
Всем привет! С прошедшим концом света и с наступающими праздниками :)
В качестве подарка сообществу Open Source, а так же любителям антиквариата, мы (совместно с товарищем humbug) решили выложить нашу последнюю исследовательскую разработку.
Предлагаем вашему вниманию с нуля переписанную на C++ реализацию виртуальной машины, совместимую с Little Smalltalk. На данный момент написан код виртуальной машины и реализованы базовые примитивы. Humbug написал серию простых тестов, которые, тем не менее, помогли обнаружить проблемы и в оригинальной версии VM. Реализация бинарно совместима с образами оригинального LST пятой версии.
Месяц работы, 300+ коммитов. А что получилось в итоге, можно узнать под катом.
Но зачем?
 Мне всегда нравился Smalltalk. Своей клинической простотой (да простят меня лисперы и фортеры) и не менее клинически-широкими возможностями. Я считаю, что он незаслуженно забыт сообществом программистов, хотя в 21-м веке из него можно извлечь немало пользы. Однако, существующие промышленные реализации чересчур громоздки для первого знакомства и не блещут красотой своих форм. Встречают, как известно, по одежке. Новичок, впервые увидевший подобный интерфейс, вряд ли будет относиться к нему, как к чему-то современному и новаторскому.
Мне всегда нравился Smalltalk. Своей клинической простотой (да простят меня лисперы и фортеры) и не менее клинически-широкими возможностями. Я считаю, что он незаслуженно забыт сообществом программистов, хотя в 21-м веке из него можно извлечь немало пользы. Однако, существующие промышленные реализации чересчур громоздки для первого знакомства и не блещут красотой своих форм. Встречают, как известно, по одежке. Новичок, впервые увидевший подобный интерфейс, вряд ли будет относиться к нему, как к чему-то современному и новаторскому.Little Smalltalk достаточно компактен, чтобы разобраться в нем за пару часов. В то же время это полноценный Smalltalk, хоть и не являющийся совместимым со стандартами Smalltalk-80 или ANSI-92. С моей точки зрения, грамотная реализация подобной микросистемы могла бы быть хорошим подспорьем в процессе обучения студентов технических ВУЗ-ов. Особенно полезен он в деле изучения ООП, поскольку концепции инкапсуляции, полиморфизма и наследования приобретают здесь совершенно четкое и в то же время очевидное выражение. Многие мои знакомые путались в этих понятиях или не понимали их изначального смысла. Имея же на руках подобный инструмент, можно за 10 минут показать буквально «на пальцах» преимущества ООП и механизмы его работы. Причем, в отличие от других языков, эти принципы не выглядят «притянутыми за уши», поскольку составляют фактическое ядро языка.
В конце концов, довольно забавно иметь нечто, написанное, по сути, само на себе и в 100 КБ, умещающее виртуальную машину, компилятор и стандартную библиотеку с полным кодом всех своих методов.
Однако я заболтался, да и пост не совсем об этом. Поговорим лучше о проекте и его целях. Итак,
Цель №1 Новая VM (Выполнено).
Переписать код Little Smalltalk на C++, устранить недостатки дизайна оригинала, откомментировать код, сделать его читаемым и легко модифицируемым.
К сожалению, код оригинала был написан то ли
Разумеется, так жить было нельзя. Поэтому код был проанализирован, и, в попытке понять Великий Замысел, появилась текущая реализация. Была разработана удобная система типов, шаблоны для контейнеров и шаблонные же указатели на объекты кучи, чтобы не приходилось думать о сборщике при каждом создании объекта. Теперь стало возможным из C++ работать с объектами виртуальной машины так же легко, как и с обычными структурами. Вся работа с памятью, расчет размеров объектов и их правильная инициализация теперь ложатся на плечи компилятора.
В качестве примера приведу код реализации опкода номер 12 «PushBlock».
