Измерение пропускной способности узких мест по времени двойного прохода пакета
По всем параметрам, сегодняшний интернет не может перемещать данные так быстро, как должен. Большинство пользователей сотовой связи в мире испытывают задержки от нескольких секунд до нескольких минут: публичные точки WiFi в аэропортах и на конференциях ещё хуже. Физикам и климатологам нужно обмениваться петабайтами данных с коллегами по всему миру, но они сталкиваются с тем, что их тщательно продуманная многогигабитная инфраструктура часто выдаёт всего несколько мегабит в секунду на трансконтинентальных линиях. [6]
Эти проблемы возникли из-за выбора архитектуры, который был сделан при создании системы регулирования заторов TCP в 80-е годы — тогда потерю пакетов решили интерпретировать как «затор». [13] Эквивалентность этих понятий была справедливой для того времени, но только из-за ограничений технологии, а не по определению. Когда NIC (контроллеры сетевых интерфейсов) модернизировали с мегабитных до гигабитных скоростей, а микросхемы памяти — с килобайт до гигабайт, до связь между потерей пакетов и заторами стала менее очевидной.
В современном TCP регулирование заторов по потере пакетов — даже в наиболее совершенной технологии такого рода CUBIC [11] — основная причина этих проблем. Если буферы узких мест слишком большие, то система регулирования заторов по потере пакетов держит их полными, вызывая излишнюю сетевую буферизацию. Если буферы слишком маленькие, то система регулирования заторов по потере пакетов неверно интерпретирует потерю пакета как сигнал затора, что ведёт к снижению пропускной способности. Решение этих проблем требует альтернативы регулированию заторов по потере пакетов. Для нахождения этой альтернативы следует разобраться, где и как возникают заторы.
Затор и узкое место
В любой момент времени в (полнодуплексное) соединении TCP есть только одно самое медленное звено или узкое место в каждом направлении. Узкое место важно по следующим причинам:
- Оно определяет максимальную скорость передачи данных по соединению. Это главное свойство несжатого потока данных (например, представьте шестиполосное шоссе в час пик, если из-за ДТП один небольшой отрезок дороги ограничен всего одной полосой. Трафик перед местом ДТП будет двигаться не быстрее, чем трафик через эту полосу.
- Это то место, где постоянно образуются очереди. Они уменьшаются только в том случае, если интенсивность исходящего потока из «бутылочного горлышка» превысит интенсивность входящего потока. Для соединений, работающих на максимальной скорости передачи все исходящие потоки к узкому месту всегда имеют более высокую интенсивность исходящего потока, так что очереди перемещаются к «бутылочному горлышку».
Независимо от того, сколько линков в соединении и какие у них скорости по отдельности, с точки зрения TCP сколь угодно сложный маршрут представляется как единое соединение с одинаковым RTT (время двойного прохода пакета, то есть время прохождения в оба конца) и пропускной способностью узкого места. Два физических ограничения, RTprop (round-trip propagation time, время двойного прохода пакета) и BtlBw (bottleneck bandwidth, пропускная способность узкого места), влияют на производительность передачи. (Если бы сетевой путь был материальной трубой, RTprop был бы длиной трубы, а BtlBw — её диаметром).
На иллюстрации 1 показаны разнообразные сочетания RTT и скорости передачи с объёмом данных в полёте, то есть inflight (данные отправлены, но без подтверждения доставки). Синие линии показывают ограничение RTprop, зелёные линии — ограничение BtlBw, а красные линии — буфер узкого места. Операции в серых областях невозможны, поскольку противоречат хотя бы одному ограничению. Переходы между ограничениями привели к образованию трёх районов (app-limited, bandwidth-limited и buffer-limited) с качественно разным поведением.
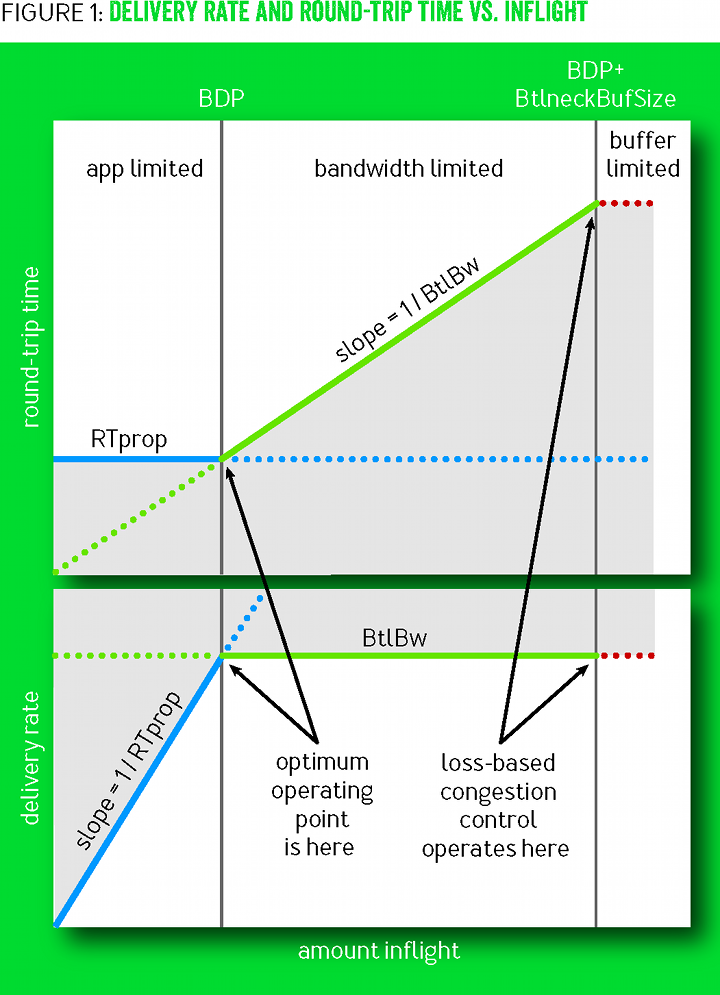
Рисунок 1
Когда в полёте недостаточно данных, чтобы заполнить трубу, RTprop определяет поведение; в противном случае доминирует BtlBw. Линии ограничения пересекаются в точке
 , она же BDP трубы (bandwidth-delay product, производное пропускной способности и задержки). Поскольку труба полная после этой точки, то излишек
, она же BDP трубы (bandwidth-delay product, производное пропускной способности и задержки). Поскольку труба полная после этой точки, то излишек  создаёт очередь к узкому месту, что приводит к линейной зависимости RTT от данных inflight, показанной на верхнем графике. Пакеты отбрасываются, когда излишек превышает вместимость буфера. Затор — это просто непрерывное нахождение справа от линии BDP, а регулирование заторов — некая схема для установления ограничения, как далеко справа от линии BDP, в среднем, происходит передача данных.
создаёт очередь к узкому месту, что приводит к линейной зависимости RTT от данных inflight, показанной на верхнем графике. Пакеты отбрасываются, когда излишек превышает вместимость буфера. Затор — это просто непрерывное нахождение справа от линии BDP, а регулирование заторов — некая схема для установления ограничения, как далеко справа от линии BDP, в среднем, происходит передача данных.Регулирование заторов по потерям работает на правой границе района, ограниченного пропускной способностью канала (bandwidth-limited), обеспечивая полную пропускную способность узкого места за счёт больших задержек и частой потери пакетов. В те времена, когда память была дорога, размеры буфера лишь немного превышали BDP, что минимизировало избыточную задержку регулирования заторов по потерям. Последующие снижения цен на память привели к увеличению излишней сетевой буферизации и росту RTT до секунд вместо миллисекунд. [9]
На левом краю района, ограниченного пропускной способностью канала, есть рабочая точка с лучшими условиями, чем справа. В 1979 году Леонард Клейнрок [16] показал, что данная рабочая точка оптимальна, она максимизирует фактическую пропускную способность с минимизацией задержек и потерь, как для отдельных соединений, так и для сети в целом [8]. К сожалению, примерно в то же время Джеффри Яффе доказал, что невозможно создать распределённый алгоритм, который сходится в этой рабочей точке. Этот вывод изменил направление исследований. Вместо поиска распределённого алгоритма, который стремится к оптимальной рабочей точки Клейнрока, исследователи начали изучать альтернативные подходы к регулированию заторов.
