
Привет, Хабр! Меня зовут Настя, и я не люблю очереди. Поэтому я расскажу вам, на примере Альфа-Лаборатории и наших исследований, каким образом можно организовать инфраструктуру и архитектуру для прогона тестов, чтобы получать результат в разы быстрее. Например, нам удалось добиться такой цифры, как 5 минут суммарного времени прохождения тестов на приложение. Для этого нам пришлось поменять подход к запуску Selenium Grid.

Прежде чем начну рассказывать про сам selenium grid и все, что связано с ним, я хочу пояснить суть проблемы, которую мы пытались решить.
В прошлом году мы внедряли DevOps как процесс. И в один момент, автоматизируя все и вся, мы поняли, что time to market для каждого артефакта на этапе тестирования не должен превышать 30 минут. Концептуально мы хотели, чтобы некоторые релизы проходили автоверификацию, если приемочное тестирование им не нужно. Для тех артефактов, которые нужно проверять руками, 30 минут — это время, за которое тестировщик получает результаты прогона автотестов, анализирует их, а также делает приемочное тестирование. При этом автотесты должны автоматически запускаться в рамках нашего pipeline.
Чтобы достичь поставленной цели, нам необходимо было ускорить прогон автотестов. Но помимо ускорения автотестов, нужно было еще сделать так, чтобы при всем обилии проектов у нас не возникали очереди на их запуск.
Чаще всего задача ускорения прогона автотестов решается двумя способами:
Мы у себя в компании придерживаемся второго подхода, но не потому, что у нас нет денег. Я — инженер, и, как многие инженеры, ленива в отношении таких вопросов. Поэтому решила пойти по более сложному и интересному пути. И при этом сэкономить банку тот самый мешочек с деньгами.
Итак, цель ясна: ускорить и устранить очереди на запуск автотестов без привлечения дополнительного финансирования.
В самом начале у нас был довольно небольшой парк, состоящий из 15 виртуальных машин.
В общей сложности у нас около 20 проектов с автотестами, которые в разное время и с разной частотой запускаются.
Наши команды:
И у всех команд фокус на быструю доставку ценности до клиента. Само собой, никто не хочет “висеть” в очереди на запуск автотестов.
Ресурсов катастрофически не хватало. Почему? Давайте рассмотрим на конкретном примере:
Заметьте, мы рассмотрели очень положительный случай, когда тестов в проекте немного, и всего-то 3 потока. Железа не хватает, нужно думать о том, как облегчить нагрузку на виртуалки. Что если мы переедем с виртуальных машин в докер-контейнеры?
Посчитали:
Давайте рассмотрим конфигурацию одного докер-контейнера, который позволит прогнать тесты в 1 поток, и сравним с тем, что у нас было при использовании виртуальных машин:
500 RAM, 0,01% core, и HDD 400 мб.

Получается, что в один момент времени мы можем создать 120 контейнеров!
Это не только перекрывает наши запросы в 60 сессий, но и страхует на будущее. Ведь количество команд растет, а значит — количество запускаемых проектов тоже постоянно растет. Итак, стало достаточно очевидно, что нам нужно взять имеющиеся ресурсы и объединить их в единое пространство вычислительных мощностей, это еще называют песочницей. Объединяя, мы при этом не хотим думать о нем именно в парадигме каких-то хостов/виртуальных машин. Мы хотим иметь просто пространство, к которому мы сможем подключаться с помощью какого-нибудь api, и создавать в нем свои докер-контейнеры, на которых потом будем запускать тесты.
Итак, нам необходимо создать песочницу вычислительных ресурсов. При этом она должна быть динамической: т.е. мы должны иметь возможность в любой момент подключить/отключить от нее ресурсы, которые у нас есть. Причем все хосты, которые мы подключаем, могут иметь разную конфигурацию и быть в различных подсетях, для нас лишь главное, чтобы между ними можно было установить связь по определенным ip и портам. Динамическую песочницу называют еще облаком или кластером, и в нем мы имеем интерфейс для создания и управления докер-контейнерами.
Когда мы поняли, как хотим решить задачу, мы построили нашу песочницу, объединив наши хосты в кластер с помощью Apache Mesos и Marathon.

Таким образом мы получаем общее пространство с вычислительными ресурсами, у которого есть свое api. API нам предоставляет Marathon, а Apache Mesos как раз таки и объединяет хосты.
Мы определились с тем, что нам нужен кластер, и даже его создали. Но вот вопрос, как же мы будем запускать тесты в кластере? Вы же помните, что мы хотим в любом случае получать результаты тестов не больше, чем за 10 минут?
И тут на помощь нам должна прийти параллелизация запуска тестов.
Для решения этой задачи нам нужен централизованный инструмент, который позволит запускать и параллелить тесты в несколько потоков для каждого проекта. Есть несколько популярных инструментов.
Хоть мой рассказ и про то, как мы запускали selenium grid в докер-контейнерах — сначала рассмотрим, как вообще работает грид на виртуальных машинах.
