Иногда средствами файловой системы приходится хранить массу информации, большинство из которой статично. Когда файлов немного и они большие — это терпимо. Но если данные лежат в огромном количестве маленьких файликов, обращение к которым псевдослучайно, ситуация приближается к катастрофе.

Есть мнение, что специализированная read-only файловая система при прочих равных обладает преимуществами перед оной общего назначения т.к:
В этой статье мы будем разбираться, как можно организовать файловую систему, имея целевой функцией максимальную производительность при минимальных издержках.
В первую очередь, диск: все эксперименты проводятся на выделенном Seagate Barracuda ST31000340NS емкостью 1 Tb.
Операционная система — Windows XP.
Процессор: AMD Athlon II X3 445 3 Ггц.
Память: 4 Гб.
Прежде чем начинать содержательную работу, хочется понять, чего можно ждать от диска. Поэтому была произведена серия замеров случайных позиционирований и чтений с диска.
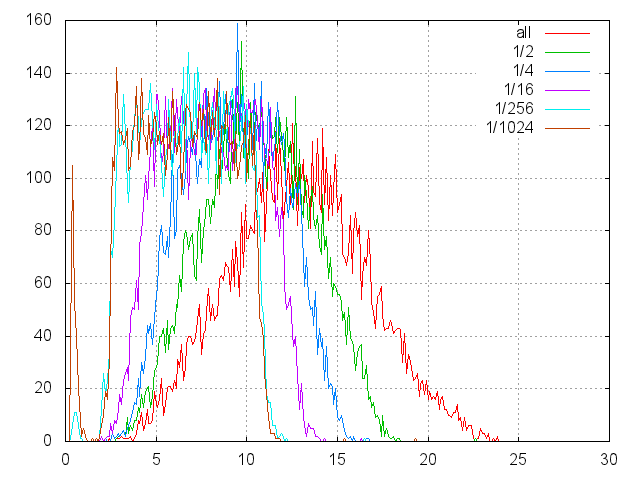
На представленном графике отображены гистограммы времен чтений с диска в произвольных позициях. По оси абсцисс отложена длительность позиционирования и чтения. По оси ординат — число попаданий в корзину шириной в 0.1 msec.
Обращения к диску производились штатным образом:
Производилось несколько серий замеров, по 10000 в каждой серии. Каждая серия отмечена своим цветом:
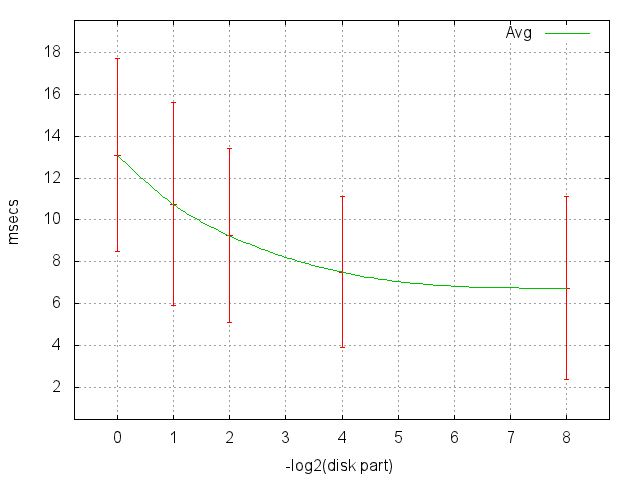
А здесь показаны мат. ожидания и ошибки из предыдущего графика, ось абсцисс в логарифмической шкале, например, 1/16 соответствует 4 (1/2**4).
Какие выводы можно сделать?
Попробуем создать файл размером с диск и получить временные характеристики работы с ним. Для этого создадим файл соизмеримого с файловой системой размера и будем читать его в случайных местах штатными _fseeki64/fread.
