

Я люблю Ceph. Я работаю с ним уже 4 года (0.80.x — 12.2.6, 12.2.5). Порой я так увлечен им, что провожу вечера и ночи в его компании, а не со своей девушкой.
Я сталкивался с различными проблемами в этом продукте, а с некоторыми продолжаю жить и по сей день. Порой я радовался легким решениям, а иногда мечтал о встрече с разработчиками, чтобы выразить свое негодование. Но Ceph по-прежнему используется в нашем проекте и не исключено, что будет использоваться в новых задачах, по крайней мере мной. В этом рассказе я поделюсь нашим опытом эксплуатации Ceph, в некотором роде выскажусь на тему того, что мне не нравится в этом решении и может быть помогу тем, кто только присматривается к нему. К написанию этой статьи меня подтолкнули события, которые начались примерно год назад, когда в наш проект завезли Dell EMC ScaleIO, ныне известный как Dell EMC VxFlex OS.
Это ни в коем случае не реклама Dell EMC или их продукта! Лично я не очень хорошо отношусь к большим корпорациям, и черным ящикам вроде VxFlex OS. Но как известно, всë в мире относительно и на примере VxFlex OS очень удобно показать каков Ceph с точки зрения эксплуатации, и я попробую это сделать.
Параметры. Речь идет о 4-значных числах!
Сервисы Ceph такие как MON, OSD и т.д. имеют различные параметры для настройки всяческих подсистем. Параметры задаются в конфигурационном файле, демоны считывают их в момент запуска. Некоторые значения можно удобно изменять налету с помощью механизма "инжекта", о котором чуть ниже. Все почти супер, если опустить тот момент, что параметров сотни:
Hammer:
> ceph daemon mon.a config show | wc -l
863Luminous:
> ceph daemon mon.a config show | wc -l
1401Получается ~500 новых параметров за два года. В целом параметризация — это круто, не круто то, что есть трудности с пониманием 80% из этого списка. В документации описано по моим прикидкам ~20% и местами неоднозначно. Понимание смысла большинства параметров приходится искать в github'е проекта или в листах рассылки, но и это не всегда помогает.
Вот пример нескольких параметров, которые мне были интересны буквально недавно, я нашел их в блоге одного Ceph-овода:
throttler_perf_counter = false // enable/disable throttler perf counter
osd_enable_op_tracker = false // enable/disable OSD op trackingКомменты в коде в духе лучших практик. Как бы, слова я понимаю и даже примерно о чём они, но что мне это даст — нет.
Или вот: osd_op_threads в Luminous не стало и только исходники помогли найти новое название: osd_peering_wq threads
Ещё мне нравится, что есть особенно холиварные параметры. Тут чувак показывает, что увеличение rgw_num _rados_handles это благо:
а другой чувак считает, что > 1 делать нельзя и даже опасно.
И самое мое любимое — это когда начинающие специалисты приводят в своих блог-постах примеры конфига, где все параметры бездумно (мне так кажется) скопированы с другого такого же блога, и так куча параметров, о которых никто не знает кроме автора кода — кочует из конфига в конфиг.
Еще я просто дико горю с того, что они сделали в Luminous. Есть суперкрутая фича — изменение параметров на лету, без перезапуска процессов. Можно, например, изменить параметр конкретного OSD:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'или поставить '*' вместо 12 и значение будет изменено на всех OSD. Это оч круто, правда. Но, как и многое в Ceph, это сделано левой ногой. Бай дизайн не все значения параметров можно менять на лету. Точнее, их можно сетить и они появятся в выводе измененными, но по факту, перечитываются и пере-применяются лишь некоторые. Например, нельзя изменить размер тред-пула без рестарта процесса. Чтобы исполнитель команды понимал, что параметр бесполезно менять таким способом — решили печатать сообщение. Здраво.
Например:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true'
mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)Неоднозначно. По факту удаление пулов становится возможным после инжекта. То есть этот warning не актуален для этого параметра. Ок, но есть еще сотни параметров, в том числе и очень полезные, у которых тоже warning и проверить их фактическую применимость нет возможности. На текущий момент я не могу понять даже по коду, какие параметры применяются после инжекта, а какие нет. Для надежности приходится рестартить сервисы и это, знаете ли, бесит. Бесит потому что я знаю, что есть механизм инжекта.
Как с этим у VxFlex OS? У аналогичных процессов типа MON (в VxFlex это MDM), OSD (SDS в VxFlex) тоже есть конфигурационные файлы, в которых на всех с десяток параметров. Правда их названия тоже ни о чем не говорят, но радует то, что мы к ним никогда не прибегали, чтобы так гореть как с Ceph.
Технический долг
Когда вы начинаете свое знакомство с Ceph с самой актуальной на сегодня версии, то все кажется прекрасным, так и хочется написать позитивную статью. Но когда ты живешь с ним в проде с версии 0.80, то все выглядит не так радужно.
До Jewel, процессы Ceph работали от root'а. В Jewel было решено, что они должны работать от пользователя 'ceph' и это требовало смены владельца у всех каталогов, которые используются сервисами Ceph. Казалось бы, что такого? Представьте себе OSD, которая обслуживает магнитный SATA-диск емкостью 2 TB, заполненный на 70%. Так вот, chown такого диска, в параллель (на разные подкаталоги) при полной утилизации диска занимает 3-4 часа. Представьте, что у вас, например, 3 сотни таких дисков. Даже если обновлять нодами (chown'ить сразу 8-12 дисков) получается довольно долгое обновление, при котором в кластере будут OSD разных версий и на одну реплику данных меньше в момент вывода сервера на обновление. В общем мы посчитали, что это абсурд, пересобрали пакеты Ceph и оставили работать OSD под root'ом. Решили, что по мере ввода или замены OSD будем переводить их на нового пользователя. Сейчас мы меняем 2-3 диска в месяц и добавляем 1-2, думаю к 2022 году справимся).
