Привет, Хабр! Мы, наконец, дождались еще одной части серии материалов от выпускника наших программ “Специалист по большим данным” и “Deep Learning”, Кирилла Данилюка, об использовании популярных на сегодняшний день нейронных сетей Mask R-CNN как части системы для классификации изображений, а именно оценки качества приготовленного блюда по набору данных с сенсоров.
Рассмотрев в предыдущей статье игрушечный набор данных, состоящий из изображений дорожных знаков, теперь мы можем перейти к решению задачи, с которой я столкнулся в реальной жизни: «Возможно ли реализовать Deep Learning алгоритм, который мог бы отличить блюда высокого качества от плохих блюд по одной фотографии?». Вкратце, бизнес хотел вот это:
 Что представляет бизнес, когда думает о машинном обучении:
Что представляет бизнес, когда думает о машинном обучении:
Это пример некорректно поставленной задачи: в данном случае невозможно определить, существует ли решение, уникально и устойчиво ли оно. К тому же сама постановка задачи очень расплывчата, не говоря уже о реализации ее решения. Конечно, данная статья не посвящена эффективности коммуникаций или управлению проектами, однако важно отметить: никогда не беритесь за проекты, в которых конечный результат не определен и зафиксирован в ТЗ. Один из наиболее надежных способов справиться с такой неопределенностью — это сначала построить прототип, а затем, использовав новые знания, структурировать всю остальную задачу. Именно так мы и поступили.
В своем прототипе я сосредоточился на одном блюде из меню — омлете — и построил масштабируемый пайплайн, который на выходе определяет «качество» омлета. Подробнее это можно описать следующим образом:

Входные изображения
Главная цель пайплайна — научиться комбинировать несколько типов сигналов (например, изображения с разных ракурсов, теплокарту и т.д.), получив предварительно сжатое представление каждого из них и пропустив в дальнейшем эти фичи через нейросеть-классификатор для итогового предсказания. Так, мы сможем воплотить в жизнь наш прототип и сделать его практически применимым в дальнейшей работе. Ниже представлены несколько использованных в прототипе сигналов:
Отмечу, что мне придется пропустить несколько важных этапов, таких как разведочный анализ данных, построение базового классификатора и active labeling (мною предложенный термин, который обозначает полуавтоматическое аннотирование объектов, вдохновленный Polygon-RNN демо-видео) пайплайн для Mask R-CNN (подробнее об этом в следующих постах).
Взглянем на весь пайплайн в целом:
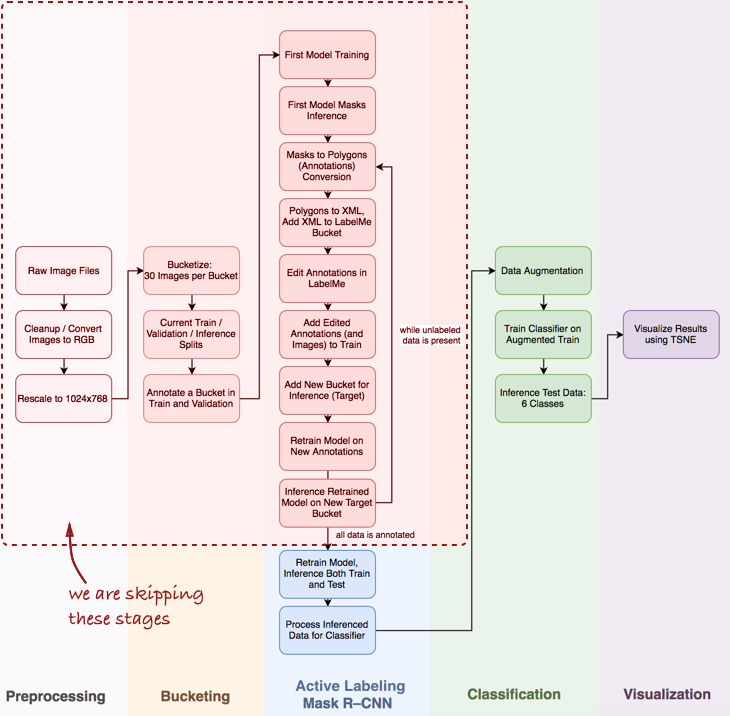
В данной статье нас интересуют этапы Mask R-CNN и классификации в рамках пайплайна
Далее мы рассмотрим три этапа: 1) использование Mask R-CNN для построения масок ингредиентов омлета; 2) ConvNet классификатор на основе Keras; 3) визуализация результатов, используя t-SNE.