Наша группа в компании Google каждый день тратит часы на изучение логов с перехватами заголовков пакетов TCP со всего мира, осмысляя аномалии и патологии поведения. Обычно мы первым делом ищем ключевые характеристики маршрута, RTprop и BtlBw. То, что их можно вывести из сетевых трейсов, позволяет предположить, что вывод Яффе мог быть не таким однозначным, как когда-то казалось. Его вывод полагается на фундаментальную неопределённость измерения (например, будь измеренное увеличение RTT вызвано изменением длины пути, уменьшением пропускной способности узкого места или увеличением задержки в очереди из-за трафика от другого соединения). Хотя невозможно устранить неопределённость каждого конкретного измерения, но поведение соединения во времени даёт более ясную картину, подсказывая возможность применения стратегий измерений, созданных для устранения неопределённости.
Совместив эти измерения с надёжным следящим контуром, применив последние достижения в системах управления [12], можно надеяться на разработку распределённого протокола регулирования заторов, который реагирует на действительный затор, а не на потерю пакетов или кратковременную задержку в очереди. И он будет с высокой вероятностью сходиться в оптимальной рабочей точке Клейнрока. Так начался наш трёхлетний проект по разработке системы управления заторами на основе измерения двух параметров, которые характеризуют маршрут: пропускной способности узкого места и времени двойного прохода пакета, или BBR.
Характеристика узкого места
Соединение работает с максимальной пропускной способностью и минимальной задержкой, когда (баланс скорости) скорость прибытия пакетов к узкому месту равняется BtlBw и (полный канал) общее количество данных в полёте равняется BDP (
 ).
).Первое условие гарантирует, что узкое место используется на 100%. Второе гарантирует, что у нас достаточно данных, чтобы предотвратить простой узкого места, но не переполнить канал. Условие баланса скорости само по себе не гарантирует отсутствия очереди, только её неизменный размер (например, если соединение начинается с отправки 10-пакетного Initial Window в пятипакетный BDP, затем работает в точности на одинаковой скорости узкого места, то пять из десяти начальных пакетов заполнят канал, а излишек сформирует стоячую очередь в узком месте, которая не сможет рассосаться). Точно так же, условие полного канала не гарантирует отсутствия очереди (например, соединение отправляет BDP всплесками по BDP/2 и полностью использует узкое место, но но средняя очередь составляет BDP/4). Единственный способ минимизировать очередь в узком месте и по всему каналу — это соответствовать обоим условиям одновременно.
Значения BtlBw и RTprop изменяются в течение срока жизни соединения, так что их следует постоянно оценивать. В настоящее время TCP отслеживает RTT (интервал времени между отправкой пакета данных до сообщения о его доставке), потому что это требуется для определения потерь. В любой момент времени
 ,
,
где
 представляет собой «шум» от очередей вдоль маршрута, стратегию получателя с задержкой подтверждений, скопление подтверждений и т.д. RTprop — это физическая характеристика соединения, и она изменяется только при изменении самого канала. Поскольку изменения канала происходят во временном масштабе ≥ RTprop, то беспристрастной и эффективной оценкой времени
представляет собой «шум» от очередей вдоль маршрута, стратегию получателя с задержкой подтверждений, скопление подтверждений и т.д. RTprop — это физическая характеристика соединения, и она изменяется только при изменении самого канала. Поскольку изменения канала происходят во временном масштабе ≥ RTprop, то беспристрастной и эффективной оценкой времени  будет
будет![$\widehat{RTprop} = RTprop +min(\eta_t) = min (RTT_t)\;\;\;\;\forall t \in [T - W_R, T]$](https://habrastorage.org/getpro/habr/post_images/4fd/1dc/212/4fd1dc212a231b684b4e714271213af4.svg)
то есть запуск
 во временном окне
во временном окне  (которое обычно составляет от десятков секунд до минут).
(которое обычно составляет от десятков секунд до минут).В отличие от RTT, ничто в спецификациях TCP не требует реализации для отслеживания пропускной способности узкого места, но хорошую оценку этого можно получить из отслеживания скорости доставки. Когда подтверждение о доставке какого-то пакета возвращается к отправителю, оно показывает RTT пакета и анонсирует доставку данных в полёте, когда пакет отбывает. Средняя скорость доставки между отправкой пакета и получением подтверждения — это отношение доставленных данных к прошедшему времени:
 . Эта скорость должна быть меньше или равна пропускной способности узкого места (количество по прибытию точно известно, так что вся неопределённость заключается в
. Эта скорость должна быть меньше или равна пропускной способности узкого места (количество по прибытию точно известно, так что вся неопределённость заключается в  , которая должна быть больше или равна настоящему интервалу прибытия; поэтому отношение должно быть меньше или равно настоящей скорости доставки, которое, в свою очередь, ограничено сверху ёмкостью узкого места). Следовательно, максимальное окно скорости доставки — это эффективная, беспристранстная оценка BtlBw:
, которая должна быть больше или равна настоящему интервалу прибытия; поэтому отношение должно быть меньше или равно настоящей скорости доставки, которое, в свою очередь, ограничено сверху ёмкостью узкого места). Следовательно, максимальное окно скорости доставки — это эффективная, беспристранстная оценка BtlBw:![$\widehat{BtlBw} = max(deliveryRate_t)\;\;\;\;\forall t \in [T - W_B, T]$](https://habrastorage.org/getpro/habr/post_images/aab/77f/87b/aab77f87b3f3fafbfa304d0bdc63e2d1.svg)
где окно времени
 обычно составляет от шести до десяти RTT.
обычно составляет от шести до десяти RTT.TCP должен записать время отправки каждого пакета, чтобы вычислить RTT. BBR дополняет эти записи общим количеством доставленных данных, так что прибытие каждого подтверждения сообщает одновременно и RTT, и результат измерения скорости доставки, которую фильтры преобразуют в оценки RTprop и BtlBw.
Заметьте, что эти значения полностью независимы: RTprop может изменяться (например, при изменении маршрута), но обладает тем же узким местом, или BtlBw может изменяться (например, когда меняется пропускная способность беспроводного канала) без изменения маршрута. (Независимость обеих сдерживающих факторов — там причина, почему они должны быть известны, чтобы связать поведение при отправке с маршрутом доставки). Поскольку RTprop виден только с левой стороны BDP, а BtlBw — только с правой стороны на рисунке 1, то они подчиняются принципу неопределённости: всякий раз, когда одно из двух можно измерить, второе измерить невозможно. Интуитивно это можно понять следующим образом: чтобы определить ёмкость канала, его нужно переполнить, что создаёт очередь, которая не даёт возможность измерить длину канала. Например, приложение с протоколом запросов/ответов может никогда не отправить достаточно данных для заполнения канала и наблюдения BtlBw. Многочасовая передача большого массива данных может всё своё время потратить в районе с ограниченной пропускной способностью и получить только единственный образец RTprop от RTT у первого пакета. Присущий принцип неопределённости означает, что вдобавок к оценкам для восстановления двух параметров маршрута, должны быть такие состояния, которые отслеживают одновременно и что можно узнать в текущей рабочей точке и, по мере того как информация теряет свежесть, как перейти в рабочую точку, где можно получить более свежие данные.