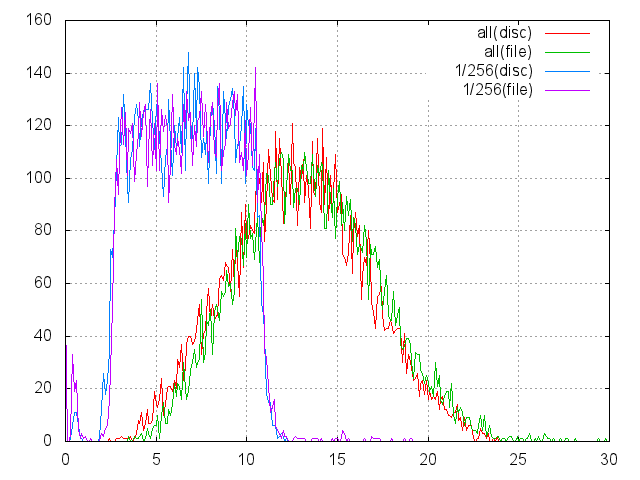
На графике аналогичные представленным ранее гистограммы. А две из них, помеченные как (disc), взяты из предыдущего графика. Парные же им гистограммы, помеченные как (file), получены на основании замеров файловых чтений. Что можно отметить:
То есть, надо дополнительно тратить по байту на каждый килобайт данных, на терабайт выходит гигабайт, а закэшировать гигабайт не так то просто. Впрочем, в ext4 такой проблемы, по-видимому, нет, или она замаскирована с помощью экстентов.
Вспомним уже про нашу тестовую задачу и попробуем решить ее в лоб — средствами файловой системы. Тут же выясняется, что:
Для начала рассмотрим гистограмму в миллисекундах:
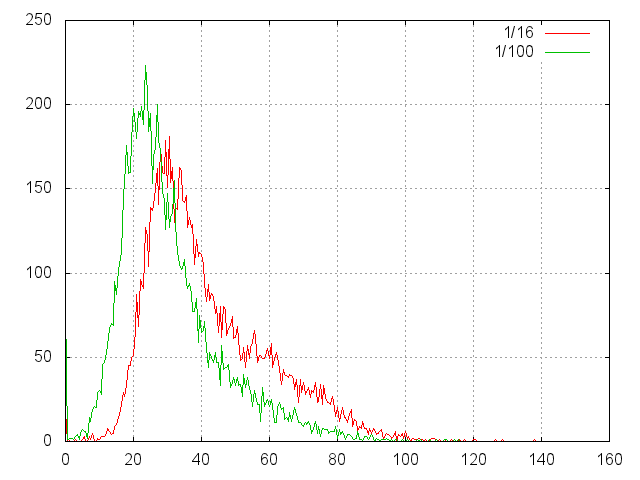
Итак, здесь представлена гистограмма времен чтений случайных файлов.
А теперь взглянем на то же в единицах условных seek’ов:
Построим прототип нашей read-only файловой системы:
Далее представлены гистограммы времен, полученные на этих данных:
Здесь самое время спросить — ну хорошо, мы разобрали очень специальный случай регулярно устроенной файловой системы (три уровня с фиксированными именами). А как быть с обычными данными, с обычными путями и названиями?
Ответ такой — принципиально ничего не изменится. По-прежнему будет один основной индекс. Но устроен он будет немного по-другому.
Выше идентификатором файла (ключом индекса) был закодированный путь к нему. Так и будет, ключ — строковый полный путь к файлу. Всё остальное в значении — размер, положение, владелец, группа, права…
Возможно, комбинаций (владелец, группа, права) будет не так много, и их выгодно будет хранить кодами Хаффмана, указывающими на глобальную таблицу комбинаций. Но это уже детали. Принципиально ситуация не отличается от той, что мы уже опробовали.
Чтобы найти файл, нужно указать его полный путь. Чтобы просмотреть содержимое директории, нужно указать путь директории и выбрать всё, что подходит по префиксу. Чтобы переместиться вверх по иерархии, откусываем кусок пути и опять ищем по префиксу.
Но ведь пути файлов занимают кучу места? Да, но файлы в одной директории имеют общий префикс, который можно хранить только один раз. Общий суффикс тоже частое явление. Чтобы понять объем данных, которые надо хранить, был проделан ряд экспериментов с путями файловой системы, которые показали, что они с помощью bzip2 (BWT+suffix sort + huffman), сжимаются в среднем в 10 раз. Таким образом, остается 5-6 байт на файл.
Суммарно можно рассчитывать на 10-16 байт на файл, или ~2 байта на килобайт данных, (если средний файл 8К). На терабайтный файл надо 2 гигабайта индекса, обычный 64-гигабайтный SSD-диск, следовательно, способен обслужить 32 терабайта данных.
Полные аналоги и предъявить трудно.
Например, SquashFS, с нулевым сжатием можно использовать аналогичным образом. Но эта система повторяет традиционную структуру, просто сжимает файлы, индексные дескрипторы и каталоги. Следовательно, ей присущи все те узкие места, которых мы старательно пытались избежать.
