Всем привет.
По роду своей профессиональной деятельности я занимаюсь внедрением проектов на основе речевых технологий. Это синтез и распознавание речи, голосовая биометрия и анализ речи.
Мало кто задумывается, насколько эти технологии уже присутствуют в нашей жизни, хоть и далеко не всегда – явно.
Постараюсь популярно объяснить вам, как это работает и зачем это вообще нужно.
Подробно начну с распознавания речи, т.к. это более близкая к повседневной жизни штука, с которой многие из нас встречались, а некоторые уже постоянно пользуются.
Но для начала попробуем разобраться в том, что же такое речевые технологии вообще и какими они могут быть.
— Синтез речи (перевод текста в речь).
С этой технологией мы пока мало сталкиваемся в реальной жизни. Или просто не замечаем ее.
Есть специальные «читалки» для iOS и Android, способные читать вслух книги, которые вы загружаете в устройство. Читают вполне сносно, через день-два уже не замечаешь, что текст читает робот.
Во многих колл-центрах динамическую информацию абонентам озвучивает синтезированный голос, т.к. записать заранее все звуковые ролики, озвученные человеком, достаточно сложно, особенно если информация меняется каждые 3 секунды
Например, в Метрополитене Санкт-Петербурга многие информационные сообщения на станциях читает именно синтез, но почти никто этого не замечает, т.к. текст звучит довольно-таки неплохо.
— Голосовая биометрия (поиск и подтверждение личности по голосу).
Да, да — голос человека также уникален, как отпечаток пальцев или сетчатка глаза. Надежность верификации (сличения двух отпечатков голоса) достигает 98%. Для этого анализируется 74 параметра голоса.
В повседневной жизни технология пока встречается очень редко. Но тенденции говорят о том, что скоро это будет распространено повсеместно, особенно в колл-центрах финансовых компаний. Интерес с их стороны к этой технологии очень большой.
У голосовой биометрии есть 2 уникальные особенности:
— это единственная технология, которая позволяет подтверждать личность удаленно, например, по телефону. И для этого не нужны специальные сканирующие устройства.
— это единственная технология, которая подтверждает активность человека, т.е. то, что по телефону разговаривает живой человек. Сразу скажу, что записанный на качественный диктофон голос не сработает – доказано. Если где-то такая запись «пройдет», значит в систему заложен изначально низкий порог «доверия».
— Анализ речи.
Мало кто знает, что по голосу можно определить настроение человека, его эмоциональное состояние, пол, примерный вес, национальную принадлежность и т.д.
Конечно, никакая машина не сможет сразу сказать, грустит человек или радуется (вполне возможно, что у него всегда по жизни такое состояние: например, среднестатистическая речь итальянца и финна очень отличаются по темпераменту), но по изменению голоса в процессе разговора, определить это уже вполне реально.
— Распознавание речи (перевод речи в текст).
Это самая распространенная речевая технология в нашей жизни, и в первую очередь — благодаря мобильным устройствам, т.к. многие производители и разработчики считают, что сказать что -то в смартфон человеку гораздо удобнее, чем набрать этот же текст на маленькой клавиатуре экрана.
Предлагаю вначале поговорить вот о чем: где мы встречаемся с технологией распознавания речи в жизни и откуда вообще мы о ней знаем?
Большинство из нас сразу вспомнят Siri (iPhone), Голосовой поиск Google, иногда — IVR системы с голосовым управлением в некоторых колл-центрах, например РЖД, Аэрофлот и т.д.
Это то, что лежит на поверхности, и то, что вы легко можете попробовать сами.
Существует распознавание речи, встроенное в систему автомобиля (набор телефонного номера, управление магнитолой), в телевизоры, инфоматы (штуки, похожие на те, которые принимают деньги за мобильных операторов). Но это мало распространено и практикуется больше как «фишка» определенных производителей. Дело даже не в технических ограничениях и качестве работы, а в удобстве пользования и привычках людей. Я плохо представляю себе человека, который голосом листает программы на телевизоре, когда под рукой есть пульт ДУ.
Итак. Технология распознавания речи. Какие они бывают?
Сразу хочу сказать, что почти вся моя работа связана с телефонией, поэтому многие примеры по тексту ниже будут взяты именно оттуда – из практики работы колл-центров.
Распознавание по закрытым грамматикам.
Распознавание одного слова (голосовой команды) из списка слов (базы).