Сопоставление потока пакетов с путём доставки
Основной алгоритм BBR состоит из двух частей:
Когда получаем подтверждение (ack)
Каждое подтверждение предоставляет новый RTT и измерения средней скорости доставки, которая обновляет оценки RTprop и BtlBw:
function onAck(packet)
rtt = now - packet.sendtime
update_min_filter(RTpropFilter, rtt)
delivered += packet.size
delivered_time = now
deliveryRate = (delivered - packet.delivered) / (delivered_time - packet.delivered_time)
if (deliveryRate > BtlBwFilter.currentMax || ! packet.app_limited)
update_max_filter(BtlBwFilter, deliveryRate)
if (app_limited_until > 0)
app_limited_until = app_limited_until — packet.sizeПроверка
if нужна из-за проблемы неопределённости, о которой говорилось в последнем параграфе: отправители могут быть ограничены приложением, то есть у приложения могут закончиться данные для заполнения сети. Это довольно типичная ситуация из-за трафика запрос/ответ. Когда есть возможность для отправки, но никакие данные не отправляются, BBR помечает соответствующие образцы пропускной способности как «ограниченные приложением», то есть app_limited (см. псевдокод send()). Этот код определяет, какие образцы включать в модель пропускной способности, так что он отражает именно сетевые ограничения, а не лимиты приложения. BtlBw является твёрдым верхним ограничением скорости доставки, так что полученная по результатам измерения скорость доставки большая, чем текущая оценка BtlBw, должна означать заниженную оценку BtlBw, независимо от того, был ли образец ограничен приложением или нет. В противном случае образцы с ограничением приложения отбрасываются. (Рисунок 1 показывает, что в регионе с ограничением приложения deliveryRate параметр BtlBw занижен). Такие проверки предотвращают заполнение фильтра BtlBw заниженными значениями, из-за которых отправка данных может замедлиться.Когда данные отправляются
Для соотнесения скорости прибытия пакетов со скоростью вылета из узкого места BBR отслеживает каждый пакет данных. (BBR должен соответствовать rate узкого места: это значит, что отслеживание является неотъемлемой частью архитектуры и фундаментальной частью работы — поэтому pacing_rate является основным контрольным параметром. Вспомогательный параметр cwnd_gain связывает inflight с небольшим множеством BDP для обработки типичных патологий сети и получателя (см. ниже главу по задержанным и растянутым подтверждениям). Концептуально, процедура
send в TCP выглядит как следующий код. (В Linux отправка данных использует эффективную процедуру массового обслуживания FQ/pacing [4], которая обеспечивает BBR линейную производительность одиночного соединения на мультигигабитных каналах и обрабатывает тысячи соединений с более низкой скоростью с незначительным оверхедом CPU).function send(packet)
bdp = BtlBwFilter.currentMax × RTpropFilter.currentMin
if (inflight >= cwnd_gain × bdp)
// wait for ack or retransmission timeout
return
if (now >= nextSendTime)
packet = nextPacketToSend()
if (! packet)
app_limited_until = inflight
return
packet.app_limited = (app_limited_until > 0)
packet.sendtime = now
packet.delivered = delivered
packet.delivered_time = delivered_time
ship(packet)
nextSendTime = now + packet.size / (pacing_gain × BtlBwFilter.currentMax)
timerCallbackAt(send, nextSendTime)Поведение в устойчивом состоянии
Скорость и количество данных, отправляемых по BBR, зависит только от BtlBw и RTprop, так что фильтры контролируют не только оценки ограничений узкого места, но и их применение. Это создаёт нестандартный контур управления, изображённый на рисунке 2, на котором показаны RTT (синим), inflight (зелёным) и скорость доставки (красным) на протяжении 700 миллисекунд для 10-мегабитного 40-миллисекундного потока. Жирная серая линия над скоростью доставки — это состояние фильтра BtlBw max. Треугольные формы получаются от цикличного применения коэффициента pacing_gain в BBR для определения увеличения BtlBw. Коэффициент передачи в каждой части цикла показан выровненным по времени с данными, на которые он повлиял. Этот коэффициент сработал на RTT раньше, когда данные отправлялись. Это показано горизонтальными неровностями в описании последовательности событий с левой стороны.

Рисунок 2
BBR сводит к минимум задержку, потому что основная часть времени проходит с одной и той же BDP в действии. За счёт этого узкое место передвигается к отправителю, так что увеличение BtlBw становится незаметным. Следовательно, BBR периодически тратит интервал RTprop на значении pacing_gain > 1, которое увеличивает скорость отправки и объём отправленных данных без подтверждения доставки (inflight). Если BtlBw не меняется, то очередь создаётся перед узким местом, увеличивая RTT, что сохраняет неизменным показатель
deliveryRate. (Очередь можно устранить, отправляя данные с компенсирующим значением pacing_gain < 1 для следующего RTprop). Если BtlBw увеличивается, то скорость deliveryRate тоже увеличивается, а новое максимальное значение фильтра немедленно увеличивает базовую скорость отслеживания (pacing_rate). По этой причине BBR приспосабливается к новому размеру узкого места экспоненциально быстро. Рисунок 3 показывает этот эффект на 10-мегабитном 40-миллисекундном потоке, который BtlBw внезапно увеличивает до 20 Мбит/с после 20 секунд устойчивой работы (в левой части графика), затем сбрасывает до 10 Мбит/с после ещё 20 секунд устойчивой работы на 20 Мбит/с (правая часть графика).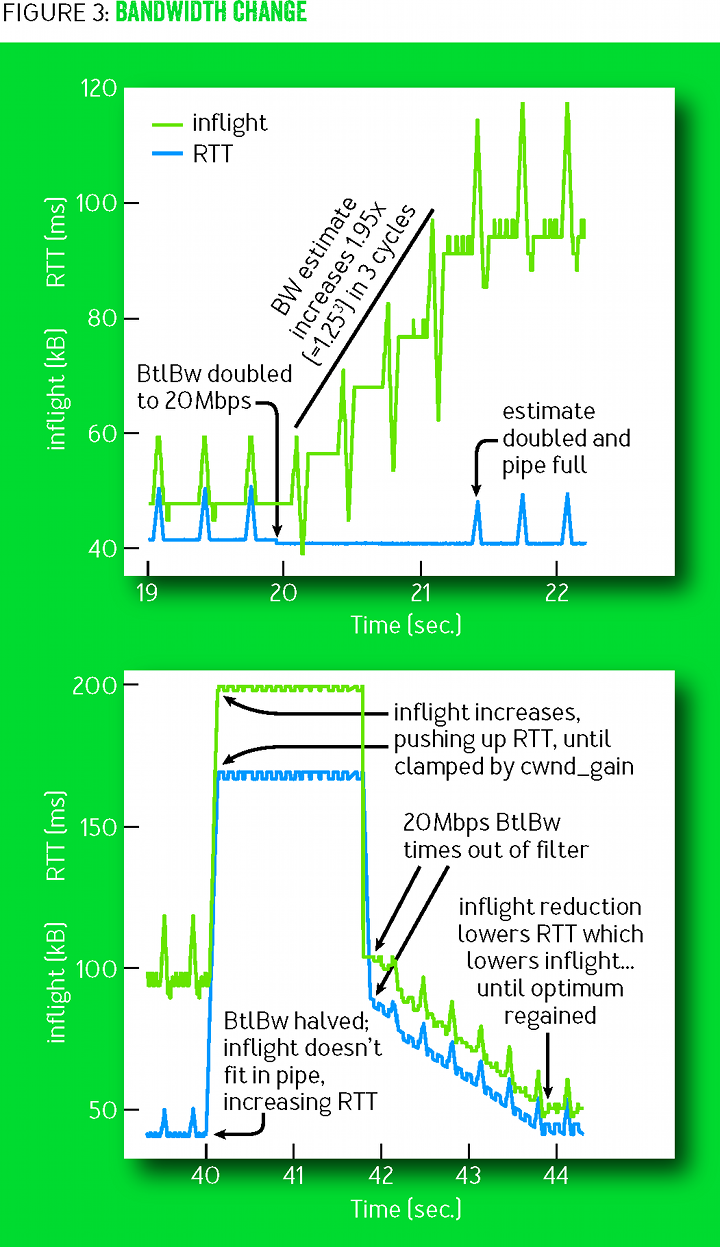
Рисунок 3
(По сути, BBR — это простой пример управляющей системы «макс-плюс», нового подхода к системам управления, основанном на нестандартной макс-плюс алгебре [12]. Этот подход позволяет адаптировать скорость [управляется коэффициентом передачи max] независимо от роста очереди [управляется коэффициентом передачи average]. В применении к нашей задаче это сводится к простому, безусловному контуру управления, где адаптация к изменениям физических ограничений автоматически осуществляется изменением фильтров, выражающих эти ограничения. Традиционная система потребовала бы создания множества контуров управления, объединённых в сложный конечный автомат, чтобы добиться такого результата).
