

Каждая из технологий, созданных с того самого момента как человек взял в руки камень, обязана улучшить жизнь человека, исполняя свои основные функции. Однако любая технология может иметь и «побочные эффекты», то есть воздействовать на человека и окружающий мир таким образом, о котором никто в момент сотворения сей технологии не думал или не хотел думать. Яркий пример: были созданы машины, и человек смог перемещаться на большие расстояния с большей скоростью, чем раньше. Но при этом началось загрязнение окружающей среды.
Сегодня мы поговорим об «побочном эффекте» интернета, который поражает не атмосферу Земли, а умы и души самих людей. Дело в том, что всемирная паутина стала отличным инструментом для распространения и обмена информацией, для общения между людьми, физически удаленными друг от друга и для многого другого. Интернет помогает в разных сферах жизни общества, от медицины до банальной подготовки к контрольной работе по истории. Однако место, в котором собирается великое множество, порой безымянных, голосов и мнений, как не прискорбно, наполняется тем, что так присуще человеку — ненавистью.
В сегодняшнем исследовании ученые разбирают по кусочкам несколько алгоритмов, основной задачей которых является выявление оскорбительных, грубых и враждебных сообщений. Им удалось сломать все эти алгоритмы, тем самым продемонстрировав их низкий уровень эффективности и указав на те ошибки, которые должны быть исправлены. Как ученые сломали то, что якобы работало, зачем они это сделали, и какие выводы должны сделать все мы — на эти и другие вопросы мы будем искать ответы в докладе исследователей. Поехали.
Предпосылки к исследованию
Социальные сети и другие формы интернет-взаимодействия между людьми стали неотъемлемой частью нашей жизни. К великому сожалению многие из пользователей таких сервисов слишком буквально понимают такое явление как «свобода слова, мысли и самовыражения», прикрывая этим правом свое неприличное, фамильярное и грубое поведение в сети. Каждый из нас так или иначе сталкивался с «деятельностью» подобных индивидуумов. Многие даже становились объектом подобных речей. Конечно нельзя отрицать, что человек имеет полное право говорить то, что он думает. Однако выражать свои мысли это одно, а оскорблять кого-то это совсем другое. Помимо свободы слова, эксплуатации подвергается и анонимность, ибо вы можете сказать что угодно в адрес кого угодно, оставаясь при этом инкогнито. Как следствие, вы не понесете никакого наказания за свое неподобающее поведение.
Не стоит объяснять, что фразы «мне это не понравилось» и «это полное де**мо, автор убейся об стену» (это еще более-менее приличный вариант) обладают абсолютно разным эмоциональным окрасом, хоть и несут в себе общую суть — комментатору не нравится, то что он увидел / прочитал / услышал и т.д. Но если запретить человеку выражать свое недовольство подобным образом, считается ли это нарушением его прав? Многие скажут, что да. С другой стороны, стоит ли продолжать закрывать глаза на растущую в геометрической прогрессии ненависть в интернете, которая в большинстве случаев не оправдана. Ненависть, как таковая, имеет место быть. Конечно, это очень сильная и невероятно отрицательная эмоция. Однако, если человек ненавидит того, кто совершил нечто ужасное (убийство, изнасилование и прочие бесчеловечные поступки), это можно еще как-то оправдать. Но когда ненависть проявляется в адрес совершенно чужого человека, которы не совершал ничего аморального или бесчеловечного, это уже совершенно другая история.
Сейчас многие компании и исследовательские группы решили создавать свои собственные алгоритмы, которые могут проанализировать любой текст и сообщить где присутствует язык вражды*, и в какой степени силы он выражен. Наши сегодняшние герои решили эти алгоритмы проверить, в частности очень распиаренный Google Perspective API, определяющий «кислотность» фразы, т.е. на сколько сильно данная фраза может быть расценена как оскорбление.
Язык вражды* — как понятно из самого названия сего термина, это совокупность языковых средств, направленных на выражение яркой неприязни между собеседниками. Самыми распространенными формами языка вражды считают: расизм, сексизм, ксенофобия, гомофобия и прочие формы неприязни к чему-то иному.Основные задачи, которые поставили перед собой исследователи, это изучить самые популярные алгоритмы выявления языка вражды, понять методы их работы и попытаться обойти их.