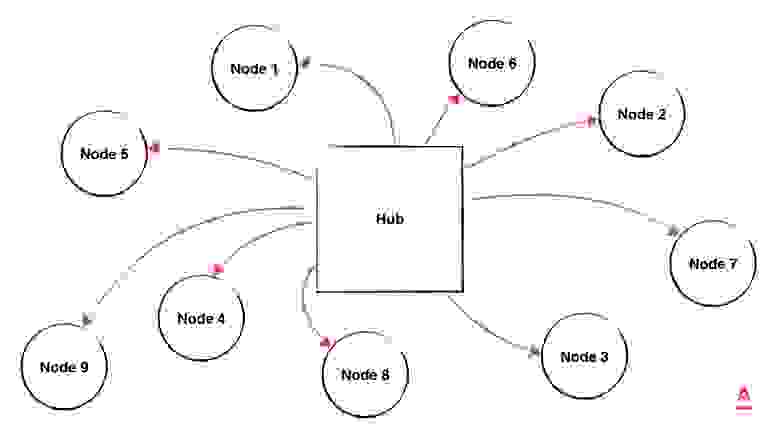
Фактически вся процедура представляет из себя 3 действия:
1. Мы копируем Selenium Standalone Server (нужной нам версии) в какую-нибудь директорию.
2. Затем выполняем команду, которая запускает этот сервер в нужном нам режиме: хаба, либо режим ноды. Обратите внимание, что за эти две функции отвечает один и тот же физический jar-ник, который вы продублировали на разные хосты.
3. Конфигурируем ноду. Либо через командную строку, либо в json-файле указываем набор браузеров и их параметры.
1. Нода на момент старта уже сконфигурирована.
Давайте посмотрим на содержимое ноды. Файл с json-конфигом для ноды находится в контейнере с ней, затем мы его переименовываем, и наш сервер узнает о своих параметрах из этого файла:
При этом если мы посмотрим на содержимое Dockerfile самой ноды, то увидим, что при конфигурировании окружения ноды мы сразу задаем переменные окружения, которые потом записываются в этот конфиг. Таким образом, нам не нужно лезть в “кишки” самого контейнера, чтобы изменить параметры запуска ноды, нам достаточно в Dockerfile переопределить значения указанных переменных. И все.
2. Когда мы стартуем ноду в контейнере, мы всегда можем быть уверены в том, что у нашего окружения уже есть браузер и драйвер для него. Потому что все это настраивается и устанавливается в момент сборки самого образа.
3. Также у нас есть скрипт sh, который выполняется после старта контейнера. И в этом скрипте мы видим, что после того, как у нас поднялся контейнер — у нас сразу же стартует наш java сервер.
Аналогично все по отношению к хабу.
В итоге запуск selenium grid в контейнере сводится к одной команде — старт докер-контейнера.
Несмотря на то, что хаб хорошо умеет работать с очередями и тайм-аутами, в самом начале использования статического грида мы испытали проблемы из-за тайм-аутов. Если хаб и нода долго не использовались, то при последующем коннекте мы ловили ситуации, когда при создании сессии на ноде эта самая сессия отваливалась именно по тайм-аутам или по причине того, что remotewebdriver не может поднять браузер. И все эти проблемы лечились рестартом грида, именно тогда мы и поняли, что для нас on-demand selenium grid будет решением проблемы.
Также мы не хотели, чтобы статический грид просто занимал место в кластере, который у нас и так небольшой. Как решить ситуацию, когда для разных проектов нам нужны разные конфигурации грида? Когда для одного проекта нужна одна версия браузера, для другого — другая? Очевидно, что держать включенными гриды — не самая хорошая идея.
Поэтому мы захотели поднимать selenium grid по запросу: объясню на примере
Казалось бы, идеальная концепция. Мы таким подходом решаем сразу две проблемы: и с деградацией грида, и с нехваткой места в кластере для хранения различных конфигураций грида.
Чтобы решить эту задачу, надо было написать скрипт автоматизированного создания грида. Мы ее решили с помощью ansible, написав нужные роли. Я не буду рассказывать, что такое ansible. Но могу сказать, что написать подобный скрипт вы у себя сможете также и на bash-e или на другом языке программирования, который на выходе вам предоставляет две команды на создание и удаление грида.
Помним, что запуск грида состоит из запуска парочки команд. И у каждой команды есть свои параметры. И чтобы автоматизировать запуск этих команд, эти параметры надо лишь автоматически вычислять до запуска команды. Либо же хардкодить.
Мы не можем хардкодить, потому что мы априори не знаем, на каком хосте и порту поднимутся компоненты Selenium Grid, так как за нас это решает Apache Mesos.
Мы, конечно, можем извернуться и вручную следить за открытыми портами и хостами, на которых поднимаем Selenium Grid, но тогда зачем нам вообще Apache Mesos и Marathon, если все будем делать вручную?
Итак, надо было автоматизировать вычисление следующих параметров:
В этом нам помогло api Marathon-а, с его помощью мы получали данные о том, на каком хосте и порту поднялся хаб. И потом уже это значение передавали перед стартом нод. Итак, что у нас получилось:
Deploy Selenium Grid
Delete Selenium Grid
Shell-скрипты, исполняемые на Jenkins, перед запуском ansible playbook рассчитываются автоматически и передают значение переменной. Прогон тестов встроен в pipeline с помощью job dsl.
Как только мы решили эту задачу и научились поднимать selenium grid в нашем кластере, то поспешили запустить тесты, и тут-то нас ожидало разочарование. Тесты не запускаются, более того — хаб даже не поднимает сессию с нодой.
Давайте разберемся, чего же не хватало нашим скриптам.