Так было (форматирование и комментарии автора сохранены):
case PushBlock: DBG0("PushBlock"); /* create a block object */ /* low is arg location */ /* next byte is goto value */ high = VAL; bytePointer += VALSIZE; rootStack[rootTop++] = context; op = rootStack[rootTop++] = gcalloc(x = integerValue(method->data[stackSizeInMethod])); op->class = ArrayClass; memoryClear(bytePtr(op), x * BytesPerWord); returnedValue = gcalloc(blockSize); returnedValue->class = BlockClass; returnedValue->data[bytePointerInContext] = returnedValue->data[stackTopInBlock] = returnedValue->data[previousContextInBlock] = NULL; returnedValue->data[bytePointerInBlock] = newInteger(bytePointer); returnedValue->data[argumentLocationInBlock] = newInteger(low); returnedValue->data[stackInBlock] = rootStack[--rootTop]; context = rootStack[--rootTop]; if(CLASS(context) == BlockClass) { returnedValue->data[creatingContextInBlock] = context->data[creatingContextInBlock]; } else { returnedValue->data[creatingContextInBlock] = context; } method = returnedValue->data[methodInBlock] = context->data[methodInBlock]; arguments = returnedValue->data[argumentsInBlock] = context->data[argumentsInBlock]; temporaries = returnedValue->data[temporariesInBlock] = context->data[temporariesInBlock]; stack = context->data[stackInContext]; bp = bytePtr(method->data[byteCodesInMethod]); stack->data[stackTop++] = returnedValue; /* zero these out just in case GC occurred */ literals = instanceVariables = 0; bytePointer = high; break;
А так стало:
void SmalltalkVM::doPushBlock(TVMExecutionContext& ec) { hptr<TByteObject> byteCodes = newPointer(ec.currentContext->method->byteCodes); hptr<TObjectArray> stack = newPointer(ec.currentContext->stack); // Block objects are usually inlined in the wrapping method code // pushBlock operation creates a block object initialized // with the proper bytecode, stack, arguments and the wrapping context. // Blocks are not executed directly. Instead they should be invoked // by sending them a 'value' method. Thus, all we need to do here is initialize // the block object and then skip the block body by incrementing the bytePointer // to the block's bytecode' size. After that bytePointer will point to the place // right after the block's body. There we'll probably find the actual invoking code // such as sendMessage to a receiver (with our block as a parameter) or something similar. // Reading new byte pointer that points to the code right after the inline block uint16_t newBytePointer = byteCodes[ec.bytePointer] | (byteCodes[ec.bytePointer+1] << 8); // Skipping the newBytePointer's data ec.bytePointer += 2; // Creating block object hptr<TBlock> newBlock = newObject<TBlock>(); // Allocating block's stack uint32_t stackSize = getIntegerValue(ec.currentContext->method->stackSize); newBlock->stack = newObject<TObjectArray>(stackSize, false); newBlock->argumentLocation = newInteger(ec.instruction.low); newBlock->blockBytePointer = newInteger(ec.bytePointer); // Assigning creatingContext depending on the hierarchy // Nested blocks inherit the outer creating context if (ec.currentContext->getClass() == globals.blockClass) newBlock->creatingContext = ec.currentContext.cast<TBlock>()->creatingContext; else newBlock->creatingContext = ec.currentContext; // Inheriting the context objects newBlock->method = ec.currentContext->method; newBlock->arguments = ec.currentContext->arguments; newBlock->temporaries = ec.currentContext->temporaries; // Setting the execution point to a place right after the inlined block, // leaving the block object on top of the stack: ec.bytePointer = newBytePointer; stack[ec.stackTop++] = newBlock; }
И такая ситуация практически со всем кодом. Читаемость, как мне кажется, повысилась, правда ценой некоторого падения производительности. Однако, нормальное профилирование еще не выполнялось, так что тут простор для творчества есть. Плюс, в сети существуют форки lst, которые, как заявляется, имеют бо́льшую производительность.
Цель №2. Интеграция c LLVM.
Некоторые разработчики считают, что JIT для Smalltalk-а малопродуктивен в силу высокой гранулярности его методов. Однако, обычно речь идет о «буквальной» трансляции инструкций виртуальной машины в JIT код.
LLVM же, напротив, помимо собственно JIT, предоставляет широкие возможности по оптимизации кода. Таким образом, основная задача состоит в том, чтобы «объяснить» LLVM, что́ можно оптимизировать и как это лучше сделать.
Мне было интересно, насколько успешно можно применять LLVM в таком «враждебном» окружении (большое количество маленьких методов, сверх-позднее связывание и т.д.). Это следующая крупная задача, которая будет решаться в ближайшее время. Здесь хорошо пригодится опыт humbug в применении LLVM.
Цель №3. Использование в качестве системы управления в embedded устройствах.
Как я уже писал выше, данная разработка не является полностью исследовательской. Одним из реальных мест применения нашей VM может стать модуль управления системой умного дома, который я разрабатываю совместно с другим хабрачеловеком (droot).
Использование Smalltalk в embedded системах не является чем-то из ряда вон. Наоборот, история знает примеры довольно успешного его применения. Например, осцило
 Данное устройство имеет на борту процессор MC68020 + DSP. Код управления написан на Smalltalk, критичные участки на ассемблере. Образ состоит из примерно 250 классов и целиком размещается в ROM. Для работы требуется менее 64 КБ DRAM.
Данное устройство имеет на борту процессор MC68020 + DSP. Код управления написан на Smalltalk, критичные участки на ассемблере. Образ состоит из примерно 250 классов и целиком размещается в ROM. Для работы требуется менее 64 КБ DRAM. Вообще, в плане возможностей использования есть презентация, где описаны многие моменты. Осторожно! Вырвиглазный дизайн и Comic Sans MS.