Mask R-CNN (MRCNN) в последнее время находятся на пике популярности. Начиная от исходной статьи Facebook-а и заканчивая Data Science Bowl 2018 на Kaggle, Mask R-CNN зарекомендовала себя как мощная архитектура для instance segmentation (т.е., не только попиксельной сегментации изображений, но и отделения нескольких объектов, принадлежащих к одному классу). К тому же, одно удовольствие работать с реализацией MRCNN от Matterport в Keras. Код отлично структурирован, имеет хорошую документацию и работает прямо из коробки, хоть и медленнее, чем ожидалось.
На практике, особенно при разработке прототипа, критически важно иметь предобученную свёрточную нейросеть. В большинстве случаев набор размеченных данных у data scientist-а весьма ограничен, либо его нет совсем, в то время как ConvNet требует большого количества размеченных данных, чтобы достигнуть сходимости (так, набор данных ImageNet содержит 1,2 млн размеченных изображений). Тут на помощь приходит transfer learning: мы можем зафиксировать веса свёрточных слоев и дообучить лишь классификатор. Фиксировать свёрточные слои важно для небольших датасетов, поскольку такая техника предотвращает переобучение.
Вот что я получил после первой эпохи дообучения:
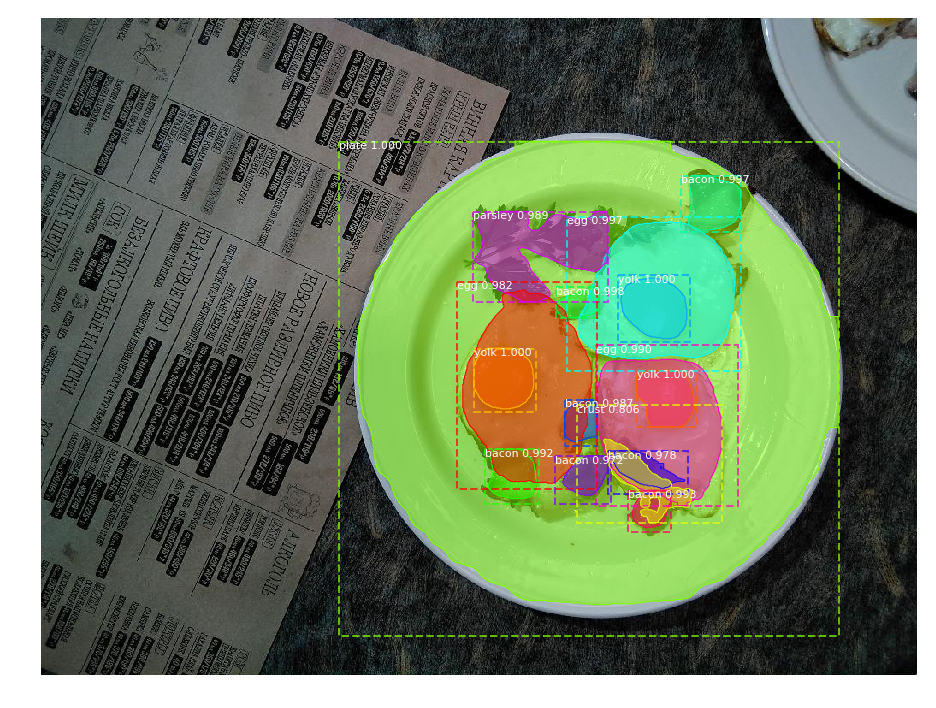
Результат сегментации объектов: распознаны все ключевые ингредиенты
На следующем этапе пайплайна (Process Inferenced Data for Classifier) необходимо вырезать ту часть изображения, которая содержит тарелку, и извлечь двумерную бинарную маску для каждого ингредиента на этой тарелке:

Кропы изображения с ключевыми ингредиентами в виде бинарных масок
Эти бинарные маски затем комбинируются в 8-канальное изображение (поскольку я определил 8 классов масок для MRCNN), и мы получаем Сигнал №1:

Сигнал №1: 8-канальное изображение, состоящее из бинарных масок. В цвете для лучшей визуализации
Чтобы получить Сигнал №2, я посчитал количество раз, которое каждый ингредиент встречается на кропе тарелки и получил набор векторов-признаков, каждый из которых соответствует своему кропу.