Еще раз взглянем, как бы выглядела команда, если бы мы запускали каждый раз ноды в Docker-контейнере для selenium grid вручную:
Вы видите два порта? Наверное, некоторым из вас интересно, откуда появился второй порт. Так вот, у докера есть внутренний порт и внешний порт. Внешний порт слушает сам контейнер. А внутренний порт прослушивается самим процессом selenium server standalone, который запускается в режиме -node.
В этом примере все запросы на порт 6666 контейнера будут пересылаться на порт 5555 ноды внутри него.
При настройке Apache Mesos-кластера мы для каждого хоста указываем диапазон портов. Этот диапазон используется для контейнеров, которые поднимаются Marathon’ом.
К примеру, если мы ставим диапазон 20000-21000, то наши контейнеры будут получать случайный порт из этого диапазона.
Marathon-агент запускает примерно такую команду.
При запуске контейнера он выбирает следующий свободный порт и подставляет его вместо знака вопроса. Таким образом в момент старта ноды в режиме сетевого моста у нас происходит мапинг портов.
Marathon стартует контейнер на случайном хосте и случайном порту.
Докер-контейнеры по умолчанию запускаются в режиме сетевого моста (bridge). Что это значит для нас? А то, что нода не будет видеть свой настоящий IP и порт! Допустим, что Apache Mesos поднял нам ноду на хосте 192.168.1.5 и порту 20345. Но процесс ноды в контейнере будет думать, что она поднимается на некотором 172.17.0.2; а порт у нее 5555.
И она зарегистрируется на хабе с таким обратным адресом. Естественно, хаб по этому адресу ее не найдет. И при запуске тестов хаб не сможет поднять сессию браузера.
Но есть еще режим host. Когда контейнер использует непосредственно порты хоста и у него нет такого понятия, как внутренний порт.
Когда мы задумались о решении данной задачи, естественно, мы подумали, зачем нам стартовать контейнер и при этом создавать сетевой мост, а почему бы не использовать хостовый режим? Мы указываем один порт, на котором поднимаемся, и контейнер, и на него же сразу смотрит selenium server.
Но не тут-то было. Чтобы наши тесты выполнялись в докер-контейнере, у которого как такового нет дисплея, а скриншоты снимать тоже надо, используем xvfb-сервер, который в момент старта контейнера тоже занимает определенный порт. Кстати, поэтому хостовый режим нас вообще не устраивает. Придется как-то подкручивать режим bridge.
Когда Marathon стартовал контейнер, он выставляет в переменных среды этого контейнера фактический хост и порты, на которых он поднял контейнер.
То есть у контейнера появляются значения переменных HOST и PORT0.
А значит, внутри контейнера есть информация о том, на каком хосте он развернут и какие внешние порты у него есть.
Чтобы у нас все заработало, необходимо, чтобы в значениях переменных host и Port, отправляемых в запросе на регистрацию, передавались значения переменных HOST и PORT0 самого контейнера.
Параметр HOST указать легко — у Selenium есть специальная настройка.
С портом сложнее. Если передать этот PORT0, то Selenium не только зарегистрируется под ним на хабе, но еще и сам на нем поднимется! Почему это проблема?
К примеру, Apache Mesos выдал нам внешний порт 20765. При старте контейнера он делает маппинг: 20765:5555. Второе число мы задаем сразу, жестко, в конфиге. И docker будет ожидать, что внутри контейнера нода будет висеть на 5555. И будет пересылать туда соединения с внешнего порта 20765.
Но если мы передадим ноде параметр -port 20765, то он изнутри будет слушать именно 20765! Не 5555. И все запросы извне не будут обрабатываться.
Возможно, вы уже догадались, что проблему можно решить, разделив понятие порта на два отдельных. Порт, на котором нода поднимается, и порт, который она должна сообщить хабу. В docker-среде эти значения как правило не совпадают.
Как сказать ноде об этих портах?
Никак.
Из коробки Selenium Standalone Server так не умеет.
Надо патчить Selenium.
Код самого Selenium находится на GitHub. И мы решили добавить в selenium standalone server еще немного… чудесного кода.
Добавили параметр advertisePort.
И условие в метод регистрации на сервере.
Теперь, если при запуске ноды задан параметр advertisePort, то он используется вместо стандартного port во время регистрации на хабе. Это локальный патч, мы пока не делали Pull Request в репозиторий selenium. Когда обкатаем до конца нашу схему, сделаем.
С помощью этого параметра ноды правильно регистрируются на хабе. Проверено, работает. Тесты прогоняются.
И да, мы использовали Marathon, так как он применяется нашими разработчиками. Это по сути proof of concept. Но вообще для запуска selenium grid-а этот фреймворк не идеально подходит, так как заточен на long running tasks. Такие как сервисы, UI-приложения.
В динамичной организационной среде требуется динамическое управление ресурсами. Статика будет ломаться об процессные проблемы.
Поэтому наша система для прогона тестов состоит из следующих компонент:
Нам не потребовалось дополнительного финансирования. И мы ускорили прогон тестов даже не до 10-ти минут, а до 5-ти. Средняя метрика для наших проектов стала равняться именно 5 минутам. 2 минуты на все процедуры поднятия/удаления грида, сборки проекта и т.д. И 3 минуты на выполнение тест-сьюитов.
Стоили ли затраченные усилия полученного результата? Безусловно, ведь в сухом остатке мы ускорили прогон тестов как минимум вдвое.
Если вы тоже не сильно любите очереди и пытаетесь ускорить прогон тестов — возможно, вам будет полезен наш опыт.