Поведение при запуске одиночного потока BBR
Современные реализации обрабатывают события вроде запуска (startup), закрытия (shutdown) и возмещения потерь (loss recovery) с помощью алгоритмов, реагирующих на «события», с большим количеством строк кода. В BBR используется код, приведённый выше (в предыдущей главе «Сопоставление потока пакетов с путём доставки»), для всего. Обработка событий происходит путём прохода через последовательность «состояний». Сами «состояния» определены таблицей с одним или несколькими фиксированными значениями коэффициентов и критериев выхода. Основное время тратится в состоянии ProbeBW, которое описано в главе «Поведение в устойчивом состоянии». Состояния Startup и Drain используются при запуске соединения (рисунок 4). Чтобы обрабатывать соединение, где пропускная способность увеличивается на 12 порядков, в состоянии Startup реализован алгоритм двоичного поиска для BtlBw, где используется коэффициент передачи
 для двукратного увеличения скорости передачи, когда увеличивается скорость доставки. Так определяется BtlBw в
для двукратного увеличения скорости передачи, когда увеличивается скорость доставки. Так определяется BtlBw в  RTT, но в то же время создаёт излишнюю очередь до
RTT, но в то же время создаёт излишнюю очередь до  . Как только Startup находит BtlBw, система BBR переходит в состояние Drain, которое использует обратные коэффициенты передачи Startup, чтобы избавиться от излишней очереди, а затем — в состояние ProbeBW, как только inflight опускается до линии BDP.
. Как только Startup находит BtlBw, система BBR переходит в состояние Drain, которое использует обратные коэффициенты передачи Startup, чтобы избавиться от излишней очереди, а затем — в состояние ProbeBW, как только inflight опускается до линии BDP.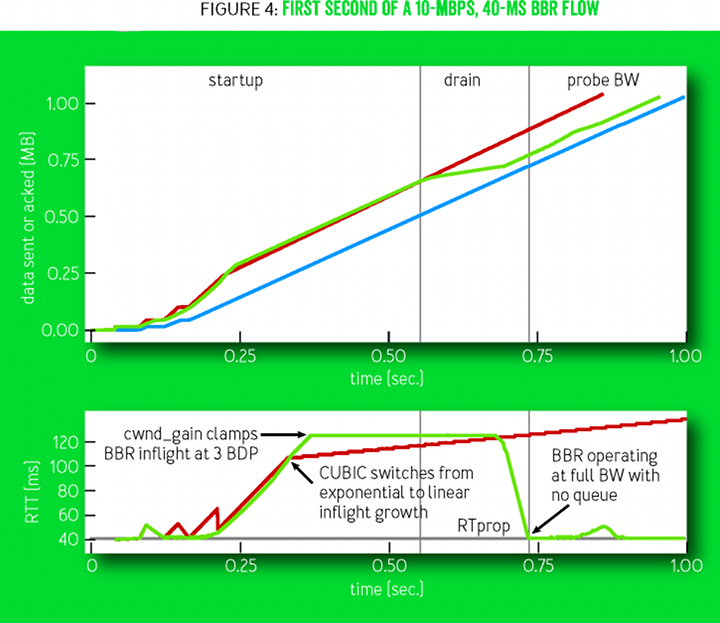
Рисунок 4
Рисунок 4 показывает первую секунду 10-мегабитного 40-миллисекундного потока BBR. На верхнем графике отложено время и последовательность событий, а также прогресс отправителя (зелёным) и получателя (синим): объём переданных и полученных данных. Красная линия показывает показатели отправителя по технологии CUBIC при тех же условиях. Вертикальные серые линии означают моменты перехода между состояниями BBR. На нижнем графике — изменение времени двойного прохода пакетов (RTT) обоих соединений. Обратите внимание, что шкала времени для этого графика соответствует времени получения подтверждения о прибытии (ack). Поэтому может показаться, что графики будто смещены во времени, но на самом деле события внизу соответствуют тем моментам, когда система BBR узнаёт об этих событиях и реагирует.
Нижний график на рисунке 4 сравнивает BBR и CUBIC. Сначала их поведение почти одинаково, но BBR полностью опустошает образовавшуюся при запуске соединения очередь, а CUBIC не может этого сделать. У неё нет модели трассы, которая сообщила бы, сколько отправленных данных являются излишними. Поэтому CUBIC менее агрессивно наращивает передачу данных без подтверждения доставки, но этот рост продолжается до тех пор, пока буфер узкого места не переполнится и не начнёт отбрасывать пакеты, или до достижения лимита у получателя на отправленные данные без подтверждения (окно приёма TCP).
Рисунок 5 показывает поведение RTT в первые восемь секунд соединения, изображённого на предыдущем рисунке 4. Технология CUBIC (красным) заполняет весь доступный буфер, затем крутится между 70% и 100% заполнения каждые несколько секунд. После запуска соединения BBR (зелёным) работает практически без создания очереди.
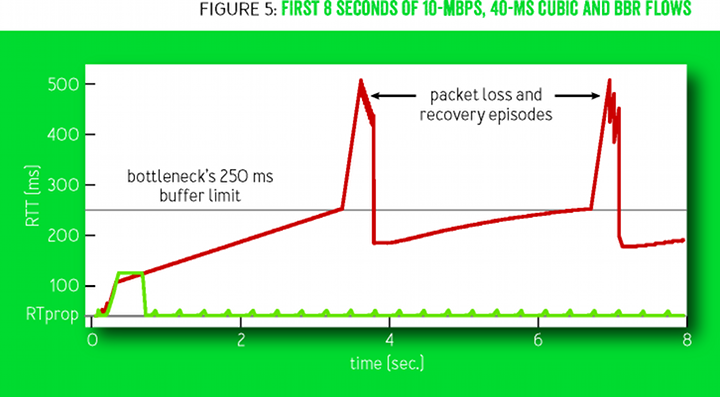
Рисунок 5
Поведение, когда несколько потоков BBR встречаются в узком месте
Рисунок 6 показывает, как пропускная способность нескольких потоков BBR сходится в честном разделе канала с узким местом на 100 мегабит/10 миллисекунд. Смотрящие вниз треугольные структуры — состояния соединений ProbeRTT, в которых самосинхронизация ускоряет окончательную конвергенцию.
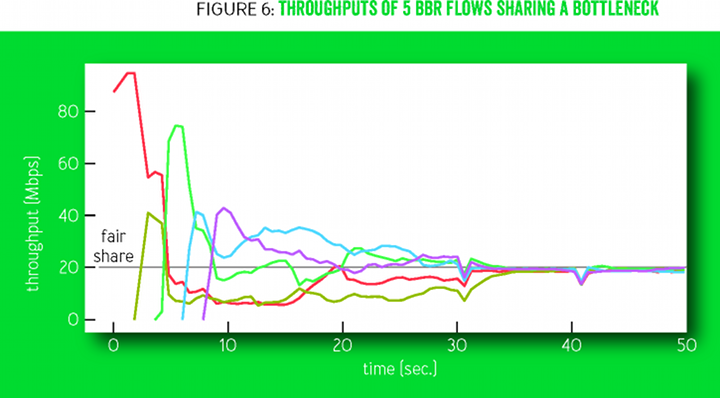
Рисунок 6
Циклы изменения коэффициентов усиления ProbeBW (рисунок 2) стимулируют бóльшие потоки уступать полосу меньшим потокам, в результате чего каждый поток понимает своё честное состояние. Это происходит довольно быстро (несколько циклов ProbeBW), хотя несправедливость может сохраняться, если опоздавшие к началу передела потоки переоценивают RTprop из-за того, что начавшие ранее потоки (временно) создают очередь.