CRUSH Tunables
CRUSH — сердце Ceph, всё вертится вокруг него. Это алгоритм, с помощью которого, псевдослучайным образом выбирается место размещения данных и благодаря которому клиенты, работающие с RADOS-кластером узнают на каких OSD хранятся нужные им данные (объекты). Ключевая фишка CRUSH в том, что нет необходимости в каких-то серверах метаданных, как например в Lustre или IBM GPFS (ныне Spectrum Scale). CRUSH позволяет клиентам и OSD взаимодействовать друг с другом напрямую. Хотя, конечно, сложно сравнивать примитивное объектное хранилище RADOS и файловые системы, что я привёл в качестве примера, но думаю мысль понятна.
В свою очередь, CRUSH tunables — это набор параметров/флагов, которые влияют на работу CRUSH, делают его более эффективным по крайней мере в теории.
Так вот, при обновлении с Hammer на Jewel (тестовом естественно) появился warning, мол tunables профиль имеет не оптимальные для текущей версии (Jewel) параметры и рекомендуется переключить профиль на оптимальный. В целом все понятно. В доке сказано, что это очень важно и это верный путь, но также сказано, что после переключения данных будет ребеланс 10% данных. 10% — звучит не страшно, но мы решили протестировать. Для кластера, примерно в 10 раз меньше того, что на проде, с таким же числом PG на одну OSD, заполненном тестовыми данными мы получили ребеланс 60%! Представляете, например, при 100TB данных, 60TB начинают перемещаться между OSD и это при постоянно идущей клиентской нагрузке требовательной к latency! Если я еще не сказал, мы предоставляем s3 и у нас даже ночью не особо снижается нагрузка на rgw, которых сейчас 8 и ещё 4 под статические сайты (static websites). В общем мы решили, что это не наш путь тем более, что делать такой ребеланс на новой версии, с которой мы еще не работали в проде — как минимум слишком оптимистично. К тому же у нас были большие бакет-индексы, которые очень плохо переживают ребеланс и это тоже было причиной отсрочки переключения профиля. Об индексах будет отдельно чуть ниже. В итоге мы просто убрали warning и решили вернуться к этому позже.
А еще при переключении профиля в тестинге у нас отвалились cephfs-клиенты, которые в ядрах CentOS 7.2, так как они не могли работать с более новым алгоритмом хеширования пришедшего с новым профилем. Мы не используем cephfs в проде, но, если бы использовали, то это было бы ещё одной причиной не переключать профиль.
Кстати, в доке сказано, что если то, что будет происходить во время ребеланса вас не устраивает, то можно откатить профиль обратно. В действительности, после чистой установки версии Hammer и обновления на Jewel профиль выглядит так:
> ceph osd crush show-tunables
{
...
"straw_calc_version": 1,
"allowed_bucket_algs": 22,
"profile": "unknown",
"optimal_tunables": 0,
...
}Тут важно, что он "unknown" и, если попытаться остановить ребеланс переключением его на "legacy" (как сказано в доке) или даже на "hammer", то ребеланс не прекратится, он просто продолжится в соответствии с другими tunables, а не "оптимальными". В общем всё нужно досконально проверять и перепроверять, ceph доверия нет.
CRUSH trade-of
Как известно, всё в этом мире сбалансированно и ко всем преимуществам прилагаются недостатки. Недостаток CRUSH в том, что PG размазываются по разным OSD неравномерно даже при одинаковом весе последних. Плюс к этому, ничего не мешает разным PG расти с разной скоростью, тут как хеш-функция ляжет. Конкретно у нас разброс утилизации OSD 48-84% при том, что они имеют один и тот же размер и, соответственно, вес. Даже серверы мы стараемся делать равными по весу, но это так, просто наш перфекционизм, не более. И фиг бы с тем, что IO по дискам распределяется неравномерно, самое страшное то, что при достижении статуса full (95%) хотя бы одной OSD в кластере, вся запись останавливается и кластер переходит в readonly. Весь кластер! И не важно, что в кластере еще полно места. Всё, конечная, выходим! Это архитектурная особенность CRUSH. Представляете, вы такие в отпуске, какая-то OSD пробила отметку в 85% (первый warning по умолчанию), и у вас есть 10% в запасе, чтобы не допустить остановки записи. А 10% при активно идущей записи — это не так уж много/долго. В идеале, с таким дизайном, для Ceph нужен дежурный, способный выполнить подготовленную инструкцию в подобных случаях.
Так вот, решили мы значит разбалансировать данные в кластере, т.к. несколько OSD были близки к nearfull-отметке (85%).
Есть несколько путей:
- Добавить диски
Проще всего, слегка расточительно и при этом не сильно эффективно, т.к. сами по себе данные могут и не переместиться с переполненных OSD или перемещение будет незначительным.
- Менять перманентный вес OSD (WEIGHT)
Это приводит к изменению веса всех вышестоящих бакетов (терминология CRUSH) по иерархии, OSD сервера, дата-центра и т.д. и, как следствие, к перемещению данных, в том числе не с тех OSD, с которых надо.
Мы попробовали, снизили вес одной OSD, после ребеланса данных наполнилась другая, снизили ей, затем третья и мы поняли, что будем долго так играться.
