Если в Google ввести запрос «a b тестирование», то по теме выпадает довольно много статей, но в них больше теории и ориентированы они на менеджеров, а в качестве инструментов предлагаются готовые клиентские реализации, вроде Google Analytics. Также есть статья про очень простую серверную реализацию (в реалиях авторов, я думаю, этого вполне достаточно).
Сегодня я расскажу о том, как это происходит у нас, в Badoo, при огромном количестве пользователей по всему миру.
У нас был целый «зоопарк» инструментов для сплит-тестирования во главе с A/B фрэймворком, часть из которых разрабатывалась для других целей. Помимо прочих недостатков, все эти инструменты использовали примерно один и тот же способ для разделения пользователей на варианты — это хеширование ID пользователя плюс «соль». Такой подход нас не удовлетворял, и было принято решение разработать новую версию, в которой можно было бы избежать недостатков старых версий.
Основные требования к новой версии инструмента сплит-тестирования были следующие:
Исходя из этих требований и учитывая рекомендации команды BI, в новом инструменте появилось следующее:
Новую версию A/B фрэймворка назвали UserSplit Tool или просто UserSplit. Разработка шла инкрементальным путем. Вначале был сделан минимально возможный рабочий функционал, для того чтобы инструментом можно было пользоваться сразу. А дальше добавлялись новые возможности и исправлялись баги.
Теперь предлагаю более детально рассмотреть наш UserSplit по состоянию на текущий момент и разобраться, зачем же нужно было это делать.
Страница выглядит следующим образом:

Здесь в основном поля информационного характера, кроме Key, Jira issue, Test managers и кнопка Create Hipchat room.
Поле Key является осмысленной строкой, которая однозначно идентифицирует тест. В программном API разработчиков используется именно Key, а не ID теста, т.к. это более читабельно, а также позволяет не завязываться на ID теста.
На этой странице можно указать диапазон дат теста (когда он активен), условия попадания в тест (например, Country is Russia), а также варианты. Для каждого варианта указывается название и процент входящих в него пользователей. Название используется разработчиками (вместо ID варианта) для того, чтобы понять, в какой вариант теста попал пользователь; оно является уникальным для теста. Только один из вариантов может быть контрольным, хотя сам контрольный вариант может и отсутствовать.

Все, что есть на этой странице — диапазон дат, условия теста, варианты — представляет собой вышеупомянутую группу настроек теста. Таких групп настроек может быть несколько, но непосредственно привязанная к тесту группа в один момент времени может быть только одна — это текущая группа настроек. При каждом изменении группы настроек теста, на самом деле, она не изменяется, а создается новая. При этом она не сразу привязывается к тесту, а только после того, как будет готова. Для подготовки группы настроек необходимо присвоить случайные сплит-группы для вариантов, а также рассчитать оценку теста и пересечения с другими тестами.
По-хорошему, у любого теста должно быть минимум 2 варианта для сравнения. При этом в большинстве тестов используется контрольный вариант, когда мы сравниваем то, что было, с тем, что стало. Но если запускается новая «фича», и у нее есть 2 варианта дизайна, то контрольного варианта не будет, т.к. раньше ее вообще не было, поэтому сравнивать не с чем. Сейчас контрольный вариант удалить нельзя, но если он не нужен, то для него можно поставить 0%. В будущем интерфейс планируется немного изменить, но пока он такой.
Важно, чтобы для контрольного варианта не было никакой дополнительной логики (кроме логирования хита), так чтобы он не отличался от того случая, когда тест неактивен. Иначе получится, что это уже не контрольный вариант, а один из тестируемых.
Исходя из требований, использование хеширования ID пользователя плюс соль не подходит для деления пользователей, т.к. не позволяет быстро оценить попадание пользователей в варианты (база на лету будет довольно медленно считать хеш с солью, а для каждого теста пересчитывать хеши для всех пользователей с разной солью заведомо довольно затратная операция). Также хеширование не позволяет добиться максимально возможного «непересечения» пользователей между тестами.
Мы решили использовать вместо этого сплит-группы (split_group). Идея в следующем: выдавать новым пользователям (при регистрации) и уже существующим сплит-группу в диапазоне от 1 до 2400 случайным образом.
Число 2400 удобно тем, что его легко делить на кусочки с шагом 5%. В каждые 5% попадает 120 групп. А затем эти 120 групп делятся без остатка на 2, 3, 4, 5, 6, 8, 10, 12 вариантов. 7, 9 и 11 вариантов — крайне редкий случай, у нас не встречался, но если такое будет, то можно добавить 2-й контрольный вариант и не учитывать его в статистике.
Для гостевых (не авторизованных) пользователей сплит-группа в вебе кладется в «куку» и вполне может не совпадать со сплит-группой пользователя после логина. Это сделано специально, чтобы в одном и том же браузере гостевые пользователи видели один и тот же вариант сайта (например, форму авторизации или регистрации), независимо от того, какая сплит-группа была у последнего залогиненного пользователя. Но сейчас информация о гостевых пользователях не выгружается в BI, поэтому при проведении таких тестов статистика не полная. Сейчас мы в процессе доработки этой части.
При добавлении вариантов для теста им случайным образом (согласно процентовке) присваиваются сплит-группы. Т.е. если варианту отведено 10% пользователей, то ему будут соответствовать 240 случайных сплит-групп. Стоит отметить, что в процессе разработки возможность разделить пользователей на равные группы мы не реализовали, а сделали указание процентов для каждого варианта, при этом если у одного варианта меняется процент, то он меняется и у всех остальных. Возможно, позже мы сделаем так, чтобы можно было указывать количество процентов для теста в целом, а сплит-группы, соответствующие этому проценту, будут делиться поровну между вариантами.
Для оценки мы используем БД Exasol (про нее недавно была статья моего коллеги wildraid), поэтому информация о тестах и группах настроек (в том числе вариантах тестов и их сплит-группах) выгружаются в именно в нее.
На самом деле сплит-группы выдаются не совсем случайным образом. Из БД извлекаются все тесты, которые пересекаются с текущим по датам (но не занимают 100% сплит-групп). Потом для этих тестов, на основе условий фильтров (без учета сплит-групп), через БД Exasol происходит проверка, есть ли реальное пересечение между ними и текущим тестом. Из реально пересекающихся тестов достаются занятые сплит-группы. Соответственно, при выделении сплит-групп текущему тесту в первую очередь происходит выбор свободных сплит-групп, а уже потом — занятых, если свободных не хватает. Далее выделенные группы распределяются по вариантам случайным образом. Это позволяет добиться минимально возможного пересечения между тестами с сохранением однородности аудитории между вариантами, например:
В первой строке указаны возможные номера сплит-групп (для наглядности я взял только 10). Во 2-й, 3-й и 5-й строках мы видим варианты тестов и соответствующие им сплит-группы. В 4-й строке таблицы плюсами отмечены свободные сплит-группы, а минусами занятые. Допустим, у нас есть тест «Тест», который пересекается с тестами «Тест1» и «Тест2». Допустим, нам нужно 4 сплит-группы для теста «Тест». Первым делом мы выбираем свободные сплит-группы 4 и 7, потом — случайным образом из занятых, например, 5 и 9. После этого перемешиваем и распределяем по вариантам. Собственно, результат на последней строке таблицы — мы добились максимального «непересечения» с другими тестами.
После того как сплит-группы выданы вариантам, происходит подсчет пересечений с другими тестами (какой процент пользователей с каким тестом пересекается).