Чтобы выяснить настоящий RTProp, поток перемещается налево от линии BDP, используя состояние ProbeRTT: если оценка RTProp не обновляется (то есть путём замера меньшего RTT) в течение многих секунд, то BBR входит в состояние ProbeRTT, уменьшая количество отправляемых данных (inflight) до четырёх пакетов по крайней мере для одного двойного прохода, а затем возвращается в предыдущее состояние. Когда большие потоки входят в состояние ProbeRTT, то из очереди изымается много пакетов, так что сразу несколько потоков видят новое значение RTprop (новое минимальное RTT). Благодаря этому их оценки RTprop обнуляются одновременно, так что они все вместе входят в состояние ProbeRTT — и очередь уменьшается ещё сильнее, в результате чего ещё больше потоков видят новое значение RTprop, и так далее. Такая распределённая координация — ключевой фактор одновременно для честного распределения полосы и стабильности.
BBR синхронизирует потоки вокруг желаемого события, коим является пустая очередь в узком месте. В противоположность такому подходу, регулирование заторов по потере пакетов синхронизирует потоки вокруг нежелательных событий, таких как периодический рост очереди и переполнение буфера, что увеличивает задержку и потерю пакетов.
Опыт внедрения B4 WAN в Google
Сеть B4 в компании Google — это высокоскоростная сеть WAN (wide-area network), построенная на обычных дешёвых коммутаторах [15]. Потери на этих коммутаторах с мелкими буферами происходят в основном из-за случайного наплыва небольших всплесков трафика. В 2015 году Google начала переводить рабочий трафик с CUBIC на BBR. Не было зафиксировано никаких проблем или регрессий, а с 2016 года весь трафик B4 TCP использует BBR. Рисунок 7 иллюстрирует одну причину, по которой это было сделано: пропускная способность BBR неизменно в 2-25 раз выше, чем у CUBIC. Мы видели даже большее улучшение, но обнаружили, что 75% соединений BBR ограничены буфером приёма TCP в ядре, который сотрудники отдела эксплуатации сети сознательно установили на низкое значение (8 МБ), чтобы не дать CUBIC заполонить сеть мегабайтами избыточного трафика без подтверждения доставки (если разделить 8 МБ на 200 мс межконтинентального RTT, то получится 335 Мбит/с максимум). Ручное увеличение буфера приёма на на одном маршруте США−Европа мгновенно повысило скорость передачи данных BBR до 2 Гбит/с, в то время как CUBIC остался на 15 Мбитах/с — это 133-кратное относительное увеличение пропускной способности было предсказано Мэтисом с коллегами в научной работе 1997 года. [17]
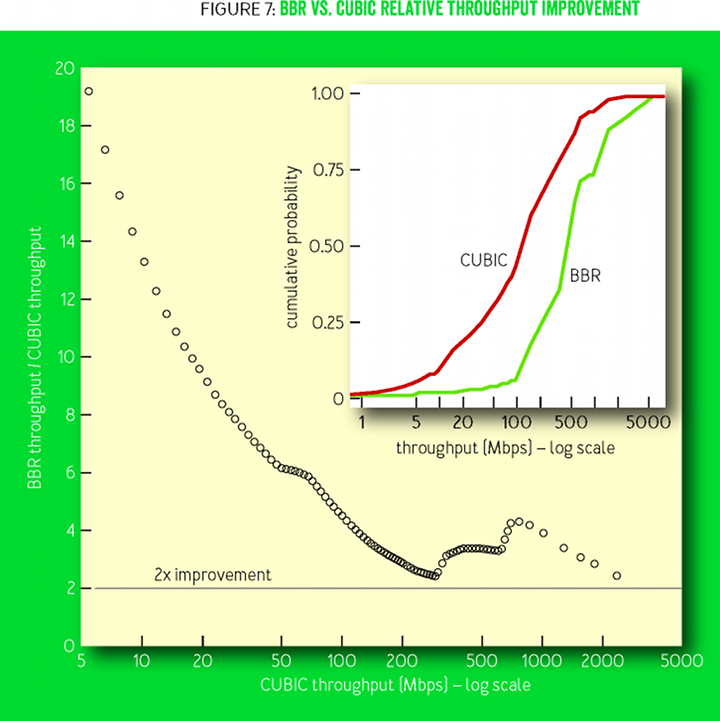
Рисунок 7
Рисунок 7 показывает относительное улучшение BBR по сравнению с CUBIC; на врезке — интегральные функции распределения (cumulative distribution functions, CDF) для пропускной способности. Замеры произведены с помощью службы активного зондирования, которая открывает постоянные соединения BBR и CUBIC к удалённым дата-центрам, затем каждую минуту передаёт по 8 МБ данных. Зонды исследуют много маршрутов B4 между Северной Америкой, Европой и Азией.
Огромное улучшение — прямое следствие того, что BBR не использует потерю пакетов как индикатор затора. Для достижения полной пропускной способности существующим методам регулирования заторов по потере пакетов нужно, чтобы уровень потерь был меньше, чем обратный квадрат BDP [17] (например, менее одной потери на 30 миллионов пакетов для соединения 10 Гбит/с и 100 мс). На рисунке 8 сравнивается измеренная полезная пропускная способность на различных уровнях потерь пакетов. В алгоритме CUBIC допуск на потерю пакетов является структурным свойством алгоритма, а в BBR это параметр конфигурации. По мере того, как уровень потерь в BBR приближается к максимальному коэффициенту усиления ProbeBW, вероятность измерения скорости доставки реального BtlBw резко падает, что приводит к недооценке со стороны фильтра max.
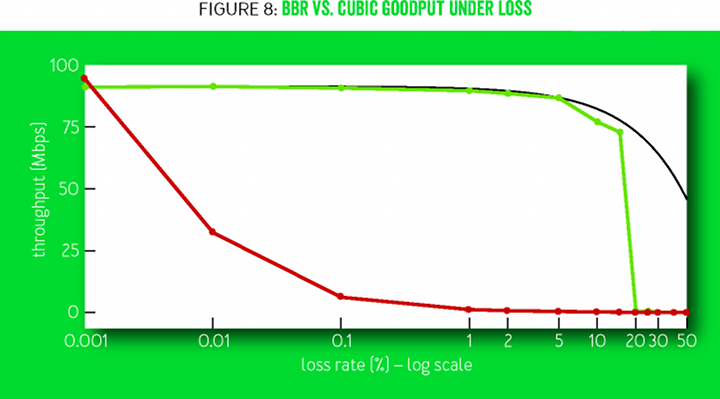
Рисунок 8
Рисунок 8 сравнивает полезную пропускную способность BBR и CUBIC в 60-секундном потоке на соединении 100 Мбит/c и 100 мс со случайными потерями от 0,001% до 50%. Пропускная способность CUBIC уменьшается в 10 раз при потерях 0,1% и полностью глохнет при более 1%. Максимальной пропускной способностью считается доля полосы за минусом потерь пакетов (
 ). BBR держится на этом уровне до уровня потерь 5% и близко к нему до 15%.
). BBR держится на этом уровне до уровня потерь 5% и близко к нему до 15%.Опыт внедрения YouTube Edge
BBR развёртывается на видеосерверах YouTube и Google.com. Google проводит небольшой эксперимент, в рамках которого малый процент пользователей случайно переводят на BBR или CUBIC. Воспроизведение видео по BBR показывает значительно улучшение всех оценок пользователями качества услуги. Возможно, потому что поведение BBR более последовательное и предсказуемое. BBR лишь немного улучшает пропускную способность соединения, потому что YouTube и так адаптирует скорость потоковой передачи до уровня гораздо ниже BtlBw, чтобы свести к минимуму излишнюю сетевую буферизацию и повторную буферизацию. Но даже здесь BBR уменьшает среднее медианное RTT на 53% в целом по миру и более чем на 80% в развивающихся странах.