- Менять не-перманентный вес OSD (REWEIGHT)
Это то, что делается при вызове 'ceph osd reweight-by-utilization'. Это приводит к смене так называемого корректировочного веса OSD и при этом не меняется вес вышестоящих бакетов. В результате данные балансируют между разными OSD одного сервера, как бы, не выходя за пределы бакета CRUSH. Нам этот подход очень понравился, мы посмотрели в dry-run'е какие будут изменения и выполнили на проде. Все было хорошо, пока процесс ребеланса не встал колом примерно на середине. Опять гугление, чтение рассылок, эксперименты с разными опциями и в конце концов выясняется, что остановка вызвана отсутствием у нас некоторых tunables в профиле о котором говорилось выше. Опять нас догнал технический долг. В итоге мы пошли по пути добавления дисков и самого неэффективного ребеланса. Благо нам все равно нужно было это делать т.к. переключение CRUSH-профиля планировалось делать с достаточным запасом по ёмкости.
Да, мы знаем про balancer (Luminous и выше) вошедший в состав mgr, который призван решить проблему неравномерности распределения данных путем перемещения PG между OSD, например, по ночам. Но я не слышал ещё положительных отзывов о его работе даже в актуальном Mimic.
Вы, наверное, скажете, что технический долг — это сугубо наша проблема и я, пожалуй, соглашусь. Но за четыре года с Ceph в проде у нас был зафиксирован только один downtime s3, который продлился целый 1 час. И то, проблема была не в RADOS'е, а в RGW, которые набрав свои дефолтные 100 тредов вешались намертво и у большинства пользователей не выполнялись запросы. Это было еще на Hammer. На мой взгляд, это хороший показатель и достигнут он благодаря тому, что мы не делаем резких движений и достаточно скептичны на счёт всего в Ceph.
Дикий GC
Как известно, удаление данных непосредственно с диска — это довольно ресурсоёмкая задача и в продвинутых системах удаление делается отложено или не делается вообще. Ceph тоже продвинутая система и в случае с RGW, при удалении s3-объекта, соответствующие RADOS-объекты не удаляются с диска сразу. RGW помечает s3-объекты как удаленные, а отдельный gc-поток занимается удалением объектов непосредственно из RADOS пулов и соответственно с дисков отложено. После обновления на Luminous поведение gc заметно поменялось, он стал работать агрессивнее, хотя параметры gc остались прежними. Под словом заметно я имею ввиду, что мы стали видеть работу gc на внешнем мониторинге сервиса по подскакивающему latency. Это сопровождалось высоким IO в пуле rgw.gc. Но проблема, с которой мы столкнулись гораздо эпичнее чем просто IO. При работе gc генерируется очень много логов вида:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828Где 0 в начале — это уровень логирования, при котором печатается данное сообщение. Как бы, ниже нуля опускать логирование уже некуда. В итоге ~1 GB логов у нас генерился одной OSD за пару часов, и всё бы ничего, если бы ceph-ноды не были бы бездисковыми… Мы загружаем OS по PXE прямо в память и не используем локальные диск или NFS, NBD для системного раздела (/). Получаются stateless-серверы. После перезагрузки всё состояние накатывается автоматизацией. Как это работает я как-нибудь опишу в отдельном материале, сейчас важно то, что под "/" отведено 6 GB памяти, из которых обычно свободно ~4. Мы отправляем все логи в Graylog и используем довольно агрессивную политику ротации логов и обычно не испытываем каких-либо проблем с переполнением дисков/RAM. Но к такому мы были не готовы, при 12 OSD на сервере "/" заполнился очень быстро, дежурные вовремя не среагировали на триггер в Zabbix и OSD просто начали останавливаться из-за невозможности писать лог. В итоге мы понизили интенсивность gc, тикет не заводили т.к. таковой уже был, и добавили скрипт в cron, в котором делаем принудительный truncate логов OSD при превышении определенного объема не дожидаясь logrotate. Кстати, уровень логирования повысили.
Placement Groups и хвалёная масштабируемость
На мой взгляд, PG — это наиболее сложная абстракция для понимания. PG нужны для того, чтобы CRUSH был более эффективным. Основное предназначение PG — группировка объектов для снижения ресурсопотребления, повышения производительности и масштабируемости. Адресация объектов директно, по отдельности, без объединения их в PG была бы очень затратной.
Основная проблема PG — это определение их числа для нового пула. Из блога Ceph:
"Choosing the right number of PGs for your cluster is a bit of black art-and a usability nightmare".
Это всегда очень специфично для конкретной инсталляции и требует длительных раздумий и подсчетов.
Основные рекомендации:
- Слишком много PG на OSD — плохо, будет перерасход ресурсов на их обслуживание и тормоза во время ребаланса/восстановления.
- Мало PG на OSD — плохо, будет страдать производительность, и OSD будут заполнены неравномерно.
- Число PG должно быть кратно степени 2. Это поможет получить "power of CRUSH".
И вот тут у меня подгорает. PG не имеют ограничений по объему или по числу объектов. Сколько ресурсов (в реальных числах) нужно на обслуживание одной PG? Зависит ли это от ее размера? Зависит ли это от числа реплик этой PG? Стоит ли мне париться, если у меня достаточно памяти, быстрые CPU и хорошая сеть?
И ещё нужно думать о будущем росте кластера. Число PG нельзя уменьшить — только увеличить. При этом делать это не рекомендуется, так как это повлечет, по сути, к сплиттингу части PG на новые и дикому ребелансу.
"Increasing the PG Count of a pool is one of the most impactful events in a Ceph Cluster, and should be avoided for production clusters if possible".
Поэтому о будущем нужно думать сразу, если это возможно.
Реальный пример.
Кластер из 3 серверов по 14x2 TB OSD в каждом, всего 42 OSD. Реплика 3, полезного места ~28 TB. Будет использоваться под S3, нужно рассчитать число PG для пула с данными и индексного пула. RGW использует больше пулов, но указанные два — основные.