Далее оцениваем сам тест: сколько пользователей в какой вариант входит, с точностью до пользователя. С помощью этих цифр можно понять, стоит ли проводить тест на этих условиях, что бы достичь статистически значимого результата, и не могут ли пересекающиеся тесты дать искажение результатов.
Вот так выглядит результат подсчета оценки теста и его пересечений с другими тестами:

*Все цифры вымышленные, любая связь с реальностью является случайной.
Красным выделяются тесты одного и того же типа. Так сделано для наглядности, потому что, например, мобильные тесты вряд ли повлияют на тесты в вебе.
Стоит отметить, что первая реализация подсчета пересечений была не очень быстрой, и если вначале подсчет выполнялся за секунды, то с ростом количества одновременно запущенных тестов он стал доходить до получаса. Было проведено несколько оптимизаций, сейчас подсчет пересечений идет не более полутора минут, а полное выполнение подсчета пересечений и оценки — до двух минут.
Интерфейс UserSplit позволяет довольно гибко указывать условия теста. Можно использовать операторы AND и OR, можно брать условия в скобки. Допустим, мы хотим, чтобы тест был доступен всем тестовым пользователям, а также новым пользователям из России. Тогда можно создать такой фильтр:

Все возможные фильтры, доступные в интерфейсе, представляют собой легкие для проверки условия, т.е. все данные для этих фильтров, как правило, у нас уже есть в памяти. Если нет, то их легко можно загрузить.
Также есть environment-фильтры, которые показывают, как и откуда зашел пользователь. Например, это user agent, страна, в которой пользователь сейчас находится (не путать со страной, которая указана у пользователя в профиле) и платформа пользователя (Web, iOS, Android и т.д.). Для гостевых пользователей доступны только environment-фильтры.
Мы хотим проводить много тестов одновременно, но если запускать тесты сразу во всех странах, то они будут пересекаться и, возможно, влиять друг на друга. Чтобы этого избежать, тесты можно запускать в разных странах. В этом случае может вылезти другая проблема — тест может неплохо показать себя в одной стране и плохо в остальных. Чтобы этого не случилось, условия теста можно изменить, добавив туда еще страны. Таким образом мы можем получить более достоверные результаты и принять правильное решение. Как говорилось ранее, чтобы такие изменения тестов не вводили в заблуждение при изучении отчетов теста, в отчете отображаются данные для нескольких версий теста.
Для удобства разработки, тестирования и поиска причин проблем были сделаны QA tools.
Flow тестов выглядит следующим образом:
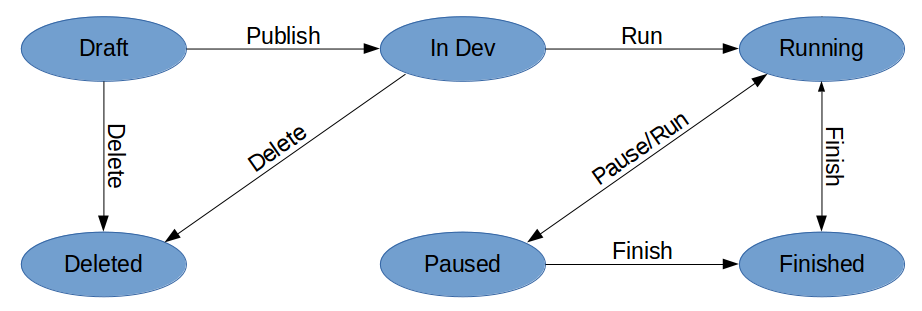
Когда тест только создан, он находится в статусе Draft. В этом состоянии продакт-менеджер может «поиграть» с ним (посмотреть его оценку и пересечения с другими тестами), при этом сам тест никто (кроме него и суперпользователей) не видит.
После того как тест готов, продакт-менеджер должен опубликовать его (действие Publish) для разработчиков. Теперь тест переходит в статус In Dev. В этом статусе диапазон дат теста игнорируется и он доступен только тестовым пользователям. Мы отслеживаем хиты из production, и как только они начинают приходить, тестовые менеджеры получают уведомление о том, что тест готов и его можно запускать.
Для запуска теста на реальных пользователей его нужно перевести в статус Running. Для временного отключения — поставить на паузу (статус Paused).
По окончании теста (Finish) можно взять результирующий вариант и решить, будет ли он применен везде (worldwide) или только согласно условиям теста.
Также можно сделать Reject, если есть желание оставить старый вариант. При этом Reject — это не то же самое, что выбрать контрольный вариант, т.к. его может и не быть, и ни один из выбираемых вариантов не устроил.

В дальнейшем мы планируем автоматически ставить задачу на «выпиливание» теста из кода после его окончания.
Довольно накладно брать информацию о тестах из базы или любого другого хранилища, чтобы просто проверить, какие варианты для каких тестов активны для пользователя. Поэтому мы решили хранить конфиг тестов на каждом сервере локально. В качестве формата конфига был выбран PHP-файл с массивом (отдельный файл на каждый тест). Такой выбор позволяет затрачивать минимум времени на обработку конфига за счет использования кеша байт-кода. Тесты раскладываются одновременно на все сервера (development, test и production), чтобы не случилось так, что в окружении разработки и на «боевых» машинах что-то работает по-разному. Для раскладки мы используем те же инструменты, что и для остальных конфигов.
Т.к. серверов много, раскладка проходит не мгновенно (около пары минут), но для решаемой задачи это не критично. Тем более, что на окружение разработки раскладка проходит довольно быстро и в первую очередь. Т.е. если нужно что-то подправить, то изменения можно довольно быстро увидеть.
Тесты, которые нужно разложить, легко заметить — они выделены красным в общем списке.
В рамках сплит-тестирования важно собирать статистику. Ключевые KPI-показатели уже отправляются в BI с привязкой к пользователю, поэтому в большинстве сплит-тестов не нужно отправлять какую-то дополнительную статистику. Достаточно отметить, что пользователь попал в тот или иной вариант теста. Этот действие у нас представляет собой отправку хита. Здесь главное не спутать с тем, что пользователь сделал какое-то действие, которое нужно измерить в рамках теста. Например, у нас есть зеленая кнопка и мы хотим проверить, будут ли на нее чаще кликать, если изменить ее цвет на красный. Получается, что отправлять хит нужно в момент отображения зеленой (контрольный вариант) или красной (тестируемый вариант) кнопки. При этом предполагается, что клики по кнопке уже отправляются в BI, и если это не так, то такую отправку нужно обязательно добавить, иначе мы не сможем оценить результат эксперимента.
Для разработчиков старый A/B фрэймворк предоставлял следующие методы:
Получается, что реализация всей логики A/B теста ложилась на плечи разработчика. А логика включает в себя условия попадания (в каких странах и т.д.) и какой процент пользователей должен попадать в тот или иной вариант. При этом разработчик мог спокойно допустить ошибку (по невнимательности или не понимая, что такое однородность аудитории).
Например, нам нужно выбрать всех пользователей из России и поделить пополам.
Допустим, разработчик написал следующий код:
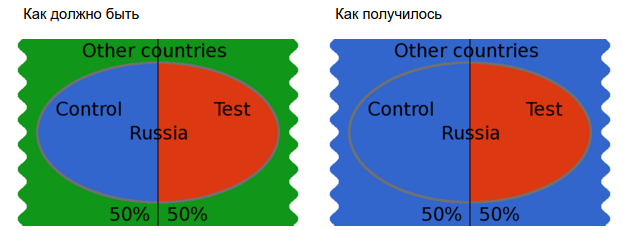
Т.е. в контрольный вариант попадет гораздо больше пользователей, включая пользователей из другого сегмента (других стран), что может привести к неоднозначным результатам (пользователи из других стран могут вести себя иначе).
