[Часть 1 из 2]

Блог Hike появился 12 декабря 2012 года, и читателей тогда было совсем немного. К 2016 году мы достигли цифр в 100 миллионов зарегистрированных пользователей и 40 миллиардов сообщений ежемесячно. Но такой рост обозначил проблему, связанную с масштабированием нашей инфраструктуры. Для ее устранения нам нужна была высокопроизводительная платформа по приемлемой цене. В 2016 и 2017 годах мы столкнулись с многочисленными перебоями в работе, с этим нужно было срочно что-то делать, поэтому мы начали рассматривать различные варианты.
Нам нужна была такая облачная платформа, которая помогла бы быстро создавать, тестировать и развертывать приложения в масштабируемой и надежной облачной среде. На первый взгляд может показаться, что все крупные облачные платформы схожи во многих отношениях, однако у них есть несколько принципиальных различий.
Мы разделим эту публикацию на 2 части:
- Причина для выбора GCP
- Переход на GCP без простоев
Подтверждение концепции
Мы начали с доказательства правильности концепции, в рамках которого рассматривали совместимость существующей инфраструктуры с сервисами, предлагаемыми облачной платформой Google Cloud, а также планировали элементы для будущего развития.
Ключевые области в рамках подтверждения концепции:
⊹ Балансировщик нагрузки
⊹ Вычислительная машина
⊹ Работа в сети и брандмауэры
⊹ Безопасность
⊹ Доступность облачных ресурсов
⊹ Большие данные
⊹ Тарификация
Подтверждение концепции включало в себя тестирование и проверку пропускной способности виртуальных машин/сети/балансировщика нагрузки, а также стабильности, масштабируемости, безопасности, мониторинга, тарификации, больших данных и сервисов машинного обучения. В июне 2017 года мы приняли важное решение о переносе всей инфраструктуры на облачную платформу Google Cloud.
Мы хотели выбрать облачную платформу, способную справиться с бесчисленными проблемами, с которыми мы столкнулись:
⊹ Балансировщик нагрузки:
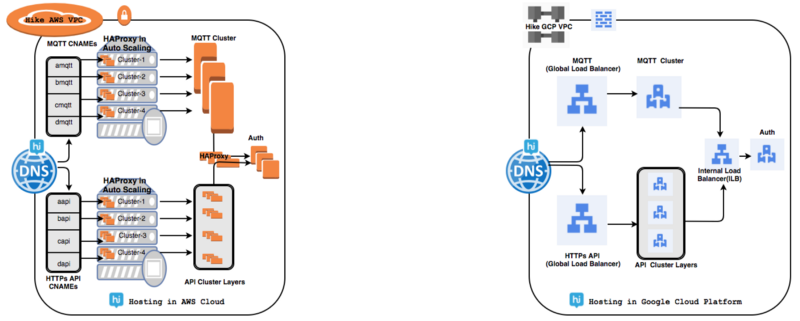
У нас было множество проблем, связанных с управлением локальными кластерами HAProxy для обработки нескольких десятков миллионов подключений активных пользователей ежедневно. Глобальный балансировщик нагрузки (GLB) решил множество наших проблем.

Используя глобальную балансировку нагрузки GCP, один IP-адрес anycast может пересылать до 1 миллиона запросов в секунду на различные сервера GCP, такие как Группы управляемых экземпляров (Managed Instance Groups – MIG), и для этого не требуется «предварительного прогрева». Наше общее время отклика улучшилось в 1,7–2 раза, поскольку GLB использует реализацию пула, которая позволяет распределять трафик по множеству источников.
⊹ Вычислительная машина:
В самих по себе вычислительных машинах не было больших проблем, но нам нужна была высокопроизводительная платформа по приемлемой цене. Общая пропускная способность виртуальных машин Google увеличилась в 1,3-1,5 раза, что позволило сократить общее количество запущенных экземпляров виртуальных машин.
Тесты Redis проводились с кластером из 6 экземпляров (8 ядер, 30 ГБ каждый). На основе приведенных ниже результатов мы пришли к выводу, что GCP обеспечивает повышение производительности до 48% (в среднем) для большинства операций REDIS и до 77% для конкретных операций REDIS.
redis-benchmark -h -p 6379 -d 2048 -r 15 -q -n 10000000 -c 100

