Бывало ли когда-нибудь так, что вы набирали в браузере длинный и интересный текст, внимательно вычитывали его, и тут, буквально через мгновение, понимали, что при обращении к сайту произошла ошибка, а ваш текст в форме был стёрт?
В основном такое бывает из-за невнимательности разработчиков сайтов (под разработчиками я в данном случае подразумеваю не только программиста, который мог не знать о нужном способе, но и, например, менеджера, который посчитал, что тратить на это время слишком нецелесообразно): современные веб-технологии (например, Web Storage) позволяют сохранять и восстанавливать данные (в том числе данные форм) при почти любых обстоятельствах — вплоть до случайного закрытия браузера.
И, тем не менее, вы писали длинный текст именно там, где ничего для сохранения данных формы не сделано.
Можно ли теперь как-то восстановить данные, если вы не можете скопировать текст из формы и не можете отправить POST-запрос повторно?
Не закрывайте браузер!
Если дело происходит в Linux, то вы можете воспользоваться потрясающе удобным способом сделать дамп области памяти, которую использует браузер. Впервые я прочитал о применении этого метода для восстановления данных, потерянных в браузере, на superuser.com — одном из сайтов StackExchange. Это был ответ пользователя с именем Joey Adams на вопрос «How do I recover a form in Firefox *without* installing a plugin?».
Кстати, работает этот способ не только в Linux.
Для Windows, спасибо Lord_D:
Для Mac, спасибо BeLove:
Итак, начнём.
Убедитесь, что у вас установлен gdb (GNU Debugger). Вам понадобится утилита gcore, которая может делать дамп оперативной памяти, которую использует запущенный процесс с определённым PID.
Вы ведь не закрывали браузер? В таком случае выясните номер процесса:
Теперь запустите gcore, чтобы создать дамп памяти для этого процесса:
Если ptrace при попытке использовать gcore выдаёт ошибку (
В текущем каталоге при запуске gcore появляется файл core.номер_процесса (например, core.20727). Кстати, учитывайте, что размер файла может быть очень большим. Например, у меня он сейчас получился 934 MiB.
Теперь попробуйте с помощью grep проверить, есть ли в дампе нужные данные. Например, если в тексте вы упоминали браузер Safari, то вы можете искать по слову «Safari»:
Если вы видите сообщение о том, что в файле есть совпадение (
Теперь остаётся извлечь из двоичного файла нужные вам куски с текстом.
Сделать это можно вот так:
В данном случае вы сообщаете grep, что с данным двоичным файлом требуется работать как с текстом, а также что для каждого совпадения требуется вывести 20 предшествующих и 20 последующих строк.
Теперь откройте получившийся файл и найдите в нём свой текст. Например, с помощью
Всем приятного вечера. И не забывайте про Ctrl + S. :)
В основном такое бывает из-за невнимательности разработчиков сайтов (под разработчиками я в данном случае подразумеваю не только программиста, который мог не знать о нужном способе, но и, например, менеджера, который посчитал, что тратить на это время слишком нецелесообразно): современные веб-технологии (например, Web Storage) позволяют сохранять и восстанавливать данные (в том числе данные форм) при почти любых обстоятельствах — вплоть до случайного закрытия браузера.
И, тем не менее, вы писали длинный текст именно там, где ничего для сохранения данных формы не сделано.
Можно ли теперь как-то восстановить данные, если вы не можете скопировать текст из формы и не можете отправить POST-запрос повторно?
Не закрывайте браузер!
Решение есть
Если дело происходит в Linux, то вы можете воспользоваться потрясающе удобным способом сделать дамп области памяти, которую использует браузер. Впервые я прочитал о применении этого метода для восстановления данных, потерянных в браузере, на superuser.com — одном из сайтов StackExchange. Это был ответ пользователя с именем Joey Adams на вопрос «How do I recover a form in Firefox *without* installing a plugin?».
Кстати, работает этот способ не только в Linux.
Для Windows, спасибо Lord_D:
Дампы очень просто делаются Process Explorer'ом. Для консоли есть PMDump. А изучать дамп можно каким-нибудь HEX-редактором (к примеру, из бесплатных — HxD) или тем же grep.
Для Mac, спасибо BeLove:
lldb --attach-pid PID
Итак, начнём.
Шаг 1
Убедитесь, что у вас установлен gdb (GNU Debugger). Вам понадобится утилита gcore, которая может делать дамп оперативной памяти, которую использует запущенный процесс с определённым PID.
Шаг 2
Вы ведь не закрывали браузер? В таком случае выясните номер процесса:
ps -e | grep firefoxТеперь запустите gcore, чтобы создать дамп памяти для этого процесса:
gcore номер_процессаЕсли ptrace при попытке использовать gcore выдаёт ошибку (
Operation not permitted) — это означает, что в вашей системе процессы не могут обращаться к памяти других процессов, не являясь их дочерними процессами (даже при совпадении UID). Например, такую ошибку вы увидите в последних версиях Ubuntu, если вы не меняли соответствующее значение в файле /proc/sys/kernel/yama/ptrace_scope. Вообще говоря, в данном случае совершенно необязательно что-то перенастраивать — вы можете просто запустить gcore от имени суперпользователя.Шаг 3
В текущем каталоге при запуске gcore появляется файл core.номер_процесса (например, core.20727). Кстати, учитывайте, что размер файла может быть очень большим. Например, у меня он сейчас получился 934 MiB.
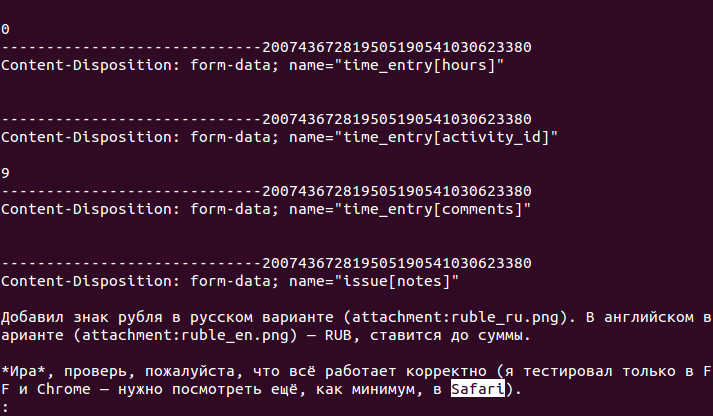
Теперь попробуйте с помощью grep проверить, есть ли в дампе нужные данные. Например, если в тексте вы упоминали браузер Safari, то вы можете искать по слову «Safari»:
grep 'Safari' core.20727Если вы видите сообщение о том, что в файле есть совпадение (
Binary file core.20727 matches) — это очень хорошая новость, переходите к четвёртому шагу. Если совпадения не нашлось — вспомните, что ещё было в тексте, и попробуйте указать что-нибудь другое.Шаг 4
Теперь остаётся извлечь из двоичного файла нужные вам куски с текстом.
Сделать это можно вот так:
grep -B 20 -A 20 -a 'Safari' core.20727 > /tmp/outВ данном случае вы сообщаете grep, что с данным двоичным файлом требуется работать как с текстом, а также что для каждого совпадения требуется вывести 20 предшествующих и 20 последующих строк.
Шаг 5
Теперь откройте получившийся файл и найдите в нём свой текст. Например, с помощью
less /tmp/out:Всем приятного вечера. И не забывайте про Ctrl + S. :)