Алгоритмы-участники исследования
Ученые выбрали несколько алгоритмов, базы данных которых отличаются друг от друга, что позволяет определить еще и самую лучшую базу. Одни алгоритмы больше опираются на выявление сексуальных коннотаций*, другие — религиозных. Общим для всех алгоритмов является источник их знаний — Twitter. По словам исследователей, это далеко от совершенства, поскольку данный сервис обладает определенными ограничениями (к примеру, количество символов в одном сообщении). Следовательно, база эффективного алгоритма должна наполняться из разных социальных сетей и сервисов.
Коннотация* — метод окрашивания слова или фразы дополнительными смысловыми или эмоциональными оттенками. Может отличаться в зависимости от языковой, культурной или другой формы социального разделения. Пример: ветреный — «день был ветреный» (прямое значение слова), «он всегда был ветреным человеком» (в данном случае имеется ввиду непостоянство и несерьезность).Список алгоритмов и их функционал:
Detox: проект Википедии для выявления неподобающей лексики в редакционных комментариях. Работает на базе логистической регрессии* и многослойного перцептрона*, используя N-граммные* модели как на уровне букв, так и слов. Размер N-грамм слова варьируется от 1 до 3, а буквы — от 1 до 5.
Логистическая регрессия* — модель предсказания вероятности события посредством подгонки данных к логистической кривой.
Многослойный перцептрон* — модель восприятия информации, состоящая из трех основных слоев: S — сенсоры (принимающие сигнал), A — ассоциативные элементы (обработка) и R- реагирующие элементы (ответ на сигнал), а также дополнительного слоя A.
N-грамм* — последовательность из n элементов.Данные для базы алгоритма собирались третьими лицами, а каждый из комментариев оценивался десятью оценщиками.
T1: алгоритм с базой, разбитой на три типа комментариев из Twitter (язык вражды, оскорбления без языка вражды и нейтральные). Исследователи заявляют, что это единственная база с подобным разделением на категории. Язык вражды выявлялся посредством поиска в среде Twitter по заданным шаблонам. Далее, найденные результаты оценивались тремя сотрудниками компании CrowdFlower (ныне Figure Eight Inc., исследование машинного обучения и искусственного интеллекта). Большая часть базы (76%) это оскорбительные фразы, в то время как язык вражды занимает всего 5%.
T2: алгоритм, использующий глубокие нейронные сети. Основной акцент был поставлен на длительной кратковременной памяти (LSTM). База сего алгоритма разделена на три категории: расизм, сексизм и ничего. Исследователи объединили первые две категории в одну, формируя целостную категорию языка вражды. Основой базы послужили 16000 твитов.
T1*, T3: алгоритм на базе свёрточной нейронной сети (CNN) и управляемых рекуррентных блоков (GRU), использующий базу знаний T1, дополнив ее отдельными категориями, нацеленными на беженцев и мусульман (T3).
Эффективность алгоритмов
Работоспособность алгоритмов проверялась двумя методами. В первом они работали так, как задумано изначально. А во втором алгоритмы обучались за счет баз данных каждого из них, своего рода обмен опытом.
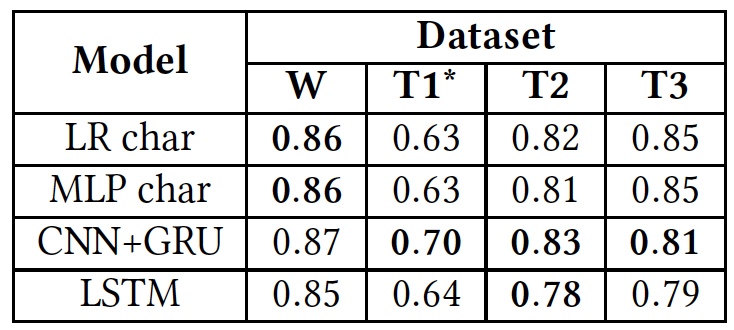
Результаты тестов (жирным шрифтом выделены результаты использования оригинальных баз данных).
Как видно из таблицы выше, все алгоритмы показали примерно одинаковые результаты, когда применялись к разным текстам (базам). Это говорит о том, что все они обучались, используя одинаковый тип текстов.
