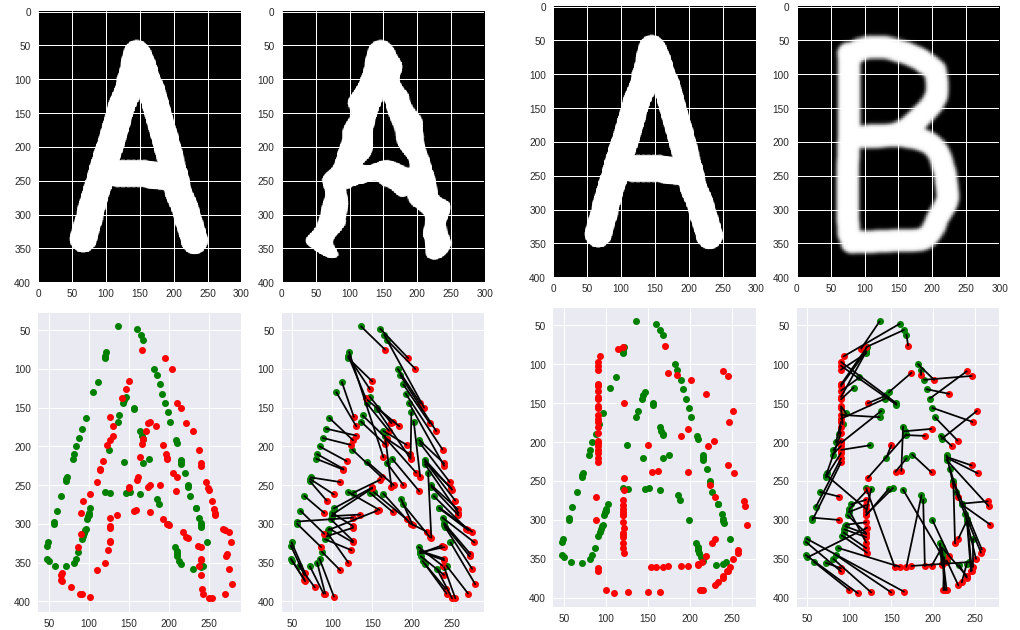
Хочу очень кратко рассказать, на каких принципах построены современные нейронные генераторы картинок, чтобы немножко разбавить флёр волшебства и магии, который окружает публичное обсуждение результатов их работы. Для того, чтобы понимать перспективы собственных профессий в мире, где похожие генераторы производят вообще все виды электронных артефактов (видео, тексты, программы, 3D-модели и так далее), – а этот мир нас, безусловно, ожидает в самом ближайшем будущем – надо понимать, что за генерацией стоит довольно простая математика на основе данных, которые ввели клавиатурой и мышкой и закачали в интернет люди.
(Должен сразу предупредить, что для специалистов текст окажется может оказаться смехотворным. Например, я полностью опускаю детали применения градиентного спуска при обучении, вообще не упоминаю слои в нейронках, уже не говоря о развёртках или там, рекурренции. Также я ловко обхожу вопрос довольно значительного различия между классической многослойной архитектурой и трансформерами. Мне кажется, что это детали реализации, хотя в них, конечно, и вложены мегалитры программистской крови. В общем, если вы работаете в этой области, то вам может быть не очень интересно, зато мне будет интересно прочитать ваши комментарии, чтобы улучшить статью и сделать её ещё более простой и понятной.)