Рисунок 9 показывает медианное улучшение RTT в сравнении BBR и CUBIC по статистике более 200 млн просмотров видео на YouTube, измеренных на пяти континентах в течение недели. Более половины из всех 7 млрд мобильных соединений в мире подключаются по 2.5G на скорости от 8 до 114 Кбит/с [5], испытывая хорошо задокументированные проблемы из-за того, что методы регулирования заторов по потере пакетов склонны переполнять буферы [3]. Узкое место в этих системах обычно находится между SGSN (обслуживающий узел поддержки GPRS) [18] и мобильным устройством. Программное обеспечение SGSN работает а стандартной платформе ПК с обильным количеством ОЗУ, где часто имеются мегабайты буфера между интернетом и мобильным устройством. Рисунок 10 сравнивает (эмулированную) задержку SGSN между интернетом и мобильным устройством для BBR и CUBIC. Горизонтальные линии отмечают одни из наиболее серьёзных последствий: TCP адаптируется к длительным задержкам RTT за исключением пакета SYN, инициирующего соединение, у которого фиксированный таймаут, в зависимости от операционной системы. Когда мобильное устройство получает большой массив данных (например, от автоматического обновления программного обеспечения) через SGSN с большим буфером, устройство не может установить никакое соединение в интернете, пока очередь не освободится (подтверждающий пакет SYN ACK задерживается на большее время, чем фиксированный таймаут SYN).
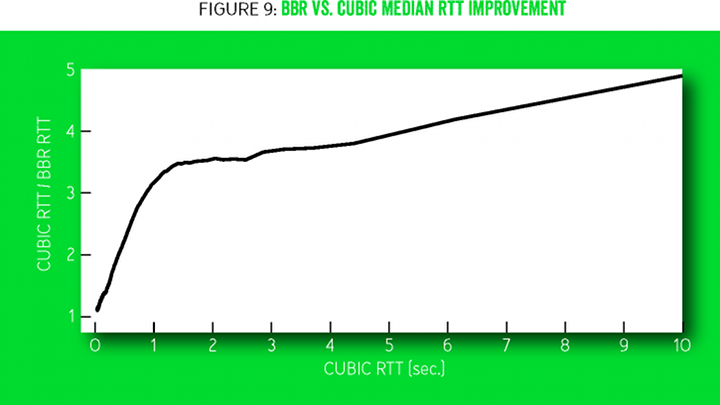
Рисунок 9
Рисунок 10 показывает медианные изменения RTT в устойчивом состоянии соединения и зависимость от размера буфера на соединении 128 Кбит/с и 40 мс с восемью потоками BBR (зелёным) или CUBIC (красным). BBR удерживает очередь у минимальных значений, независимо от размера буфера узкого места и количества активных потоков. Потоки CUBIC всегда заполняют буфер, так что задержка увеличивается линейно с размером буфера.

Рисунок 10
Адаптивная полоса в мобильной сотовой связи
Сотовые системы адаптируют полосу пропускания для каждого пользователя частично в зависимости от прогноза запросов, в котором учитывается очередь пакетов, предназначенная для этого пользователя. Ранние версии BBR были настроены таким образом, чтобы создавать очень маленькие очереди, из-за чего соединения стопорились на низких скоростях. Увеличение пикового значения pacing_gain для ProbeBW и увеличение очередей привело к уменьшению заглохших соединений. Это показывает возможность великолепной адаптации для некоторых сетей. С текущим значением пикового коэффициента усиления
 не проявляется никакой деградации ни в какой сети, по сравнению с CUBIC.
не проявляется никакой деградации ни в какой сети, по сравнению с CUBIC.Задержанные и растянутые пакеты ack
Сети сотовой связи, WiFi и широкополосные сети часто задерживают и скапливают пакеты ack [1]. Когда inflight ограничивается одним BDP, это приводит к срывам, снижающим пропускную способность. Увеличение коэффициента cwnd_gain ProbeBW до двух позволило продолжить ровную передачу на прогнозируемой скорости доставки, даже когда пакеты ack задерживались до значения в один RTT. Это в значительной степени предотвращает срывы.
Ограничители текущего ведра
Первоначальное развёртывание BBR на YouTube показал, что большинство интернет-провайдеров в мире искажают трафик с помощью ограничителей скорости по алгоритму текущего ведра [7]. Ведро обычно полно в начале соединения, так что BBR узнаёт параметр BtlBw для лежащей в основе сети. Но как только ведро опустошается, то все пакеты, отправленные быстрее, чем (намного меньшая, чем BtlBw) скорость наполнения ведра, отбрасываются. BBR в конце концов узнаёт эту новую скорость доставки, но цикличное изменение коэффициента усиления ProbeBW приводит к постоянным умеренным потерям. Чтобы минимизировать потери полосы восходящего потока и увеличение задержек приложения от этих потерь, мы добавили специальный детектор ограничителей и явную модель ограничителей в BBR. Мы также активно изучаем лучшие способы устранить вред от работы ограничителей скорости.
Конкуренция с методами регулирования заторов по потерям пакетов
BBR сводится к честному разделению полосы пропускания узкого места, будь то в конкуренции с другими потоками BBR или с потоками под управлением методов регулирования заторов по потерям пакетов. Даже когда последние заполняют доступный буфер, ProbeBW всё ещё надёжно сдвигает оценку BtlBw в сторону честного разделения потоков, а ProbeRTT считает оценку RTProp достаточно высокой для сходимости «око за око» к честному разделению. Однако неуправляемые буферы маршрутизаторов, превышающие некоторые BDP, заставляют устаревших конкурентов с регулированием заторов по потерям пакетов раздувать очередь и захватывать больше, чем им причитается по-честному. Устранение этого — ещё одна область активных исследований.
Заключение
Переосмысление методов регулирования заторов приносит огромную пользу. Вместо использования событий, таких как потери или занятие буфера, которые лишь слабо коррелируют с заторами, BBR начинает с формальной модели заторов Клейнрока и связанной с ней оптимальной рабочей точки. Досадный вывод о «невозможности» одновременного определения критически важных параметров задержки и полосы пропускания обходится с помощью наблюдения, что их можно прогнозировать одновременно. Затем последние достижения в системах управления и теории оценивания применяются для создания простого распределённого контура управления, который приближается к оптимуму, полностью используя сеть при сохранении маленькой очереди. Реализация BBR от Google доступна в ядре Linux с открытым исходным кодом и детально описана в приложении к этой статье.
Технология BBR используется на бэкбоне Google B4, на порядки улучшая пропускную способность по сравнению с CUBIC. Она также разворачивается на веб-серверах Google и YouTube, в значительной степени уменьшая задержку на всех пяти континентах, протестированных к настоящему времени, а особенно сильно в развивающихся странах. Технология BBR работает исключительно на стороне отправителя и не требует изменений в протоколе, у получателя или в сети, что позволяет развёртывать её постепенно. Она зависит только от RTT и уведомлений о доставке пакетов, так что её можно применять в большинстве транспортных протоколов интернета.
C авторами можно связаться по адресу bbr-dev@googlegroups.com.
Выражение признательности
Авторы благодарны Лену Клейнроку за указание, как нужно правильно регулировать заторы. Мы в долгу перед Ларри Бракмо (Larry Brakmo) за новаторскую работу над системами регулирования заторов Vegas [2] и New Vegas, которые предвосхитили многие элементы BBR, а также за его советы и руководство на начальном этапе разработки BBR. Мы также хотели бы поблагодарить Эрика Думазета (Eric Dumazet), Нандиту Дуккипати (Nandita Dukkipati), Яну Айенгар (Jana Iyengar), Яна Светта (Ian Swett), Фитца Ноулана (M. Fitz Nowlan), Дэвида Уэзерала (David Wetherall), Леонидаса Контотанассиса (Leonidas Kontothanassis), Амина Вахдата (Amin Vahdat) и группы разработки Google BwE и инфраструктуры YouTube за их неоценимую помощь и поддержку.