Кстати, если от постов про тестирование ваше сердце бьется чаще и возникает желание провернуть что-то подобное — обратите внимание, что у нас есть вакансия тестировщика.
А если есть какие-то вопросы и уточнения — обязательно пишите в комментариях.

Прежде чем начну рассказывать про сам selenium grid и все, что связано с ним, я хочу пояснить суть проблемы, которую мы пытались решить.
В прошлом году мы внедряли DevOps как процесс. И в один момент, автоматизируя все и вся, мы поняли, что time to market для каждого артефакта на этапе тестирования не должен превышать 30 минут. Концептуально мы хотели, чтобы некоторые релизы проходили автоверификацию, если приемочное тестирование им не нужно. Для тех артефактов, которые нужно проверять руками, 30 минут — это время, за которое тестировщик получает результаты прогона автотестов, анализирует их, а также делает приемочное тестирование. При этом автотесты должны автоматически запускаться в рамках нашего pipeline.
Чтобы достичь поставленной цели, нам необходимо было ускорить прогон автотестов. Но помимо ускорения автотестов, нужно было еще сделать так, чтобы при всем обилии проектов у нас не возникали очереди на их запуск.
Чаще всего задача ускорения прогона автотестов решается двумя способами:
- Подход богачей — заливание проблемы деньгами: покупка дополнительного железа, клаудов, найм новых людей.
- Подход для простолюдинов — инженерный способ решения этой задачи.
Мы у себя в компании придерживаемся второго подхода, но не потому, что у нас нет денег. Я — инженер, и, как многие инженеры, ленива в отношении таких вопросов. Поэтому решила пойти по более сложному и интересному пути. И при этом сэкономить банку тот самый мешочек с деньгами.
Итак, цель ясна: ускорить и устранить очереди на запуск автотестов без привлечения дополнительного финансирования.
В самом начале у нас был довольно небольшой парк, состоящий из 15 виртуальных машин.
- Средняя конфигурация машинки была следующая: 4RAM/2 core/50 HDD
- И в один момент времени на одной машинке без потерь в скорости мы могли выполнять не более 2-х потоков тестов. Т.е. запускать не более 2-х сессий с браузерами. В противном случае — скорость выполнения тестов проседала.
- Все машинки были виндовые, что тоже накладывало на нас определенные ограничения (например, кроссбраузерность мы вообще не тестировали)
- И машинки находились в разных подсетях Банка (разные дата-центры). Поэтому управлять их конфигурациями было крайне сложно, так как пересоздание и управление происходило на стороне сисадминов.
В общей сложности у нас около 20 проектов с автотестами, которые в разное время и с разной частотой запускаются.
Наши команды:
- хотят релизиться от 3-х до 5-ти раз в день
- выпускают релизы не чаще раза в 1-2 недели
И у всех команд фокус на быструю доставку ценности до клиента. Само собой, никто не хочет “висеть” в очереди на запуск автотестов.
Ресурсов катастрофически не хватало. Почему? Давайте рассмотрим на конкретном примере:
- У нас есть проект, в котором порядка 30 тестов (это средняя цифра)
- Если мы запускаем тесты в один поток — то это как минимум 30 минут.
- Наша цель уложиться в 10 минут — значит, надо параллелить прогон тестов на несколько браузеров, а соответственно — на несколько машин.
- Значит, запускаем эти тесты в параллели как минимум в 3 потока. На практике же выходит, что каждый проект генерирует от 5 до 10 потоков.
- А теперь вспомним о наших 20 проектах. Если у нас возникает ситуация, когда все одновременно хотят запустить автотесты, чтобы избежать очереди, нужно минимум поднять 60 сессий с тестами.
- 40 еще поднимутся, с учетом того, что по 2 сессии на виртуалку.
- А остальные попадут в очередь — минимум на 10 минут.
Заметьте, мы рассмотрели очень положительный случай, когда тестов в проекте немного, и всего-то 3 потока. Железа не хватает, нужно думать о том, как облегчить нагрузку на виртуалки. Что если мы переедем с виртуальных машин в докер-контейнеры?
Посчитали:
- Возьмем наши 15 машин и построим из них единое пространство, где будем создавать докер-контейнеры, в которых будут прогоняться наши тесты.
- 15 виртуальных машин = это 60 RAM, 30 core и 750 HDD, причем это все находится в трех дата центрах, т.е. мы можем создать отказоустойчивое пространство.
Давайте рассмотрим конфигурацию одного докер-контейнера, который позволит прогнать тесты в 1 поток, и сравним с тем, что у нас было при использовании виртуальных машин:
500 RAM, 0,01% core, и HDD 400 мб.

Получается, что в один момент времени мы можем создать 120 контейнеров!
Это не только перекрывает наши запросы в 60 сессий, но и страхует на будущее. Ведь количество команд растет, а значит — количество запускаемых проектов тоже постоянно растет. Итак, стало достаточно очевидно, что нам нужно взять имеющиеся ресурсы и объединить их в единое пространство вычислительных мощностей, это еще называют песочницей. Объединяя, мы при этом не хотим думать о нем именно в парадигме каких-то хостов/виртуальных машин. Мы хотим иметь просто пространство, к которому мы сможем подключаться с помощью какого-нибудь api, и создавать в нем свои докер-контейнеры, на которых потом будем запускать тесты.
