
Вещь, которая привлекла меня изучать компьютерную науку была компилятором. Я думал, что это все магия, как они могут читать даже мой плохо написанный код и компилировать его. Когда я прошел курс компиляторов, я стал находить этот процесс очень простым и понятным.
Содержание
Простой интерпретатор с нуля на Python #1
Простой интерпретатор с нуля на Python #2
Простой интерпретатор с нуля на Python #3
Простой интерпретатор с нуля на Python #4
Простой интерпретатор с нуля на Python #2
Простой интерпретатор с нуля на Python #3
Простой интерпретатор с нуля на Python #4
В этом цикле статей я попытаюсь захватить часть этой простоты путем написания простого интерпретатора для обычного императивного языка IMP (IMperative Language). Интерпретатор будет написан на Питоне, потому что это простой и широко известный язык. Также, питон-код похож на псевдокод, и даже если вы не знаете его [питон], у вас получится понять код. Парсинг будет выполнен с помощью простого набора комбинаторов, написанных с нуля (подробнее расскажу в следующей части). Никаких дополнительных библиотек не будет использовано, кроме sys (для I/O), re (регулярные выражения в лексере) и unittest (для проверки работоспособности нашей поделки).
Сущность языка IMP
Прежде всего, давайте обсудим, для чего мы будем писать интерпретатор. IMP есть нереально простой язык со следующими конструкциями:
Присвоения (все переменные являются глобальные и принимают только integer):
x := 1
Условия:
if x = 1 then y := 2 else y := 3 end
Цикл while:
while x < 10 do x := x + 1 end
Составные операторы (разделенные ;):
x := 1; y := 2
Это всего-лишь игрушечный язык. Но вы можете расширить его до уровня полезности как у Python или Lua. Я лишь хотел сохранить его настолько простым, насколько смогу.
А вот тут пример программы, которая вычисляет факториал:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end
Язык IMP не умеет читать входные данные (input), т.е. в начале программы нужно создать все нужные переменные и присвоить им значения. Также, язык не умеет выводить что-либо: интерпретатор выведет результат в конце.
Структура интерпретатора
Ядро интерпретатора является ничем иным, как промежуточным представлением (intermediate representation, IR). Оно будет представлять наши IMP-программы в памяти. Так как IMP простой как 3 рубля, IR будет напрямую соответствовать синтаксису языка; мы создадим по классу для каждой единицы синтаксиса. Конечно, в более сложном языке вы хотели бы использовать еще и семантическую представление, которое намного легче для анализа или исполнения.
Всего три стадии интерпретации:
- Разобрать символы исходного кода на токены.
- Собрать все токены в абстрактное синтаксическое дерево (abstract syntax tree, AST). AST и есть наша IR.
- Исполнить AST и вывести результат в конце.
Процессом разделения символов на токены называется лексинг (lexing), а занимается этим лексер (lexer). Токены являют собой короткие, удобоваримые строки, содержащие самые основные части программы, такие как числа, идентификаторы, ключевые слова и операторы. Лексер будет пропускать пробелы и комментарии, так как они игнорируются интерпретатором.
Процесс сборки токенов в AST называется парсингом. Парсер извлекает структуру нашей программы в форму, которую мы можем исполнить.
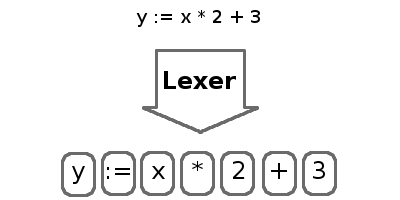
Эта статься будет сосредоточена исключительно на лексере. Сначала мы напишем общую лекс-библиотеку а затем уже лексер для IMP. Следующие части будут сфокусированы на парсере и исполнителе.
Лексер
По правде говоря, лексические операции очень просты и основываются на регулярных выражениях. Если вы с ними не знакомы, то можете прочитать официальную документацию.