Заходим в калькулятор PG (есть такой калькулятор), считаем с рекомендуемыми 100 PG на OSD, получаем всего 1312 PG. Но не все так просто: у нас есть вводная — кластер в течение года точно вырастет в три раза, но железо докупят чуть позже. Увеличиваем "Target PGs per OSD" в три раза, до 300 и получаем 4480 PG.
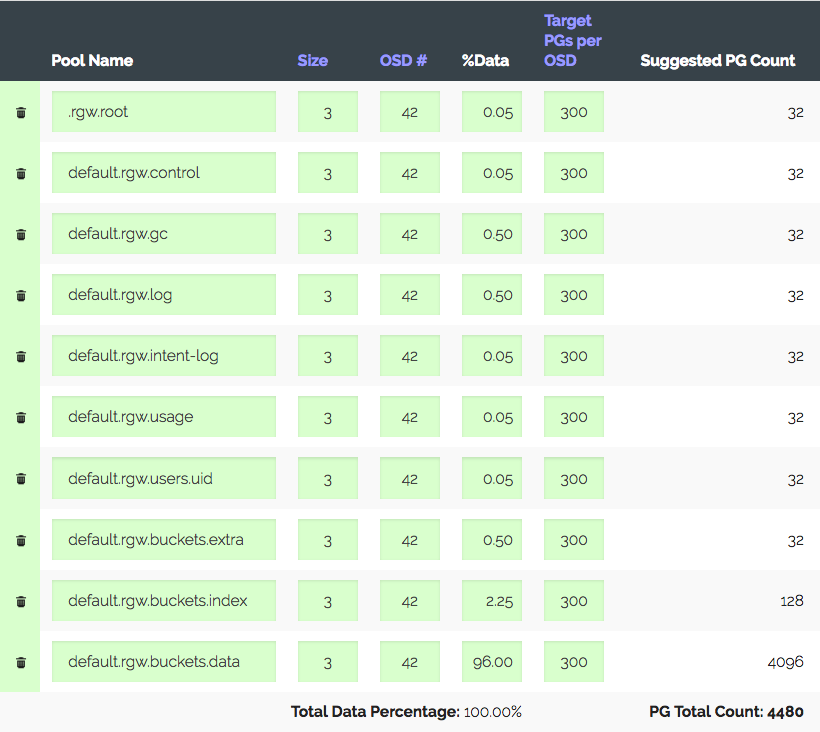
Устанавливаем число PG для соответствующих пулов — получаем warning: too many PG Per OSD… приехали. Получили ~300 PG на OSD при ограничении в 200 (Luminous). Раньше было 300, кстати. И самое интересное, что всем излишним PG не позволяется пириться (peering), то есть это не просто warning. В итоге считаем, что мы все делаем правильно, повышаем лимиты, отключаем предупреждение и идем дальше.
Другой реальный пример поинтереснее.
S3, 152 TB полезного объема, 252 OSD по 1.81 TB, ~105 PG на OSD. Кластер рос постепенно, всё было хорошо пока с новыми законами в нашей стране не возникла потребность в росте до 1 PB, то есть + ~850 TB, и при этом нужно сохранить производительность, которая сейчас довольно хорошая для S3. Допустим мы возьмём диски по 6 (5.7 реально) TB и с учетом реплики 3 получим + 447 OSD. С учетом текущих получится 699 OSD по 37 PG на каждую, а если учитывать различный вес, то получится, что на старые OSD придётся всего десяток PG. И вот вы мне скажите, насколько сносно это будет работать? Производительность кластера с разным числом PG довольно сложно померить синтетически, но те тесты, что проводил я показывают, что для оптимальной производительности нужно от 50 PG на 2 TB OSD. А дальнейший рост? Без увеличения числа PG можно дойти до мапинга PG к OSD 1:1. Может я чего-то не понимаю?
Да, можно создать новый пул для RGW с нужным числом PG и намапить на него отдельный S3-регион. Или и вовсе построить рядом новый кластер. Но согласитесь, что всё это костыли. И получается, что вроде как хорошо масштабируемый Ceph из-за своей концепции PG масштабируется с оговорками. Вам либо придётся жить с отключенными ворнингами готовясь к росту, либо в какой-то момент ребелансить все данные в кластере, либо забить на производительность и жить с тем, что получится. Либо пройти через всё это.
Радует, что разработчики Ceph понимают, что PG сложная и лишняя абстракция для пользователя и ему о ней лучше не знать.
"In Luminous we've taken major steps to finally eliminate one of the most common ways to drive your cluster into a ditch, and looking forward we aim to eventually hide PGs entirely so that they are not something most users will ever have to know or think about".
В vxFlex нет понятия PG или каких-то аналогов. Вы просто добавляете диски в пул и всё. И так до 16 PB. Представляете, ничего не нужно рассчитывать, нет кучи статусов этих PG, диски утилизируются равномерно на всём протяжении роста. Т.к. диски отдаются в vxFlex целиком (нет файловой системы поверх них) нет возможности оценить заполненность и нет вообще такой проблемы. Я даже не знаю, как передать вам насколько это приятно.
"Нужно ждать SP1"
Ещё одна история "успеха". Как известно, RADOS — это примитивнейшее хранилище ключ-значение. S3, реализуемый поверх RADOS'а тоже примитивный, но все же немного более функционален. Например, в S3 можно получить список объектов по префиксу. Для того, чтобы это работало, RGW поддерживает свой собственный индекс для каждого бакета. Этот индекс — один RADOS-объект, который фактически будет обслуживаться одной OSD. С ростом числа объектов в бакете растёт объект индекса. По нашим наблюдениям, начиная от нескольких миллионов объектов в бакете начинаются заметные тормоза при записи в этот бакет. OSD обслуживающая объект индекса ест много памяти и может периодически уходить в down. Тормоза вызваны тем, что индекс блокируется на каждое изменение, дабы сохранить консистентность. Кроме этого, при операциях scrub'инга или ребеланса объект индекса также блокируется на всё время операции. Всё это периодически приводит к тому, что клиенты получают тайм-ауты и 503, производительность больших бакетов страдает в принципе.