Динамическая песочница
Итак, нам необходимо создать песочницу вычислительных ресурсов. При этом она должна быть динамической: т.е. мы должны иметь возможность в любой момент подключить/отключить от нее ресурсы, которые у нас есть. Причем все хосты, которые мы подключаем, могут иметь разную конфигурацию и быть в различных подсетях, для нас лишь главное, чтобы между ними можно было установить связь по определенным ip и портам. Динамическую песочницу называют еще облаком или кластером, и в нем мы имеем интерфейс для создания и управления докер-контейнерами.
Когда мы поняли, как хотим решить задачу, мы построили нашу песочницу, объединив наши хосты в кластер с помощью Apache Mesos и Marathon.

Таким образом мы получаем общее пространство с вычислительными ресурсами, у которого есть свое api. API нам предоставляет Marathon, а Apache Mesos как раз таки и объединяет хосты.
Оркестратор тестов: Selenium grid спешит на помощь
Мы определились с тем, что нам нужен кластер, и даже его создали. Но вот вопрос, как же мы будем запускать тесты в кластере? Вы же помните, что мы хотим в любом случае получать результаты тестов не больше, чем за 10 минут?
И тут на помощь нам должна прийти параллелизация запуска тестов.
Для решения этой задачи нам нужен централизованный инструмент, который позволит запускать и параллелить тесты в несколько потоков для каждого проекта. Есть несколько популярных инструментов.
- Jenkins
- нативный оркестратор Selenium
Хоть мой рассказ и про то, как мы запускали selenium grid в докер-контейнерах — сначала рассмотрим, как вообще работает грид на виртуальных машинах.

Фактически вся процедура представляет из себя 3 действия:
1. Мы копируем Selenium Standalone Server (нужной нам версии) в какую-нибудь директорию.
2. Затем выполняем команду, которая запускает этот сервер в нужном нам режиме: хаба, либо режим ноды. Обратите внимание, что за эти две функции отвечает один и тот же физический jar-ник, который вы продублировали на разные хосты.
$ java
-jar selenium-server-standalone.jar
-role hub3. Конфигурируем ноду. Либо через командную строку, либо в json-файле указываем набор браузеров и их параметры.
$ java \
-jar selenium-server-standalone.jar \
-role node \
-hub http://host1:4444/grid/registerЧто делает хаб после старта грида
- Создает новые сессии с нодами
- Отправляет тестовые запросы в очередь, если все ноды заняты;
- Отвечает ошибкой, если у него нет нод или ноды с конкретными параметрами
Что делает нода
- После того как мы запустили сервер в режиме ноды на виртуалке и указали в параметрах команды адрес хаба, задача ноды — зарегистрировать на хабе. То есть сообщить ему, что она находится в его гриде, и о том, какие браузеры с драйверами у нее есть.
- Сама регистрация выглядит как посыл http-запроса с отправкой json-массива, в котором содержится вся информация по ноде.
- Следующая задача ноды — это исполнение тех запросов, которые она принимает через хаб после того, как тот создал сессию с этой нодой.
- Под запросами я подразумеваю те команды, которые шлет наш jar-ник с автотестами. Как пример, командой будет какой-нибудь шаг типа “Найди мне кнопку на данной странице со следующим id”. Соответственно, хабу чтобы выполнить такой шаг теста, нужно знать, к какому вообще тесту относится данный шаг. Ведь в один момент он может выполнять несколько тестов. И этот шаг подразумевает, что тот, кто будет выполнять эту команду, уже выполнил какую-то предысторию из других команд, например, перешел как раз таки на соответствующую страницу. Вот именно для этого и нужен уникальный идентификатор сессии с браузером в ноде, который создает хаб и затем по этому ИД понимает, на какую ноду ему распределять запросы.
- Нода же просто ждет команды от хаба, и при получении http-запросов, которые он перенаправляет на нее — она их выполняет.
Чем же отличается старт грида в докер-контейнерах?
1. Нода на момент старта уже сконфигурирована.
Давайте посмотрим на содержимое ноды. Файл с json-конфигом для ноды находится в контейнере с ней, затем мы его переименовываем, и наш сервер узнает о своих параметрах из этого файла:
/opt/selenium/generate_config > /opt/selenium/config.json При этом если мы посмотрим на содержимое Dockerfile самой ноды, то увидим, что при конфигурировании окружения ноды мы сразу задаем переменные окружения, которые потом записываются в этот конфиг. Таким образом, нам не нужно лезть в “кишки” самого контейнера, чтобы изменить параметры запуска ноды, нам достаточно в Dockerfile переопределить значения указанных переменных. И все.
2. Когда мы стартуем ноду в контейнере, мы всегда можем быть уверены в том, что у нашего окружения уже есть браузер и драйвер для него. Потому что все это настраивается и устанавливается в момент сборки самого образа.
$ /opt/selenium$ ls
chromedriver-2.29
selenium-server-standalone.jar
config.json
3. Также у нас есть скрипт sh, который выполняется после старта контейнера. И в этом скрипте мы видим, что после того, как у нас поднялся контейнер — у нас сразу же стартует наш java сервер.
$ java ${JAVA_OPTS} -jar /opt/selenium/selenium-server-standalone.jar \
-role node \
-hub http://$HUB_HOST:$HUB_PORT/grid/register \
-nodeConfig /opt/selenium/config.json \
${SE_OPTS} &
Аналогично все по отношению к хабу.
