О чатботах, использующих нейронные сети я уже писал некоторое время назад. Сегодня я расскажу о том как я попробовал сделать полномасштабный русскоязычный вариант.

Обучаемые диалоговые системы приобрели в последнее время неожиданную популярность. К сожалению, все что сделано в рамках нейросетевых диалоговых систем, сделано для английского языка. Но сегодня мы восполним этот пробел и научим модель говорить по русски.
Метод
Я решил для начала отказаться от генерации текста пословно. Это круто, но не так полезно, как кажется и особо сложно для русского языка с его большим числом разных словоформ. Вместо этого я решил пойти путем подбора правильного ответа из большой базы. Т.е. задачей является создать нейросеть, которая определяет, является ли предложение подходящим ответом, учитывая контекст разговора, или нет.
Почему так:
— Не нужен большой softmax слой для выбора слов, а значит мы можем больше ресурсов нейросети выделить на собственно задачу анализа текста.
— Полученная модель сопоставления годится для разных целей, теоретически можно заставить чатбот общаться на разные специальные темы, просто загрузив новую базу текстов, без нового обучения. Это полезно на практике.
— Можно сделать модель, которая работает быстро и может реально общаться со многими пользователями одновременно без нескольких GPU на сервере.
Зачем
Вообще, общетематические диалоговые системы бывают полезны, например, в онлайн-консультантах, чтобы консультант мог поговорить на несвязанные с основной задачей темы, в играх, и в ряде других задач.
Почему нейронные сети?
Нельзя ли подойти к задаче более классическим методом? Загрузить набор ответов в БД и искать полнотекстовым индексом по предыдущей фразе? Ответ, так сделать можно, но результат получается не очень. Вот допустим:
Ч: привет!
К: грег, мария, это али…
Ч: как дела?
К: из соседнего номера поступила жалоба на шум, месье
Ч: как тебя зовут?
К: спасибо, спасибо.
Ч: сколько тебе лет?
К: ты живешь где-то рядом...?
Поиск по большой базе ответов дает много результатов, но релевантность их маленькая, поэтому диалоги получаются достаточно низкого качества. Вот здесь нам и должна помочь нейронная сеть – с помощью нее мы отсортируем хорошие ответы от плохих.
Где взять данные для обучения:
Самый больной для многих вопрос. Вот здесь и здесь люди взяли базу субтитров к фильмам. Такая база есть и для русского языка, правда меньше размером. Но большая беда этой базы – в ней много монологов, различного мусора и вообще разделить диалоги друг от друга сложно.
Поэтому я решил пойти другим путем и помимо субтитров собрать диалоги из находящихся в открытом доступе книг. Начинающие писатели и авторы всевозможных фанфиков создали просто невероятный объем информации, так что грех им не воспользоваться. Конечно, там много всякой ерунды. В процессе работы мне приходилось это неизбежно читать, и голова пухла от длинных бесед какого-то Сергея и Сейлор Мун (кому то же это пришло в голову!). Но в целом, это более качественная база, чем субтитры, правда собрать ее не так просто, нужно потратить время.
Архитектура
Здесь есть немалый простор для фантазии. Я начал с простых вариантов и продвигался к сложным, чтобы понять, какая реально польза от различных наворотов. В статьях люди обычно стараются сделать круто и прицепить какой-то новый прибамбас, а в связи с тем, что область новая, то польза от этого не всегда очевидна.
Самая простая модель берет соединение последовательности векторов слов контекста и ответа и подает все это на обычный полностью соединенный слой. Поскольку ответ бывает разной длины, его записываем в вектор длины фиксированной, заполняя “лишнее” место нулями. Считается, что это плохо. Посмотрим.
Второй вариант отличается тем, что до “смешивания” контекста и ответа им дан “свой собственный” слой для формирования представления. Ну и дальше может быть несколько слоев обработки, на рисунке показано два.
Третий вариант кодирует последовательность разной длины с помощью рекуррентного LSTM кодировщика. Это много медленнее и обучается дольше. Но вроде как должно работать лучше.