Bucket Index resharding — это механизм, позволяющий разделить индекс на несколько частей (RADOS-объектов) и, соответственно, разложить по разным OSD, тем самым добиться масштабируемости и снизить влияние служебных операций.
Кстати, стоит отметить, что возможность ручного решардинга появилась только в Jewel и была бекпортирована в одну из последних багфиксных! сборок Hammer, что показывает ее высокую важность т.к. это не является баг-фиксом. Как вообще до этого работали большие бакеты?
В Hammer у нас было несколько бакетов с 20+ млн объектов, и мы регулярно испытывали с ними проблемы, мы знали номера заветных OSD и по сообщениям из Graylog понимали, что с ними происходит. Ручной решардинг нам не подходил, т.к. требовал остановки IO для конкретного бакета. Нам нужен был Luminous, т.к. в нем решардинг стал автоматическим и прозрачным для клиентов. Мы обновились на Luminous, но решардинг не включали, тестировали. Всё выглядело нормально, и мы включили его в проде. IO ожидаемо подросло в index-пуле, бакеты начали шардироваться, я открыл бутылочку пивка и закончил рабочий день пораньше. Спустя день мы обнаружили, что IO стабильно держится на высоком уровне, при этом все проблемные бакеты расшардированы. Выяснялось, что индексы шардируются по кругу… Вскоре нашлись тикеты; раз, два:
Пришлось отключать, благо проблемные индексы были уже шардированы. Еще один пункт в копилку технического долга, т.к. бакеты могут расти дальше и шардинг будет нужен снова не завтра, так через месяц.
Кстати, обновление Hammer->Jewel было весёлым из-за этих жирных индексов. OSD держащая индекс пробивала все тайм-ауты на рестарте. Нам приходилось подкручивать таймауты тредов прям на проде, чтобы эти заветные OSD могли подняться и не убивали сами себя.
История с авторешардингом — не единственный случай, когда новая фича работала так, что лучше бы она не работала вообще. В версии Hammer была такая фича s3, как версионирование объектов. Это принесло нам сильно больше вреда, чем пользы. У многих бакетов с включенным версионированием постепенно, с ростом числа объектов, начинали появляться объекты с неверным etag, с нулевым body, возникали ошибки при удалении объектов. На тот момент мы нашли несколько открытых репортов с похожими проблемами. Мы тщетно пытались воспроизвести эти проблемы, потратили много времени без результата. Suspend версионирования не решал проблему. В итоге "решением" было создание новых бакетов без версионирования и перенос объектов в них. Это довольно сильно ударило по нашей репутации и доставило неудобства нашим заказчикам, а мы потратили много ресурсов на помощь им.
Холивары на тему числа реплик
Как только заходят разговоры о числе реплик, так сразу реплика 2 — это идиотизм, наркомания и вообще такую конфигурацию скоро ждет участь Cloudmouse. Да, если у вас Ceph, то, возможно.
В vxFlex OS фактор репликации 2 и это невозможно поменять. Единственное, необходимо иметь определенный объем места в резерве для восстановления данных в случае аварии. Этот объем должен быть равен дисковому объему, который может отказать единовременно. Если у вас потенциально вся стойка может быть отключена по питанию, то и резервировать вам нужно объем самой жирной стойки. Можно спорить об эффективности и надежности подобной схемы, но не зная точно, как это работает внутри, остаётся только довериться инженерам Dell EMC.
Производительность
Ещё одна холиварная тема. Что такое производительность распределенной системы хранения данных, да ещё и с репликацией по сети? Хороший вопрос. Понятно, что у таких систем большой оверхед. На мой взгляд, уровень производительности систем типа Ceph, vxFlex нужно измерять в отношении их показателей к показателям используемого оборудования. Важно понимать сколько производительности мы теряем из-за используемой прослойки. Эта метрика является и экономической в том числе, от нее зависит сколько нам нужно купить дисков и серверов для достижения нужных абсолютных значений.
Письмо от 9 августа из ceph-devel рассылки: Вкратце, ребята получают утилизированные по CPU серверы (по два Xeon'а в сервере!) и смешные IOPS на All-NVMe кластере на Ceph 12.2.7 и bluestore.
Статей, презентаций и дискуссий в листах рассылки валом, но "летит" Ceph всё ещё довольно низко. Несколько лет назад (во времена Hammer) мы тестировали различные решения для блочного стораджа и Ceph был у нас фаворитом, так как мы использовали его в качестве s3 и надеялись использовать как блочный. К сожалению, тогдашний ScaleIO растоптал Ceph RBD с поразительными результатами. Основная проблема Ceph, с которой мы столкнулись — это недоутилизированные диски и переутилизированный CPU. Я хорошо помню наши приседания с RDMA поверх InfiniBand, jemalloc и прочими оптимизациями. Да, если писать с 10-20 клиентов, то можно получить довольно приятные суммарные iops, но в отсутствии параллелизма клиентского io, Ceph совсем плох даже на быстрых дисках. vxFlex же умудряется хорошо утилизировать все диски и демонстрирует высокую производительность. Принципиально отличается ресурсопотребление — у Ceph высокий system time, у scaleio — io wait. Да, тогда не было bluestore, но судя по сообщениям в рассылке, он не серебряная пуля, и к тому же даже сейчас по числу баг-репортов, кажется, он лидер в трекере Ceph. Мы выбрали тогдашний ScaleIO не сомневаясь. Учитывая метрику, о которой говорилось в начале раздела, Ceph был бы экономически не выгоден даже с учетом стоимости лицензий Dell EMC.