Понятие «закрытые грамматики» означает, что в систему заложена определенная конечная база слов, в которой система будет искать произнесенное абонентом слово или выражение.
В этом случае система должна поставить вопрос абоненту так, что бы получить однозначный ответ, состоящий из одного слова.
Пример:
Вопрос системы: «Какой день недели вас интересует?»
Ответ абонента: «Вторник»
В этом примере вопрос поставлен так, что система ожидает совершенно определенный ответ от абонента.
База слов в приведенном примере может состоять из следующих вариантов ответа: «понедельник, вторник, среда, четверг, пятница, суббота, воскресенье». Также следует предусмотреть и заложить в базу следующие варианты ответов: «не знаю», «все равно», «любой» и т.д. — эти ответы абонента должны также предусматриваться и обрабатываться системой отдельно, согласно заранее заложенным сценарием диалога.
Встроенные грамматики.
Это разновидность закрытых грамматик.
Распознавание часто запрашиваемых стандартных выражений и понятий.
Понятие «встроенные грамматики» означает, что в систему уже заложены грамматики (т.е. ее не нужно отдельно «обучать»), которые способны распознавать конкретные тематические фразы абонента. При составлении сценария диалога, необходимо просто сослаться на определенную встроенную грамматику.
Пример:
Вопрос системы: «В какое время фильм Вас интересует?»
Ответ абонента: «В 15.30»
В приведенном примере распознается значения времени. Вся необходимая грамматика по распознаванию времени уже заложена в систему.
Встроенные грамматики служат для упрощения разработки голосовых меню, когда можно использовать стандартные универсальные блоки.
Распознавание по открытым грамматикам.
Распознавание всей произнесенной абонентом фразы целиком.
Это позволяет системе задать абоненту открытый вопрос и получить ответ, сформулированный в свободной форме.
Понятие «открытые грамматики» означает, что система ожидает услышать от абонента не конкретное слово/команду, а все смысловое предложение целиком, в котором систему будет интересовать каждое слово.
Пример:
Вопрос системы: «Что вас интересует?»
Ответ абонента: «Какие документы нужны для кредита?»
В этом примере распознается каждое слово в ответе абонента и выявляется общий смысл сказанного. На основании распознанных ключевых слов и понятий в предложении формируется запрос в базу данных и «собирается» ответ абоненту – предоставляется справочная информация.
Распознавание слитной речи дает системе много больше возможностей для автоматизации процесса диалога с абонентом. Плюс к этому возрастает скорость и удобство пользования системой со стороны абонента. Но такие системы сложнее в реализации. Если решение задачи может подразумевать односложные ответы абонента, то лучше применять закрытые грамматики.
Они надежнее работают, такие системы просты в реализации и более привычны для абонентов, которые привыкли пользоваться DTMF набором (навигация с помощью донабора номера в тоновом режиме).
Но будущее, конечно, за слитным распознаванием речи. Постепенно и пользователи к этому привыкнут и не будут «подвисать» на 5-10 секунд, когда система предлагает им вступить в открытый диалог с ней.
Как работает IVR система с распознаванием слитной речи?
На примере ПО VoiceNavigator — синтез и распознавание русской речи для IVR системы.
! Осторожно. Дальше будет более сложный текст для понимания.
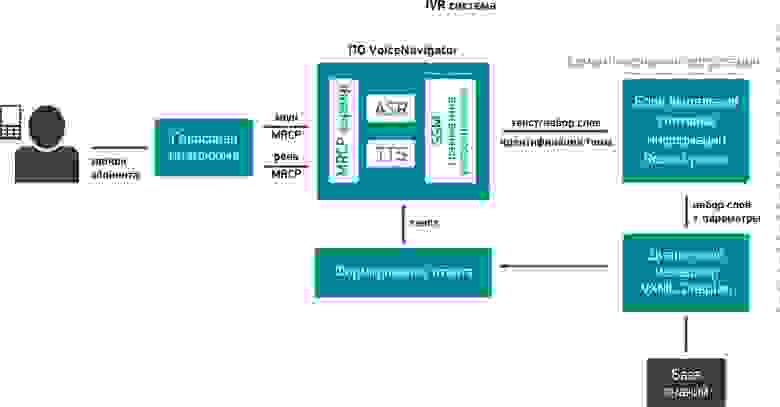
1.Сразу остановимся на том, что вызов абонента пришел в колл-центр и был переведен на голосовую платформу. Голосовая платформа – это ПО, которое занимается отработкой всей логики диалога абонента с системой, т.е. на голосовой платформе работает IVR меню. Наиболее популярные голосовые платформы: Avaya, Genesys, Cisco и Asterisk.