CNN классификатор был реализован с нуля, используя Keras. Я хотел скомбинировать несколько сигналов (Сигнал №1 и Сигнал №2, а также возможное добавление данных в будущем) и позволить нейросети по ним строить прогнозы относительно качества блюда. Ниже представленная архитектура является пробной и далека от идеала:
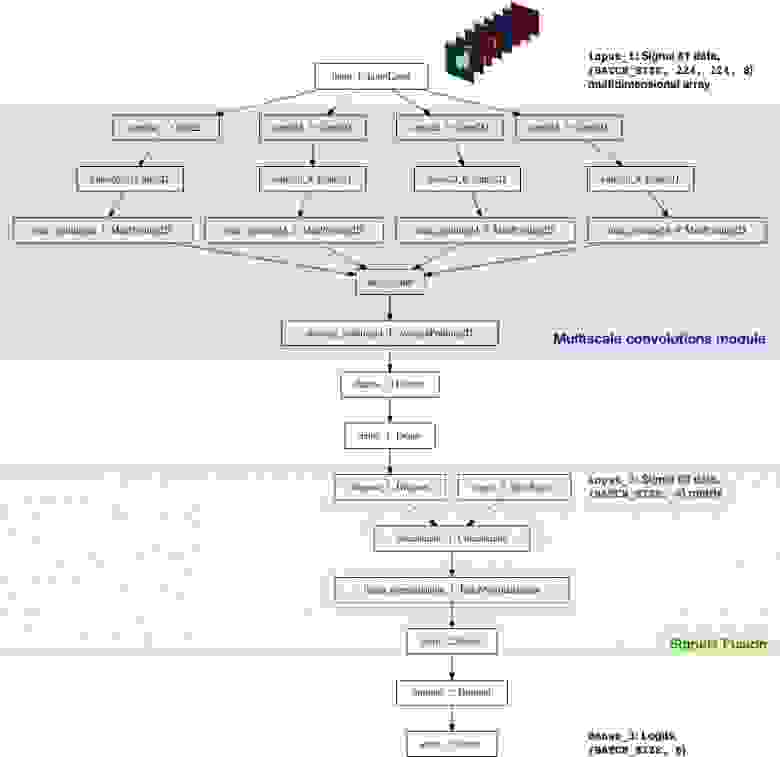
Несколько слов по поводу архитектуры классификатора:
Для визуализации результатов работы классификатора на тестовых данных я использовал t-SNE — алгоритм, который позволяет перенести исходные данные в пространство меньшей размерности (чтобы понять принцип работы алгоритма, рекомендую прочитать статью-первоисточник, она чрезвычайно информативна и хорошо написана).
Перед визуализацией я взял тестовые изображения, извлек логит-слой классификатора и применил к данному датасету алгоритм t-SNE. Хоть я и не пробовал различные значения параметра перплексии, результат все равно выглядит вполне неплохо:

Результат работы t-SNE на тестовых данных с предсказаниями классификатора
Конечно, данный подход неидеален, однако он работает. При этом возможных улучшений может быть довольно много:
Заключение. Нужно, наконец, признать, что у бизнеса нет ни данных, ни пояснений, ни тем более четко поставленной задачи, которую необходимо решить. И это хорошо (иначе, зачем им ты?), ведь твоя работа как раз и заключается в том, чтобы использовать различные инструменты, многоядерные процессоры, предобученные модели и смесь технической и бизнес-экспертизы для создания дополнительной ценности в компании.
Начните с малого: работающий прототип можно создать из нескольких игрушечных блоков кода, и он в разы увеличит продуктивность дальнейших бесед с руководством компании. В этом и заключается работа data scientist-а — предлагать бизнесу новые подходы и идеи.