В новой версии программного интерфейса для единообразия было выделено специальное пространство имен \UserSplit\Tests для классов с константами. Если у теста нет какой-то дополнительной логики, то можно использовать класс \UserSplit\Tests\Common.
Проверка попадания в вариант выглядит следующим образом:
При вызове метода \UserSplit\SplitTests\Checker::getActiveVariant() хит логируется автоматически. Получается что в случае, если дополнительной логики нет, то неравномерно залогировать хиты, как в старом варианте, не получится.
Чтобы отключить автоматическое логирование хитов, нужно передать 4-й параметр false и не забыть залогировать хит позже:
Это может понадобиться, например, при отправке писем. В этом случае попадание пользователя в тест должно происходить только тогда, когда он прочитал письмо (как правило, есть способы это проверить).
Если же есть какая-то дополнительная логика при определении попадания пользователя в вариант теста, то нужно создать свой класс. Выглядит это примерно следующим образом:
Тут нужно обратить внимание на важные моменты, которые описаны в комментариях. Учитывая, что тут легко ошибиться, нужно использовать такой подход только в исключительных случаях. Их два:
Тесты, в которых не нужна какая-то дополнительная серверная логика, можно проводить полностью на клиенте (мобильное приложение или JS в браузере). Например, цвет кнопки можно тестировать полностью на клиенте, тем более, что сейчас шаблоны у нас рисуются в JS, а не на сервере. Для этого была доработана реализация мобильного API и взаимодействие c JS (на самом деле, теперь там используется то же API). Работало оно следующим образом: клиент присылал список поддерживаемых тестов (в виде чисел — ID тестов в формате строки), а сервер в ответ присылал список тестов с активными вариантами (в том же виде). Т.к. для новых тестов стали использовать ключи тестов и названия вариантов, а отличить число от строки проще простого, то для новых тестов просто стали оперировать ими.
Также есть тесты смешанного типа (я их называю клиент-серверные), где и на сервере, и на клиенте нужно знать, какой вариант активен. В этом случае, помимо попадания в тест, нужно еще проверять, поддерживает ли клиент этот тест.
Здесь появилась проблема с тем, что мы не можем просто так добавить проверку дополнительных условий в клиентских и клиент-серверных тестах. Такую проверку можно автоматизировать, если сделать такой интерфейс:
После проверки условий делаем дополнительную проверку: если у теста есть PHP-класс (класс, находящийся в пространстве имен \UserSplit\Tests и имеющий такое же название, как и ключ теста, но в CamelCase) и он имплементирует этот интерфейс, то вызываем у него метод checkAdditionalConditions(). Если результат false — значит, пользователь не попал в тест. Реализовать эту идею мы пока еще не успели, но собираемся.
В команде биллинга был разработан инструмент «пользовательские группы». Изначально он был сделан для того, чтобы управлять доступностью фич для пользователей.
Применялся он следующим образом: например, у нас есть сезонные подарки на Рождество, но их нет смысла отображать в мусульманских странах, т.к. там его не отмечают. В таком случае мы можем создать пользовательскую группу, в которой будет прописан список стран, где отмечают Рождество, и проверять пользователя на вхождение в нее перед отображением рождественских подарков. Соответственно, эту пользовательскую группу можно менять (например, добавить страны) через веб-интерфейс, не привлекая разработчика. Использовать сплит-тесты в данном случае было бы неправильно, т.к. нам не нужно сравнивать варианты, нам нужно только включить фичу для определенного круга пользователей.
Но, помимо прямого назначения, этот инструмент использовался для сплит-тестирования. Например, тесты как сущность там отсутствовали и создавались в виде нескольких пользовательских групп, представляющих собой варианты.
В целом инструменты для сплит-тестирования и пользовательские группы довольно похожи, а держать два похожих инструмента не очень хорошо. Поэтому мы решили сделать на базе UserSplit пользовательские группы, а пользовательские группы команды биллинга перенести в UserSplit.
Интерфейс (как программный, так и веб) выглядит почти так же, как и интерфейс сплит-тестов, но он упрощен за счет отсутствия вариантов. Вот так выглядит программный интерфейс:
Иногда возникает необходимость пройти по всем пользователям, соответствующим каким-то условиям, чтобы совершить какое-то действие. Для сплит-тестов и пользовательских групп был сделан UserSplit Iterator. Он позволяет сформировать правильный SQL-запрос в БД, включающий все условия теста или группы пользователей, и получить только тех пользователей, которые попадают в тест или пользовательскую группу.
Помимо уже озвученных проблем и планов у нас есть еще пара идей:
В одном из проведенных тестов лексем (текстов), где переименовали одну из платных фич, мы получили неплохой прирост прибыли. Но такие изменения требуют немало ресурсов разработчиков. Т.к. у нас есть своя система переводов лексем, мы решили встроить в нее сплит-тестирование, чтобы привлекать разработчика для этого не было необходимости. Сейчас эта фича находится в разработке у команды бэк-офиса.
На странице теста планируется выводить график, какое количество пользователей в какой вариант попадает, чтобы можно было увидеть, есть ли трафик по тесту и насколько он равномерный между вариантами.
В итоге получился довольно мощный инструмент, который еще можно развивать. Он успешно используется уже полгода. На данный момент проведено около 40 тестов и около 30 запущено. Проверка попадания пользователя в тесты в среднем на запрос составляет около 0,5 мс.
Если у вас есть вопросы по этой теме — не стесняйтесь задавать их в комментариях.
И спасибо всем, кто участвовал в разработке UserSplit!
Ринат Ахмадеев, PHP-разработчик.
Сегодня я расскажу о том, как это происходит у нас, в Badoo, при огромном количестве пользователей по всему миру.
У нас был целый «зоопарк» инструментов для сплит-тестирования во главе с A/B фрэймворком, часть из которых разрабатывалась для других целей. Помимо прочих недостатков, все эти инструменты использовали примерно один и тот же способ для разделения пользователей на варианты — это хеширование ID пользователя плюс «соль». Такой подход нас не удовлетворял, и было принято решение разработать новую версию, в которой можно было бы избежать недостатков старых версий.
Основные требования к новой версии инструмента сплит-тестирования были следующие:
- у нас большой проект и большая команда, поэтому нужно проводить много тестов одновременно;
- тесты, идущие одновременно, должны минимально пересекаться по пользователям, если же пересечения с другими тестами есть, то информация об этом должна отображаться менеджеру;
- при создании теста хотелось бы понимать, какое количество человек попадет в каждый вариант теста;
- чтобы при анализе не было вопросов, почему KPI-показатели по тесту вдруг скакнули, изменения условий тестов должны отображаться в отчете;
- программное API для разработчиков должно быть простым и снижать вероятность ошибки;
- нужна возможность менять условия теста без привлечения разработчика;
- для QA должен быть удобный инструмент, который позволяет указать вариант для пользователя независимо от того, попадает ли пользователь под условия теста или нет;
- проверка пользователя на попадание в тест должна проходить достаточно быстро, чтобы это не влияло на время отдачи страницы;
- тест не должен быть бесконечным, потому что это со временем сильно усложнит оценку пересечений тестов, а также вносит энтропию в код.
