Функциональное тестирование интерфейса (GUI) приложений — задача очень важная, нужная, но не всегда тривиальная. Основной вопрос тут: как сэмулировать работу пользователя? Простого, рядового пользователя, которому придется непосредственно изо дня в день работать с вашим софтом.
Казалось бы, причем здесь распознавание текстов?
А что, если сделать снимок экрана, запомнить некоторую область и в качестве проверки распознать текст в этой области. Если в заданной области есть ожидаемый текст, то можно туда кликнуть.
Звучит неплохо, надо пробовать.
Для начала необходимо выбрать движок для распознавания текстов или написать его самому. Писать самому — задача нетривиальная, поэтому возьмем что-то готовое и желательно Open Source. Ну что ж, для начала почитаем мануалы.
Есть такое чудо под названием Tesseract OCR. И к нему есть API-обертка на .NET! Звучит просто, но не все так просто: фоткаем, распознаем и… ничего — Tesseract не увидел в нашем снимке текста! Если быть точнее, не увидел на куске снимка.
Покопавшись немногов тонкостях и механизмах распознавания в интернете, я нашел это: stackoverflow.com/questions/9480013/image-processing-to-improve-tesseract-ocr-accuracy.
Получается, надо сначала сделать:
А уже потом пробовать что-то там распознавать!
Тут нам на помощь пришла библиотека AForge.NET. Она, кстати, Open Source, как и Tesseract.
Поясню по пунктам:
Теперь гораздо лучше.
Ядро программки уже готово, осталосьсовсем чуть-чуть и все будет круто написать приложение с неким подобием тест дизайнера, где можно разметить области экрана и сохранить в некое подобие тест плана. И написать проигрыватель тестов. Делов-то, на 15 минутЗдесь конечно пришлось повозиться, но это тема другой статьи.
В итоге, соединяя все вместе, получился и простенький дизайнер тестов и простенький проигрыватель.
Это скриншот той части программки, которую я называю Тест дизайнер!
А это видео работы программки — записываем простенький тест и запускаем его!
Вот собственно и всё!
Ах да!
Исходники проекта: github.com/skaeff/miranda-tester
Собранная версия с английским и русским словарями: github.com/skaeff/miranda-tester/blob/master/miranda-tester-net40-compiled.7z
Краткое резюме:
И да, для скриншота нажимаем Shift+Esc.
Казалось бы, причем здесь распознавание текстов?
Как и чем обычно тестируют и автоматизируют
В общем, тут скучный текст, основанный большей частью на опыте
Обычно отталкиваются от того софта, который надо автоматизировать. Например, для Win приложений можно посмотреть в сторону MSAA и его развития UI Automation. Этот фреймворк неплохо распознает элементы управления и экранный текст посредством API. Web приложения можно «потыкать» Selenium-ом или WatiN-ом и т. п.
Подобные способы не всегда подходят, например когда пользователь работает с приложением через удаленный рабочий стол, или Web приложение «нашпигованно» сторонними контроллами (ActiveX, Java applets и т. п.).
Очень хорошо данная проблематика описана здесь, а список софта — здесь.
Подобные способы не всегда подходят, например когда пользователь работает с приложением через удаленный рабочий стол, или Web приложение «нашпигованно» сторонними контроллами (ActiveX, Java applets и т. п.).
Очень хорошо данная проблематика описана здесь, а список софта — здесь.
Идея
мы пойдем другим путем ©Маяковский
А что, если сделать снимок экрана, запомнить некоторую область и в качестве проверки распознать текст в этой области. Если в заданной области есть ожидаемый текст, то можно туда кликнуть.
Звучит неплохо, надо пробовать.
И тернистый путь реализации
Для начала необходимо выбрать движок для распознавания текстов или написать его самому. Писать самому — задача нетривиальная, поэтому возьмем что-то готовое и желательно Open Source. Ну что ж, для начала почитаем мануалы.
Есть такое чудо под названием Tesseract OCR. И к нему есть API-обертка на .NET! Звучит просто, но не все так просто: фоткаем, распознаем и… ничего — Tesseract не увидел в нашем снимке текста! Если быть точнее, не увидел на куске снимка.
Как сделать снимок прямоугольной области экрана
public static Bitmap GetAreaFromScreen(Rectangle area) { var rect = new Rectangle(area.X, area.Y, area.Width, area.Height); var bmp = new Bitmap(rect.Width, rect.Height, PixelFormat.Format24bppRgb); using (var g = Graphics.FromImage(bmp)) g.CopyFromScreen(rect.Left, rect.Top, 0, 0, bmp.Size, CopyPixelOperation.SourceCopy); return bmp; }
Кусок 'плохого' кода, который ничего не распознал
public string RecognizeText(Bitmap source) { try { using (var page = engine.Process(source, PageSegMode.SingleLine)) { var text = page.GetText(); var conf = page.GetMeanConfidence(); threshold = conf; return text; } } catch (Exception e) { Trace.TraceError(e.ToString()); return ""; } }
Покопавшись немного
Получается, надо сначала сделать:
1. fix DPI (if needed) 300 DPI is minimum
2. fix text size (e.g. 12 pt should be ok)
3. try to fix text lines (deskew and dewarp text)
4. try to fix illumination of image (e.g. no dark part of image
5. binarize and de-noise image
А уже потом пробовать что-то там распознавать!