20 сентября 2018 стартует “Специалист по большим данным 9.0”, где вы, помимо всего прочего, научитесь визуализировать данные и понимать бизнес-логику, скрывающуюся за той или иной задачей, что поможет эффективнее представлять результаты вашей работы коллегам и руководству.
Рассмотрев в предыдущей статье игрушечный набор данных, состоящий из изображений дорожных знаков, теперь мы можем перейти к решению задачи, с которой я столкнулся в реальной жизни: «Возможно ли реализовать Deep Learning алгоритм, который мог бы отличить блюда высокого качества от плохих блюд по одной фотографии?». Вкратце, бизнес хотел вот это:

Это пример некорректно поставленной задачи: в данном случае невозможно определить, существует ли решение, уникально и устойчиво ли оно. К тому же сама постановка задачи очень расплывчата, не говоря уже о реализации ее решения. Конечно, данная статья не посвящена эффективности коммуникаций или управлению проектами, однако важно отметить: никогда не беритесь за проекты, в которых конечный результат не определен и зафиксирован в ТЗ. Один из наиболее надежных способов справиться с такой неопределенностью — это сначала построить прототип, а затем, использовав новые знания, структурировать всю остальную задачу. Именно так мы и поступили.
Постановка задачи
В своем прототипе я сосредоточился на одном блюде из меню — омлете — и построил масштабируемый пайплайн, который на выходе определяет «качество» омлета. Подробнее это можно описать следующим образом:
- Тип задачи: мультиклассовая классификация с 6 дискретными классами качества: good (хороший), broken_yolk (с растекшимся желтком), overroasted (пережаренный), two_eggs (из двух яиц), four_eggs (из четырех яиц), misplaced_pieces (с разбросанными по тарелке кусочками).
- Набор данных: 351 вручную собранных фотографий различных омлетов. Обучающая/валидационная/тестовая выборки: 139/32/180 перемешанных фотографий.
- Метки классов: каждой фотографии соответствует метка класса, соответствующая субъективной оценке качества омлета.
- Метрика: категориальная кросс-энтропия.
- Минимальные доменные знания: «качественный» омлет должен выглядеть следующим образом: он состоит из трех яиц, небольшого количества бекона, листа петрушки в центре, не имеет растекшихся желтков и пережаренных кусочков. Также общая композиция должна “выглядеть хорошо”, то есть кусочки не должны быть разбросаны по всей тарелке.
- Критерий завершения работы: наилучшее значение кросс-энтропии на тестовой выборке среди всех возможных после двух недель разработки прототипа.
- Способ итоговой визуализации: t-SNE на пространстве данных меньшей размерности.

Входные изображения
Главная цель пайплайна — научиться комбинировать несколько типов сигналов (например, изображения с разных ракурсов, теплокарту и т.д.), получив предварительно сжатое представление каждого из них и пропустив в дальнейшем эти фичи через нейросеть-классификатор для итогового предсказания. Так, мы сможем воплотить в жизнь наш прототип и сделать его практически применимым в дальнейшей работе. Ниже представлены несколько использованных в прототипе сигналов:
- Маски ключевых ингредиентов (Mask R-CNN): Сигнал №1.
- Число ключевых ингредиентов на кадре., Сигнал №2.
- RGB-кропы тарелок с омлетом без заднего плана. Для простоты, я решил пока не добавлять их в модель, хотя они являются наиболее очевидным сигналом: в дальнейшем можно обучить свёрточную нейросеть для классификации, используя какую-нибудь адекватную функцию потерь типа triplet loss, посчитать эмбеддинги изображений и провести отсечение по L2 расстоянию от текущего изображения до идеального. К сожалению, у меня не было возможности проверить эту гипотезу, поскольку тестовая выборка состояла лишь из 139 объектов.
Общий взгляд на пайплайн
Отмечу, что мне придется пропустить несколько важных этапов, таких как разведочный анализ данных, построение базового классификатора и active labeling (мною предложенный термин, который обозначает полуавтоматическое аннотирование объектов, вдохновленный Polygon-RNN демо-видео) пайплайн для Mask R-CNN (подробнее об этом в следующих постах).