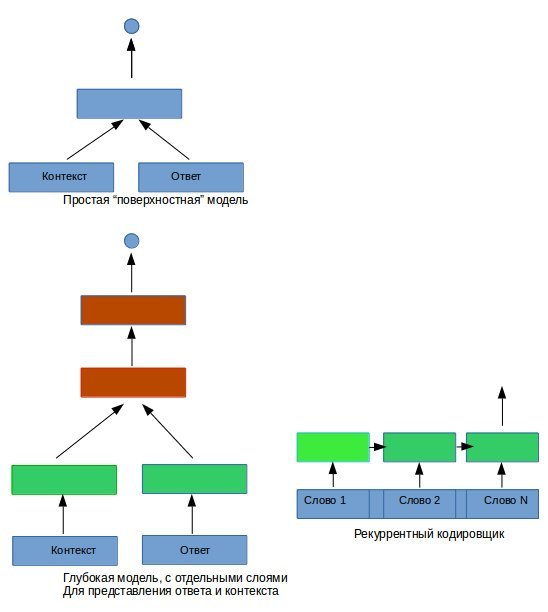
Рис.1. Архитектура нейронных сетей
Результаты
По способности выбирать правильный ответ из нескольких предложенных вариантов (случайно взятых ответов), самый лучший результат показала модель номер 2, с пятью слоями для анализа данных по 700 нейронов в каждом (+1 слой репрезентации входных данных, тоже из 700 нейронов). Чтобы обучить такую глубокую сеть, пришлось использовать Хайвей (Highway) слои, которые позволяют информации проще распространятся от нижних слоев к верхним, также подождать несколько дней пока модель рассчитывалась на GPU. Модель номер 1 явно недообучилась, а номер 3 долго думала, и тоже не добрала до результатов модели номер 2 несколько процентов. Что напоминает нам о том, хотя самые простые модели не годятся для больших объемом данных, все же никогда не следует умножать сущности сверх необходимости.
Получившаяся система располагает базой в 30 миллионов пар реплик, а нейронная сеть имеет около 3 млн. обучаемых параметров.
Какие же диалоги можно в результате получить?
Ч: Привет
К: привет.
Ч: Как твои дела?
К: Не знаю.
Ч: Как тебя зовут?
К: меня зовут юнис.
Ч: Сколько тебе лет?
К: Пятнадцать.
Ч: Где ты живешь?
К: Дома.
Ч: ты учишься в школе?
К: Нет
Ч: а где ты учишься?
К: в бундесвере.
Ч: Ты любишь музыку?
К: да, я люблю музыку.
Ч: Какая музыка тебе нравится?
К: в основном я слушаю r&b, фанк.
Ч: Ты веришь в бога?
К: я и сейчас верю в бога, старина
Ч: что такое мораль?
К: два человека вместе — разве это не мораль?
Ч: какого цвета море?
К: цвета океана после шторма.
Достаточно хорошо, на мой взгляд. Вот еще пример:
Ч: Где живет бегемот?
К: Жил
Ч: а что, сейчас не живет?
К: Я не знаю.
Ч: тогда где он жил раньше?
К: у парка, на мэйпл стрит.
Ч: куда же он пропал?
К: куда он пропал?
Ч: я тебя спрашиваю, куда он пропал?
К: я не понимаю, почему я снова в больнице.
Ч: потому что ты болеешь
К: я просто хочу помогать людям.
Ч: Тогда скажи мне, где бегемот!
К: почему ты так сильно хочешь это знать?
Ч: просто ответь мне
К: ты хочешь, чтобы я помогла тебе попрощаться с родными?
Ч: Это угроза?
К: Наблюдение
Ч: Так где же все-таки бегемот?
К: он на гавайях, но радж управляет отсюда
Ч: Кто такой радж?
К: не встречалась с ним?
Ч: Нет, никогда
К: жили-были муж с женой, только муж каждую ночь исчезал.
Выводы:
Получилось забавно. Но все же видно низкое качестве обучающих данных. Для развития модели было бы полезно собрать больше реальных диалогов. Тем не менее, результаты обнадеживают, поскольку для получения довольно разумных ответов не потребовалось создавать вручную никаких шаблонов и правил выбора ответов.

