«А оно там делает магию»
кто-то из тех, кого я удалённо консультировал по Эластику.
Я всегда говорю, что верю в три вещи: мониторинг, логи и бэкапы.
Тема про то, как мы собираем и храним логи, достаточно полно была раскрыта в предыдущих статьях, тема про бэкапы в Elasticsearch — совсем отдельная история, поэтому в этой, возможно заключительной, статье цикла я расскажу как происходит мониторинг моего любимого кластера. Это не очень сложно (и не требует использования дополнительных плагинов и сторонних сервисов) — ибо REST API, предоставляемое самим Elasticsearch простое, понятное и удобное в использовании. Всего-то надо немного углубиться в его внутреннее устройство, понять, что означают все эти метрики, пулы тредов, веса распределения шардов по нодам, настройки очередей — и не останется никаких вопросов о том, что же за «магию» эластик делает прямо сейчас.

На недавней конференции Highload++ 2017 я рассказал о том, как строил кластер своей мечты, и говорил, что недостаточно просто построить сервис. Критически важно в любой момент знать, в каком он состоянии, причём контроль обязательно должен быть многоуровневым. Разбудите меня посреди ночи (отделу мониторинга привет!) — и через две минуты я буду знать, в каком состоянии находится кластер. Причём одна минута из двух уйдёт на подключение к корпоративному VPN и логин в Zabbix.
Нижний уровень мониторинга — железо и базовые метрики, такие же, какие собираются с любого сервера, но некоторые, в случае кластера Elasticsearch, требуют особого внимания. А именно:
Я специально выделил ошибки сети — эластик крайне чувствителен к проблемам с сетью. По умолчанию текущий активный мастер пингует остальные ноды раз в секунду, а ноды, в свою очередь, проверяют наличие кворума мастер-нод. Если на каком-то этапе нода не ответила на пинг в течение 30 секунд, то она помечается как недоступная, с последствиями в виде ребаланса кластера и долгих проверок целостности. А это совсем не то, чем правильно спроектированный кластер должен быть занят посреди рабочего дня.
Уровень повыше, но мониторинг всё такой же стандартный:
Если любая из метрик упала в ноль — это, означает что приложение упало, либо зависло, и немедленно вызывается алерт по уровню disaster.
С этого момента начинается самое интересное. Поскольку Elasticsearch написан на java, то сервис запускается как обычное jvm-приложение и поначалу для его мониторинга я использовал агент Jolokia, ставший стандартом де-факто для мониторинга java-приложений в нашей компании.
Jolokia, как сказано на сайте разработчика, это «JMX на капсаицине», который, по сути, представляет собой JMX-HTTP гейт. Запускается вместе с приложением как javaagent, слушает порт, принимает http-запросы, возвращает JMX-метрики, обёртнутые в JSON, причём делает это быстро, в отличии от медленного JMX-агента того же Zabbix. Умеет в авторизацию, firewall-friendly, позволяет разграничение доступов до уровня отдельных mbeans. Словом, прекрасный сервис для мониторинга java-приложений, оказавшийся в случае с Elasticsearch… совершенно бесполезным.
Дело в том, что Elasticsearch предоставляет замечательное API, которое полностью покрывает все потребности в мониторинге — в том числе, те же метрики о состоянии java-машины, что и Jolokia. Принимает http-запросы, возвращает JSON — что может быть лучше?
Пройдёмся API более детально, от простого к сложному:
Общие метрики состояния кластера. Самые важные из них это:
На основании этих метрик строится вот такой, насыщенный информацией, график:

Здесь и далее по клику откроется покрупнее
В идеальном состоянии все его метрики должен лежать на нуле. Алармы по этим метрикам поднимаются если:
Остальные метрики критического влияния на работу кластера не оказывают, поэтому алармы на них не заведены, но они собираются и по ним строятся графики для контроля и периодического анализа.