В итоге запуск selenium grid в контейнере сводится к одной команде — старт докер-контейнера.
Проблема статического грида
Несмотря на то, что хаб хорошо умеет работать с очередями и тайм-аутами, в самом начале использования статического грида мы испытали проблемы из-за тайм-аутов. Если хаб и нода долго не использовались, то при последующем коннекте мы ловили ситуации, когда при создании сессии на ноде эта самая сессия отваливалась именно по тайм-аутам или по причине того, что remotewebdriver не может поднять браузер. И все эти проблемы лечились рестартом грида, именно тогда мы и поняли, что для нас on-demand selenium grid будет решением проблемы.
Также мы не хотели, чтобы статический грид просто занимал место в кластере, который у нас и так небольшой. Как решить ситуацию, когда для разных проектов нам нужны разные конфигурации грида? Когда для одного проекта нужна одна версия браузера, для другого — другая? Очевидно, что держать включенными гриды — не самая хорошая идея.
Selenium Grid On-Demand
Поэтому мы захотели поднимать selenium grid по запросу: объясню на примере
- Допустим, мы хотим запустить тесты для проекта с 30-ю тестами, которые разложены в 3 тест-сьюита.
- Значит, мы запускаем джоб, который сначала нам создает selenium grid в кластере для этого прогона, и в качестве значения параметра о количестве нод в гриде он передает количество наших тест-сьюитов. То есть, для каждого проекта — конфигурация грида своя.
- После того как отработала команда поднятия selenium grid-а, происходит запуск тестов.
- После прогона тестов — грид удаляется.
Казалось бы, идеальная концепция. Мы таким подходом решаем сразу две проблемы: и с деградацией грида, и с нехваткой места в кластере для хранения различных конфигураций грида.
Автоматизация создания Selenium Grid On-Demand
Чтобы решить эту задачу, надо было написать скрипт автоматизированного создания грида. Мы ее решили с помощью ansible, написав нужные роли. Я не буду рассказывать, что такое ansible. Но могу сказать, что написать подобный скрипт вы у себя сможете также и на bash-e или на другом языке программирования, который на выходе вам предоставляет две команды на создание и удаление грида.
Помним, что запуск грида состоит из запуска парочки команд. И у каждой команды есть свои параметры. И чтобы автоматизировать запуск этих команд, эти параметры надо лишь автоматически вычислять до запуска команды. Либо же хардкодить.
Мы не можем хардкодить, потому что мы априори не знаем, на каком хосте и порту поднимутся компоненты Selenium Grid, так как за нас это решает Apache Mesos.
Мы, конечно, можем извернуться и вручную следить за открытыми портами и хостами, на которых поднимаем Selenium Grid, но тогда зачем нам вообще Apache Mesos и Marathon, если все будем делать вручную?
Итак, надо было автоматизировать вычисление следующих параметров:
- количество нод, которые мы поднимаем
- определение адреса хаба (его хост и порт, на котором он поднялся), чтобы передавать это значение ноде, иначе она не сможет зарегистрироваться.
В этом нам помогло api Marathon-а, с его помощью мы получали данные о том, на каком хосте и порту поднялся хаб. И потом уже это значение передавали перед стартом нод. Итак, что у нас получилось:
Deploy Selenium Grid
$ ansible-playbook -i inventory play-site.yml \
-e test_id=mytest \
-e nodes_type=chrome \
-e nodes_count=4test_id: уникальный идентификатор проекта с тестами
nodes_count: количество нод
nodes_type: тип браузера [chrome|firefox]
Delete Selenium Grid
$ ansible-playbook -i inventory play-site.yml \
-e test_id=mytest \
-e clean=true Shell-скрипты, исполняемые на Jenkins, перед запуском ansible playbook рассчитываются автоматически и передают значение переменной. Прогон тестов встроен в pipeline с помощью job dsl.
export grid_name=testproject
export nodes_count=$(find tests -name "*feature" \
| grep -v build | grep -v classes | grep features | wc -l)
cd ansible
ansible-playbook -i inventory play-site.yml \
-e test_id=$grid_name \
-e nodes_type=chrome \
-e nodes_count=$nodes_count
export hub_url=$(cat hub.url)
currentdir=$(pwd)
cd ../tests
./gradlew clean generateCucumberReport \
-i -Pbrowser=$browser -PremoteHub=$hub_url
Как только мы решили эту задачу и научились поднимать selenium grid в нашем кластере, то поспешили запустить тесты, и тут-то нас ожидало разочарование. Тесты не запускаются, более того — хаб даже не поднимает сессию с нодой.
Проблема поднятия Selenium Grid On-Demand в распределенном кластере
Давайте разберемся, чего же не хватало нашим скриптам.