Исходя из этих требований и учитывая рекомендации команды BI, в новом инструменте появилось следующее:
- возможность указывать условия попадания в тест в виде фильтра;
- возможность указывать даты начала и окончания теста в обязательных полях;
- возможность указывать варианты для теста, а также проценты вариантов;
- при сохранении подсчитывается оценка попадания пользователей в варианты теста, а также пересечения с другими тестами (в процентном соотношении);
- при каждом изменении теста создается новая, так сказать, группа настроек теста, которая включает в себя фильтры, даты начала и окончания теста, а также варианты, что позволяет видеть в отчетах BI изменения тестов и понимать причину скачков в графиках;
- для оценки количества пользователей на лету. Все пользователи были поделены на сплит-группы, а распределение пользователей по вариантам свелось к распределению сплит-групп по вариантам.
Новую версию A/B фрэймворка назвали UserSplit Tool или просто UserSplit. Разработка шла инкрементальным путем. Вначале был сделан минимально возможный рабочий функционал, для того чтобы инструментом можно было пользоваться сразу. А дальше добавлялись новые возможности и исправлялись баги.
Теперь предлагаю более детально рассмотреть наш UserSplit по состоянию на текущий момент и разобраться, зачем же нужно было это делать.
Основные свойства теста
Страница выглядит следующим образом:

Здесь в основном поля информационного характера, кроме Key, Jira issue, Test managers и кнопка Create Hipchat room.
Поле Key является осмысленной строкой, которая однозначно идентифицирует тест. В программном API разработчиков используется именно Key, а не ID теста, т.к. это более читабельно, а также позволяет не завязываться на ID теста.
Описание остальных полей
В поле Jira issue мы указываем номер задачи Jira. Он используется для того, чтобы было проще найти задачу, в рамках которой делался тест. Также в эту задачу будут поступать автоматические комментарии с уведомлениями.
В поле Test managers указываем тех людей, которые имеют доступ к редактированию теста; они же будут получать уведомления в Hipchat. Как правило, сюда попадают автор теста и наблюдатели (watchers) задачи Jira.
Кнопка Create Hipchat room создает комнату в мессенджере и добавляет туда всех тестовых менеджеров. В эту комнату тоже будут поступать уведомления, кроме того, здесь можно обсудить детали теста. Также в комнату можно добавить других пользователей прямо из интерфейса UserSplit:
Сейчас их два:
В будущем планируется сделать уведомление о скором окончании теста и, возможно, еще какие-то уведомления.
В поле Test managers указываем тех людей, которые имеют доступ к редактированию теста; они же будут получать уведомления в Hipchat. Как правило, сюда попадают автор теста и наблюдатели (watchers) задачи Jira.
Кнопка Create Hipchat room создает комнату в мессенджере и добавляет туда всех тестовых менеджеров. В эту комнату тоже будут поступать уведомления, кроме того, здесь можно обсудить детали теста. Также в комнату можно добавить других пользователей прямо из интерфейса UserSplit:
Уведомления
Сейчас их два:
- уведомление о скором начале теста (приближается дата старта);
- уведомление о том, что код для теста выложен «на бой» и тест можно запускать.
В будущем планируется сделать уведомление о скором окончании теста и, возможно, еще какие-то уведомления.
Условия теста и варианты
На этой странице можно указать диапазон дат теста (когда он активен), условия попадания в тест (например, Country is Russia), а также варианты. Для каждого варианта указывается название и процент входящих в него пользователей. Название используется разработчиками (вместо ID варианта) для того, чтобы понять, в какой вариант теста попал пользователь; оно является уникальным для теста. Только один из вариантов может быть контрольным, хотя сам контрольный вариант может и отсутствовать.
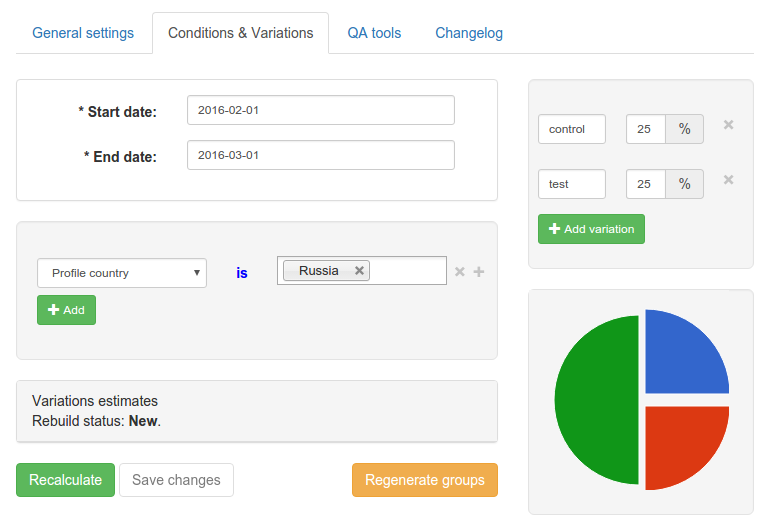
Все, что есть на этой странице — диапазон дат, условия теста, варианты — представляет собой вышеупомянутую группу настроек теста. Таких групп настроек может быть несколько, но непосредственно привязанная к тесту группа в один момент времени может быть только одна — это текущая группа настроек. При каждом изменении группы настроек теста, на самом деле, она не изменяется, а создается новая. При этом она не сразу привязывается к тесту, а только после того, как будет готова. Для подготовки группы настроек необходимо присвоить случайные сплит-группы для вариантов, а также рассчитать оценку теста и пересечения с другими тестами.
Варианты
По-хорошему, у любого теста должно быть минимум 2 варианта для сравнения. При этом в большинстве тестов используется контрольный вариант, когда мы сравниваем то, что было, с тем, что стало. Но если запускается новая «фича», и у нее есть 2 варианта дизайна, то контрольного варианта не будет, т.к. раньше ее вообще не было, поэтому сравнивать не с чем. Сейчас контрольный вариант удалить нельзя, но если он не нужен, то для него можно поставить 0%. В будущем интерфейс планируется немного изменить, но пока он такой.
Важно, чтобы для контрольного варианта не было никакой дополнительной логики (кроме логирования хита), так чтобы он не отличался от того случая, когда тест неактивен. Иначе получится, что это уже не контрольный вариант, а один из тестируемых.
Сплит-группы пользователей
Исходя из требований, использование хеширования ID пользователя плюс соль не подходит для деления пользователей, т.к. не позволяет быстро оценить попадание пользователей в варианты (база на лету будет довольно медленно считать хеш с солью, а для каждого теста пересчитывать хеши для всех пользователей с разной солью заведомо довольно затратная операция). Также хеширование не позволяет добиться максимально возможного «непересечения» пользователей между тестами.
Мы решили использовать вместо этого сплит-группы (split_group). Идея в следующем: выдавать новым пользователям (при регистрации) и уже существующим сплит-группу в диапазоне от 1 до 2400 случайным образом.
Число 2400 удобно тем, что его легко делить на кусочки с шагом 5%. В каждые 5% попадает 120 групп. А затем эти 120 групп делятся без остатка на 2, 3, 4, 5, 6, 8, 10, 12 вариантов. 7, 9 и 11 вариантов — крайне редкий случай, у нас не встречался, но если такое будет, то можно добавить 2-й контрольный вариант и не учитывать его в статистике.