Итак, голосовая платформа передает в VoiceNavigator звук с микрофона телефона абонента.
2.Звук попадает в модуль распознавания речи (ASR), который преобразует речь человека в текст в виде последовательности отдельно составленных слов. Полученные слова не имеют для системы пока никакого смысла.
Пример голосовой фразы абонента по теме расписания поездов:

3.Далее текст попадает в модуль SSM грамматики распознавания (на том, что это такое, здесь останавливаться не буду, кто захочет углубиться в тематику, сможет найти сам. Это будет касаться и остальных терминов ниже по тексту), где полученные слова анализируются на предмет тематики высказывания (к какой теме относится распознанная фраза). В нашем примере распознанная фраза относится к теме: «Поезда дальнего следования» и имеет свой уникальный идентификатор.
4.Затем текст вместе с идентификатором темы передается в модуль выделения слотовой информации (robust parser), в котором выделяются определенные понятия и выражения, важные для данной предметной области (смысл высказывания пользователя). В этом модуле система «понимает», что сказал абонент и анализирует, достаточно ли данной информации для формирования запроса в базу знаний или требуются уточняющие вопросы.
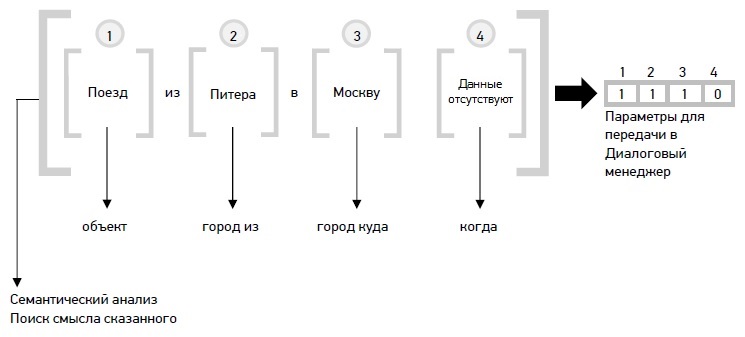
Модуль выделения слотовой информации формирует определенные параметры, которые передаются далее в диалоговый менеджер вместе с распознанными словами.
5.Диалоговый менеджер занимается обработкой всей логики (алгоритма) ведения диалога IVR системы с абонентом. На основании переданных параметров, диалоговый менеджер может отправить запрос в базу знаний (в речи абонента содержится вся информация) для формирования ответа абоненту или запросить у абонента дополнительную информацию, уточнить запрос (в речи абонента содержится не вся информация).
6.Для формирования ответа абоненту диалоговый менеджер обращается в базу знаний. Она содержит всю информацию по предметной области.
7.Далее система формирует ответ абоненту на основании информации из базы знаний и согласно сценарию диалога из диалогового менеджера.
8.После предоставления ответа абоненту, IVR система готова к продолжению работы.
С чего следует начать при создании IVR системы на основе распознавания речи?
Обучение системы распознавания слитной речи.
1.Основой распознавания слитной речи является статистика. Поэтому любой проект по внедрению IVR системы с применением распознавания слитной речи начинается со сбора статистики. Необходимо знать, что интересует абонентов, как они формулируют вопросы, какой информацией изначально обладают, что ожидают услышать в ответ и т.д.
Сбор информации начинается с прослушивания и анализа реальных записей разговоров абонентов с операторами КЦ. На основе этой информации строятся статистические таблицы, из которых становится понятным, какие голосовые запросы абонентов необходимо автоматизировать, и как это можно сделать.
2.Этой информации становится достаточно для создания упрощенного прототипа будущего IVR меню. Такой прототип необходим для сбора и анализа более релевантных ответов абонентов на вопросы IVR меню, т.к. манера общения абонентов с операторами КЦ и с речевыми IVR меню сильно отличается.
Созданный прототип IVR меню размещается на входящем номере телефона в компанию. Он может быть максимально упрощен или вообще не отрабатывать заложенный функционал, т.к. его основная задача заключается в накоплении статистического материала (всевозможных ответов абонентов), который будет являться основой для формирования статистической языковой модели (SLM) направленной на определенную тематику. Гибкость языковой модели для конкретной предметной области позволяет улучшить качество распознавания.