Расширенная статистика по кластеру, из которой собираем только несколько метрик:
Несмотря на то, что ноды выполняют разные задачи, API для получения статистики вызывается одинаково и возвращает один и тот же набор метрик вне зависимости от роли ноды в кластере. И уже нашей задачей, при создании шаблона в Zabbix, становится отбор метрик в зависимости от роли ноды. В этом API несколько сотен метрик, большая часть которых полезна только для глубокой аналитики работы кластера, а под мониторинг и алерты поставлены следующие:
jvm.mem.heap_max_in_bytes — выделенная память в байтах, jvm.mem.heap_used_in_bytes — используемая память в байтах, jvm.mem.heap_used_percent — используемая память, в процентах от выделенного Xmx.
Очень важный параметр, и вот почему: Elasticsearch хранит в оперативной памяти каждой дата-ноды индексную часть каждого шарда принадлежащего этой ноде для осуществления поиска. Регулярно приходит Garbage Collector и очищает неиспользуемые пулы памяти. Через некоторое время, если данных на ноде много и они перестают помещаться в память, сборщик выполняет очистку всё дольше и дольше, пытаясь найти то, что вообще можно очистить, вплоть до полного stop the world.
А из-за того, что кластер Elasticsearch работает со скоростью самой медленной дата-ноды, залипать начинает уже весь кластер. Есть еще одна причина следить за памятью — по моему опыту, после 4-5 часов в состоянии jvm.mem.heap_used_percent > 95% падение процесса становится неизбежным.
График использования памяти в течение дня обычно выглядит как-то так и это совершенно нормальная картина. Горячая зона:

Тёплая зона, тут картина выглядит более спокойной, хотя и менее сбалансированной:

Сведение значения метрик http.total_rps со всех нод в один график позволяет оценить адекватность балансировки нагрузки по нодам и видеть перекосы, как только они появляются. Как видим на графике ниже — они минимальны:

throttle_time_in_millis — очень интересная метрика, существующая в нескольких секциях на каждой ноде. То, из какой секции её собирать, зависит от роли ноды. Метрика показывает время ожидания выполнения операции в миллисекундах, в идеале не должно отличаться от нуля:
Каких-то конкретных диапазонов верхних значений в которые должны вписываться throttle_times не существует, это зависит от конкретной инсталляции и вычисляется эмпирическим путём. В идеале, конечно, должен быть ноль.
search — секция, содержащая метрики запросов выполняемых на ноде. Имеет ненулевые значения только на нодах с данными. Из десятка метрик в этой секции особо полезны две:
На основании этих двух метрик строится график среднего времени затраченного на выполнение одного поискового запроса на каждой дата-ноде кластера:

Как видим — идеальный график ровный в течении дня, без резких всплесков. Так же видна резкая разница по скорости поиска между «горячей» (сервера с SSD) и «тёплой» зонами.
Надо учесть, что при выполнении поиска Elasticsearch осуществляет его по всем нодам, где находятся шарды индекса (и primary, и replica). Соответственно, результирующее время поиска будет примерно равно времени, затраченному на поиск на самой медленной ноде, плюс время на агрегацию найденных данных. И если ваши пользователи вдруг начали жаловаться, что поиск стал медленным, анализ этого графика позволит найти ноду, из-за которой это происходит.
thread_pool — группа метрик, описывающих пулы очередей, куда попадают операции на выполнение. Очередей много, подробное описание их назначения — в официальной документации, но набор возвращаемых метрик для каждой очереди один и тот же: threads, queue, active, rejected, largest, completed. Основные очереди, которые обязательно должны попадать в мониторинг это — generic, bulk, refresh и search.
А вот на эти метрики, на мой взгляд, нужно обращать особое внимание:
Рост этого показателя — очень плохой признак, который показывает, что эластику не хватает ресурсов для приёма новых данных. Бороться, без добавления железа в кластер, сложно. Можно, конечно, добавлять количество процессоров-обработчиков и увеличивать размеры bulk-очередей, но разработчики не рекомендуют этого делать. Правильное решение — наращивать мощность железа, добавлять в кластер новые ноды, дробить нагрузку. Второй неприятный момент в том, что сервис доставки данных до эластика должен уметь обрабатывать отказы и «дожимать» данные позже, чтобы избежать потери данных.