Цель №4. Попытаться представить, каким может быть Smalltalk «с человеческим лицом».
Алан Кэй, работавший в 80-х годах в лаборатории Xerox PARC разработал язык Smalltalk. Он же заложил основы того, что мы нынче называем графическим пользовательским интерфейсом. Причем первое применение этого интерфейса как раз было в IDE Smalltalk-а. Собственно для него и создавалось. Впоследствии эти наработки были использованы в проектах Lisa и Machintosh другим шустрым малым, которого нынче многие называют «отцом GUI» и PC в придачу.
Суровый VisualAge суров (кликабельно)
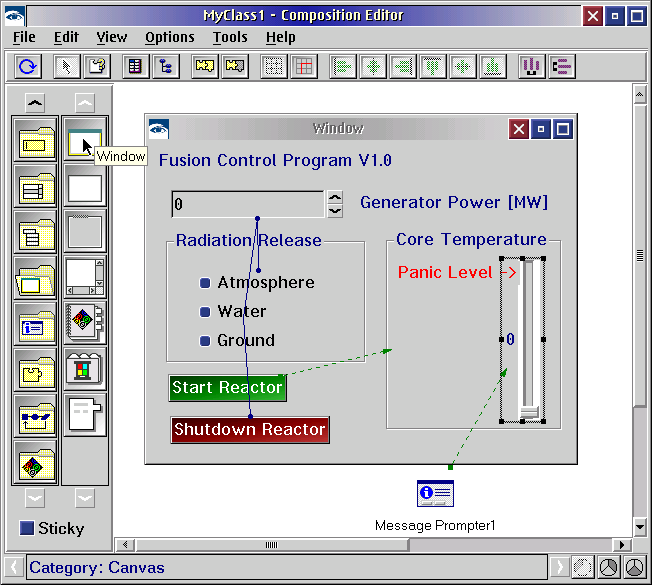
Классический Smalltalk всегда отличался суровостью внешнего вида и квадратно-гнездовым расположением элементов. Суровость интерфейса, соревнующаяся с библиотекой Motif, никогда не добавляла привлекательности.
Нынче же заказчики привыкли к «мокрому полу» и градиентикам, так что свободно использовать Smalltalk для решения задач могут лишь нерды в «профессорских» очках с черепаховой оправой. В качестве средства разработки современных приложений оно не очень годится. Разумеется, если только заказчик сам не является фанатом подобных систем, что маловероятно.
Dolphin
 Практически единственным выбивающимся из стройных рядов Squeak, Pharo и прочих Visual Age является Dolphin Smalltalk, изначально ориентировавшийся на тесную интеграцию с ОС.
Практически единственным выбивающимся из стройных рядов Squeak, Pharo и прочих Visual Age является Dolphin Smalltalk, изначально ориентировавшийся на тесную интеграцию с ОС.К сожалению, он платный, только под винду, а community версия кастрирована ржавыми садовыми ножницами по самое небалуй. После проделывания ряда заданий из документации (хорошей, кстати), делать становится решительно нечего. Писать свои классы, да и только. Community версия не дает нормальных возможностей по созданию пользовательского интерфейса. В итоге мы имеем быстрые нативные виджеты, прозрачные вызовы WinAPI и нулевую портабельность. Отличная разработка, которую никак не хотят выпустить на волю из бездны финансовой оккупации.
В рамках проекта LLST я хочу заняться интеграцией библиотеки Qt, а так же поэкспериментировать в плане пользовательского интерфейса. Впоследствии библиотека может быть портирована на промышленный Smalltalk.
Где взять исходники и что с ними делать?
Раз вы дочитали до этого места (что само по себе удивительно!), то наверное желаете получить исходники. Их есть у меня! Основной рабочий репозиторий в настоящее время располагается на
Примечание 1: В силу своей специфики, код собирается в 32-битном режиме. Поэтому для сборки и запуска на x64, необходимы 32 битные библиотеки (
ia32-libs в случае Ubuntu), а так же библиотека g++-multilib.sudo apt-get install ia32-libs g++-multilib
Примечание 2: Кто не хочет мучаться с компиляцией может скачать готовый статически собранный пакет на странице релизов.
UPD: Новые правила сборки лучше почитать в разделе Usage на главной странице репозитория (не забыв почитать раздел LLVM).
Собирать так:
~ $ git clone https://github.com/0x7CFE/llst.git ~ $ cd llst ~/llst $ mkdir build && cd build ~/llst/build $ cmake .. ~/llst/build $ make llst
При правильной фазе луны и личной удаче, в директории build обнаружится исполняемый файл llst, коий можно использовать во благо.