Приложение — подробное описание
Машина состояний для последовательного зондирования
Коэффициент усиления pacing_gain управляет, как быстро отправляются пакеты относительно BtlBw, и это ключ к интеллектуальной функции BBR. При pacing_gain больше единицы увеличивается inflight и уменьшается промежуток между поступлениями пакетов, что передвигает соединение в правую часть на рисунке 1. При pacing_gain меньше единицы происходит обратный эффект, соединение передвигается влево.
BBR использует pacing_gain для реализации простой машины последовательного зондирования состояний, которая чередуется между тестированием на бóльшую полосу и тестированием на меньшее время двойного прохода пакета. (Необязательно тестировать на меньшую полосу, потому что она обрабатывается автоматически фильтром BtlBw msx: новые измерения отражают падение, так что BtlBw скорректирует себя сразу, как только последние старые изменения уберутся из фильтра по таймауту. Фильтр RTprop min таким же образом обрабатывает увеличение пути доставки).
Если увеличивается пропускная способность бутылочного горлышка, BBR должен отправлять данные быстрее, чтобы обнаружить это. Точно так же, если меняется реальное время двойного прохода пакета, это меняет BDP, и поэтому BDP должен отправлять данные медленнее, чтобы удержать inflight ниже BDP для измерения нового RTprop. Поэтому единственный способ обнаружить эти изменения — проведение экспериментов, отправляя быстрее для проверки увеличения BtlBw или отправляя медленнее для проверки уменьшения RTprop. Частота, масштаб, продолжительность и структура этих экспериментов различаются в зависимости от того, что уже известно (запуск соединения или стабильное состояние) и от поведения приложения, которое отправляет данные (прерывистое или постоянное).
Устойчивое состояние
Потоки BBR тратят бóльшую часть своего времени в состоянии ProbeBW, зондируя полосу с помощью метода под названием gain cycling, что помогает потокам BBR достичь высокой пропускной способности, низкой задержки в очереди и сходимости в честном разделе полосы. Используя gain cycling, BBR циклично пробует ряд значений для коэффициента усиления pacing_gain. Используется восемь фаз цикла со следующими значениями: 5/4, 3/4, 1, 1, 1, 1, 1, 1. Каждая фаза обычно идёт в течение прогнозируемого RTprop. Такой дизайн позволяет циклу коэффициента сначала зондировать канал на бóльшую пропускную способность со значением pacing_gain больше 1.0, а затем рассредотачивать любую образовавшуюся очередь с помощью pacing_gain на такую же величину меньше 1.0, а затем двигаться на крейсерской скорости с короткой очередью коэффициентов ровно 1.0. Средний коэффицент усиления для всех фаз равняется 1.0, потому что ProbeBW стремится к среднему значению, чтобы уравняться с доступной полосой пропускания и, следовательно, сохранить высокую степень использования полосы, не увеличивая при этом очередь. Обратите внимание, что хотя циклы изменений коэффицента изменяют pacing_gain, но значение cwnd_gain неизменно остаётся равным двум, поскольку задержанные и растянутые пакеты подтверждения могут появиться в любой момент (см. главу о задержанных и растянутых пакетах ack).
Более того, для улучшения смешивания потоков и справедливого разделения полосы, и для уменьшения очередей, когда многочисленные потоки BBR совместно используют узкое место, BBR случайным образом изменяет фазы цикла ProbeBW, случайно выбирая первую фазу среди всех значений, кроме 3/4. Почему цикл не начинается с 3/4? Главная задача этого значения коэффициента — рассредоточить любую очередь, которая может образоваться во время применения коэффициента 5/4, когда канал уже полный. Когда процесс выходит из состояния Drain или ProbeRTT и входит в ProbeBW, то очередь отсутствует, так что коэффициент 3/4 не выполняет свою задачу. Применение 3/4 в таком контексте имеет только негативный эффект: заполнение канала в этой фазе будет 3/4, а не 1. Таким образом, начало цикла с 3/4 имеет только негативный эффект, но не имеет положительного, а поскольку вход в состояние ProbeBW происходит на старте любого соединения достаточно долго, то BBR использует эту маленькую оптимизацию.
Потоки BBR действуют сообща, чтобы периодически опустошать очередь в узком месте при помощи состояния, которое называется ProbeRTT. В любом состоянии кроме самого ProbeRTT, если оценка RTProp не обновлялась (например, посредством замера меньшего RTT) более 10 секунд, то BBR входит в состояние ProbeRTT и уменьшает cwnd до очень маленького значения (четыре пакета). Сохраняя такое минимальное количество пакетов «в полёте» по крайней мере 200 мс и на протяжении одного времени двойного прохода пакета, BBR выходит из состояния ProbeRTT и входит или в Startup, или в ProbeBW, в зависимости от оценки, заполнен ли уже канал.
BBR создан, чтобы работать бóльшую часть времени (около 98%) в состоянии ProbeBW, а остальное время — в ProbeRTT, основываясь на наборе компромиссов. Состояние ProbeRTT продолжается достаточно долго (по крайней мере, 200 мс), чтобы позволить потокам с разными RTT иметь параллельные состояния ProbeRTT, но в то же время оно продолжается достаточно короткий промежуток времени, чтобы ограничить снижение производительности примерно двумя процентами (200 мс / 10 секунд). Окно фильтра RTprop (10 секунд) достаточно маленькое, чтобы быстро подстроиться под изменение уровня трафика или изменение маршрута, но при этом достаточно большое для интерактивных приложений. Такие приложения (например, веб-страницы, вызовы удалённых процедур, фрагменты видео) часто демонстрируют естественные периоды молчания или малой активности в раках этого окна, где скорость потока достаточно низкая или достаточно продолжительная, чтобы рассредоточить очередь в узком месте. Затем фильтр RTprop оппортунистически подбирает эти измерения RTprop, а RTProp обновляется без необходимости задействовать ProbeRTT. Таким образом, потокам обычно требуется всего лишь жертвовать 2% полосы, если многочисленные потоки обильно заполняют канал на протяжении целого окна RTProp.
Поведение при запуске
Когда запускается поток BBR, он осуществляет свой первый (и самый быстрый) последовательный процесс зондирования/опустошения очереди. Сетевая пропускная способность изменяется в диапазоне 1012 — от нескольких бит до 100 гигабит в секунду. Чтобы выяснить значение BtlBw при таком гигантском изменении диапазона, BBR осуществляет двоичный поиск в пространстве скорости. Он очень быстро находит BtlBw (
двойных проходов пакетов), но за счёт создания очереди в 2BDP на последнем этапе поиска. Поиск выполняется в состоянии Startup в BBR, а опустошение создавшейся очереди — в состоянии Drain.Сначала Startup экспоненциально увеличивает скорость отправки данных, удваивая её на каждом раунде. Чтобы добиться такого быстрого зондирования наиболее спокойным образом, при запуске значения коэффициентов усиления pacing_gain и cwnd_gain установлены на
, в минимальное значение, которое позволяет удваивать скорость отправки данных на каждом раунде. Как только канал заполняется, коэффициент cwnd_gain ограничивает размер очереди значением  .
.В состоянии запуска соединения BBR оценивает, заполнен ли канал, с помощью поиска плато в оценке BtlBw. Если обнаруживается, что прошли несколько (три) раунда, где попытки удвоить скорость доставки реально не даёт большой прибавки скорости (менее 25%), то он считает, что достиг BtlBw, так что выходит из состояния Startup и входит в состояние Drain. BBR ждёт три раунда, чтобы получить убедительные доказательства, что наблюдаемое отправителем плато скорости доставки не является временным эффектом под влиянием окна приёма. Ожидание трёх раундов даёт достаточно времени для автоматической настройки на стороне получателя, чтобы раскрыть окно приёма и чтобы отправитель по BBR обнаружил необходимость увеличения BtlBw: в первом раунде алгоритм автоматической настройки окна приёма увеличивает окно приёма; во втором раунде отправитель заполняет увеличившееся окно приёма; в третьем раунде отправитель получает образцы с увеличенной скоростью доставки. Такой предел в три раунда доказал себя по результатам внедрения на YouTube.