Входными данными для лексера будет простой поток символов. Для простоты мы прочитаем инпут в память. А вот выходящими данными будет список токенов. Каждый токен включает в себя значение и метку (тег, для идентификации вида токена). Парсер будет использовать это для построения дерева (AST).
Итак, давайте сделаем обычнейший лексер, который будет брать список регэкспов и разбирать на теги код. Для каждого выражения он будет проверять, соответствует ли инпут текущей позиции. Если совпадение найдено, то соответствующий текст извлекается в токен, наряду с тегом регулярного выражения. Если регулярное выражение ни к чему не подходит, то текст отбрасывается. Это позволяет нам избавиться от таких вещей как комментарии и пробелы. Если вообще ничего не совпало, то мы рапортуем об ошибке и скрипт становится героем. Этот процесс повторяется, пока мы не разберем весь поток кода.
Вот код из библиотеки лексера:
import sys import re def lex(characters, token_exprs): pos = 0 tokens = [] while pos < len(characters): match = None for token_expr in token_exprs: pattern, tag = token_expr regex = re.compile(pattern) match = regex.match(characters, pos) if match: text = match.group(0) if tag: token = (text, tag) tokens.append(token) break if not match: sys.stderr.write('Illegal character: %s\n' % characters[pos]) sys.exit(1) else: pos = match.end(0) return tokens
Отметим, что порядок передачи в регулярные выражения является значительным. Функция lex будет перебирать все выражения и примет только первое найденное совпадение. Это значит, что при использовании этой функции, первым делом нам следует передавать специфичные выражения (соответствующие операторам и ключевым словам), а затем уже обычные выражения (идентификаторы и числа).
Лексер IMP
С учетом кода выше, создание лексера для нашего языка становится очень простым. Для начала определим серию тегов для токенов. Для языка нужно всего лишь 3 тега. RESERVED для зарезервированных слов или операторов, INT для чисел, ID для идентификаторов.
import lexer RESERVED = 'RESERVED' INT = 'INT' ID = 'ID'
Теперь мы определим выражения для токенов, которые будут использованы в лексере. Первые два выражения соответствуют пробелам и комментариям. Так как у них нету тегов, лексер их пропустит.
token_exprs = [ (r'[ \n\t]+', None), (r'#[^\n]*', None),
После этого следуют все наши операторы и зарезервированные слова.
(r'\:=', RESERVED), (r'\(', RESERVED), (r'\)', RESERVED), (r';', RESERVED), (r'\+', RESERVED), (r'-', RESERVED), (r'\*', RESERVED), (r'/', RESERVED), (r'<=', RESERVED), (r'<', RESERVED), (r'>=', RESERVED), (r'>', RESERVED), (r'=', RESERVED), (r'!=', RESERVED), (r'and', RESERVED), (r'or', RESERVED), (r'not', RESERVED), (r'if', RESERVED), (r'then', RESERVED), (r'else', RESERVED), (r'while', RESERVED), (r'do', RESERVED), (r'end', RESERVED),
Наконец, нам нужны выражения для чисел и идентификаторов. Обратите внимание, что регулярным выражениям для идентификаторов будут соответствовать все зарезервированные слова выше, поэтому очень важно, чтобы эти две строчки шли последними.
(r'[0-9]+', INT), (r'[A-Za-z][A-Za-z0-9_]*', ID), ]
Когда наши регэкспы определены, мы можем создать обертку над функцией lex:
def imp_lex(characters): return lexer.lex(characters, token_exprs)
Если вы дочитали до этих слов, то вам, скорее всего, будет интересно как работает наше чудо. Вот код для теста:
import sys from imp_lexer import * if __name__ == '__main__': filename = sys.argv[1] file = open(filename) characters = file.read() file.close() tokens = imp_lex(characters) for token in tokens: print token
$ python imp.py hello.imp
Скачать полный исходный код: imp-interpreter.tar.gz
Автор оригинальной статьи — Jay Conrod.
UPD: Спасибо пользователю zeLark за исправление бага, связанного с порядком определения шаблонов.