Взглянем на весь пайплайн в целом:
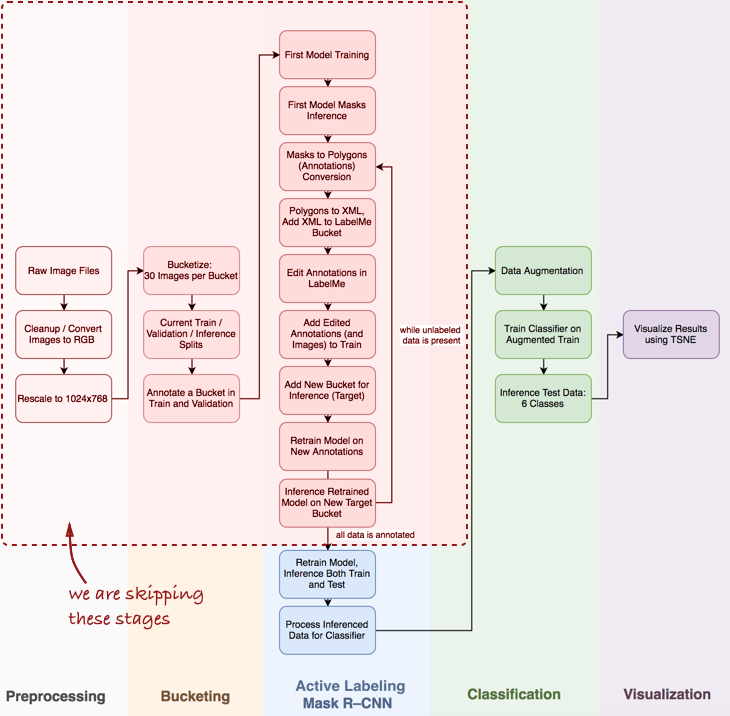
В данной статье нас интересуют этапы Mask R-CNN и классификации в рамках пайплайна
Далее мы рассмотрим три этапа: 1) использование Mask R-CNN для построения масок ингредиентов омлета; 2) ConvNet классификатор на основе Keras; 3) визуализация результатов, используя t-SNE.
Этап 1: Mask R-CNN и построение масок
Mask R-CNN (MRCNN) в последнее время находятся на пике популярности. Начиная от исходной статьи Facebook-а и заканчивая Data Science Bowl 2018 на Kaggle, Mask R-CNN зарекомендовала себя как мощная архитектура для instance segmentation (т.е., не только попиксельной сегментации изображений, но и отделения нескольких объектов, принадлежащих к одному классу). К тому же, одно удовольствие работать с реализацией MRCNN от Matterport в Keras. Код отлично структурирован, имеет хорошую документацию и работает прямо из коробки, хоть и медленнее, чем ожидалось.
На практике, особенно при разработке прототипа, критически важно иметь предобученную свёрточную нейросеть. В большинстве случаев набор размеченных данных у data scientist-а весьма ограничен, либо его нет совсем, в то время как ConvNet требует большого количества размеченных данных, чтобы достигнуть сходимости (так, набор данных ImageNet содержит 1,2 млн размеченных изображений). Тут на помощь приходит transfer learning: мы можем зафиксировать веса свёрточных слоев и дообучить лишь классификатор. Фиксировать свёрточные слои важно для небольших датасетов, поскольку такая техника предотвращает переобучение.
Вот что я получил после первой эпохи дообучения:

Результат сегментации объектов: распознаны все ключевые ингредиенты
На следующем этапе пайплайна (Process Inferenced Data for Classifier) необходимо вырезать ту часть изображения, которая содержит тарелку, и извлечь двумерную бинарную маску для каждого ингредиента на этой тарелке:

Кропы изображения с ключевыми ингредиентами в виде бинарных масок
Эти бинарные маски затем комбинируются в 8-канальное изображение (поскольку я определил 8 классов масок для MRCNN), и мы получаем Сигнал №1:

Сигнал №1: 8-канальное изображение, состоящее из бинарных масок. В цвете для лучшей визуализации
Чтобы получить Сигнал №2, я посчитал количество раз, которое каждый ингредиент встречается на кропе тарелки и получил набор векторов-признаков, каждый из которых соответствует своему кропу.