Примерным аналогом можно считать использование СУБД для хранения данных. В самом деле: храним содержимое файлов как BLOB’ы, а метаданные, как атрибуты таблицы. Просто и изящно. СУБД сама заботится о том, как поэффективнее расположить файлы в доступном ей дисковом пространстве. Сама создает и поддерживает все нужные индексы. Плюс приятный бонус — мы можем менять наши данные без ограничений.
Однако:
Очевидно, одноразовая файловая система никому не нужна. Время заполнения файловой системы размером в несколько терабайт может занимать десятки часов. За это время могут накопиться новые изменения, следовательно, должен существовать метод изменения данных, отличный от полного обновления. При этом желательно не останавливать работу. Что ж, тема эта достойна отдельного повествования и со временем мы собираемся рассказать об этом.
Итак, представлен прототип read-only файловой системы, который прост, гибок, решает тестовую задачу и при этом:

Есть мнение, что специализированная read-only файловая система при прочих равных обладает преимуществами перед оной общего назначения т.к:
- не обязательно управлять свободным пространством;
- не надо тратиться на журналирование;
- можно не заботиться о фрагментации и хранить файлы непрерывно;
- возможно собрать всю мета-информацию в одном месте и эффективно ее кэшировать;
- грех не сжимать мета-информацию, раз уж она оказалась в одной куче.
В этой статье мы будем разбираться, как можно организовать файловую систему, имея целевой функцией максимальную производительность при минимальных издержках.
Задача
- 100 млн небольших файлов (по ~8К).
- Трехуровневая иерархия — 100 директорий верхнего уровня, в каждой из которых 100 директорий среднего уровня, в каждой из которых 100 директорий нижнего уровня, в каждой из которых 100 файлов.
- Оптимизируем время построения и среднее время чтения случайного файла.
Железо
В первую очередь, диск: все эксперименты проводятся на выделенном Seagate Barracuda ST31000340NS емкостью 1 Tb.
Операционная система — Windows XP.
Процессор: AMD Athlon II X3 445 3 Ггц.
Память: 4 Гб.
Характеристики диска
Прежде чем начинать содержательную работу, хочется понять, чего можно ждать от диска. Поэтому была произведена серия замеров случайных позиционирований и чтений с диска.
На представленном графике отображены гистограммы времен чтений с диска в произвольных позициях. По оси абсцисс отложена длительность позиционирования и чтения. По оси ординат — число попаданий в корзину шириной в 0.1 msec.
Обращения к диску производились штатным образом:
- открытие через CreateFile("\\\\.\\PhysicalDrive1"...);
- позиционирование через SetFilePointer;
- и чтение посредством ReadFile.
Производилось несколько серий замеров, по 10000 в каждой серии. Каждая серия отмечена своим цветом:
- all — позиционирование идет по всему диску;
- ½ — только по его младшей половине и т.д.
А здесь показаны мат. ожидания и ошибки из предыдущего графика, ось абсцисс в логарифмической шкале, например, 1/16 соответствует 4 (1/2**4).
Какие выводы можно сделать?
- В худшем случае (случайный поиск) матожидание одного чтения составляет 13 msec. То есть больше 80 случайных чтений в секунду с этого диска сделать нельзя.
- На 1/256 мы впервые видим попадания в кэш.
- На 1/1024 в кэш начинает попадать ощутимое количество чтений ~1%.
- Больше ничем 1/256 от 1/1024 не отличается, прогон головок уже слишком мал, мы видим только их разгон и (в основном) успокоение.
- У нас есть возможность масштабирования, то есть допустимо проводить эксперименты на частично заполненном диске и довольно уверенно экстраполировать результаты.
NTFS
Попробуем создать файл размером с диск и получить временные характеристики работы с ним. Для этого создадим файл соизмеримого с файловой системой размера и будем читать его в случайных местах штатными _fseeki64/fread.
На графике аналогичные представленным ранее гистограммы. А две из них, помеченные как (disc), взяты из предыдущего графика. Парные же им гистограммы, помеченные как (file), получены на основании замеров файловых чтений. Что можно отметить:
- Времена близки.
- Хотя файл составляет 90% от файловой системы (9хЕ11 байт), чтение из него на полном размере в среднем почти на миллисекунду медленнее.
- Дисковый кэш для файла работает лучше, чем для диска.
- Появились хвосты в ~6 msec, если худшее время для полного чтения было около 24 msec, то теперь тянется почти до 30. Аналогично и для 1/256. Видимо, метаданные выпали из кэша и их приходится дополнительно читать.