Пример реализации прототипа IVR меню:
Вопрос системы: «Какая услуга Вас интересует?»
Ответ абонента: «Я хотел бы взять кредит»
Ответ системы: «Вызов будет переведен на оператора контактного центра»
Действия системы: Перевод на оператора КЦ при любом ответе абонента.
С помощью прототипа IVR меню, разработчик создает эмуляцию работы системы и собирает реальные записи ответов абонентов (сбор фонограмм), по которым впоследствии будет обучаться система.
Не имеет значение, что произнесет абонент на вопрос системы, вызов в любом случае будет переведен на оператора контактного центра. Таким образом, абонент будет обслужен без причинения ему неудобств, а разработчики IVR меню получать базу всех возможных вариантов ответов по данной тематике на примере реального диалога.
Необходимое количество фонограмм для реализации проекта может достигать нескольких тысяч, а время для сбора фонограмм может занять несколько месяцев. Все зависит от сложности проекта.
3.Затем собранные записи разговоров транскрибируются. Каждая запись прослушивается специалистом и переводится в текст. Транскрибированные фразы не должны содержать пунктуационные знаки и специальные символы. Также все слова и аббревиатуры должны быть прописаны полностью, как их произносит клиент. Данная работа занимает достаточно много времени, но не требует специфических знаний, поэтому к работе обычно одновременно привлекается сразу много сотрудников.
4.Транскрибированные файлы служат для построения тренировочного файла (словарь слов и выражений, конфигурационные параметры), который представляет собой XML документ. Чем объемней будет тренировочный файл по предметной области, тем более качественным будет распознавание.
Тренировочный файл позволяет сформировать языковую модель (SLM), которая является основой распознавания слитной речи.
Для этого тренировочный файл загружается в специальную утилиту, разработанную компанией ЦРТ (именно она является автором ПО VoiceNavigator) – ASR Конструктор, который строит языковую модель. Затем языковая модель загружается в программное обеспечение VoiceNavigator.
На данном этапе работы по построению речевого IVR меню, система способна распознавать речь абонента в виде отдельно составленных слов, не связанных друг с другом.
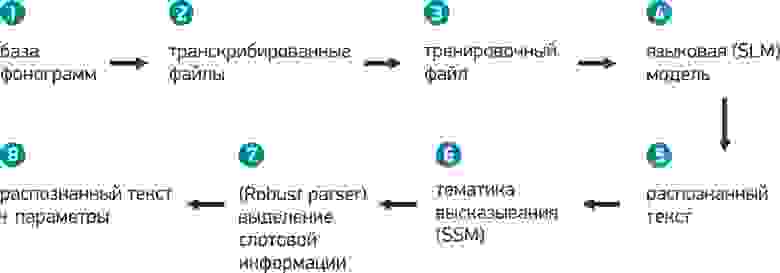
5.Затем в распознанном списке слов необходимо выявить тему обращения абонента (SSM грамматика распознавания) и выделить слотовую информацию (Robust parser). Для этого требуется дополнительное обучение системы с помощью соответствующих тренировочных файлов.
Тренировочные файлы могут быть созданы на основе уже полученных ранее транскрибированных файлов. Но в отличие от задачи по получению языковой модели, транскрибированные файлы должны быть соответствующим образом доработаны под их пригодность для SSM грамматики и Robust parser.
Что же, начало статьи получилось достаточно простым для понимания тех, кто вообще не знаком с речевыми технологиями. А потом я с головой окунулся в тонкости создания реальных систем голосового самообслуживания. Прошу прощения за такие метаморфозы.
Кого заинтересовала данная тема, и он хочет больше узнать про создание IVR систем с голосовым управлением, хочу порекомендовать посетить специальный wiki сайт – www.vxml.ru
Он посвящен разработке IVR систем на диалоговом языке VoiceXML, который является основным в данной работе.
Спасибо.
По роду своей профессиональной деятельности я занимаюсь внедрением проектов на основе речевых технологий. Это синтез и распознавание речи, голосовая биометрия и анализ речи.
Мало кто задумывается, насколько эти технологии уже присутствуют в нашей жизни, хоть и далеко не всегда – явно.
Постараюсь популярно объяснить вам, как это работает и зачем это вообще нужно.
Подробно начну с распознавания речи, т.к. это более близкая к повседневной жизни штука, с которой многие из нас встречались, а некоторые уже постоянно пользуются.
Но для начала попробуем разобраться в том, что же такое речевые технологии вообще и какими они могут быть.