Единственное значительное отклонение видно у T1*. Связано это с тем, что база данных сего алгоритма крайне несбалансированная, по словам ученых. Язык вражды занимает всего 5%, как мы уже знаем. Изначальное разделение на три категории текстов было преобразовано в разделение на две, когда «оскорбления, но без языка вражды» и «нейтральные» тексты были совмещены в одну группу, занимающую порядка 80% всей базы.
Далее исследователи провели переподготовку алгоритмов. Сначала использовались оригинальные базы. После этого каждый из алгоритмов должен был работать с базой другого алгоритма, вместо своей «родной».
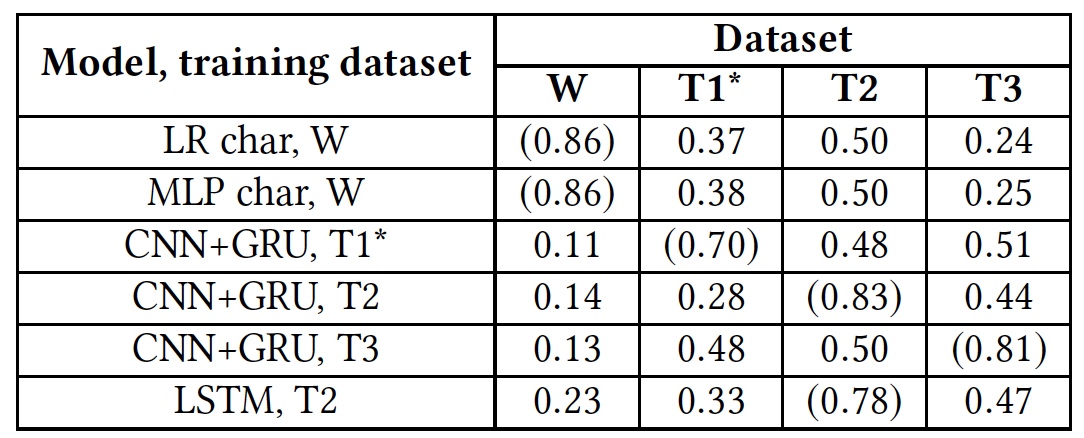
Результаты теста переподготовки (результаты с использованием родных баз выделены круглыми скобками).
Этот тест показал абсолютную неподготовленность всех алгоритмов к работе с чужими базами данных. Это говорит о том, что лингвистические индикаторы языка вражды не пересекаются в разных базах, что может быть связано с тем, что в разных базах крайне мало совпадающих слов, или из-за неточностей интерпретации тех или иных фраз.
Оскорбления и язык вражды
Исследователи решили уделить отдельное внимание двум категориям текстов: оскорбительным и с языком вражды. Суть в том, что одни алгоритмы совмещают их в одну кучу, тогда как другие пытаются разделить их как независимые группы. Конечно, оскорбления это явно негативное явление, и его можно спокойно отнести в одну категорию с враждой. Однако определение оскорблений гораздо более сложный процесс нежели выявления явной ненависти в тексте.
Для проверки алгоритмов на способность выявлять оскорбления была использована база T1. А вот алгоритм T1* не брал участия в данном тесте, ввиду того, что он и так подготовлен к подобной работе, что делает результаты его проверки необъективными.
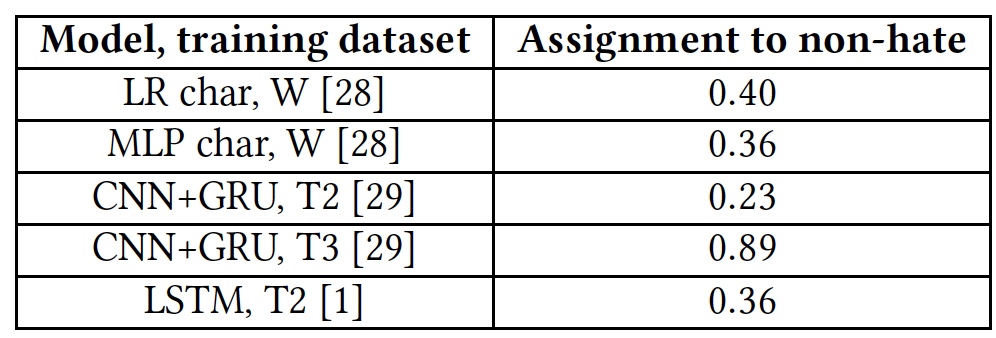
Результаты теста на способность выявлять оскорбительные тексты.