Метрику по отказам нужно контролировать по каждой очереди, и привязывать к ней аларм, в зависимости от назначения ноды. Нет смысла мониторить bulk-очереди на нодах, которые не работают на приём данных. Также, информация о загрузке пулов очень полезна для оптимизации работы кластера. Например, сравнивая нагруженность search-пула в разных зонах кластера, можно построить аналитику по разумному сроку хранения данных на горячих нодах, прежде чем осуществлять их перенос на медленные ноды для длительного хранения. Впрочем, аналитика и тонкая настройка кластера — это отдельная объёмная тема и, наверное, уже не для этой статьи.
Хорошо, с метриками более-менее разобрались, осталось рассмотреть последний вопрос — как их получать и отправлять в мониторинг. Использовать Zabbix или любой другой — не важно, принцип один и тот же.
Вариантов, как всегда, несколько. Можно выполнять curl-запросы непосредственно в API, прямо до нужной метрики. Плюсы — просто, минусы — медленно и нерационально. Можно делать запрос на весь API, получать большой JSON со всеми метриками и разбирать его. Когда-то я делал именно так, но потом перешёл на модуль elasticsearch в python. По сути это обертка над библиотекой urllib, который транслирует функции в те же запросы к Elasticsearch API и предоставляет к ним более удобный интерфейс. Исходный код скрипта и описание его работы можно традиционно посмотреть на GitHub. Шаблоны и скрины в Zabbix, предоставить, к сожалению не могу, по вполне понятным причинам.

Метрик в Elasticsearch API много (несколько сотен) и перечисление их всех выходит за рамки одной статьи, поэтому я описал только наиболее значимые из тех что мы собираем и то, на что необходимо обратить пристальное внимание при их мониторинге. Надеюсь, что после прочтения статьи у вас не осталось сомнений в том, что никакой «магии» эластик внутри себя не делает — только нормальную работу хорошего, надёжного сервиса. Своеобразного, не без тараканов, но тем не менее, прекрасного.
Если что-то осталось непонятным, возникли вопросы или некоторые места требуют более детального рассмотрения — пишите в комментарии, обсудим.
кто-то из тех, кого я удалённо консультировал по Эластику.
Я всегда говорю, что верю в три вещи: мониторинг, логи и бэкапы.
Тема про то, как мы собираем и храним логи, достаточно полно была раскрыта в предыдущих статьях, тема про бэкапы в Elasticsearch — совсем отдельная история, поэтому в этой, возможно заключительной, статье цикла я расскажу как происходит мониторинг моего любимого кластера. Это не очень сложно (и не требует использования дополнительных плагинов и сторонних сервисов) — ибо REST API, предоставляемое самим Elasticsearch простое, понятное и удобное в использовании. Всего-то надо немного углубиться в его внутреннее устройство, понять, что означают все эти метрики, пулы тредов, веса распределения шардов по нодам, настройки очередей — и не останется никаких вопросов о том, что же за «магию» эластик делает прямо сейчас.

На недавней конференции Highload++ 2017 я рассказал о том, как строил кластер своей мечты, и говорил, что недостаточно просто построить сервис. Критически важно в любой момент знать, в каком он состоянии, причём контроль обязательно должен быть многоуровневым. Разбудите меня посреди ночи (отделу мониторинга привет!) — и через две минуты я буду знать, в каком состоянии находится кластер. Причём одна минута из двух уйдёт на подключение к корпоративному VPN и логин в Zabbix.
Disclaimer: Описываемая структура состоит из кластера Elasticsearch 5.x.x, с выделенными мастер-, дата- и клиентскими нодами. Кластер разделён на «горячий» и «тёплый» сегменты (hot/warm cluster architecture). Скриншоты приведены по системе мониторинга Zabbix. Но общие принципы мониторинга ES можно применить к кластеру почти любой конфигурации и версий.Итак, уровни мониторинга снизу вверх:
Уровень сервера
Нижний уровень мониторинга — железо и базовые метрики, такие же, какие собираются с любого сервера, но некоторые, в случае кластера Elasticsearch, требуют особого внимания. А именно:
- Загрузка процессорных ядер и общее LA;
- Использование памяти;
- Пинг до сервера и время отклика;
- i/o по дисковой подсистеме;
- Остаток свободного места на дисках (настройка watermark.low по умолчанию запрещает эластику создавать новые индексы при наличии менее 85% свободного места );
- Использование сети и, особенно, коллизии и ошибки на интерфейсах.