Кстати, если в кластере используются диски разной емкости, то в зависимости от их веса будут распределены PG. Это справедливое распределение с точки зрения объема (типа), но не справедливое по IO. Из-за меньшего числа PG на маленькие диски будет приходиться меньше IO, чем на большие при том, что у них обычно одинаковая производительность. Возможно, разумным будет завысить вес меньших дисков в начале и понижать его при приближении к nearfull. Так производительность кластера может быть более сбалансированной, но это не точно.
В vxFlex нет понятия журнала или какого-то кеша или тиринга, вся запись сразу идёт на диски. Также нет процедуры предварительной настройки диска (смотрю в сторону ceph-volume), вы просто отдаёте ему блочное устройство в монопольное пользование, всё очень просто и удобно.
Scrub
Банально, согласен. Через это, наверное, прошел каждый кто живет с Ceph.
Как только в вашем кластере появляется много данных и начинается активное их использование, не заметить влияние скраба довольно сложно. "Много данных" в моем понимании — это не какой-то общий объём в кластере, а заполненность используемых дисков. Например, если у вас диски по 2 TB и они заполнены на >50%, то у вас много данных в Ceph, даже если диска всего два. Мы в свое время очень настрадались от скраба и долго искали решение. Наш рецепт, который хорошо работает и по сей день.
У vxFlex OS тоже есть такой механизм и по умолчанию он выключен, как и почти всё, что не является основной функциональностью. При включении можно задать всего один параметр — bandwidth в килобайтах. Меняется он на лету и позволяет подобрать оптимальное для вашего кластера значение. Мы оставили значение по умолчанию и пока всё хорошо, даже меняем периодически диски после сообщений об ошибках.
Кстати, что интересно, vxFlex сам разруливает ситуации типа scrub-error. Ceph же с той же репликой 2 требует ручного вмешательства.
Мониторинг
Luminous — знаковый во многих смыслах релиз. В этой версии наконец появились родные средства мониторинга. С помощью встроенного MGR-плагина и официального шаблона для Zabbix можно в несколько действий получить базовый мониторинг с графиками и самыми важными алертами (3 штуки). Также есть плагины и для других систем. Это правда круто, мы пользуемся этим, но по-прежнему нужно писать свои скрипты и шаблоны для мониторинга IO по пулам, чтобы понимать когда озорничает gc, например. Отдельная тема — это мониторинг RGW инстансов.

Без него я просто как слепой котенок. Его тоже нужно писать самому.
А это фрагмент внешнего мониторинга S3, то как клиенты "видят" сервис:
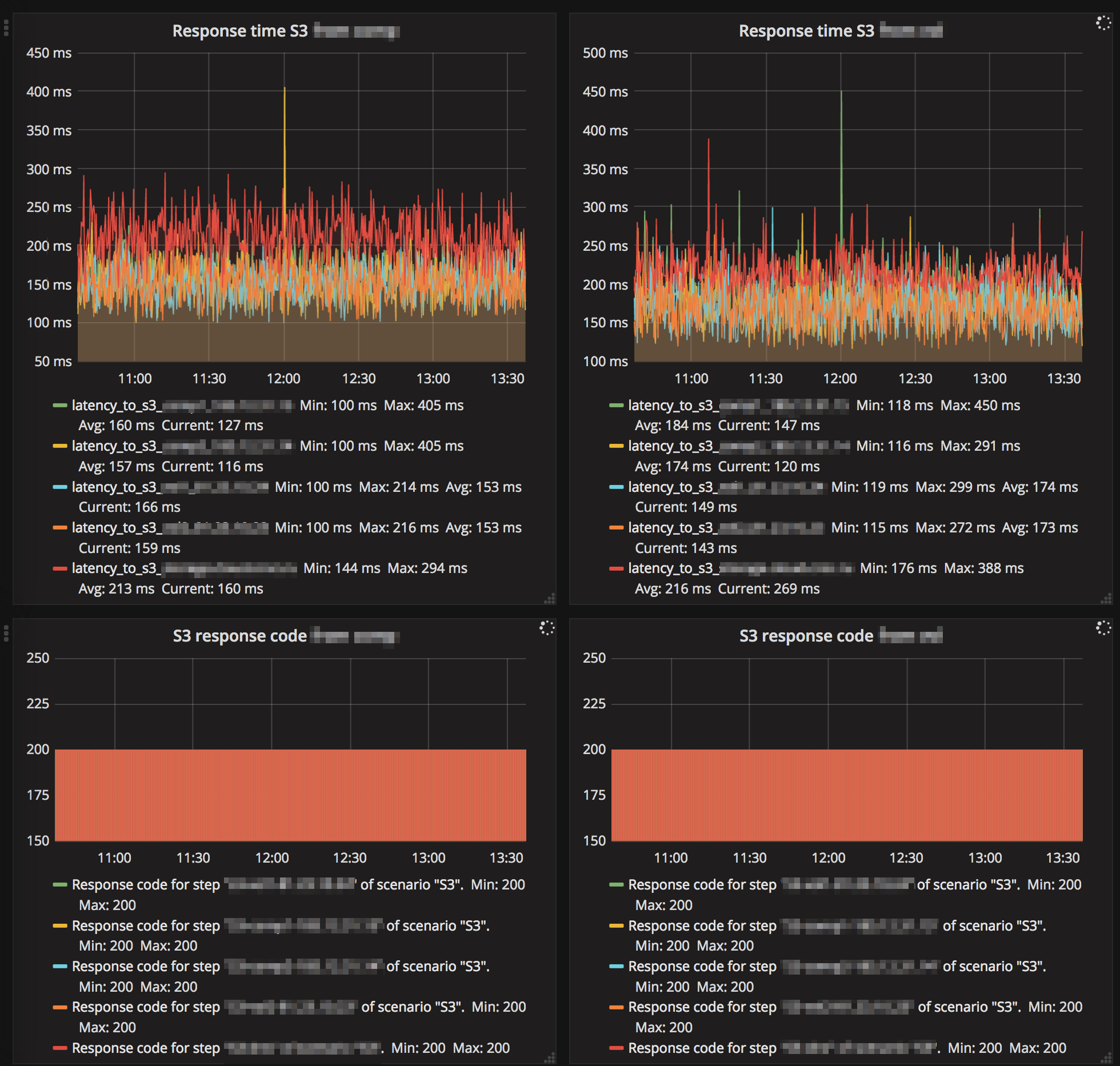
К самому Ceph этот мониторинг, естественно, не имеет отношения, но я очень рекомендую вам его завести, если такового ещё нет.