Для гостевых (не авторизованных) пользователей сплит-группа в вебе кладется в «куку» и вполне может не совпадать со сплит-группой пользователя после логина. Это сделано специально, чтобы в одном и том же браузере гостевые пользователи видели один и тот же вариант сайта (например, форму авторизации или регистрации), независимо от того, какая сплит-группа была у последнего залогиненного пользователя. Но сейчас информация о гостевых пользователях не выгружается в BI, поэтому при проведении таких тестов статистика не полная. Сейчас мы в процессе доработки этой части.
При добавлении вариантов для теста им случайным образом (согласно процентовке) присваиваются сплит-группы. Т.е. если варианту отведено 10% пользователей, то ему будут соответствовать 240 случайных сплит-групп. Стоит отметить, что в процессе разработки возможность разделить пользователей на равные группы мы не реализовали, а сделали указание процентов для каждого варианта, при этом если у одного варианта меняется процент, то он меняется и у всех остальных. Возможно, позже мы сделаем так, чтобы можно было указывать количество процентов для теста в целом, а сплит-группы, соответствующие этому проценту, будут делиться поровну между вариантами.
Оценка теста
Для оценки мы используем БД Exasol (про нее недавно была статья моего коллеги wildraid), поэтому информация о тестах и группах настроек (в том числе вариантах тестов и их сплит-группах) выгружаются в именно в нее.
На самом деле сплит-группы выдаются не совсем случайным образом. Из БД извлекаются все тесты, которые пересекаются с текущим по датам (но не занимают 100% сплит-групп). Потом для этих тестов, на основе условий фильтров (без учета сплит-групп), через БД Exasol происходит проверка, есть ли реальное пересечение между ними и текущим тестом. Из реально пересекающихся тестов достаются занятые сплит-группы. Соответственно, при выделении сплит-групп текущему тесту в первую очередь происходит выбор свободных сплит-групп, а уже потом — занятых, если свободных не хватает. Далее выделенные группы распределяются по вариантам случайным образом. Это позволяет добиться минимально возможного пересечения между тестами с сохранением однородности аудитории между вариантами, например:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Тест1 | A | B | B | A | ||||||
| Тест2 | A | B | A | A | B | B | ||||
| - | - | - | + | - | - | + | - | - | - | |
| Тест | A | B | B | A |
После того как сплит-группы выданы вариантам, происходит подсчет пересечений с другими тестами (какой процент пользователей с каким тестом пересекается).
Далее оцениваем сам тест: сколько пользователей в какой вариант входит, с точностью до пользователя. С помощью этих цифр можно понять, стоит ли проводить тест на этих условиях, что бы достичь статистически значимого результата, и не могут ли пересекающиеся тесты дать искажение результатов.
Вот так выглядит результат подсчета оценки теста и его пересечений с другими тестами:
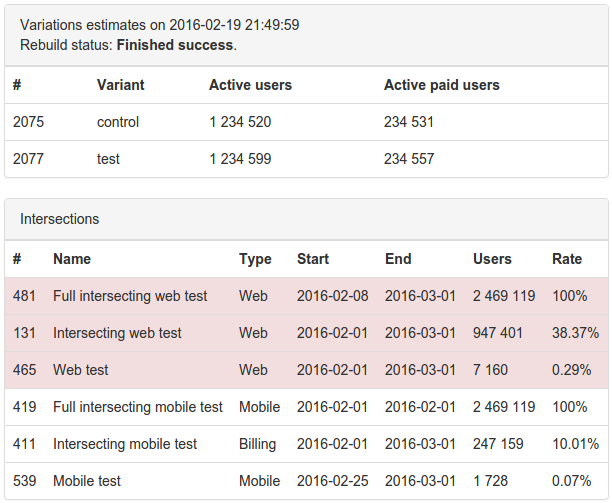
*Все цифры вымышленные, любая связь с реальностью является случайной.
Красным выделяются тесты одного и того же типа. Так сделано для наглядности, потому что, например, мобильные тесты вряд ли повлияют на тесты в вебе.
Стоит отметить, что первая реализация подсчета пересечений была не очень быстрой, и если вначале подсчет выполнялся за секунды, то с ростом количества одновременно запущенных тестов он стал доходить до получаса. Было проведено несколько оптимизаций, сейчас подсчет пересечений идет не более полутора минут, а полное выполнение подсчета пересечений и оценки — до двух минут.
Условия теста
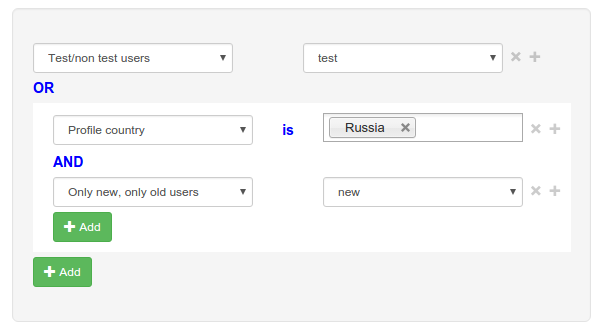
Интерфейс UserSplit позволяет довольно гибко указывать условия теста. Можно использовать операторы AND и OR, можно брать условия в скобки. Допустим, мы хотим, чтобы тест был доступен всем тестовым пользователям, а также новым пользователям из России. Тогда можно создать такой фильтр:
Внутреннее устройство и обработка условий
Условия, показанные на скриншоте, преобразуются в формат JSON:
Для оптимизации мы обрабатываем не все условия. Например:
(A AND B) OR C
Если A равно false, то условие B обрабатываться не будет и обработка сразу же перейдет к условию C.
Если A и B равны true, то условие C обрабатываться не будет и итоговое значение будет true, т.е. пользователь попадает под условия фильтра.
[
{
"filter":"is_test_user",
"operator":"eq",
"value":"Yes"
},
"OR",
[
{
"filter":"country_id",
"operator":"in",
"value":["50"]
},
"AND",
{
"filter":"is_new_user",
"operator":"eq",
"value":"1"
}
]
]
Для оптимизации мы обрабатываем не все условия. Например:
(A AND B) OR C
Если A равно false, то условие B обрабатываться не будет и обработка сразу же перейдет к условию C.
Если A и B равны true, то условие C обрабатываться не будет и итоговое значение будет true, т.е. пользователь попадает под условия фильтра.
Все возможные фильтры, доступные в интерфейсе, представляют собой легкие для проверки условия, т.е. все данные для этих фильтров, как правило, у нас уже есть в памяти. Если нет, то их легко можно загрузить.
Также есть environment-фильтры, которые показывают, как и откуда зашел пользователь. Например, это user agent, страна, в которой пользователь сейчас находится (не путать со страной, которая указана у пользователя в профиле) и платформа пользователя (Web, iOS, Android и т.д.). Для гостевых пользователей доступны только environment-фильтры.
Изменение условий теста
Мы хотим проводить много тестов одновременно, но если запускать тесты сразу во всех странах, то они будут пересекаться и, возможно, влиять друг на друга. Чтобы этого избежать, тесты можно запускать в разных странах. В этом случае может вылезти другая проблема — тест может неплохо показать себя в одной стране и плохо в остальных. Чтобы этого не случилось, условия теста можно изменить, добавив туда еще страны. Таким образом мы можем получить более достоверные результаты и принять правильное решение. Как говорилось ранее, чтобы такие изменения тестов не вводили в заблуждение при изучении отчетов теста, в отчете отображаются данные для нескольких версий теста.