Все алгоритмы показали довольно посредственные результаты. Исключением стал Т3, но далеко не за счет своих талантов. Дело в том, что слова, которые алгоритму незнакомы, помечаются тегом unk. Практически 40% слов в каждом предложении отмечали этим тегом, и алгоритм автоматически засчитывал их как оскорбления. А это, естественно, далеко не всегда было правильно. Другими словами, алгоритм Т3 также не справился с поставленной задачей ввиду своего куцего словарного запаса.
Одной из основных проблем алгоритмов ученые считаю человеческий фактор. Большая часть баз данных каждого из алгоритмов собирается, анализируется и оценивается людьми. А тут возможны сильные разногласия результатов. Одна и та же фраза может показаться оскорбительной для одних людей или нейтральной для других.
Также негативный эффект играет и отсутствие у алгоритмов понимания нестандартных фраз, которые могут спокойно содержать сквернословие, но при этом не иметь никаких оскорблений или языка вражды.
Для демонстрации этого был проведен тест с несколькими фразами. Далее тест повторили, но в каждую из фраз добавили весьма распространенное в английском языке матерное слово «f*ck» (помеченное буквой F в таблице).
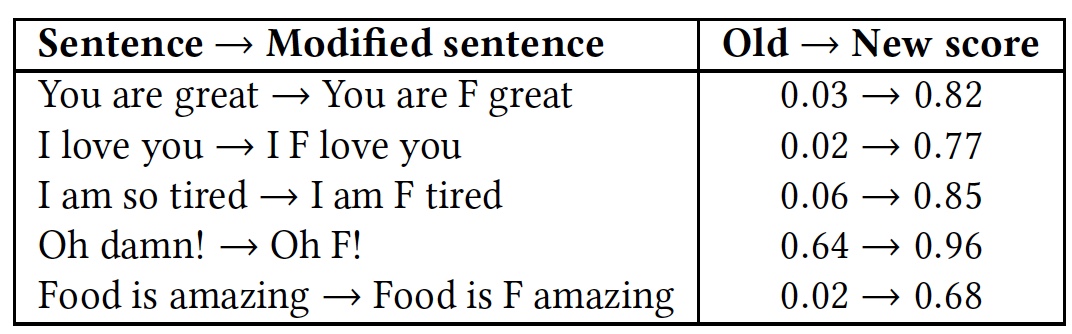
Сравнительные результаты распознания фраз с и без слова «f*ck».
Как видно из таблицы, стоило добавить слово на букву F, как все алгоритмы сразу же восприняли фразу как язык вражды. Хотя суть фраз осталась прежней, дружелюбной, но изменился эмоциональный окрас на более ярко выраженный.
Вышеописанные тесты Google Perspective API показывают схожие результаты. Этот алгоритм также не способен отличить язык вражды от оскорблений, а оскорбление от простого эпитета, использованного для эмоционального приукрашивания фразы.
Как обмануть алгоритм?
Как это часто бывает, если кто-то что-то ломает, то не всегда это плохо. А все потому, что поломав мы выявляем недостаток системы, ее слабое место, которое следует улучшить, предотвратив повторение поломки. Вышеописанные модели не стали исключением, и исследователи решили посмотреть как можно нарушить их работу. Как оказалось, это было не так сложно, как думали создатели этих алгоритмов.
Модель обхода алгоритма проста: взломщик знает, что его тексты проверяются, он может изменять вводные данные (текст) таким образом, чтобы избежать обнаружения. К самому алгоритму и его структуре у взломщика доступа нет. Проще говоря, нарушитель ломает алгоритм исключительно на пользовательском уровне.
Обход алгоритма (назовем это старым добрым словом «взлом») разделен на три типа:
- Изменение слова: намеренные опечатки и Leet, то есть замена некоторых букв на цифры (к примеру: You look great today! — Y0U 100K 6r347 70D4Y!);
- Изменение пространства между словами: добавление и удаление пробелов;
- Добавление слов в конце фразы.
Первая программа взлома — изменение слов — должна успешно выполнить три задачи: уменьшить степень распознавания слова алгоритмом, избежать исправлений орфографическими программами и сохранить читаемость слов для человека.