Обучаемые диалоговые системы приобрели в последнее время неожиданную популярность. К сожалению, все что сделано в рамках нейросетевых диалоговых систем, сделано для английского языка. Но сегодня мы восполним этот пробел и научим модель говорить по русски.
Метод
Я решил для начала отказаться от генерации текста пословно. Это круто, но не так полезно, как кажется и особо сложно для русского языка с его большим числом разных словоформ. Вместо этого я решил пойти путем подбора правильного ответа из большой базы. Т.е. задачей является создать нейросеть, которая определяет, является ли предложение подходящим ответом, учитывая контекст разговора, или нет.
Почему так:
— Не нужен большой softmax слой для выбора слов, а значит мы можем больше ресурсов нейросети выделить на собственно задачу анализа текста.
— Полученная модель сопоставления годится для разных целей, теоретически можно заставить чатбот общаться на разные специальные темы, просто загрузив новую базу текстов, без нового обучения. Это полезно на практике.
— Можно сделать модель, которая работает быстро и может реально общаться со многими пользователями одновременно без нескольких GPU на сервере.
Зачем
Вообще, общетематические диалоговые системы бывают полезны, например, в онлайн-консультантах, чтобы консультант мог поговорить на несвязанные с основной задачей темы, в играх, и в ряде других задач.
Почему нейронные сети?
Нельзя ли подойти к задаче более классическим методом? Загрузить набор ответов в БД и искать полнотекстовым индексом по предыдущей фразе? Ответ, так сделать можно, но результат получается не очень. Вот допустим:
Ч: привет!
К: грег, мария, это али…
Ч: как дела?
К: из соседнего номера поступила жалоба на шум, месье
Ч: как тебя зовут?
К: спасибо, спасибо.
Ч: сколько тебе лет?
К: ты живешь где-то рядом...?
Поиск по большой базе ответов дает много результатов, но релевантность их маленькая, поэтому диалоги получаются достаточно низкого качества. Вот здесь нам и должна помочь нейронная сеть – с помощью нее мы отсортируем хорошие ответы от плохих.
Где взять данные для обучения:
Самый больной для многих вопрос. Вот здесь и здесь люди взяли базу субтитров к фильмам. Такая база есть и для русского языка, правда меньше размером. Но большая беда этой базы – в ней много монологов, различного мусора и вообще разделить диалоги друг от друга сложно.
Поэтому я решил пойти другим путем и помимо субтитров собрать диалоги из находящихся в открытом доступе книг. Начинающие писатели и авторы всевозможных фанфиков создали просто невероятный объем информации, так что грех им не воспользоваться. Конечно, там много всякой ерунды. В процессе работы мне приходилось это неизбежно читать, и голова пухла от длинных бесед какого-то Сергея и Сейлор Мун (кому то же это пришло в голову!). Но в целом, это более качественная база, чем субтитры, правда собрать ее не так просто, нужно потратить время.
Архитектура
Здесь есть немалый простор для фантазии. Я начал с простых вариантов и продвигался к сложным, чтобы понять, какая реально польза от различных наворотов. В статьях люди обычно стараются сделать круто и прицепить какой-то новый прибамбас, а в связи с тем, что область новая, то польза от этого не всегда очевидна.
Самая простая модель берет соединение последовательности векторов слов контекста и ответа и подает все это на обычный полностью соединенный слой. Поскольку ответ бывает разной длины, его записываем в вектор длины фиксированной, заполняя “лишнее” место нулями. Считается, что это плохо. Посмотрим.
Второй вариант отличается тем, что до “смешивания” контекста и ответа им дан “свой собственный” слой для формирования представления. Ну и дальше может быть несколько слоев обработки, на рисунке показано два.
Третий вариант кодирует последовательность разной длины с помощью рекуррентного LSTM кодировщика. Это много медленнее и обучается дольше. Но вроде как должно работать лучше.