Сервис облачных вычислений Google Compute Engine (GCE) обеспечил дополнительные преимущества в управлении нашей инфраструктурой благодаря использованию следующего:
● Группа управляемых экземпляров (MIG): MIG помогают нам поддерживать работу служб приложений в надежной среде с многозональными функциями вместо выделения ресурсов для каждой зоны. MIG автоматически идентифицирует и корректирует неработоспособные экземпляры в группе для обеспечения оптимальной работы всех экземпляров.
● Динамическая миграция: Динамическая миграция помогает поддерживать работу экземпляров виртуальных машин даже в случае сбоя хост-системы, например, при обновлении программного обеспечения или оборудования. Работая с нашим предыдущим облачным партнером, мы получали уведомление о запланированном событии технического обслуживания и были вынуждены останавливать и запускать виртуальную машину, чтобы перейти на работоспособную виртуальную машину.
● Пользовательские виртуальные машины: В рамках GCP мы можем создавать собственные виртуальные машины с необходимыми для конкретных рабочих нагрузок вычислительной мощностью процессора и объемом памяти.
⊹ Работа в сети и брандмауэры:
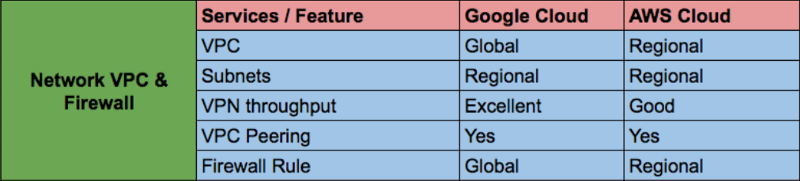
Управлять несколькими сетями и правилами брандмауэра непросто и может привести к риску. Сетевой VPC GCP по умолчанию является глобальным и обеспечивает межрегиональную связь без дополнительной настройки и без изменений пропускной способности сети. Правила брандмауэра обеспечивают гибкость в рамках VPC для проектов, использующих имя правила тегов.
Для сети с низкой задержкой и более высокой пропускной способностью мы были вынуждены выбирать дорогостоящие экземпляры с пропускной способность в 10Гбит/с и активировали расширенные сети на этих экземплярах.
⊹ Безопасность:
Безопасность — самый важный аспект для любого поставщика облачных сервисов. В прошлом безопасность была либо недоступна для большинства сервисов, либо была лишь дополнительным вариантом.
Облачные сервисы Google по умолчанию зашифрованы. Для защиты данных GCP использует несколько уровней шифрования. Использование нескольких уровней шифрования обеспечивает защиту резервируемых данных и позволяет выбрать оптимальный подход, основанный на требованиях приложений, например, использование сервиса Identity-Aware Proxy и шифрование неактивных данных по умолчанию.
Кроме того, GCP закрывает недавние катастрофические уязвимости, основанные на спекулятивном выполнении, в подавляющем большинстве современных процессоров (Meltdown, Spectre). Google разработал новый метод бинарной модификации, называемый Retpoline, который позволяет обойти эту проблему и прозрачно внести изменения во всю работающую инфраструктуру незаметно для пользователей.
⊹ Доступность облачных ресурсов:
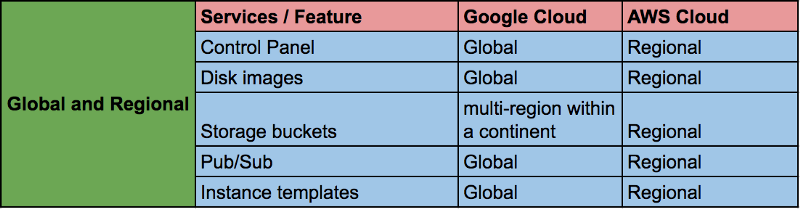
Доступность ресурсов GCP отличается от таковой у других поставщиков облачных решений, так как большинство ресурсов GCP, включая панель управления, являются либо зональными, либо региональными. Нам приходилось управлять несколькими VPC для отдельных проектов из отдельных учетных записей, которым требовались пиринг VPC или VPN-соединение для частного подключения. Нам также приходилось держать копию образа в отдельной учетной записи.
В облаке Google Cloud большинство ресурсов являются либо глобальными, либо региональными. К таким ресурсам относятся панель управления (где мы можем видеть все виртуальные машины нашего проекта на одном экране), образы дисков, контейнеры для хранения данных (несколько регионов в рамках континента), VPC (но отдельные подсети являются региональными), глобальная балансировка нагрузки, публикация и подписка и т. д.
⊹ Большие данные:
Мы перешли от монолитной, трудноуправляемой аналитической конфигурации к полностью управляемой системе с BQ, что привело к улучшениям в трех областях:
● Увеличение скорости обработки запросов до 50 раз.
● Полностью управляемые системы обработки данных с автоматическим масштабированием.
● Время обработки данных сократилось с часов до 15 минут.
⊹ Тарификация:
Было трудно сравнивать различных поставщиков облачных сервисов, поскольку многие сервисы не были похожи или сопоставимы, различались для разных сценариев использования и зависели от уникальных сценариев использования.
Преимущества GCP:
● Скидки за длительное использование: Применяются при нарастающем использовании виртуальных машин при достижении определенных пороговых значений. Мы можем автоматически получить скидку до 30% на рабочие нагрузки, которые выполняются в течение большей части учетного месяца.
● Поминутная тарификация: При выделении виртуальной машины в GCE взимается плата за минимальный период 10 минут, после чего начинается поминутная тарификация за фактическое использование виртуальной машины. Это обеспечивает значительное снижение затрат, поскольку нам не приходится оплачивать полный час, даже если экземпляр машины работает менее часа.
● Превосходное оборудование, меньшее количество экземпляров: Мы обнаружили, что почти для всех уровней и приложений с помощью GCP можно выполнять ту же рабочую нагрузку с одинаковой производительностью, но меньшим количеством экземпляров.
● Обязательство, а не резервирование: Еще одним фактором является подход GCP к цене экземпляров виртуальных машин. В AWS основным способом сокращения затрат на экземпляр виртуальной машины является покупка зарезервированных экземпляров сроком на 1–3 года. Если рабочая нагрузка требовала изменения конфигурации виртуальной машины или данный экземпляр был нам не нужен, нам приходилось продавать его на рынке зарезервированных экземпляров по более низкой цене. В GCP есть «Скидка за обязательство по использованию», которая действует при резервировании ресурсов процессора и памяти, при этом не имеет значения, какие экземпляры виртуальной машины мы используем.
Заключение:
Исходя из этого подробного анализа, мы решили перейти на GCP и начали работать над схемой перехода и контрольными списками. В следующей статье мы расскажем о том, что узнали в ходе выполнения этого проекта.