Программа меняет местами две буквы в слове. Предпочтение отдается буквам ближе к середине слова и друг к другу. Исключаются только первая и последняя буквы в слове. Далее в слова вносятся изменения с оглядкой на Leet, где некоторые буквы заменяются на числа: a — 4, e — 3, l — 1, o — 0, s — 5.
Дабы бороться с подобными хитростями, алгоритмы были слегка усовершенствованы путем внедрения орфографической проверки и стохастического преобразования тренировочной базы знаний. То есть в базе присутствовали не только основные слова, но и их измененные путем перестановки букв формы.
Однако, чем длиннее слово, тем больше вариантов перестановки букв существует, что расширяет возможности программы взломщика.
Метод удаления или добавления пробелов также имеет свои особенности. Удаление пробелов больше подходит для противостояния алгоритмам, анализирующим целые слова. Но алгоритмы, анализирующие каждую букву, легко могут справиться с отсутствием пробелов.
Добавление пробелов может показаться очень неэффективным методом, однако он все же способен обмануть некоторые алгоритмы. Модели, рассматривающие слова целиком, проводят лексический анализ фразы, разбивая ее на составляющие (лексемы). В таком случае пробел служит как разделитель слов, то есть важный элемент анализа фразы. Если же пробелов больше, чем надо, то слова между ними становятся нераспознаваемыми для алгоритма. При этом подобный метод обхода сохраняет высокую степень читаемости фраз для человека. Работает метод просто: выбирается случайная буква в слове, после нее ставится пробел. В результате слово, которое ранее было известно алгоритму, таковым быть прекращает. Пример: «Ненависть» — «нена висть». Если же убрать все пробелы в тексте, то вся фраза целиком станет для алгоритма одним непонятным ему словом. Как в той истории, где дочь подарила матери новый телефон, а та написала ей смс с текстом: «дорогаякакставитьпробелнаэтомтелефоне». Мы можем прочесть эту фразу, но алгоритм воспримет ее как одно слово, которого, конечно же, он не знает.
Однако, если алгоритм анализирует буквы по отдельности, то он сможет распознать фразу, посему сей метод взлома не пригоден в таких случаях.
Чтобы противостоять таким атакам, алгоритмы также были переподготовлены. Для борьбы с добавлением пробелов, база алгоритмов прошла через программу случайного внедрения пробелов: слово из n букв может быть разделено пробелом n-1 способами. Однако это привело к комбинаторному взрыву, когда сложность алгоритма резко возрастает из-за увеличения размера входных данных. Как следствие, обучение алгоритма, опираясь на известном методе добавления пробелов, крайне сложное и малоэффективное занятие.
С удаление пробелов также есть сложности. Если базу алгоритма пополнить фразами, которые он знает, но уже без пробелов, то это будет эффективно работать только в том случае, когда будет применена именно такая фраза. Стоит заменить пару букв или слово, и алгоритм не распознает ничего.
В методе взлома путем добавления слов основной сутью является то, как работает алгоритм распознавания. Он разделяет слова на категории, скажем на «хорошие» и «плохие». Если во фразе больше «хороших», то вероятнее всего алгоритм определит всю фразу как «хорошую». И наоборот. Если добавить в «плохую» по смыслу фразу случайное «хорошее» слово, то таким образом можно обмануть алгоритм, а смысл фразы для читающего ее человека останется прежним. Программа взлома генерирует случайные цифры (от 10 до 50) или слова в конце каждой фразы. В качестве источника случайных слов был выбран список самых распространенных обычных слов английского языка, предоставленный Google-ом.

Таблица результатов применения вышеописанных методов взлома и реакции на это алгоритмов (А — атака, АТ — обучение на базе принципа атакующей программы, SC — проверка орфографии, RW — удаление пробелов).
Для наглядной демонстрации метода обхода путем внедрения дополнительных слов, исследователи провели тест с использованием слова «love» (любовь). Данное слово было добавлено в конце фраз оскорбительного характера.

Результаты теста с добавлением слова «love».
Из таблицы видно, что данный метод смог обмануть все алгоритмы, анализирующие слова целиком. Алгоритмы, анализирующие буквы отдельно, также пострадали, но не так значительно.
Ранее Google Perspective API уже подвергался проверке, которая показала его малоэффективную способность распознавать нейтральные и оскорбительные тексты.