- Но в целом чтение из большого файла работает очень похоже на работу с голым диском и в некоторых случаях может ее заменить или эмулировать. Это делает честь NTFS, т.к. например, структура ext2/ext3 требует для файла минимум 4-байтного числа на каждый 4-Kb блок данных:
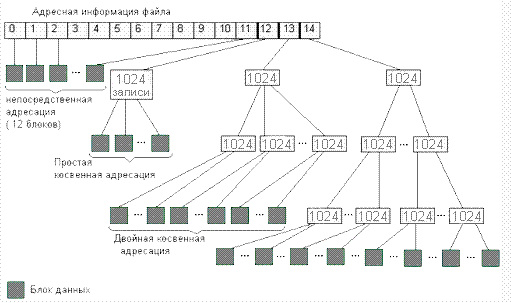
То есть, надо дополнительно тратить по байту на каждый килобайт данных, на терабайт выходит гигабайт, а закэшировать гигабайт не так то просто. Впрочем, в ext4 такой проблемы, по-видимому, нет, или она замаскирована с помощью экстентов.
NTFS с иерархией
Вспомним уже про нашу тестовую задачу и попробуем решить ее в лоб — средствами файловой системы. Тут же выясняется, что:
- Это занимает довольно много времени, на создание одной ветки из миллиона файлов уходит около получаса с тенденцией к постепенному замедлению по мере заполнения диска в соответствии с нашим первым графиком.
- Создание всех 100 млн. файлов, следовательно, заняло бы 50+ часов.
- Поэтому мы сделаем замеры на 7 млн файлов (~1/16) и отмасштабируемся к полной задаче.
- Попытка провести замеры в условиях, более приближенных к боевым, привела к тому, что на 12-м миллионе файлов рухнула NTFS с примерно такой же диагностикой, что получила главная героиня в фильме “Смерть ей к лицу”: — “Вообще-то, раздробленный шейный позвонок, это очень, ОЧЕНЬ плохой признак!”
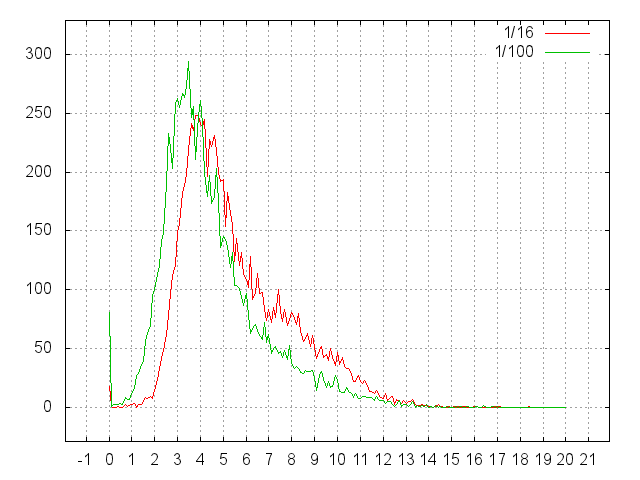
Для начала рассмотрим гистограмму в миллисекундах:
Итак, здесь представлена гистограмма времен чтений случайных файлов.
- Две серии -— 7 млн как 1/16 задачи и 1 млн для калибровки.
- В серии 10000 измерений, в корзине 0.5 msec.
- Общее время 1/16 теста — 7’13’’ то есть матожидание — 43 msec.
- Общее время 1/100 теста — 5’20’’ то есть матожидание — 32 msec.
А теперь взглянем на то же в единицах условных seek’ов:
- Что 1/16, что 1/100, слишком велики, чтобы их сколь-нибудь эффективно кэшировать. А файлы наши слишком малы для фрагментации.
- Поэтому 1 seek мы должны заплатить за чтение собственно данных. Все остальное — внутренние дела файловой системы.
- Максимумы приходятся на 3.5 (для 1/100) и 4 (для 1/16) seek’а.
- А матожидания вообще на 4...5.
- То есть, чтобы добраться до информации о том, где хранится файл, файловой системе (NTFS) приходится делать 3-4 чтения. А иногда и больше 10.
- В случае полной задачи, надо полагать, ситуация не улучшится.
Прототип
Построим прототип нашей read-only файловой системы:
- Состоит он из двух файлов — данных и метаданных.
- Файл данных — просто записанные подряд все файлы.
- Файл метаданных — В-дерево с ключом — идентификатор файла. Значение — адрес в файле данных и его размер.