QA tools
Для удобства разработки, тестирования и поиска причин проблем были сделаны QA tools.
Описание QA tools
Порой сделать так, чтобы пользователь попадал под условия теста, достаточно сложно. Еще сложнее может быть со сплит-группой, особенно если для теста используется небольшой процент пользователей. И если разработчик может сделать, скажем, «хак» в коде, чтобы увидеть нужный вариант теста, то QA-специалисту делать такое просто противопоказано. Поэтому и для разработчиков, для и QA-специалистов были созданы так называемые QA tools.
QA tools состоят из двух инструментов:
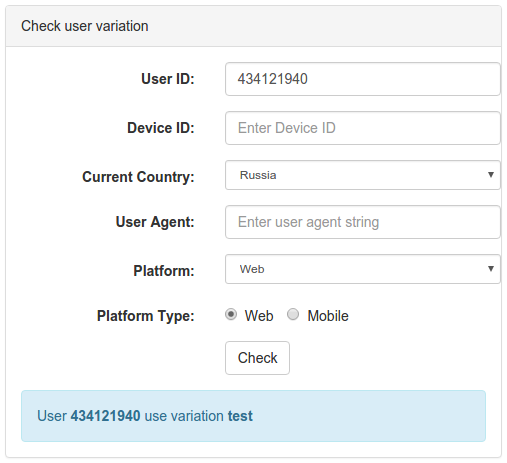
Добавить пользователя в вариант можно по ID пользователя или по device_id (удобно для гостевых пользователей, использующих мобильные приложения). При этом можно указать, для какого ID пользователя это нужно сделать — из production окружения или окружения разработки (галочка devel).
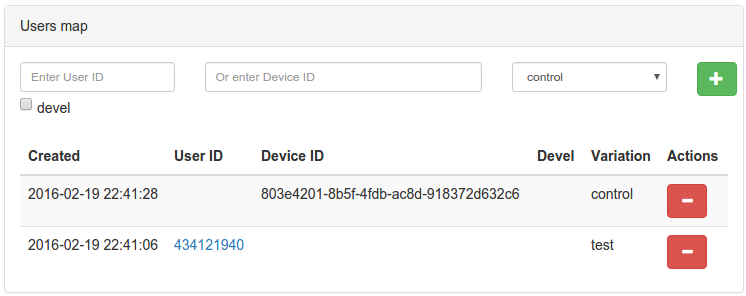
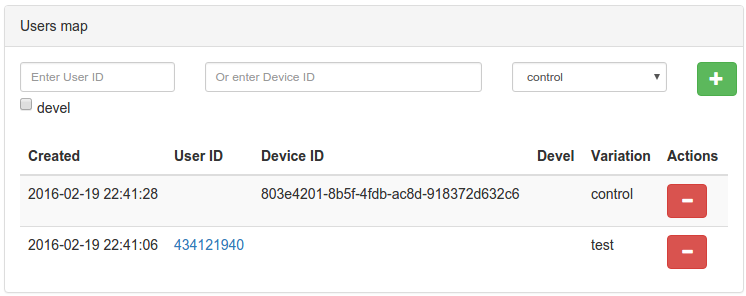
При проверке пользователя на попадание в вариант теста необходимо указать ID пользователя или device_id, а также значения environment-фильтров при необходимости. При нажатии на кнопку Check мы увидим, в какой вариант теста попал пользователь, или причину, по которой он не попал (не подошла сплит-группа, не прошел по условиям и т.д.).
При проведении автоматизированных тестов, как правило, берутся случайные пользователи из пула. Получается, что разные пользователи попадают в разные варианты сплит-тестов, из-за чего автотесты ломаются. Поэтому для автоматизированных тестов было сделано специальное API, которое позволяет указать, какой пользователь в какой вариант попадает. Но проблему это решает не полностью, т.к. постоянно появляются новые сплит-тесты, которые делают нестабильными автотесты. Мы планируем сделать метод в API, который будет отключать все тесты для пользователя. Соответственно, если нужно будет проверить какой-то вариант сплит-теста, то для такого пользователя можно будет включить какой-то один сплит-тест после отключения всех всех остальных.
QA tools состоят из двух инструментов:
- добавление пользователя в вариант;
- проверка, в какой вариант попадает пользователь.
Добавление пользователя в вариант
Добавить пользователя в вариант можно по ID пользователя или по device_id (удобно для гостевых пользователей, использующих мобильные приложения). При этом можно указать, для какого ID пользователя это нужно сделать — из production окружения или окружения разработки (галочка devel).
Проверка попадания пользователя в вариант
При проверке пользователя на попадание в вариант теста необходимо указать ID пользователя или device_id, а также значения environment-фильтров при необходимости. При нажатии на кнопку Check мы увидим, в какой вариант теста попал пользователь, или причину, по которой он не попал (не подошла сплит-группа, не прошел по условиям и т.д.).
Автоматизированное тестирование
При проведении автоматизированных тестов, как правило, берутся случайные пользователи из пула. Получается, что разные пользователи попадают в разные варианты сплит-тестов, из-за чего автотесты ломаются. Поэтому для автоматизированных тестов было сделано специальное API, которое позволяет указать, какой пользователь в какой вариант попадает. Но проблему это решает не полностью, т.к. постоянно появляются новые сплит-тесты, которые делают нестабильными автотесты. Мы планируем сделать метод в API, который будет отключать все тесты для пользователя. Соответственно, если нужно будет проверить какой-то вариант сплит-теста, то для такого пользователя можно будет включить какой-то один сплит-тест после отключения всех всех остальных.
Лог изменений теста
Лог изменений теста
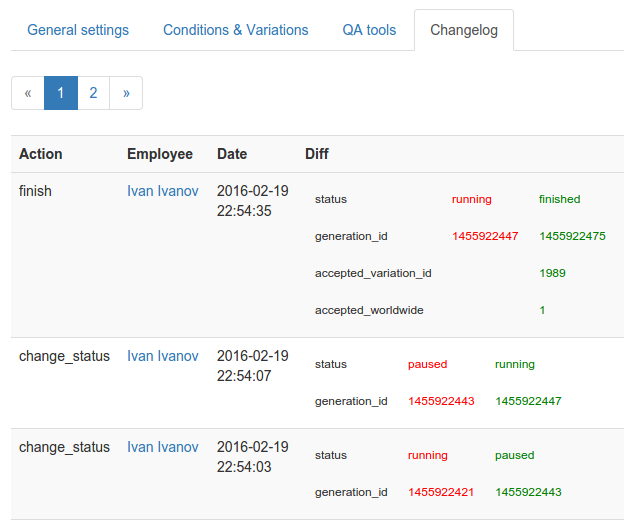
Чтобы упростить поиск причин проблем, все изменения теста записываются в БД и выводятся на странице Changelog:

Flow тестов
Flow тестов выглядит следующим образом:
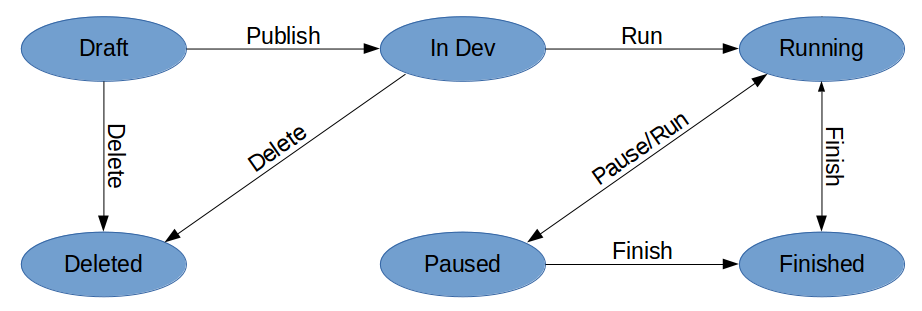
Когда тест только создан, он находится в статусе Draft. В этом состоянии продакт-менеджер может «поиграть» с ним (посмотреть его оценку и пересечения с другими тестами), при этом сам тест никто (кроме него и суперпользователей) не видит.