Например так:
build$ ./llst
Если все хорошо, то вывод должен быть примерно таким:
много буков
Image read complete. Loaded 4678 objects Running CompareTest equal(1) OK equal(2) OK greater(int int) OK greater(int symbol) ERROR true (class True): does not understand asSmallInt VM: error trap on context 0xf728d8a4 Backtrace: error:(True, String) doesNotUnderstand:(True, Symbol) =(SmallInt, True) assertEq:withComment:(Block, True, String) assertWithComment:(Block, String) greater(CompareTest) less(int int) OK less(symbol int) OK nilEqNil OK nilIsNil OK Running SmallIntTest add OK div OK mul OK negated(1) OK negated(2) OK negative(1) OK negative(2) OK quo(1) OK quo(2) OK sub OK Running LoopTest loopCount OK sum OK symbolStressTest OK Running ClassTest className(1) OK className(2) OK sendSuper OK Running MethodLookupTest newline(Char) OK newline(String) OK parentMethods(1) OK parentMethods(2) OK Running StringTest asNumber OK asSymbol OK at(f) OK at(o) OK at(X) OK at(b) OK at(A) OK at(r) OK copy OK indexOf OK lowerCase OK plus(operator +. 1) OK plus(2) OK plus(3) OK plus(4) OK plus(5) OK plus(6) OK plus(7) OK plus(8) OK plus(9) OK reverse OK size(1) OK size(2) OK size(3) OK size(4) OK Running ArrayTest at(int) OK at(char) OK atPut OK Running GCTest copy OK Running ContextTest backtrace(1) OK backtrace(2) OK instanceClass OK Running PrimitiveTest SmallIntAdd OK SmallIntDiv OK SmallIntEqual OK SmallIntLess OK SmallIntMod OK SmallIntMul OK SmallIntSub OK bulkReplace OK objectClass(SmallInt) OK objectClass(Object) OK objectSize(SmallInt) OK objectSize(Char) OK objectSize(Object) OK objectsAreEqual(1) OK objectsAreEqual(2) OK smallIntBitAnd OK smallIntBitOr OK smallIntShiftLeft OK smallIntShiftRight OK ->
Наблюдаемая ошибка относится к коду образа, а не является проблемой в VM. То же самое поведение наблюдается и при запуске тестового образа на оригинальном lst5.
Далее можно поиграться с образом и поговорить с ним:
-> 2 + 3 5 -> (2+3) class SmallInt -> (2+3) class parent Number -> Object class MetaObject -> Object class class Class -> 1 to: 10 do: [ :x | (x * 2) print. $ print ] 2 4 6 8 10 12 14 16 18 20 1
…и так далее. полезными так же являются методы
listMethods, viewMethod и allMethods:-> Collection viewMethod: #collect: collect: transformBlock | newList | newList <- List new. self do: [:element | newList addLast: (transformBlock value: element)]. ^ newList
У любого класса можно спросить о родителе (через
parent) и о потомках:-> Collection subclasses Array ByteArray MyArray OrderedArray String Dictionary MyDict Interval List Set IdentitySet Tree Collection ->
Завершить работу можно, послав сочетание Ctrl+D:
-> Exited normally GC count: 717, average allocations per gc: 25963, microseconds spent in GC: 375509 9047029 messages sent, cache hits: 4553006, misses: 53201, hit ratio 98.85 %
В общем, много чего интересного может рассказать о себе образ. Еще больше можно найти в его исходниках, которые лежат в файле llst/image/imageSource.st.
Для удобного восприятия, мной была написана схема подсветки синтаксиса для Katepart, которая лежит все в том же репозитории по адресу: llst/misc/smalltalk.xml. Чтобы она заработала, нужно скопировать этот файл в директорию /usr/share/kde4/apps/katepart/syntax/ либо в аналог в ~/.kde и перезапустить редактор. Будет работать во всех редакторах, использующих Katepart: Kate, Kwrite, Krusader, KDevelop и т.д.
Заключение
Надеюсь, я не утомил вас пространными размышлениями на тему смолтока и его места в арсенале программиста. Очень хочу услышать отзывы на тему проекта в целом и читаемости его исходников в частности.
В следующей статье рассматривается сам язык Smalltalk и даются основные концепции, необходимые для успешного чтения исходников. Затем последует серия статей, где я распишу более подробно внутреннее устройство виртуальной машины и сконцентрируюсь на представлении объектов в памяти. Наконец финальные статьи скорее всего, будут посвящены результатам работы с LLVM и Qt. Спасибо за внимание! :)
 P.S.: В настоящий момент я ищу место для возмездного приложения своих сил (работу, то есть). Если у вас имеются интересные проекты (особенно подобного же плана), прошу стучаться в личку. Сам я нахожусь в Новосибирском академгородке.
P.S.: В настоящий момент я ищу место для возмездного приложения своих сил (работу, то есть). Если у вас имеются интересные проекты (особенно подобного же плана), прошу стучаться в личку. Сам я нахожусь в Новосибирском академгородке.