- Под идентификатором файла понимается закодированный путь к нему. Вспомним, что наши данные расположены в трехуровневой системе директорий, где каждый уровень кодируется числом от 0 до 100, аналогично и сам файл. Вся эта структура упаковывается в целое число.
- Дерево записано в виде 4К страниц, применяется примитивное сжатие.
- Для того, чтобы избежать фрагментации, указанные файлы приходится создавать в разных файловых системах.
- Просто дописывать данные в конец файла (данных) оказывается неэффективно. Чем больше файл, тем дороже обходится файловой системе (NTFS, WinXP) его расширение. Чтобы избежать этой нелинейности, приходится предварительно создать файл нужного размера (900 Гб).
- Занимает это предварительное создание больше 2 часов, всё это время уходит на заполнение этого файла нулями, видимо, из соображений безопасности.
- Столько же времени занимает и заполнение этого файла данными.
- Построение индекса занимает около 2 минут.
- Напомним, всего 100 млн файлов, каждый размером около 8К.
- Файл индекса занимает 521 Мб. Или ~5 байт на файл. Или ~5 бит на килобайт данных.
- Был также опробован вариант индекса с более сложным сжатием (кодами Хаффмана). Занимает этот индекс 325 Мб. Или 3 бита на килобайт данных.
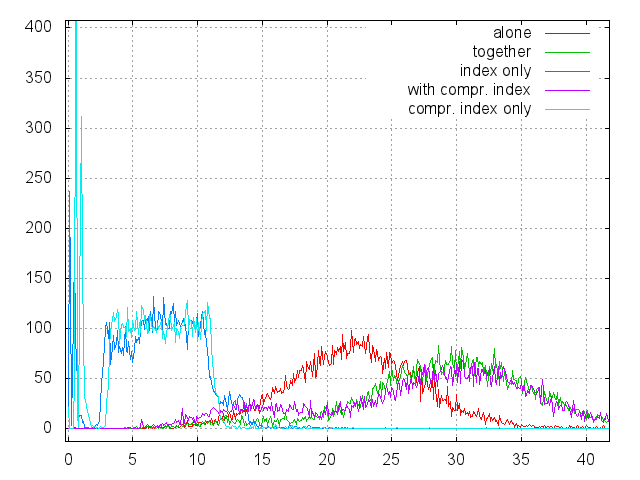
Далее представлены гистограммы времен, полученные на этих данных:
- «alone» — под этой меткой идет файл данных, расположенный отдельно от индексного файла, на другом физическом диске;
- «ogether» — и файл данных и индекс расположены в пределах одной файловой системы на одном физическом диске;
- «index only» — осуществляется только поиск информации о файле в индексе без чтения собственно данных;
- «with compr. index» — то же, что и «together», но со сжатым индексом;
- «compr. index only» — то же, что и «index only», но со сжатым индексом;
- всего 10000 чтений, шаг гистограммы 0.1 msec.
Выводы:
- Качество сжатия индекса почти не влияет на скорость работы. На разжатие страниц тратится процессорное время, но зато лучше работает кэш страниц.
- Чтение индекса выглядит как одно чтение из файла соответствующего размера (см. первый график). Так как 512 Мб — это 1/2000 диска, среднее время seek’а должно быть около 6.5 msec, плюс надбавка за то, что мы читаем из файла, а не напрямую с диска. Судя по всему, это оно и есть. Дерево индекса трех-уровневое, верхние два уровня очень быстро оказываются в кэше, а нижний уровень страниц кэшировать бессмысленно. В результате, любой поиск в дереве вырождается в единственное чтение листовой страницы.
- Если файл данных и индексный файл расположены на одном физическом диске, общее время поиска равно двум случайным seek’ам на полное расстояние. Один на чтение данных и один на переход к индексному файлу, который расположен либо в самом начале, либо в самом конце диска.
- Если же файлы разнесены по разным устройствам, мы имеем один полный seek на чтение данных и один короткий на поиск в индексе. Учитывая, что индексный файл относительно невелик, напрашивается естественное решение — если нам нужно хранилище в несколько (десятков) терабайт, надо готовить выделенный диск под индекс (SSD) и несколько дисков под данные. Это может быть оформлено как JBOD и внешне выглядеть как обычная файловая система.
- Эта схема обладает важной особенностью — гарантированным временем ответа, чего трудно добиться в обычных файловых системах, например, для использования в системах реального времени.