После того как тест готов, продакт-менеджер должен опубликовать его (действие Publish) для разработчиков. Теперь тест переходит в статус In Dev. В этом статусе диапазон дат теста игнорируется и он доступен только тестовым пользователям. Мы отслеживаем хиты из production, и как только они начинают приходить, тестовые менеджеры получают уведомление о том, что тест готов и его можно запускать.
Для запуска теста на реальных пользователей его нужно перевести в статус Running. Для временного отключения — поставить на паузу (статус Paused).
Окончание тестов
По окончании теста (Finish) можно взять результирующий вариант и решить, будет ли он применен везде (worldwide) или только согласно условиям теста.
Также можно сделать Reject, если есть желание оставить старый вариант. При этом Reject — это не то же самое, что выбрать контрольный вариант, т.к. его может и не быть, и ни один из выбираемых вариантов не устроил.
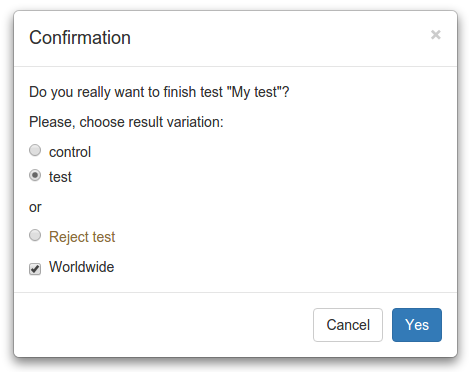
В дальнейшем мы планируем автоматически ставить задачу на «выпиливание» теста из кода после его окончания.
Раскладка тестов
Довольно накладно брать информацию о тестах из базы или любого другого хранилища, чтобы просто проверить, какие варианты для каких тестов активны для пользователя. Поэтому мы решили хранить конфиг тестов на каждом сервере локально. В качестве формата конфига был выбран PHP-файл с массивом (отдельный файл на каждый тест). Такой выбор позволяет затрачивать минимум времени на обработку конфига за счет использования кеша байт-кода. Тесты раскладываются одновременно на все сервера (development, test и production), чтобы не случилось так, что в окружении разработки и на «боевых» машинах что-то работает по-разному. Для раскладки мы используем те же инструменты, что и для остальных конфигов.
Т.к. серверов много, раскладка проходит не мгновенно (около пары минут), но для решаемой задачи это не критично. Тем более, что на окружение разработки раскладка проходит довольно быстро и в первую очередь. Т.е. если нужно что-то подправить, то изменения можно довольно быстро увидеть.
Тесты, которые нужно разложить, легко заметить — они выделены красным в общем списке.
Статистика
В рамках сплит-тестирования важно собирать статистику. Ключевые KPI-показатели уже отправляются в BI с привязкой к пользователю, поэтому в большинстве сплит-тестов не нужно отправлять какую-то дополнительную статистику. Достаточно отметить, что пользователь попал в тот или иной вариант теста. Этот действие у нас представляет собой отправку хита. Здесь главное не спутать с тем, что пользователь сделал какое-то действие, которое нужно измерить в рамках теста. Например, у нас есть зеленая кнопка и мы хотим проверить, будут ли на нее чаще кликать, если изменить ее цвет на красный. Получается, что отправлять хит нужно в момент отображения зеленой (контрольный вариант) или красной (тестируемый вариант) кнопки. При этом предполагается, что клики по кнопке уже отправляются в BI, и если это не так, то такую отправку нужно обязательно добавить, иначе мы не сможем оценить результат эксперимента.
Программный интерфейс
Для разработчиков старый A/B фрэймворк предоставлял следующие методы:
// определение, попадает ли пользователь в диапазон процентов
\ABFramework\Utils::matchPercentage(
$user_id, // ID пользователя, от которого (плюс соль) брался хеш
$from_percent,
$to_percent,
$salt // вышеупомянутая соль, нужна для того, чтобы в одном и том же диапазоне для разных тестов были не одни и те же пользователи
);
// логирование хита, т.е. информация о том, что пользователь попал в вариант эксперимента
\ABFrameworkAPI::addHit($user_id, $test_id, $experiment_id, $variation_id);
Получается, что реализация всей логики A/B теста ложилась на плечи разработчика. А логика включает в себя условия попадания (в каких странах и т.д.) и какой процент пользователей должен попадать в тот или иной вариант. При этом разработчик мог спокойно допустить ошибку (по невнимательности или не понимая, что такое однородность аудитории).
Например, нам нужно выбрать всех пользователей из России и поделить пополам.
Допустим, разработчик написал следующий код:
if ($country_id == \Country::RUSSIA && \ABFramework\Utils::matchPercentage($user_id, 0, 50, 'salt')) {
$variation_id = static::VARIATION_ID_TEST;
} else {
$variation_id = static::VARIATION_ID_CONTROL;
}
\ABFrameworkAPI::addHit($user_id, static::TEST_ID, static::EXPERIMENT_ID, $variation_id);
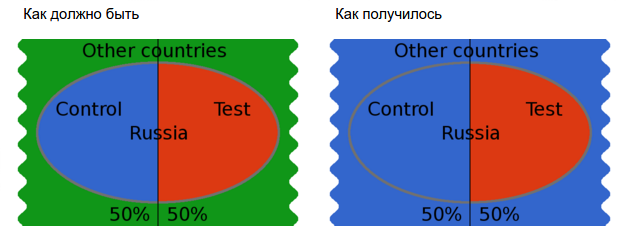
Т.е. в контрольный вариант попадет гораздо больше пользователей, включая пользователей из другого сегмента (других стран), что может привести к неоднозначным результатам (пользователи из других стран могут вести себя иначе).
В новой версии программного интерфейса для единообразия было выделено специальное пространство имен \UserSplit\Tests для классов с константами. Если у теста нет какой-то дополнительной логики, то можно использовать класс \UserSplit\Tests\Common.
Проверка попадания в вариант выглядит следующим образом:
$Environment = \UserSplit\CheckerEnvironment::byGlobals(); // нужно для environment-фильтров, см. выше
$Checker = \UserSplit\SplitTests\Checker::getInstance(); // DI мы еще не внедрили и не факт, что внедрим, т.к. команда большая и сложно прийти к единому решению
$variant = $Checker->getActiveVariant(\UserSplit\Tests\Common::MY_SPLIT_TEST_KEY, $User, $Environment);
if ($variant === \UserSplit\Tests\Common::MY_SPLIT_TEST_VARIANT_TEST) {
// новое поведение
} else {
// старое поведение
}
При вызове метода \UserSplit\SplitTests\Checker::getActiveVariant() хит логируется автоматически. Получается что в случае, если дополнительной логики нет, то неравномерно залогировать хиты, как в старом варианте, не получится.