Приятно отметить, что мониторы Сeph умеют в Graylog по протоколу GELF и мы этим пользуемся. Получаем алерты, например, когда OSD down, out, failed и другие. При настроенном парсинге сообщений можем анализировать логи за период времени, например, знать топ OSD по переходу в down за месяц, или строить график интенсивности скраббинга.
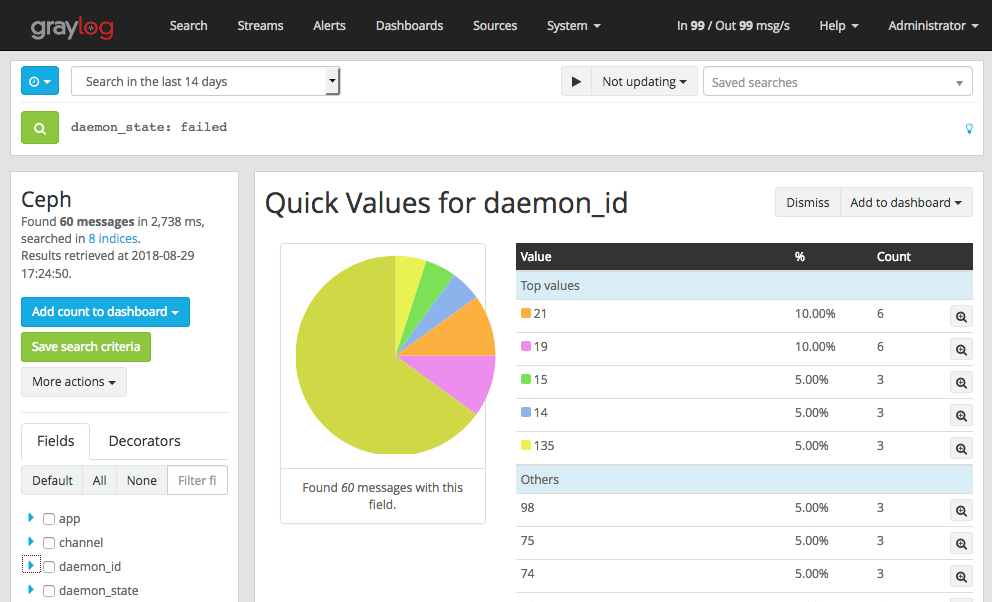
Как-то было, что у нас OSD подвисали и не успевали отвечать на heartbeat и мониторы их отмечали как failed (см. скрин выше). Причина была в vm.zone_reclaim_mode=1 на двухсокетных серверах с NUMA.
Вот вроде и похвалил Ceph. Правда c vxFlex это тоже можно. А ещё у него очень хороший дешбоард:
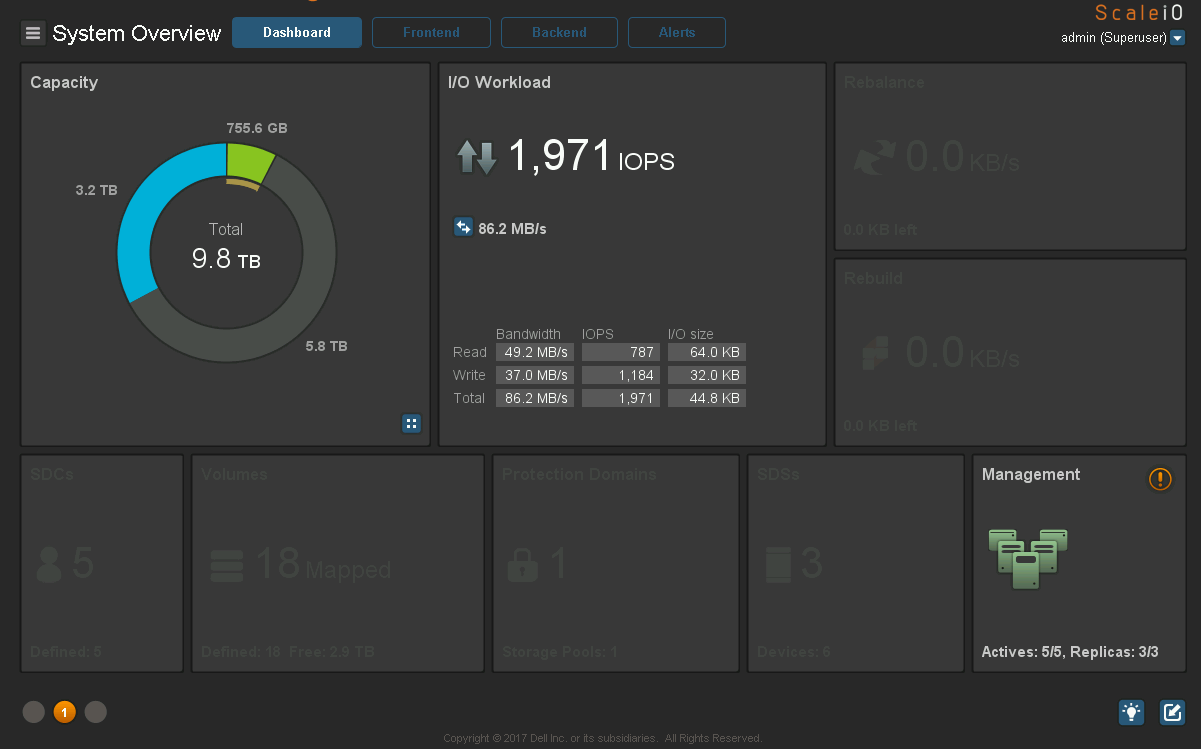
Понятно какой клиент генерит нагрузку:

Детализация IO по нодам и дискам:
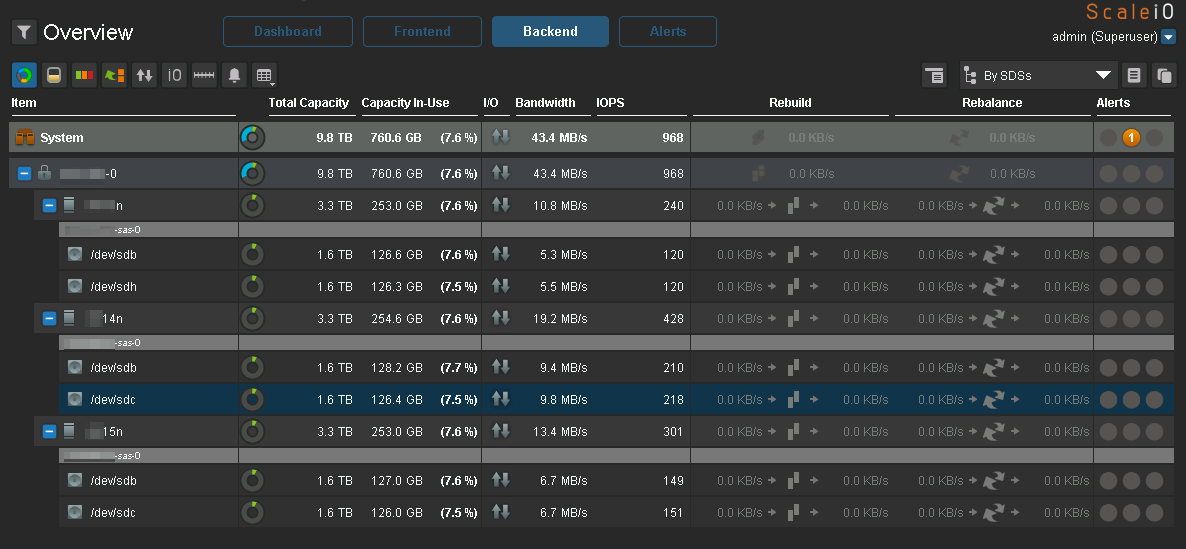
Обратите внимание как равномерно заполнены диски и как почти равномерно на них приходится IO, то чего так не хватает Ceph.
Все крутилки под рукой:
Про дешбоард Ceph, который подвезли в Luminous я и говорить не буду. Возможно в 2.0, что появился в Mimic будет интереснее, но я его ещё не смотрел.
vxFlex тоже не идеален
Когда кластер переходит в Degraded state например, когда меняется диск или перезагружается сервер нельзя создавать новые волюмы.
Клиент vxFlex — модуль ядра и поддержка новых ядер от RH появляется с задержкой. Официальной поддержки 7.5 ещё нет, например. В Ceph клиенты для RBD и cephfs — модули апстримного ядра и с обновлением последнего они тоже обновляются.
vxFlex беден на возможности в сравнении с Ceph. vxFlex — это только блочный сторадж, у которого нет, например, тиринга.
Расти можно только до 16 PB, такое вот ещё ограничение есть. С Сeph бы хватило нервов до 2 PB вырасти…
Заключение