Рис.1. Архитектура нейронных сетей
Результаты
По способности выбирать правильный ответ из нескольких предложенных вариантов (случайно взятых ответов), самый лучший результат показала модель номер 2, с пятью слоями для анализа данных по 700 нейронов в каждом (+1 слой репрезентации входных данных, тоже из 700 нейронов). Чтобы обучить такую глубокую сеть, пришлось использовать Хайвей (Highway) слои, которые позволяют информации проще распространятся от нижних слоев к верхним, также подождать несколько дней пока модель рассчитывалась на GPU. Модель номер 1 явно недообучилась, а номер 3 долго думала, и тоже не добрала до результатов модели номер 2 несколько процентов. Что напоминает нам о том, хотя самые простые модели не годятся для больших объемом данных, все же никогда не следует умножать сущности сверх необходимости.
Получившаяся система располагает базой в 30 миллионов пар реплик, а нейронная сеть имеет около 3 млн. обучаемых параметров.
Какие же диалоги можно в результате получить?
Ч: Привет
К: привет.
Ч: Как твои дела?
К: Не знаю.
Ч: Как тебя зовут?
К: меня зовут юнис.
Ч: Сколько тебе лет?
К: Пятнадцать.
Ч: Где ты живешь?
К: Дома.
Ч: ты учишься в школе?
К: Нет
Ч: а где ты учишься?
К: в бундесвере.
Ч: Ты любишь музыку?
К: да, я люблю музыку.
Ч: Какая музыка тебе нравится?
К: в основном я слушаю r&b, фанк.
Ч: Ты веришь в бога?
К: я и сейчас верю в бога, старина
Ч: что такое мораль?
К: два человека вместе — разве это не мораль?
Ч: какого цвета море?
К: цвета океана после шторма.
Достаточно хорошо, на мой взгляд. Вот еще пример:
Ч: Где живет бегемот?
К: Жил
Ч: а что, сейчас не живет?
К: Я не знаю.
Ч: тогда где он жил раньше?
К: у парка, на мэйпл стрит.
Ч: куда же он пропал?
К: куда он пропал?
Ч: я тебя спрашиваю, куда он пропал?
К: я не понимаю, почему я снова в больнице.
Ч: потому что ты болеешь
К: я просто хочу помогать людям.
Ч: Тогда скажи мне, где бегемот!
К: почему ты так сильно хочешь это знать?
Ч: просто ответь мне
К: ты хочешь, чтобы я помогла тебе попрощаться с родными?
Ч: Это угроза?
К: Наблюдение
Ч: Так где же все-таки бегемот?
К: он на гавайях, но радж управляет отсюда
Ч: Кто такой радж?
К: не встречалась с ним?
Ч: Нет, никогда
К: жили-были муж с женой, только муж каждую ночь исчезал.
Как можно поговорить с этим ботом в живую?
Я попробовал сделать android-приложение которое общается с сервером, на котором расположен бот. Приложение сырое, находится в стадии тестирования, чтобы его установить надо вступить в группу бета-тестировщиков:
plus.google.com/u/0/communities/103302070341792486151
После чего его можно установить с:
play.google.com/apps/testing/mindy.bot
PS
в настоящее время функция этого приложения — исследовательская. денег не берет, рекламы не показывает. Пока в приложении используется упрощенная модель, для уменьшения нагрузки на сервер.
PPS
Если модель попытается общаться на английском, просто отвечайте ей на русском, и она исправит свою ошибку.
plus.google.com/u/0/communities/103302070341792486151
После чего его можно установить с:
play.google.com/apps/testing/mindy.bot
PS
в настоящее время функция этого приложения — исследовательская. денег не берет, рекламы не показывает. Пока в приложении используется упрощенная модель, для уменьшения нагрузки на сервер.
PPS
Если модель попытается общаться на английском, просто отвечайте ей на русском, и она исправит свою ошибку.
Выводы:
Получилось забавно. Но все же видно низкое качестве обучающих данных. Для развития модели было бы полезно собрать больше реальных диалогов. Тем не менее, результаты обнадеживают, поскольку для получения довольно разумных ответов не потребовалось создавать вручную никаких шаблонов и правил выбора ответов.