Чтобы отключить автоматическое логирование хитов, нужно передать 4-й параметр false и не забыть залогировать хит позже:
$variant = $Checker->getActiveVariant(\UserSplit\Tests\Common::MY_SPLIT_TEST_KEY, $User, $Environment, false);
// какая-то логика
$Checker->logHit(\UserSplit\Tests\Common::MY_SPLIT_TEST_KEY, $variant, $User);
Это может понадобиться, например, при отправке писем. В этом случае попадание пользователя в тест должно происходить только тогда, когда он прочитал письмо (как правило, есть способы это проверить).
Если же есть какая-то дополнительная логика при определении попадания пользователя в вариант теста, то нужно создать свой класс. Выглядит это примерно следующим образом:
namespace UserSplit\Tests;
class MySplitTest
{
const KEY = 'my_split_test';
const VARIANT_CONTROL = 'control';
const VARIANT_TEST = 'test';
public static function getInstance()
{
// синглтон
}
public function getActiveVariant(\User $User, $is_log_hit = false)
{
$Environment = \UserSplit\CheckerEnvironment::byGlobals();
$Checker = \UserSplit\SplitTests\Checker::getInstance();
$variant = $Checker->getActiveVariant(static::KEY, $User, $Environment, false);
// важный момент: для контрольного варианта тоже нужно проверять дополнительное условие перед логированием хита, чтобы аудитория получилась однородной
if (!$variant) {
return $variant;
}
if (!$this->checkSomeAdditinalCondition($User)) {
return false;
}
if ($is_log_hit) {
// важный момент: хит логируем только после проверки дополнительного условия и для всех вариантов, включая контрольный
$Checker->logHit(static::KEY, $variant, $User);
}
return $variant;
}
}
Тут нужно обратить внимание на важные моменты, которые описаны в комментариях. Учитывая, что тут легко ошибиться, нужно использовать такой подход только в исключительных случаях. Их два:
- есть какое-то тяжелое условие (например, дополнительный запрос в базу), поэтому добавлять его в возможные условия теста не хотелось бы, а проверять лучше в последнюю очередь;
- есть какое-то уникальное условие, которое вряд ли понадобится в других тестах.
Клиентские тесты
Тесты, в которых не нужна какая-то дополнительная серверная логика, можно проводить полностью на клиенте (мобильное приложение или JS в браузере). Например, цвет кнопки можно тестировать полностью на клиенте, тем более, что сейчас шаблоны у нас рисуются в JS, а не на сервере. Для этого была доработана реализация мобильного API и взаимодействие c JS (на самом деле, теперь там используется то же API). Работало оно следующим образом: клиент присылал список поддерживаемых тестов (в виде чисел — ID тестов в формате строки), а сервер в ответ присылал список тестов с активными вариантами (в том же виде). Т.к. для новых тестов стали использовать ключи тестов и названия вариантов, а отличить число от строки проще простого, то для новых тестов просто стали оперировать ими.
Также есть тесты смешанного типа (я их называю клиент-серверные), где и на сервере, и на клиенте нужно знать, какой вариант активен. В этом случае, помимо попадания в тест, нужно еще проверять, поддерживает ли клиент этот тест.
Здесь появилась проблема с тем, что мы не можем просто так добавить проверку дополнительных условий в клиентских и клиент-серверных тестах. Такую проверку можно автоматизировать, если сделать такой интерфейс:
namespace UserSplit;
interface AdditionalConditions
{
/**
* @param \User $User
* @param \UserSplit\CheckerEnvironment $Environment
* @return boolean
*/
public static function checkAdditionalConditions(\User $User, \UserSplit\CheckerEnvironment $Environment);
}
После проверки условий делаем дополнительную проверку: если у теста есть PHP-класс (класс, находящийся в пространстве имен \UserSplit\Tests и имеющий такое же название, как и ключ теста, но в CamelCase) и он имплементирует этот интерфейс, то вызываем у него метод checkAdditionalConditions(). Если результат false — значит, пользователь не попал в тест. Реализовать эту идею мы пока еще не успели, но собираемся.
Пользовательские группы
В команде биллинга был разработан инструмент «пользовательские группы». Изначально он был сделан для того, чтобы управлять доступностью фич для пользователей.
Применялся он следующим образом: например, у нас есть сезонные подарки на Рождество, но их нет смысла отображать в мусульманских странах, т.к. там его не отмечают. В таком случае мы можем создать пользовательскую группу, в которой будет прописан список стран, где отмечают Рождество, и проверять пользователя на вхождение в нее перед отображением рождественских подарков. Соответственно, эту пользовательскую группу можно менять (например, добавить страны) через веб-интерфейс, не привлекая разработчика. Использовать сплит-тесты в данном случае было бы неправильно, т.к. нам не нужно сравнивать варианты, нам нужно только включить фичу для определенного круга пользователей.
Но, помимо прямого назначения, этот инструмент использовался для сплит-тестирования. Например, тесты как сущность там отсутствовали и создавались в виде нескольких пользовательских групп, представляющих собой варианты.
В целом инструменты для сплит-тестирования и пользовательские группы довольно похожи, а держать два похожих инструмента не очень хорошо. Поэтому мы решили сделать на базе UserSplit пользовательские группы, а пользовательские группы команды биллинга перенести в UserSplit.
Интерфейс (как программный, так и веб) выглядит почти так же, как и интерфейс сплит-тестов, но он упрощен за счет отсутствия вариантов. Вот так выглядит программный интерфейс:
$Environment = \UserSplit\CheckerEnvironment::byGlobals(); // нужно для environment-фильтров, см. выше
$Checker = \UserSplit\UserGroups\Checker::getInstance(); // DI мы еще не внедрили, и не факт, что внедрим, т.к. команда большая и сложно прийти к единому решению
$is_in_group = $Checker->isInGroup(\UserSplit\Groups\Common::MY_USER_GROUP_KEY, $User, $Environment);
if ($is_in_group) {
// поведение, которое соответствует пользовательской группе
}
UserSplit Iterator
Иногда возникает необходимость пройти по всем пользователям, соответствующим каким-то условиям, чтобы совершить какое-то действие. Для сплит-тестов и пользовательских групп был сделан UserSplit Iterator. Он позволяет сформировать правильный SQL-запрос в БД, включающий все условия теста или группы пользователей, и получить только тех пользователей, которые попадают в тест или пользовательскую группу.
Планы
Помимо уже озвученных проблем и планов у нас есть еще пара идей:
- тестирование лексем;
- предварительные графики.
Тестирование лексем
В одном из проведенных тестов лексем (текстов), где переименовали одну из платных фич, мы получили неплохой прирост прибыли. Но такие изменения требуют немало ресурсов разработчиков. Т.к. у нас есть своя система переводов лексем, мы решили встроить в нее сплит-тестирование, чтобы привлекать разработчика для этого не было необходимости. Сейчас эта фича находится в разработке у команды бэк-офиса.
Предварительные графики
На странице теста планируется выводить график, какое количество пользователей в какой вариант попадает, чтобы можно было увидеть, есть ли трафик по тесту и насколько он равномерный между вариантами.
Результат
В итоге получился довольно мощный инструмент, который еще можно развивать. Он успешно используется уже полгода. На данный момент проведено около 40 тестов и около 30 запущено. Проверка попадания пользователя в тесты в среднем на запрос составляет около 0,5 мс.
Если у вас есть вопросы по этой теме — не стесняйтесь задавать их в комментариях.
И спасибо всем, кто участвовал в разработке UserSplit!
Ринат Ахмадеев, PHP-разработчик.