Этап 2: ConvNet классификатор в Keras
CNN классификатор был реализован с нуля, используя Keras. Я хотел скомбинировать несколько сигналов (Сигнал №1 и Сигнал №2, а также возможное добавление данных в будущем) и позволить нейросети по ним строить прогнозы относительно качества блюда. Ниже представленная архитектура является пробной и далека от идеала:

Несколько слов по поводу архитектуры классификатора:
- Multiscale сверточный модуль: первоначально я выбрал фильтр 5х5 для сверточных слоев, однако это привело лишь к удовлетворительному результату. Улучшения удалось добиться за счет применения AveragePooling2D к нескольким слоям с различными фильтрами: 3x3, 5х5, 7х7, 11х11. Также был добавлен дополнительный свёрточный слой размера 1х1 перед каждым из слоев, чтобы уменьшить размерность. Данная компонента немного напоминает Inception модуль, хоть я и не планировал строить слишком глубокую сеть.
- Фильтры большего размера: я использовал фильтры большего размера, поскольку они помогают легче извлекать признаки большего масштаба из входного изображения (которое само по сути является слоем активации с 8 фильтрами — маску каждого ингредиента можно рассматривать как отдельный фильтр).
- Объединение сигналов: в моей наивной реализации использовался только один слой, который соединял два набора признаков: обработанные бинарные маски (Сигнал №1) и подсчитанные ингредиенты (Сигнал №2). Однако, несмотря на простоту, добавление Сигнала №2 позволило уменьшить метрику кросс-энтропии с 0.8 до [0.7, 0.72].
- Логиты: в терминах TensorFlow, логит — это слой, на котором применяется tf.nn.softmax_cross_entropy_with_logits, чтобы рассчитать batch loss.
Этап 3: визуализация результатов с помощью t-SNE
Для визуализации результатов работы классификатора на тестовых данных я использовал t-SNE — алгоритм, который позволяет перенести исходные данные в пространство меньшей размерности (чтобы понять принцип работы алгоритма, рекомендую прочитать статью-первоисточник, она чрезвычайно информативна и хорошо написана).
Перед визуализацией я взял тестовые изображения, извлек логит-слой классификатора и применил к данному датасету алгоритм t-SNE. Хоть я и не пробовал различные значения параметра перплексии, результат все равно выглядит вполне неплохо:
Результат работы t-SNE на тестовых данных с предсказаниями классификатора
Конечно, данный подход неидеален, однако он работает. При этом возможных улучшений может быть довольно много:
- Больше данных. Свёрточные сети требуют очень много данных, а у меня было всего 139 изображений для обучения. Такие приемы как аугментация данных работают отлично (я использовал D4 или двугранную симметричную аугментацию, в результате чего получилось более 2 тысяч изображений), но наличие большего количества реальных данных все-таки чрезвычайно важно.
- Более подходящая функция потерь. Для простоты я использовал категориальную кросс-энтропию, которая хороша тем, что работает прямо из коробки. Оптимальным вариантом было бы использование функции потерь, которая учитывает вариацию внутри классов, к примеру, триплетная функция потерь (см. статью FaceNet).
- Улучшение архитектуры классификатора. Текущий классификатор — это по сути прототип, единственная цель которого — построить бинарные маски и скомбинировать несколько наборов признаков, чтобы сформировать единый пайплайн.
- Улучшение разметки изображений. Я был весьма небрежен при разметке изображений вручную: классификатор справился с этой работой лучше меня на дюжине тестовых изображений.
Заключение. Нужно, наконец, признать, что у бизнеса нет ни данных, ни пояснений, ни тем более четко поставленной задачи, которую необходимо решить. И это хорошо (иначе, зачем им ты?), ведь твоя работа как раз и заключается в том, чтобы использовать различные инструменты, многоядерные процессоры, предобученные модели и смесь технической и бизнес-экспертизы для создания дополнительной ценности в компании.
Начните с малого: работающий прототип можно создать из нескольких игрушечных блоков кода, и он в разы увеличит продуктивность дальнейших бесед с руководством компании. В этом и заключается работа data scientist-а — предлагать бизнесу новые подходы и идеи.
20 сентября 2018 стартует “Специалист по большим данным 9.0”, где вы, помимо всего прочего, научитесь визуализировать данные и понимать бизнес-логику, скрывающуюся за той или иной задачей, что поможет эффективнее представлять результаты вашей работы коллегам и руководству.