Я специально выделил ошибки сети — эластик крайне чувствителен к проблемам с сетью. По умолчанию текущий активный мастер пингует остальные ноды раз в секунду, а ноды, в свою очередь, проверяют наличие кворума мастер-нод. Если на каком-то этапе нода не ответила на пинг в течение 30 секунд, то она помечается как недоступная, с последствиями в виде ребаланса кластера и долгих проверок целостности. А это совсем не то, чем правильно спроектированный кластер должен быть занят посреди рабочего дня.
Уровень сервиса
Уровень повыше, но мониторинг всё такой же стандартный:
- Количество запущенных процессов сервиса elasticsearch;
- Используемая сервисом память;
- Пинг до порта приложения (стандартные порты elasticsearch/kibana — 9200/9300/5601).
Если любая из метрик упала в ноль — это, означает что приложение упало, либо зависло, и немедленно вызывается алерт по уровню disaster.
Уровень приложения
С этого момента начинается самое интересное. Поскольку Elasticsearch написан на java, то сервис запускается как обычное jvm-приложение и поначалу для его мониторинга я использовал агент Jolokia, ставший стандартом де-факто для мониторинга java-приложений в нашей компании.
Jolokia, как сказано на сайте разработчика, это «JMX на капсаицине», который, по сути, представляет собой JMX-HTTP гейт. Запускается вместе с приложением как javaagent, слушает порт, принимает http-запросы, возвращает JMX-метрики, обёртнутые в JSON, причём делает это быстро, в отличии от медленного JMX-агента того же Zabbix. Умеет в авторизацию, firewall-friendly, позволяет разграничение доступов до уровня отдельных mbeans. Словом, прекрасный сервис для мониторинга java-приложений, оказавшийся в случае с Elasticsearch… совершенно бесполезным.
Дело в том, что Elasticsearch предоставляет замечательное API, которое полностью покрывает все потребности в мониторинге — в том числе, те же метрики о состоянии java-машины, что и Jolokia. Принимает http-запросы, возвращает JSON — что может быть лучше?
Пройдёмся API более детально, от простого к сложному:
Уровень Кластера
_cluster/health
Общие метрики состояния кластера. Самые важные из них это:
- status — принимает одно из значений: green/yellow/red. Тут всё понятно: green — всё хорошо; yellow — какие-то шарды отсутствуют/инициализируются, но оставшихся кластеру достаточно, чтобы собраться в консистентное состояние; red — всё плохо, каким-то индексам не хватает шардов до 100% целостности, беда, трагедия, будите админа (но новые данные кластер, тем не менее, принимает).
- number_of_nodes/number_of_data_nodes — общее количество нод в кластере, количество дата-нод. Полезно мониторить их изменение, потому что иногда (крайне редко) случаются ситуации, когда какая-то из нод залипла под нагрузкой и вывалилась из кластера, но потребляет ресурсы и держит порт открытым. Такое поведение не отлавливается стандартным мониторингом сервисов (уровня ниже), но на целостность кластера влияет и ещё как.
- relocating_shards — шарды, находящиеся в процессе ребаланса, перемещаются с одной дата-ноды на другую.
- initializing_shards — инициализирующися шарды. Метрика отличается от нуля только в моменты, когда создаются новые индексы и эластик распределяет их шарды по нодам. Ситуация вполне нормальная, но только если этот процесс не длится дольше некоторого времени. Время вычисляется эмпирическим путём, на моём кластере установлено в ±10 минут. Если дольше — что-то не то, алерт.
- unassigned_shards — количество неназначенных шард. Значение метрики не равное нулю — это очень плохой признак. Либо из кластера выпала нода, либо не хватает места для размещения, либо какая-то другая причина и нужно незамедлительно разбираться.
