
Облачные вычисления так популярны по нескольким причинам: они гибкие, относительно дешевые по сравнению с поддержкой внутренней инфраструктуры и позволяют отлично автоматизировать распределение ресурсов (и тут тоже экономия). Когда объем обрабатываемых данных растет из года в год, нельзя полагаться на вертикальную масштабируемость, покупая все более и более дорогие серверы. Данные должны быть распределены по нескольким более дешевым системам (кластерам), где могут надежно храниться, обрабатываться и возвращаться к пользователю при необходимости. Создание таких систем — непростая задача, но, к счастью, есть решения, которые отлично вписываются в облачную архитектуру. Я говорю об Apache Ignite.
Я собираюсь использовать AWS-облако для развертывания кластера Ignite. Для целей обучения нам хватит бесплатных машин базового уровня (AWS free tier). Я выбрал образ Ubuntu 18.04, но в целом это неважно. Перед развертыванием первых машин нам надо настроить группу безопасности (Security Group). В ней должны быть определены сетевые правила для портов, необходимых для узлов Ignite.
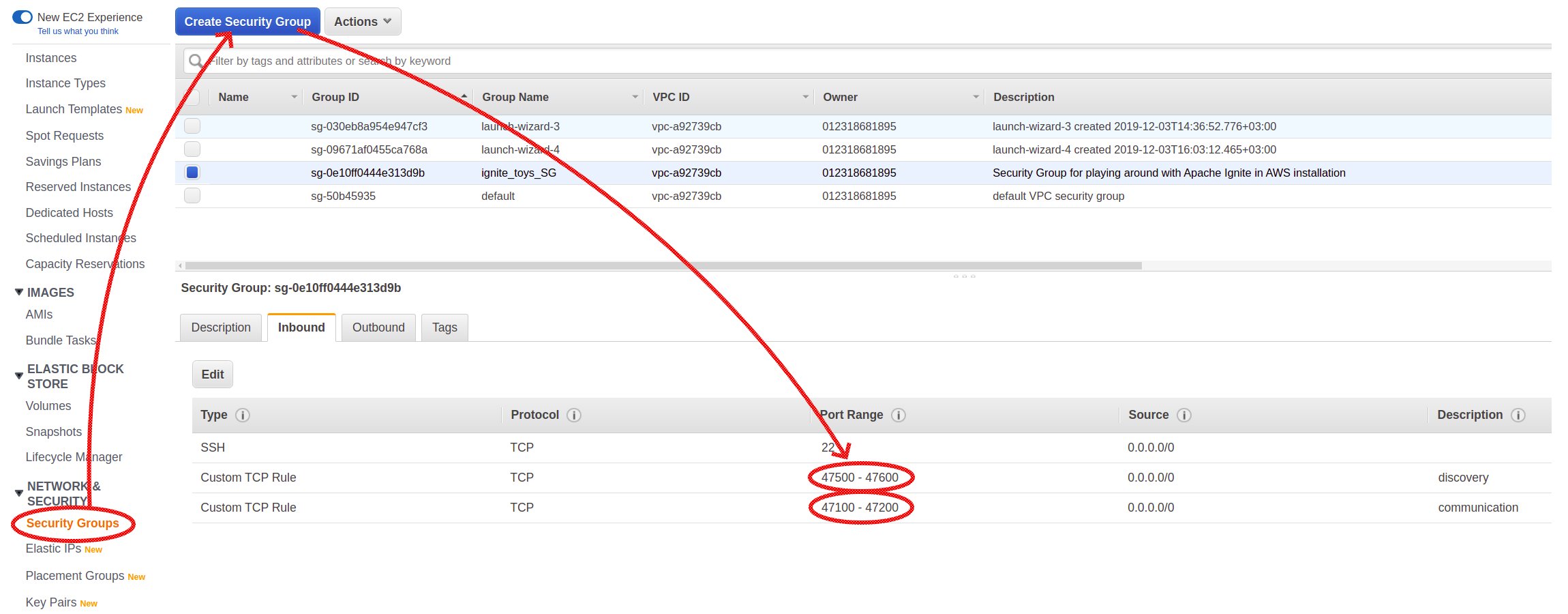
Рисунок 1 – Конфигурация Security Group
Подготовка среды
Я собираюсь использовать AWS-облако для развертывания кластера Ignite. Для целей обучения нам хватит бесплатных машин базового уровня (AWS free tier). Я выбрал образ Ubuntu 18.04, но в целом это неважно. Перед развертыванием первых машин нам надо настроить группу безопасности (Security Group). В ней должны быть определены сетевые правила для портов, необходимых для узлов Ignite.
Рисунок 1 – Конфигурация Security Group