— Синтез речи (перевод текста в речь).
С этой технологией мы пока мало сталкиваемся в реальной жизни. Или просто не замечаем ее.
Есть специальные «читалки» для iOS и Android, способные читать вслух книги, которые вы загружаете в устройство. Читают вполне сносно, через день-два уже не замечаешь, что текст читает робот.
Во многих колл-центрах динамическую информацию абонентам озвучивает синтезированный голос, т.к. записать заранее все звуковые ролики, озвученные человеком, достаточно сложно, особенно если информация меняется каждые 3 секунды
Например, в Метрополитене Санкт-Петербурга многие информационные сообщения на станциях читает именно синтез, но почти никто этого не замечает, т.к. текст звучит довольно-таки неплохо.
— Голосовая биометрия (поиск и подтверждение личности по голосу).
Да, да — голос человека также уникален, как отпечаток пальцев или сетчатка глаза. Надежность верификации (сличения двух отпечатков голоса) достигает 98%. Для этого анализируется 74 параметра голоса.
В повседневной жизни технология пока встречается очень редко. Но тенденции говорят о том, что скоро это будет распространено повсеместно, особенно в колл-центрах финансовых компаний. Интерес с их стороны к этой технологии очень большой.
У голосовой биометрии есть 2 уникальные особенности:
— это единственная технология, которая позволяет подтверждать личность удаленно, например, по телефону. И для этого не нужны специальные сканирующие устройства.
— это единственная технология, которая подтверждает активность человека, т.е. то, что по телефону разговаривает живой человек. Сразу скажу, что записанный на качественный диктофон голос не сработает – доказано. Если где-то такая запись «пройдет», значит в систему заложен изначально низкий порог «доверия».
— Анализ речи.
Мало кто знает, что по голосу можно определить настроение человека, его эмоциональное состояние, пол, примерный вес, национальную принадлежность и т.д.
Конечно, никакая машина не сможет сразу сказать, грустит человек или радуется (вполне возможно, что у него всегда по жизни такое состояние: например, среднестатистическая речь итальянца и финна очень отличаются по темпераменту), но по изменению голоса в процессе разговора, определить это уже вполне реально.
— Распознавание речи (перевод речи в текст).
Это самая распространенная речевая технология в нашей жизни, и в первую очередь — благодаря мобильным устройствам, т.к. многие производители и разработчики считают, что сказать что -то в смартфон человеку гораздо удобнее, чем набрать этот же текст на маленькой клавиатуре экрана.
Предлагаю вначале поговорить вот о чем: где мы встречаемся с технологией распознавания речи в жизни и откуда вообще мы о ней знаем?
Большинство из нас сразу вспомнят Siri (iPhone), Голосовой поиск Google, иногда — IVR системы с голосовым управлением в некоторых колл-центрах, например РЖД, Аэрофлот и т.д.
Это то, что лежит на поверхности, и то, что вы легко можете попробовать сами.
Существует распознавание речи, встроенное в систему автомобиля (набор телефонного номера, управление магнитолой), в телевизоры, инфоматы (штуки, похожие на те, которые принимают деньги за мобильных операторов). Но это мало распространено и практикуется больше как «фишка» определенных производителей. Дело даже не в технических ограничениях и качестве работы, а в удобстве пользования и привычках людей. Я плохо представляю себе человека, который голосом листает программы на телевизоре, когда под рукой есть пульт ДУ.
Итак. Технология распознавания речи. Какие они бывают?
Сразу хочу сказать, что почти вся моя работа связана с телефонией, поэтому многие примеры по тексту ниже будут взяты именно оттуда – из практики работы колл-центров.
Распознавание по закрытым грамматикам.
Распознавание одного слова (голосовой команды) из списка слов (базы).
Понятие «закрытые грамматики» означает, что в систему заложена определенная конечная база слов, в которой система будет искать произнесенное абонентом слово или выражение.
В этом случае система должна поставить вопрос абоненту так, что бы получить однозначный ответ, состоящий из одного слова.
Пример:
Вопрос системы: «Какой день недели вас интересует?»
Ответ абонента: «Вторник»
В этом примере вопрос поставлен так, что система ожидает совершенно определенный ответ от абонента.
База слов в приведенном примере может состоять из следующих вариантов ответа: «понедельник, вторник, среда, четверг, пятница, суббота, воскресенье». Также следует предусмотреть и заложить в базу следующие варианты ответов: «не знаю», «все равно», «любой» и т.д. — эти ответы абонента должны также предусматриваться и обрабатываться системой отдельно, согласно заранее заложенным сценарием диалога.