Еще раз взглянем, как бы выглядела команда, если бы мы запускали каждый раз ноды в Docker-контейнере для selenium grid вручную:
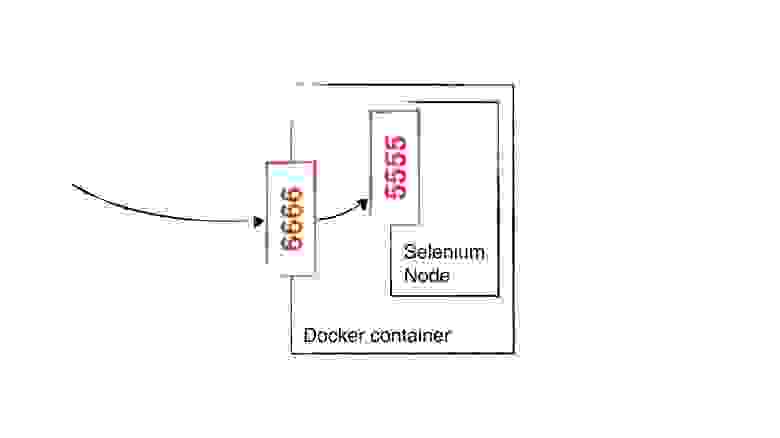
$ docker run -d -p 6666:5555 selenium/node-chromeВы видите два порта? Наверное, некоторым из вас интересно, откуда появился второй порт. Так вот, у докера есть внутренний порт и внешний порт. Внешний порт слушает сам контейнер. А внутренний порт прослушивается самим процессом selenium server standalone, который запускается в режиме -node.

В этом примере все запросы на порт 6666 контейнера будут пересылаться на порт 5555 ноды внутри него.
Запуск ноды в Marathon
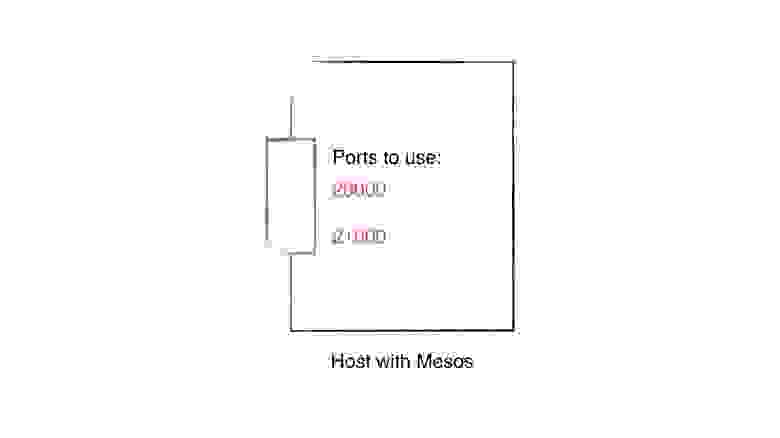
При настройке Apache Mesos-кластера мы для каждого хоста указываем диапазон портов. Этот диапазон используется для контейнеров, которые поднимаются Marathon’ом.

К примеру, если мы ставим диапазон 20000-21000, то наши контейнеры будут получать случайный порт из этого диапазона.
Marathon-агент запускает примерно такую команду.
$ docker run -d -p <?>:5555 selenium/node-chromeПри запуске контейнера он выбирает следующий свободный порт и подставляет его вместо знака вопроса. Таким образом в момент старта ноды в режиме сетевого моста у нас происходит мапинг портов.
$ docker run -d -p 20345:5555 selenium/node-chromeMarathon стартует контейнер на случайном хосте и случайном порту.
Нода отправляет неправильные координаты
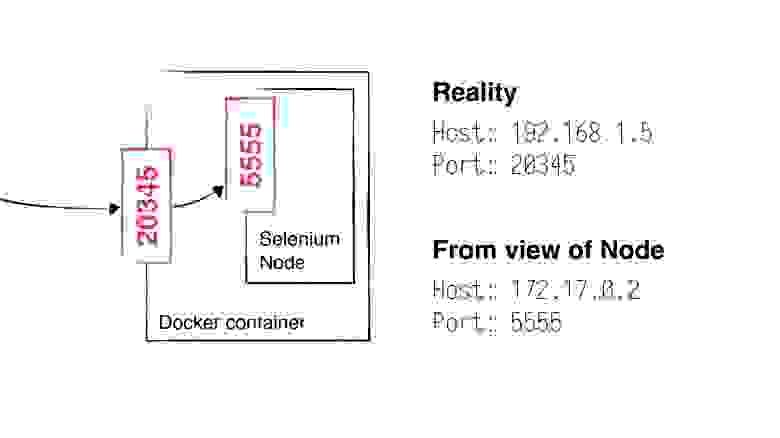
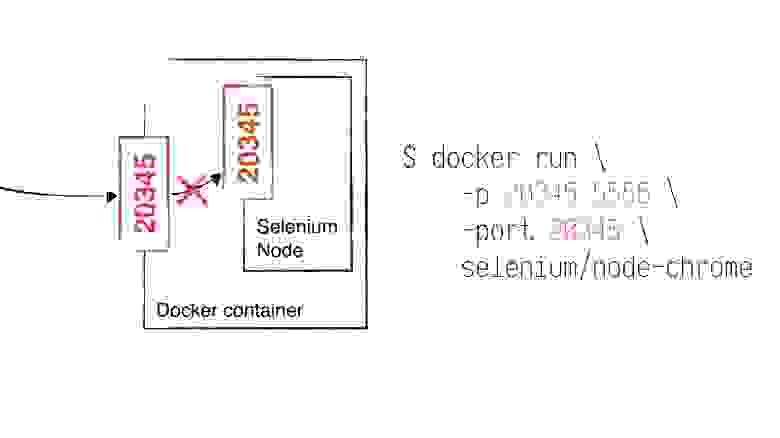
Докер-контейнеры по умолчанию запускаются в режиме сетевого моста (bridge). Что это значит для нас? А то, что нода не будет видеть свой настоящий IP и порт! Допустим, что Apache Mesos поднял нам ноду на хосте 192.168.1.5 и порту 20345. Но процесс ноды в контейнере будет думать, что она поднимается на некотором 172.17.0.2; а порт у нее 5555.
host = 172.17.0.2
port = 5555И она зарегистрируется на хабе с таким обратным адресом. Естественно, хаб по этому адресу ее не найдет. И при запуске тестов хаб не сможет поднять сессию браузера.