Тут нам на помощь пришла библиотека AForge.NET. Она, кстати, Open Source, как и Tesseract.
кусок 'хорошего' кода с магией AForge
public string RecognizeText(Bitmap source) { try { var seq = new FiltersSequence(); seq.Add(new ResizeBilinear(source.Width * 2, source.Height * 2)); seq.Add(new Grayscale(0.2126, 0.7152, 0.0722)); seq.Add(new OtsuThreshold()); seq.Add(new Threshold(100)); temp = seq.Apply(source); using (var page = engine.Process(temp, PageSegMode.SingleLine)) { var text = page.GetText(); var conf = page.GetMeanConfidence(); threshold = conf; return text; } } catch (Exception e) { Trace.TraceError(e.ToString()); return ""; } }
Поясню по пунктам:
- DPI — у скриншота DPI норм, нам хватит;
- fix text size — тут зависит от размера шрифта, иногда надо увеличить, иногда сделать потолще или повыше. ResizeBilinear в помощь;
- try to fix text lines — тут зависит от точности выделенной области экрана. Выделяем текст прицельно, стараясь не зацепить «артефакты» — ручная работа;
- try to fix illumination of image — Grayscale да и все тут!
- binarize and de-noise image — бинаризуем и дешумизуем (!) OtsuThreshold и Threshold(100).
Теперь гораздо лучше.
Ядро программки уже готово, осталось
В итоге, соединяя все вместе, получился и простенький дизайнер тестов и простенький проигрыватель.
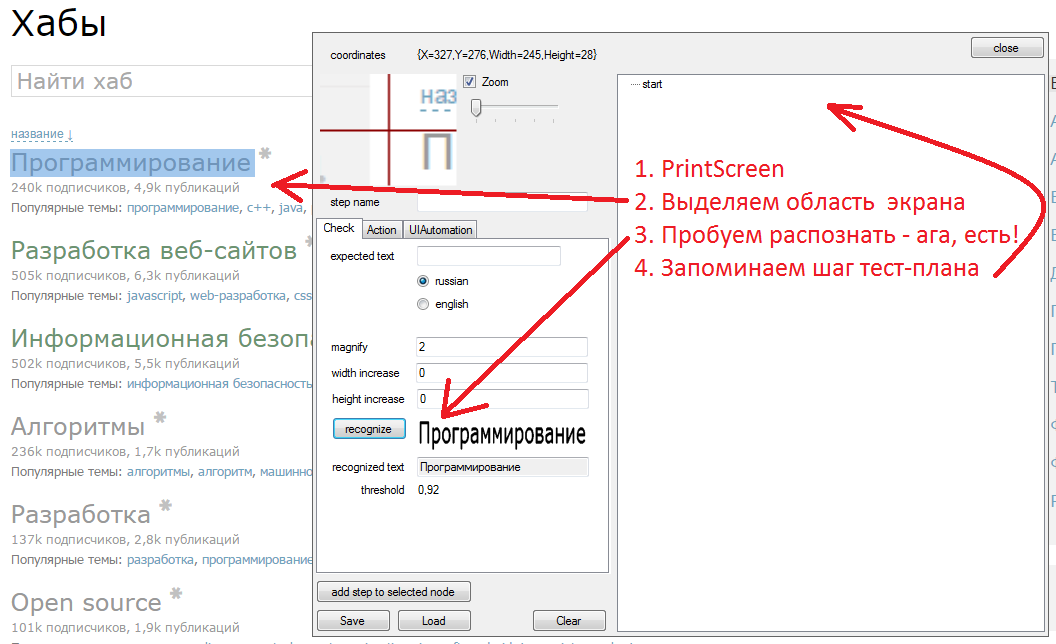
А теперь скриншот из которого ничего непонятно и видео без звука
Это скриншот той части программки, которую я называю Тест дизайнер!
А это видео работы программки — записываем простенький тест и запускаем его!
Вот собственно и всё!
Ах да!
Исходники, ТТХ и прочее
Исходники проекта: github.com/skaeff/miranda-tester
Собранная версия с английским и русским словарями: github.com/skaeff/miranda-tester/blob/master/miranda-tester-net40-compiled.7z
Краткое резюме:
- Tesseract OCR github.com/tesseract-ocr/tesseract — библиотека оптического распознавания текстов;
- AForge.Net www.aforgenet.com — библиотека обработки изображений;
- Немного логики, написанной на C#.
И да, для скриншота нажимаем Shift+Esc.