Встроенные грамматики.
Это разновидность закрытых грамматик.
Распознавание часто запрашиваемых стандартных выражений и понятий.
Понятие «встроенные грамматики» означает, что в систему уже заложены грамматики (т.е. ее не нужно отдельно «обучать»), которые способны распознавать конкретные тематические фразы абонента. При составлении сценария диалога, необходимо просто сослаться на определенную встроенную грамматику.
Пример:
Вопрос системы: «В какое время фильм Вас интересует?»
Ответ абонента: «В 15.30»
В приведенном примере распознается значения времени. Вся необходимая грамматика по распознаванию времени уже заложена в систему.
Встроенные грамматики служат для упрощения разработки голосовых меню, когда можно использовать стандартные универсальные блоки.
Распознавание по открытым грамматикам.
Распознавание всей произнесенной абонентом фразы целиком.
Это позволяет системе задать абоненту открытый вопрос и получить ответ, сформулированный в свободной форме.
Понятие «открытые грамматики» означает, что система ожидает услышать от абонента не конкретное слово/команду, а все смысловое предложение целиком, в котором систему будет интересовать каждое слово.
Пример:
Вопрос системы: «Что вас интересует?»
Ответ абонента: «Какие документы нужны для кредита?»
В этом примере распознается каждое слово в ответе абонента и выявляется общий смысл сказанного. На основании распознанных ключевых слов и понятий в предложении формируется запрос в базу данных и «собирается» ответ абоненту – предоставляется справочная информация.
Распознавание слитной речи дает системе много больше возможностей для автоматизации процесса диалога с абонентом. Плюс к этому возрастает скорость и удобство пользования системой со стороны абонента. Но такие системы сложнее в реализации. Если решение задачи может подразумевать односложные ответы абонента, то лучше применять закрытые грамматики.
Они надежнее работают, такие системы просты в реализации и более привычны для абонентов, которые привыкли пользоваться DTMF набором (навигация с помощью донабора номера в тоновом режиме).
Но будущее, конечно, за слитным распознаванием речи. Постепенно и пользователи к этому привыкнут и не будут «подвисать» на 5-10 секунд, когда система предлагает им вступить в открытый диалог с ней.
Как работает IVR система с распознаванием слитной речи?
На примере ПО VoiceNavigator — синтез и распознавание русской речи для IVR системы.
! Осторожно. Дальше будет более сложный текст для понимания.
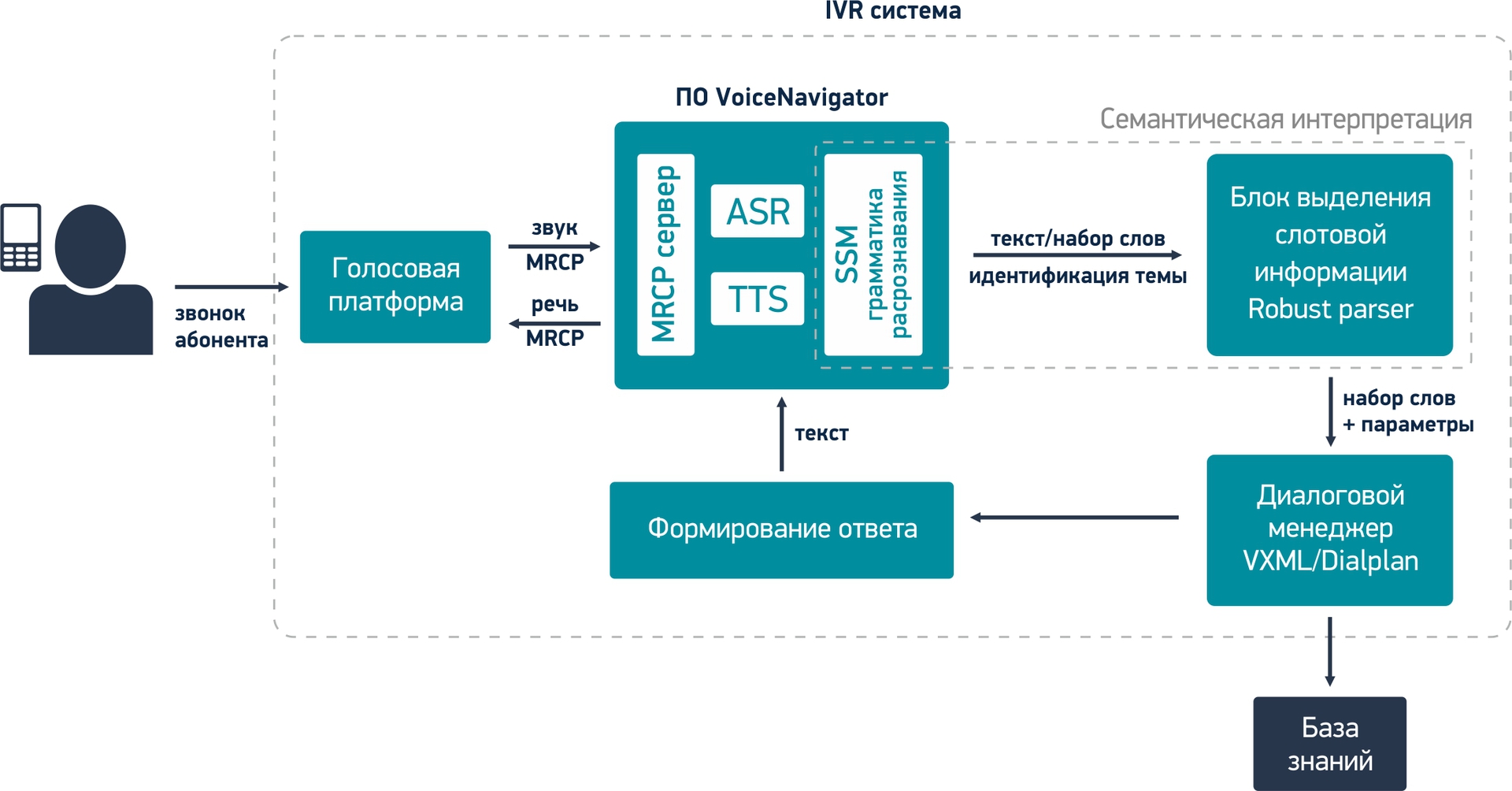