Решение проблемы регистрации ноды на хабе
Но есть еще режим host. Когда контейнер использует непосредственно порты хоста и у него нет такого понятия, как внутренний порт.
Когда мы задумались о решении данной задачи, естественно, мы подумали, зачем нам стартовать контейнер и при этом создавать сетевой мост, а почему бы не использовать хостовый режим? Мы указываем один порт, на котором поднимаемся, и контейнер, и на него же сразу смотрит selenium server.
Но не тут-то было. Чтобы наши тесты выполнялись в докер-контейнере, у которого как такового нет дисплея, а скриншоты снимать тоже надо, используем xvfb-сервер, который в момент старта контейнера тоже занимает определенный порт. Кстати, поэтому хостовый режим нас вообще не устраивает. Придется как-то подкручивать режим bridge.
Переменные среды контейнера
Когда Marathon стартовал контейнер, он выставляет в переменных среды этого контейнера фактический хост и порты, на которых он поднял контейнер.
То есть у контейнера появляются значения переменных HOST и PORT0.
А значит, внутри контейнера есть информация о том, на каком хосте он развернут и какие внешние порты у него есть.
Чтобы у нас все заработало, необходимо, чтобы в значениях переменных host и Port, отправляемых в запросе на регистрацию, передавались значения переменных HOST и PORT0 самого контейнера.
{
…
"host": "$HOST",
"port": "$PORT0",
…
}Параметр HOST указать легко — у Selenium есть специальная настройка.
С портом сложнее. Если передать этот PORT0, то Selenium не только зарегистрируется под ним на хабе, но еще и сам на нем поднимется! Почему это проблема?
К примеру, Apache Mesos выдал нам внешний порт 20765. При старте контейнера он делает маппинг: 20765:5555. Второе число мы задаем сразу, жестко, в конфиге. И docker будет ожидать, что внутри контейнера нода будет висеть на 5555. И будет пересылать туда соединения с внешнего порта 20765.
Но если мы передадим ноде параметр -port 20765, то он изнутри будет слушать именно 20765! Не 5555. И все запросы извне не будут обрабатываться.

Возможно, вы уже догадались, что проблему можно решить, разделив понятие порта на два отдельных. Порт, на котором нода поднимается, и порт, который она должна сообщить хабу. В docker-среде эти значения как правило не совпадают.
Как сказать ноде об этих портах?
Никак.
Из коробки Selenium Standalone Server так не умеет.
Надо патчить Selenium.
Патчим Selenium Server
Код самого Selenium находится на GitHub. И мы решили добавить в selenium standalone server еще немного… чудесного кода.
Добавили параметр advertisePort.
@Expose( serialize = false )
@Parameter(
names = "-advertisePort",
description = "<Integer> : advertise port of Node. "
+ "This port is sent to Hub for backward communication with this node."
)
public Integer advertisePort;
И условие в метод регистрации на сервере.
if (registrationRequest.getConfiguration().advertisePort != null) {
registrationRequest.getConfiguration().port =
registrationRequest.getConfiguration().advertisePort;
}
Теперь, если при запуске ноды задан параметр advertisePort, то он используется вместо стандартного port во время регистрации на хабе. Это локальный патч, мы пока не делали Pull Request в репозиторий selenium. Когда обкатаем до конца нашу схему, сделаем.
С помощью этого параметра ноды правильно регистрируются на хабе. Проверено, работает. Тесты прогоняются.
И да, мы использовали Marathon, так как он применяется нашими разработчиками. Это по сути proof of concept. Но вообще для запуска selenium grid-а этот фреймворк не идеально подходит, так как заточен на long running tasks. Такие как сервисы, UI-приложения.
Выводы
В динамичной организационной среде требуется динамическое управление ресурсами. Статика будет ломаться об процессные проблемы.
Поэтому наша система для прогона тестов состоит из следующих компонент:
- кластер, в котором создаются докер-контейнеры
- selenium grid как приложение, которое состоит из следующих компонент: хаб и ноды
- Jenkins как приложение, которое выполняет наши job-ы
- и скрипты, которые автоматизируют какую-то работу. К ним у нас относятся ansible и sh-скрипты.
Нам не потребовалось дополнительного финансирования. И мы ускорили прогон тестов даже не до 10-ти минут, а до 5-ти. Средняя метрика для наших проектов стала равняться именно 5 минутам. 2 минуты на все процедуры поднятия/удаления грида, сборки проекта и т.д. И 3 минуты на выполнение тест-сьюитов.
Стоили ли затраченные усилия полученного результата? Безусловно, ведь в сухом остатке мы ускорили прогон тестов как минимум вдвое.
Если вы тоже не сильно любите очереди и пытаетесь ускорить прогон тестов — возможно, вам будет полезен наш опыт.
Кстати, если от постов про тестирование ваше сердце бьется чаще и возникает желание провернуть что-то подобное — обратите внимание, что у нас есть вакансия тестировщика.
А если есть какие-то вопросы и уточнения — обязательно пишите в комментариях.