Часто слышу, что Ceph это академический проект с кучей нерешённых проблем, что это фреймворк без документации, что его бесплатность компенсируется его сложностью, что построить нормальный сторадж на Ceph — утопия. В целом я согласен со всем.
Недавно на хабре была публикация о том, какой Ceph здоровский и что им может управлять "обычный админ". После этой статьи мой начальник подкалывал меня, мол "как так Саня, обычный админ может, а у тебя вечно R&D, вечно какие-то проблемы". Мне было немного обидно. Не знаю какие там у ребят "обычные админы", но Ceph постоянно нужно внимание довольно квалифицированного персонала, он как живой организм, который то и дело болеет.
Если вы спросите меня использовать Ceph в 2k18 или нет, то я отвечу следующее. Если ваш сервис должен работать 24/7 и плановая или неплановая остановка недопустима (публичный S3, например, или EBS), а деградация в работе сервиса повлечет за собой негодование клиентов и наказание рублем, то использовать Ceph очень и очень опасно. Скорее всего, вы будете периодически страдать. А если к тому же нужна производительность — то это может быть экономически не выгодно. Если же вы строите хранилище для внутренних нужд проекта/компании и есть возможность проводить maintenance с остановкой сервиса или выкручивать на максимум backfilling на выходных, то c Ceph вы уживетесь и, возможно, он добавит некой пикантности в вашу жизнь.
Почему же мы продолжаем использовать Ceph относясь к первой категории? Как говорится, "от ненависти до любви один шаг". Так и у меня с Ceph. Люблю потому что знаю. Слишком много пройдено с ним вместе, чтобы взять и дропнуть эти отношения и накопившуюся экспертизу, тем более сейчас, когда кажется, что все под контролем…
Но булки расслаблять нельзя!
Всем HEALTH_OK!