1.Сразу остановимся на том, что вызов абонента пришел в колл-центр и был переведен на голосовую платформу. Голосовая платформа – это ПО, которое занимается отработкой всей логики диалога абонента с системой, т.е. на голосовой платформе работает IVR меню. Наиболее популярные голосовые платформы: Avaya, Genesys, Cisco и Asterisk.
Итак, голосовая платформа передает в VoiceNavigator звук с микрофона телефона абонента.
2.Звук попадает в модуль распознавания речи (ASR), который преобразует речь человека в текст в виде последовательности отдельно составленных слов. Полученные слова не имеют для системы пока никакого смысла.
Пример голосовой фразы абонента по теме расписания поездов:

3.Далее текст попадает в модуль SSM грамматики распознавания (на том, что это такое, здесь останавливаться не буду, кто захочет углубиться в тематику, сможет найти сам. Это будет касаться и остальных терминов ниже по тексту), где полученные слова анализируются на предмет тематики высказывания (к какой теме относится распознанная фраза). В нашем примере распознанная фраза относится к теме: «Поезда дальнего следования» и имеет свой уникальный идентификатор.
4.Затем текст вместе с идентификатором темы передается в модуль выделения слотовой информации (robust parser), в котором выделяются определенные понятия и выражения, важные для данной предметной области (смысл высказывания пользователя). В этом модуле система «понимает», что сказал абонент и анализирует, достаточно ли данной информации для формирования запроса в базу знаний или требуются уточняющие вопросы.

Модуль выделения слотовой информации формирует определенные параметры, которые передаются далее в диалоговый менеджер вместе с распознанными словами.
5.Диалоговый менеджер занимается обработкой всей логики (алгоритма) ведения диалога IVR системы с абонентом. На основании переданных параметров, диалоговый менеджер может отправить запрос в базу знаний (в речи абонента содержится вся информация) для формирования ответа абоненту или запросить у абонента дополнительную информацию, уточнить запрос (в речи абонента содержится не вся информация).
6.Для формирования ответа абоненту диалоговый менеджер обращается в базу знаний. Она содержит всю информацию по предметной области.
7.Далее система формирует ответ абоненту на основании информации из базы знаний и согласно сценарию диалога из диалогового менеджера.
8.После предоставления ответа абоненту, IVR система готова к продолжению работы.
С чего следует начать при создании IVR системы на основе распознавания речи?