- number_of_pending_tasks — количество задач в очереди на исполнение. Если не равно нулю — теряем реалтайм, кластер не успевает.
- task_max_waiting_in_queue_millis — среднее время ожидания задачи в очереди на исполнение (в мс.). Аналогично предыдущей метрике, должно быть нулевым. Ибо «нет ничего хуже, чем догонять и ждать».
- active_shards_percent_as_number — количество активных шардов в процентах. Активные шарды — все, кроме тех, что находятся в состоянии unassigned/initializing. В нормальном состоянии — 100%. Для удобства отображения на графиках я использую обратную метрику, вычисляемую как inactive_shards_percent_as_number = 100 — active_shards_percent_as_number.
На основании этих метрик строится вот такой, насыщенный информацией, график:
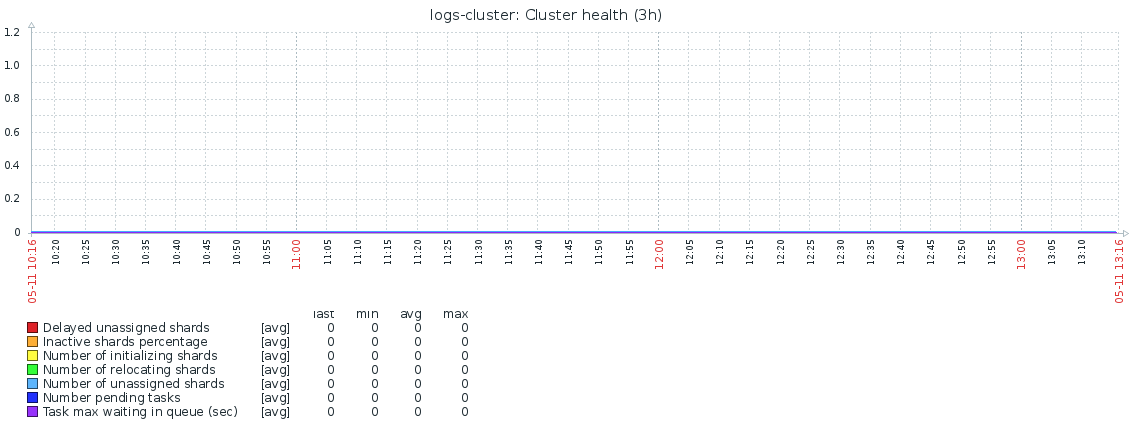
Здесь и далее по клику откроется покрупнее
В идеальном состоянии все его метрики должен лежать на нуле. Алармы по этим метрикам поднимаются если:
- status = red — сразу, yellow — через 10 минут;
- количество нод меньше зафиксированного количества;
- количество шард в статусе initializing больше 0 дольше 10 минут;
- количество шард в статусе unassigned не равно 0 — сразу.
Остальные метрики критического влияния на работу кластера не оказывают, поэтому алармы на них не заведены, но они собираются и по ним строятся графики для контроля и периодического анализа.
_cluster/stats
Расширенная статистика по кластеру, из которой собираем только несколько метрик:
- docs.count — количество проиндексированных записей в кластере по состоянию на текущий момент времени. Из этой метрики вычисляется количество новых записей в секунду по простой формуле: rps = (docs.count(t) — docs.count(t-1))/t. И если вдруг rps упал в ноль — аларм.
- indices.count — мы используем Elasticsearch для хранения и оперативного доступа к логам приложений. Каждый день для логов каждого приложения создаётся новый индекс, и каждый день индексы старше 21 дня удаляются из кластера. Таким образом каждый день создаётся и удаляется одинаковое количество индексов. Рост общего количества индексов значит, что либо админы поставили под сбор в эластик логи нового приложения, либо сломался скрипт очистки старых индексов. Не критично, но поглядывать нужно.
- fs.free_in_bytes, fs.total_in_bytes, fs.available_in_bytes — информация о файловой системе, хранит данные о суммарном объёме места, доступного всему кластеру.