Здесь самое время спросить — ну хорошо, мы разобрали очень специальный случай регулярно устроенной файловой системы (три уровня с фиксированными именами). А как быть с обычными данными, с обычными путями и названиями?
Ответ такой — принципиально ничего не изменится. По-прежнему будет один основной индекс. Но устроен он будет немного по-другому.
Выше идентификатором файла (ключом индекса) был закодированный путь к нему. Так и будет, ключ — строковый полный путь к файлу. Всё остальное в значении — размер, положение, владелец, группа, права…
Возможно, комбинаций (владелец, группа, права) будет не так много, и их выгодно будет хранить кодами Хаффмана, указывающими на глобальную таблицу комбинаций. Но это уже детали. Принципиально ситуация не отличается от той, что мы уже опробовали.
Чтобы найти файл, нужно указать его полный путь. Чтобы просмотреть содержимое директории, нужно указать путь директории и выбрать всё, что подходит по префиксу. Чтобы переместиться вверх по иерархии, откусываем кусок пути и опять ищем по префиксу.
Но ведь пути файлов занимают кучу места? Да, но файлы в одной директории имеют общий префикс, который можно хранить только один раз. Общий суффикс тоже частое явление. Чтобы понять объем данных, которые надо хранить, был проделан ряд экспериментов с путями файловой системы, которые показали, что они с помощью bzip2 (BWT+suffix sort + huffman), сжимаются в среднем в 10 раз. Таким образом, остается 5-6 байт на файл.
Суммарно можно рассчитывать на 10-16 байт на файл, или ~2 байта на килобайт данных, (если средний файл 8К). На терабайтный файл надо 2 гигабайта индекса, обычный 64-гигабайтный SSD-диск, следовательно, способен обслужить 32 терабайта данных.
Аналоги
Полные аналоги и предъявить трудно.
Например, SquashFS, с нулевым сжатием можно использовать аналогичным образом. Но эта система повторяет традиционную структуру, просто сжимает файлы, индексные дескрипторы и каталоги. Следовательно, ей присущи все те узкие места, которых мы старательно пытались избежать.
Примерным аналогом можно считать использование СУБД для хранения данных. В самом деле: храним содержимое файлов как BLOB’ы, а метаданные, как атрибуты таблицы. Просто и изящно. СУБД сама заботится о том, как поэффективнее расположить файлы в доступном ей дисковом пространстве. Сама создает и поддерживает все нужные индексы. Плюс приятный бонус — мы можем менять наши данные без ограничений.
Однако:
- В конечном счете, СУБД всё равно обращается к диску, напрямую или через файловую систему. А это таит опасность, стоит недоглядеть и — бац! время работы замедлилось в разы. Но, допустим, у нас идеальная СУБД, с которой этого не произойдёт.
- СУБД не сможет сжать префиксы столь же эффективно просто в силу того, что не рассчитана на read-only режим.
- То же самое можно сказать и про метаданные — в СУБД они будут занимать гораздо больше места.
- Больше места — больше чтений с диска — медленней работа.
- Использование хэш-кодов от пути файла не решает проблемы т.к. соответствие пути хэш-коду всё равно надо где-то хранить просто для того, чтобы обеспечить возможность просмотра содержимого директории. Выльется всё в то, что придется воспроизвести структуру файловой системы средствами СУБД.
- Файлы размером больше страницы будут принудительно разбиты СУБД на части, и произвольный доступ к ним будет осуществляться в лучшем случае за логарифмическое от размера файла время.
- Если мы можем просто разместить все метаданные на выделенном SSD диске, в случае СУБД сделать это будет намного сложнее.
- Про гарантированное время отклика можно забыть.
Транзакционность
Очевидно, одноразовая файловая система никому не нужна. Время заполнения файловой системы размером в несколько терабайт может занимать десятки часов. За это время могут накопиться новые изменения, следовательно, должен существовать метод изменения данных, отличный от полного обновления. При этом желательно не останавливать работу. Что ж, тема эта достойна отдельного повествования и со временем мы собираемся рассказать об этом.
Итого
Итак, представлен прототип read-only файловой системы, который прост, гибок, решает тестовую задачу и при этом:
- демонстрирует максимально возможную на отведенном для него железе производительность;
- его архитектура не накладывает объективных ограничений на объем данных;
- дает понять, что следует делать, чтобы получить файловую систему общего назначения, а не заточенную под конкретную задачу поделку
- дает понять, в какую сторону стоит двигаться для того, чтобы сделать нашу файловую систему инкрементально изменяемой.