В качестве тестовых фраз тогда использовали (переводить не буду по понятным причинам):
S1: Climate change is happening and it’s not changing in our favor. If you think differently you’re an idiot.
S2: They’re stupid, it’s getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It’s stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
S2: They’re stupid, it’s getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It’s stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
Исследователи использовали эти же фразы в своем исследование. Результат был значительно лучше, что говорит о том, что Google Perspective API был усовершенствован. Однако применив метод удаления пробелов в сочетании с внедрением слова «love» на каждой из вышеперечисленных фраз показал совершенно другой результат.
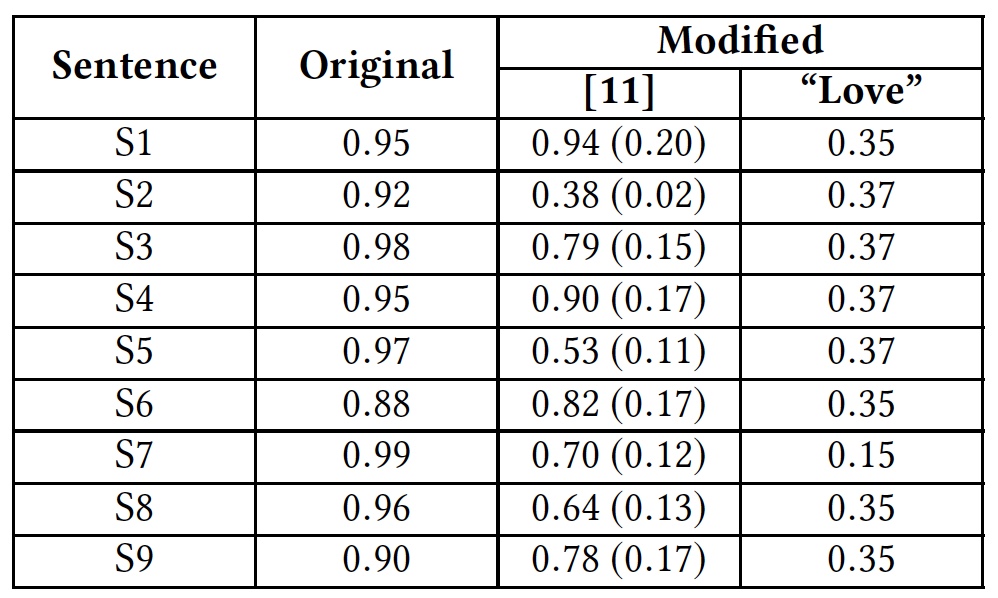
Google Perspective API: степень «токсичности» (оскорбительности) фраз.
В скобках указаны нынешние результаты в сравнение с теми, что были до усовершенствования Google Perspective API.
Для более детального ознакомления с данным исследованием вы можете использовать отчет ученых, доступный тут.
Эпилог
Исследователи намеренно использовали максимально простые методы обмана алгоритмов, чтобы продемонстрировать их низкую степень эффективности, а также указать разработчикам та не слабые места, которые требуют их внимания.
Программы, которые могут отслеживать оскорбительные фразы в сети, это конечно великолепная идея. Но что дальше? Должна ли эта программа подобные фразы блокировать? Или она должна предложить альтернативный вариант фразы, которые не будет содержать оскорблений? Со стороны этики вопросов крайне много: свобода слова, цензура, культура поведения, равенство людей и прочее. Имеет ли право программа решать, что человек имеет право говорить, а что нет? Возможно. Однако реализация подобной программы должна быть безупречной, лишенной изъянов, которые могут быть использованы против нее. И пока ученые продолжают ломать голову над этим вопросом, само общество должно решить для себя — так ли прекрасна тотальная свобода слова или может следует ее иногда ограничивать?
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до декабря бесплатно при оплате на срок от полугода, заказать можно тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Only registered users can participate in poll. Log in, please.
А теперь вопрос к вам, дорогие читатели. Как вы думаете, стоит ли оставить все как есть или ограничить свободу слова в контексте фильтрации оскорблений и языка вражды?
59.09% Свобода слова должна быть абсолютной.26
13.64% Оскорбления и язык вражды это ужасно. Их нужно фильтровать.6
2.27% Общество не готово к таким переменам.1
15.91% Я не обращаю внимания на грубости в сети и вам советую.7
9.09% Мне все равно.4
44 users voted. 13 users abstained.