Уровень ноды
_nodes/stats
Несмотря на то, что ноды выполняют разные задачи, API для получения статистики вызывается одинаково и возвращает один и тот же набор метрик вне зависимости от роли ноды в кластере. И уже нашей задачей, при создании шаблона в Zabbix, становится отбор метрик в зависимости от роли ноды. В этом API несколько сотен метрик, большая часть которых полезна только для глубокой аналитики работы кластера, а под мониторинг и алерты поставлены следующие:
Метрики по памяти процесса elastic
jvm.mem.heap_max_in_bytes — выделенная память в байтах, jvm.mem.heap_used_in_bytes — используемая память в байтах, jvm.mem.heap_used_percent — используемая память, в процентах от выделенного Xmx.
Очень важный параметр, и вот почему: Elasticsearch хранит в оперативной памяти каждой дата-ноды индексную часть каждого шарда принадлежащего этой ноде для осуществления поиска. Регулярно приходит Garbage Collector и очищает неиспользуемые пулы памяти. Через некоторое время, если данных на ноде много и они перестают помещаться в память, сборщик выполняет очистку всё дольше и дольше, пытаясь найти то, что вообще можно очистить, вплоть до полного stop the world.
А из-за того, что кластер Elasticsearch работает со скоростью самой медленной дата-ноды, залипать начинает уже весь кластер. Есть еще одна причина следить за памятью — по моему опыту, после 4-5 часов в состоянии jvm.mem.heap_used_percent > 95% падение процесса становится неизбежным.
График использования памяти в течение дня обычно выглядит как-то так и это совершенно нормальная картина. Горячая зона:
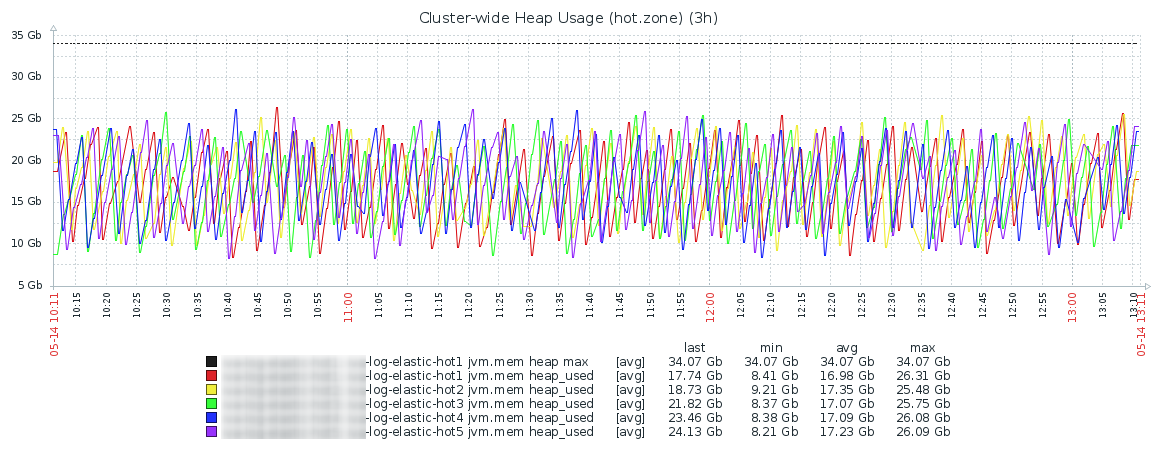
Тёплая зона, тут картина выглядит более спокойной, хотя и менее сбалансированной:

- fs.total.total_in_bytes, fs.total.free_in_bytes, fs.total.available_in_bytes — метрики по дисковому пространству, доступному каждой ноде. Если значение приближается к watermark.low — аларм.
- http.current_open, http.total_opened — количество открытых http-подключений к нодам — на момент опроса и общее, накопительный счетчик с момента запуска ноды, из которого легко вычисляется rps.
Сведение значения метрик http.total_rps со всех нод в один график позволяет оценить адекватность балансировки нагрузки по нодам и видеть перекосы, как только они появляются. Как видим на графике ниже — они минимальны:

throttle_time_in_millis — очень интересная метрика, существующая в нескольких секциях на каждой ноде. То, из какой секции её собирать, зависит от роли ноды. Метрика показывает время ожидания выполнения операции в миллисекундах, в идеале не должно отличаться от нуля:
- indexing.throttle_time_in_millis — время, которое кластер потратил на ожидание при индексации новых данных. Имеет смысл только на нодах, принимающих данные.