В состоянии Drain алгоритм BBR стремится быстро опустошить очередь, которая образовалась в состоянии запуска соединения, перейдя в режим pacing_gain с обратными значениями, чем те, которые использовались в состоянии Startup. Когда количество пакетов в полёте соответствует оценке BDP, это означает, что BBR оценивает очередь как полностью опустошённую, но канал по-прежнему заполнен. Тогда BBR выходит из состояния Drain и входит в ProbeBW.
Заметьте, что запуск соединения BBR и медленный старт CUBIC оба изучают пропускную способность узкого места экспоненциально, удваивая скорость отправки на каждом раунде. Однако они кардинально отличаются. Во-первых, BBR более надёжно определяет доступную пропускную способность, поскольку он не прекращает поиск в случае потери пакета или (как Hystart у CUBIC [10]) увеличения задержки. Во-вторых, BBR плавно наращивает скорость отправки, в то время как у CUBIC на каждом раунде (даже с pacing) происходит всплеск пакетов, а потом период тишины. Рисунок 4 показывает количество пакетов в полёте и наблюдаетмое время RTT для каждого сообщения о подтверждении у BBR и CUBIC.
Реагирование на переходные ситуации
Сетевой путь и проход трафика по нему могут испытывать внезапные драматические изменения. Чтобы плавно и надёжно адаптироваться к ним, а также уменьшить потери пакетов в этих ситуациях, BBR использует ряд стратегий, чтобы реализовать свою базовую модель. Во-первых, BBR расценивает
 как цель, к которой текущий cwnd осторожно приближается снизу, увеличивая cwnd каждый раз не более чем на количество данных, для которых пришли подтверждения доставки. Во-вторых, при таймауте повторной передачи, который означает, что отправитель считает потерянными все пакеты в полёте, BBR консервативно снижает cwnd до одного пакета и отправляет единственный пакет (точно как алгоритмы регулирования заторов по потере пакетов, такие как CUBIC). В конце концов, когда отправитель замечает потерю пакета, но в полёте всё ещё есть пакеты, на первом этапе процесса по восстановлению потерь BBR временно снижает скорость отправки до уровня текущей скорости доставки; на втором и последующих раундах восстановления потерь он проверяет, что скорость отправки никогда не превышает текущую скорость доставки более чем в два раза. Это значительно снижает потери в переходных ситуациях, когда BBR сталкивается с ограничителями скорости или конкурирует с другими потоками в буфере, сравнимого размером с BDP.
как цель, к которой текущий cwnd осторожно приближается снизу, увеличивая cwnd каждый раз не более чем на количество данных, для которых пришли подтверждения доставки. Во-вторых, при таймауте повторной передачи, который означает, что отправитель считает потерянными все пакеты в полёте, BBR консервативно снижает cwnd до одного пакета и отправляет единственный пакет (точно как алгоритмы регулирования заторов по потере пакетов, такие как CUBIC). В конце концов, когда отправитель замечает потерю пакета, но в полёте всё ещё есть пакеты, на первом этапе процесса по восстановлению потерь BBR временно снижает скорость отправки до уровня текущей скорости доставки; на втором и последующих раундах восстановления потерь он проверяет, что скорость отправки никогда не превышает текущую скорость доставки более чем в два раза. Это значительно снижает потери в переходных ситуациях, когда BBR сталкивается с ограничителями скорости или конкурирует с другими потоками в буфере, сравнимого размером с BDP.Ссылки
1. Abrahamsson, M. 2015. TCP ACK suppression. Почтовый список рассылки IETF AQM; https://www.ietf.org/mail-archive/web/aqm/current/msg01480.html.
2. Brakmo, L. S., Peterson, L.L. 1995. TCP Vegas: end-to-end congestion avoidance on a global Internet. IEEE Journal on Selected Areas in Communications 13(8): 1465-1480.
3. Chakravorty, R., Cartwright, J., Pratt, I. 2002. Practical experience with TCP over GPRS. In IEEE GLOBECOM.
4. Corbet, J. 2013. TSO sizing and the FQ scheduler. LWN.net; https://lwn.net/Articles/564978/.
5. Ericsson. 2015 Ericsson Mobility Report (июнь); https://www.ericsson.com/res/docs/2015/ericsson-mobility-report-june-2015.pdf.
6. ESnet. Application tuning to optimize international astronomy workflow from NERSC to LFI-DPC at INAF-OATs; http://fasterdata.es.net/data-transfer-tools/case-studies/nersc-astronomy/.
7. Flach, T., Papageorge, P., Terzis, A., Pedrosa, L., Cheng, Y., Karim, T., Katz-Bassett, E., Govindan, R. 2016. An Internet-wide analysis of traffic policing. ACM SIGCOMM: 468-482.
8. Gail, R., Kleinrock, L. 1981. An invariant property of computer network power. Conference Record, International Conference on Communications: 63.1.1-63.1.5.
9. Gettys, J., Nichols, K. 2011. Bufferbloat: dark buffers in the Internet. acmqueue 9(11); http://queue.acm.org/detail.cfm?id=2071893.
10. Ha, S., Rhee, I. 2011. Taming the elephants: new TCP slow start. Computer Networks 55(9): 2092-2110.
11. Ha, S., Rhee, I., Xu, L. 2008. CUBIC: a new TCP-friendly high-speed TCP variant. ACM SIGOPS Operating Systems Review 42(5): 64-74.
12. Heidergott, B., Olsder, G. J., Van Der Woude, J. 2014. Max Plus at Work: Modeling and Analysis of Synchronized Systems: a Course on Max-Plus Algebra and its Applications. Princeton University Press.
13. Jacobson, V. 1988. Congestion avoidance and control. ACM SIGCOMM Computer Communication Review 18(4): 314-329.
14. Jaffe, J. 1981. Flow control power is nondecentralizable. IEEE Transactions on Communications 29(9): 1301-1306.
15. Jain, S., Kumar, A., Mandal, S., Ong, J., Poutievski, L., Singh, A., Venkata, S., Wanderer, J., Zhou, J., Zhu, M., et al. 2013. B4: experience with a globally-deployed software defined WAN. ACM SIGCOMM Computer Communication Review 43(4): 3-14.
16. Kleinrock, L. 1979. Power and deterministic rules of thumb for probabilistic problems in computer communications. In Conference Record, International Conference on Communications: 43.1.1-43.1.10.
17. Mathis, M., Semke, J., Mahdavi, J., Ott, T. 1997. The macroscopic behavior of the TCP congestion avoidance algorithm. ACM SIGCOMM Computer Communication Review 27(3): 67-82.
18. Википедия. Обслуживающий узел поддержки GPRS в базовой сети GPRS; https://en.wikipedia.org/wiki/GPRS_core_network#Serving_GPRS_support_node_.28SGSN.29.
Статьи по теме
«Буферы на стороне отправителя и случай адаптации для мультимедиа»
Aiman Erbad, Charles «Buck» Krasic
«Что вы не знали о сетевой производительности»
Kevin Fall, Steve McCanne
«Экскурсия по сетевой инфраструктуре дата-центра»
Dennis Abts, Bob Felderman
Авторы статьи — участники проекта Google make-tcp-fast, цель которого — развитие транспортной системы интернета посредством фундаментальных исследований и свободного программного обеспечения. Вкладом проекта стали TFO (TCP Fast Open), TLP (Tail Loss Probe), система возмещения потерь RACK, fq/pacing и значительная часть коммитов git в код TCP ядра Linux за последние пять лет.