Обучение системы распознавания слитной речи.
1.Основой распознавания слитной речи является статистика. Поэтому любой проект по внедрению IVR системы с применением распознавания слитной речи начинается со сбора статистики. Необходимо знать, что интересует абонентов, как они формулируют вопросы, какой информацией изначально обладают, что ожидают услышать в ответ и т.д.
Сбор информации начинается с прослушивания и анализа реальных записей разговоров абонентов с операторами КЦ. На основе этой информации строятся статистические таблицы, из которых становится понятным, какие голосовые запросы абонентов необходимо автоматизировать, и как это можно сделать.
2.Этой информации становится достаточно для создания упрощенного прототипа будущего IVR меню. Такой прототип необходим для сбора и анализа более релевантных ответов абонентов на вопросы IVR меню, т.к. манера общения абонентов с операторами КЦ и с речевыми IVR меню сильно отличается.
Созданный прототип IVR меню размещается на входящем номере телефона в компанию. Он может быть максимально упрощен или вообще не отрабатывать заложенный функционал, т.к. его основная задача заключается в накоплении статистического материала (всевозможных ответов абонентов), который будет являться основой для формирования статистической языковой модели (SLM) направленной на определенную тематику. Гибкость языковой модели для конкретной предметной области позволяет улучшить качество распознавания.
Пример реализации прототипа IVR меню:
Вопрос системы: «Какая услуга Вас интересует?»
Ответ абонента: «Я хотел бы взять кредит»
Ответ системы: «Вызов будет переведен на оператора контактного центра»
Действия системы: Перевод на оператора КЦ при любом ответе абонента.
С помощью прототипа IVR меню, разработчик создает эмуляцию работы системы и собирает реальные записи ответов абонентов (сбор фонограмм), по которым впоследствии будет обучаться система.
Не имеет значение, что произнесет абонент на вопрос системы, вызов в любом случае будет переведен на оператора контактного центра. Таким образом, абонент будет обслужен без причинения ему неудобств, а разработчики IVR меню получать базу всех возможных вариантов ответов по данной тематике на примере реального диалога.
Необходимое количество фонограмм для реализации проекта может достигать нескольких тысяч, а время для сбора фонограмм может занять несколько месяцев. Все зависит от сложности проекта.
3.Затем собранные записи разговоров транскрибируются. Каждая запись прослушивается специалистом и переводится в текст. Транскрибированные фразы не должны содержать пунктуационные знаки и специальные символы. Также все слова и аббревиатуры должны быть прописаны полностью, как их произносит клиент. Данная работа занимает достаточно много времени, но не требует специфических знаний, поэтому к работе обычно одновременно привлекается сразу много сотрудников.
4.Транскрибированные файлы служат для построения тренировочного файла (словарь слов и выражений, конфигурационные параметры), который представляет собой XML документ. Чем объемней будет тренировочный файл по предметной области, тем более качественным будет распознавание.
Тренировочный файл позволяет сформировать языковую модель (SLM), которая является основой распознавания слитной речи.
Для этого тренировочный файл загружается в специальную утилиту, разработанную компанией ЦРТ (именно она является автором ПО VoiceNavigator) – ASR Конструктор, который строит языковую модель. Затем языковая модель загружается в программное обеспечение VoiceNavigator.
На данном этапе работы по построению речевого IVR меню, система способна распознавать речь абонента в виде отдельно составленных слов, не связанных друг с другом.

5.Затем в распознанном списке слов необходимо выявить тему обращения абонента (SSM грамматика распознавания) и выделить слотовую информацию (Robust parser). Для этого требуется дополнительное обучение системы с помощью соответствующих тренировочных файлов.
Тренировочные файлы могут быть созданы на основе уже полученных ранее транскрибированных файлов. Но в отличие от задачи по получению языковой модели, транскрибированные файлы должны быть соответствующим образом доработаны под их пригодность для SSM грамматики и Robust parser.
Что же, начало статьи получилось достаточно простым для понимания тех, кто вообще не знаком с речевыми технологиями. А потом я с головой окунулся в тонкости создания реальных систем голосового самообслуживания. Прошу прощения за такие метаморфозы.
Кого заинтересовала данная тема, и он хочет больше узнать про создание IVR систем с голосовым управлением, хочу порекомендовать посетить специальный wiki сайт – www.vxml.ru
Он посвящен разработке IVR систем на диалоговом языке VoiceXML, который является основным в данной работе.
Спасибо.