- store.throttle_time_in_millis — время, затраченное кластером, на ожидание при записи новых данных на диск. Аналогично метрике выше — имеет смысл только на нодах куда поступают новые данные.
- recovery.throttle_time_in_millis — включает в себя не только время ожидания при восстановлении шард (например, после сбоев), но и время ожидания при перемещении шард с ноды на ноду (например, при ребалансе или миграции шард между зонами hot/warm). Метрика особо актуальна на нодах, где данные хранятся долго.
- merges.total_throttled_time_in_millis — общее время, затраченное кластером на ожидание объединения сегментов на данной ноде. Накопительный счётчик.
Каких-то конкретных диапазонов верхних значений в которые должны вписываться throttle_times не существует, это зависит от конкретной инсталляции и вычисляется эмпирическим путём. В идеале, конечно, должен быть ноль.
search — секция, содержащая метрики запросов выполняемых на ноде. Имеет ненулевые значения только на нодах с данными. Из десятка метрик в этой секции особо полезны две:
- search.query_total — всего запросов на поиск, выполненных на ноде с момента её перезагрузки. Из этой метрики вычисляем среднее количество запросов в секунду.
- search.query_time_in_millis — время в миллисекундах, затраченное на все операции поиска с момента перезагрузки ноды.
На основании этих двух метрик строится график среднего времени затраченного на выполнение одного поискового запроса на каждой дата-ноде кластера:
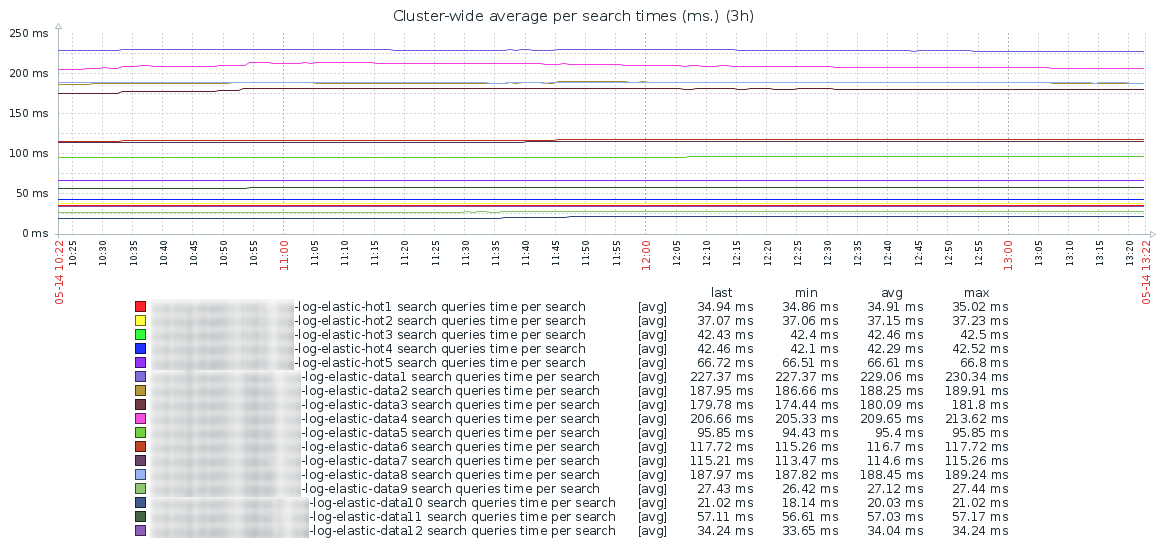
Как видим — идеальный график ровный в течении дня, без резких всплесков. Так же видна резкая разница по скорости поиска между «горячей» (сервера с SSD) и «тёплой» зонами.
Надо учесть, что при выполнении поиска Elasticsearch осуществляет его по всем нодам, где находятся шарды индекса (и primary, и replica). Соответственно, результирующее время поиска будет примерно равно времени, затраченному на поиск на самой медленной ноде, плюс время на агрегацию найденных данных. И если ваши пользователи вдруг начали жаловаться, что поиск стал медленным, анализ этого графика позволит найти ноду, из-за которой это происходит.
thread_pool — группа метрик, описывающих пулы очередей, куда попадают операции на выполнение. Очередей много, подробное описание их назначения — в официальной документации, но набор возвращаемых метрик для каждой очереди один и тот же: threads, queue, active, rejected, largest, completed. Основные очереди, которые обязательно должны попадать в мониторинг это — generic, bulk, refresh и search.
А вот на эти метрики, на мой взгляд, нужно обращать особое внимание:
- thread_pool.bulk.completed — счётчик, хранящий количество выполненных операций пакетной (bulk) записи данных в кластер с момента перезагрузки ноды. Из него вычисляется rps по записи.
- thread_pool.bulk.active — количество задач в очереди на добавление данных на момент опроса, показывает загруженность кластера по записи на текущий момент времени. Если этот параметр выходит за установленный размер очереди, начинает расти следующий счётчик.
- thread_pool.bulk.rejected — счётчик количества отказов по запросам на добавление данных. Имеет смысл только на нодах осуществляющих приём данных. Суммируется накопительным итогом, раздельно по нодам, обнуляется в момент полной перезагрузки ноды.
Рост этого показателя — очень плохой признак, который показывает, что эластику не хватает ресурсов для приёма новых данных. Бороться, без добавления железа в кластер, сложно. Можно, конечно, добавлять количество процессоров-обработчиков и увеличивать размеры bulk-очередей, но разработчики не рекомендуют этого делать. Правильное решение — наращивать мощность железа, добавлять в кластер новые ноды, дробить нагрузку. Второй неприятный момент в том, что сервис доставки данных до эластика должен уметь обрабатывать отказы и «дожимать» данные позже, чтобы избежать потери данных.
Метрику по отказам нужно контролировать по каждой очереди, и привязывать к ней аларм, в зависимости от назначения ноды. Нет смысла мониторить bulk-очереди на нодах, которые не работают на приём данных. Также, информация о загрузке пулов очень полезна для оптимизации работы кластера. Например, сравнивая нагруженность search-пула в разных зонах кластера, можно построить аналитику по разумному сроку хранения данных на горячих нодах, прежде чем осуществлять их перенос на медленные ноды для длительного хранения. Впрочем, аналитика и тонкая настройка кластера — это отдельная объёмная тема и, наверное, уже не для этой статьи.
Получение данных
Хорошо, с метриками более-менее разобрались, осталось рассмотреть последний вопрос — как их получать и отправлять в мониторинг. Использовать Zabbix или любой другой — не важно, принцип один и тот же.
Вариантов, как всегда, несколько. Можно выполнять curl-запросы непосредственно в API, прямо до нужной метрики. Плюсы — просто, минусы — медленно и нерационально. Можно делать запрос на весь API, получать большой JSON со всеми метриками и разбирать его. Когда-то я делал именно так, но потом перешёл на модуль elasticsearch в python. По сути это обертка над библиотекой urllib, который транслирует функции в те же запросы к Elasticsearch API и предоставляет к ним более удобный интерфейс. Исходный код скрипта и описание его работы можно традиционно посмотреть на GitHub. Шаблоны и скрины в Zabbix, предоставить, к сожалению не могу, по вполне понятным причинам.

Заключение
Метрик в Elasticsearch API много (несколько сотен) и перечисление их всех выходит за рамки одной статьи, поэтому я описал только наиболее значимые из тех что мы собираем и то, на что необходимо обратить пристальное внимание при их мониторинге. Надеюсь, что после прочтения статьи у вас не осталось сомнений в том, что никакой «магии» эластик внутри себя не делает — только нормальную работу хорошего, надёжного сервиса. Своеобразного, не без тараканов, но тем не менее, прекрасного.
Если что-то осталось непонятным, возникли вопросы или некоторые места требуют более детального рассмотрения — пишите в комментарии, обсудим.
