 (*) На самом деле, не совсем.
(*) На самом деле, не совсем.
Наверное, многие слышали про Valgrind — отладчик, который может сказать, где в вашей нативной программе утечка памяти, где ветвление зависит от неинициализированной переменной и многое другое (а ведь кроме memcheck, у него есть и другие режимы работы). Внутри себя эта чудо-программа перемалывает нативный код в некий промежуточный байткод, инструментирует его и генерирует новый машинный код — уже с run-time проверками. Но есть проблема: Valgrind не умеет работать под Windows. Когда мне это понадобилось, поиски привели меня к аналогичной утилите под названием DrMemory, также с ней в комплекте был аналог strace. Но речь не столько о них, сколько о библиотеке динамической инструментации, на базе которой они построены, DynamoRIO. В какой-то момент я заинтересовался этой библиотекой с точки зрения написания собственной инструментации, начал искать документацию, набрёл на большое количество примеров и был поражён тем, что простенькую, но законченную инструментацию вроде подсчёта инструкций вызова можно написать буквально в 237 строк сишного кода, 32 из которых — лицензия, а 8 — описание. Нет, это, конечно не "пишем убийцу Valgrind в 30 строк кода на JavaScript", но сильно проще, чем то, что можно представить для подобной задачи.
В качестве примера давайте напишем уже четвёртую реализацию инструментации для фаззера American Fuzzy Lop, о котором недавно уже писали на Хабре.
Что такое AFL
AFL — это инструмент для поиска багов и уязвимостей на основе guided fuzzing, собранный из железобетонных костылей эвристик, реализованных максимально тривиальным и эффективным способом. Вот так смотришь на инструмент, способный, наблюдая за поведением libjpeg, синтезировать валидные джипеги, и поражаешься, что всё это сделано на основе не такой уж и заумной механики. Вкратце, для полноценной работы AFL целевой бинарник должен быть инструментирован таким образом, чтобы в процессе выполнения собирать рёберное покрытие: представим себе каждый базовый блок (basic block, что-то вроде последовательности инструкций от метки и до ближайшей инструкции перехода) в качестве вершины графа. Рёбра — это возможные пути передачи управления между ББ. Соответственно, AFL интересует то, какие переходы и в каком примерно количестве происходили между базовыми блоками программы.
Основной способ инструментации в AFL — статическая на этапе компиляции с помощью обёрток afl-gcc / afl-g++ или их аналогов для clang. Что забавно, afl-gcc подменяет вызываемую команду as на обёртку, переписывающую ассемблерный листинг, сгенерированный компилятором. Есть и более продвинутый вариант, называемый llvm mode, который честно встраивается в процесс компиляции (производимой с помощью LLVM, естественно) и, теоретически, должен поэтому давать большую производительность генерируемого кода. Наконец, для фаззинга уже скомпилированных бинарников есть qemu mode — патч к QEMU в режиме эмуляции одного процесса, добавляющий необходимую инструментацию (изначально этот режим работы QEMU предназначался, чтобы запускать отдельные процессы, собранные для другой архитектуры, используя хостовое ядро).
Что такое DynamoRIO
DynamoRIO — это система динамической инструментации (то есть она инструментирует уже скомпилированные бинарники прямо во время выполнения), работающая на Windows, Linux и Android на архитектурах x86 и x86_64, а также ARM (поддержка AArch64 есть в release candidate версии 7.0). В отличие от QEMU, она предназначена не для исполнения программ "близко к тексту" на чужой архитектуре, а для лёгкого создания собственных инструментаций, модифицирующих поведение программы на родной архитектуре. При этом ставится цель по возможности не портить оптимизированный код. К сожалению, я так и не нашёл способ, при котором клиенты (так называются пользовательские библиотеки инструментации) могли бы не знать о целевом наборе инструкций (кроме каких-то тривиальных случаев, где достаточно кроссплатформенных обёрток для базовых инструкций), поскольку не происходит конверсии "машинный код -> байткод — [инструментация] -> новый байткод -> инструментированный машинный код". Вместо этого на каждый транслируемый базовый блок происходит передача клиенту списка декодированных инструкций, который он может изменять и дополнять с помощью удобных функций и макросов. То есть в машинных кодах программировать не нужно, но набор инструкций x86 (или другой платформы) знать, скорее всего, придётся.
В качестве небольшого бонуса: полез я посмотреть, что ещё есть интересного в их аккаунте на Гитхабе, и набрёл на занятный репозиторий: DRK. Репозиторий, похоже, заброшен и несколько потерял актуальность, но описание впечатляет:
DRK is DynamoRIO as a loadable Linux Kernel module. When DRK is loaded, all kernel-mode execution (system calls, interrupt & exception handlers, kernel threads, etc.) happens under the purview of DynamoRIO whereas user-mode execution is untouched — the inverse of normal DynamoRIO, which instruments a user-mode process and doesn't touch kernel-mode execution.
Тестовая программа
Для начала посмотрим, на что в принципе способен AFL. Нет, мы не будем брать уязвимую версию какой-нибудь библиотеки и ждать часы или сутки. Для теста напишем максимально тупую программу, которая разыменовывает нулевой указатель, если на stdin подать ей строку, начинающуюся с букв NULL. Это, конечно, не синтез джипега из ниоткуда, но зато и ждать почти не нужно.
Итак, скачаем AFL отсюда и соберём его. Как вы уже, наверное, догадались, собирать будем под GNU/Linux. Впрочем, другие Unix-like системы и Юниксы вроде Mac OS X тоже должны работать. Возьмём небольшую программку:
#include <stdio.h> #include <string.h> volatile int *ptr = NULL; const char cmd[] = "NULL"; int main(int argc, char *argv[]) { char buf[16]; fgets(buf, sizeof buf, stdin); if (strncmp(buf, cmd, 4)) { return 0; } *ptr = 1; return 0; }
Скомпилируем её и запустим фаззинг:
$ export AFL_PATH=~/tmp/build/afl-2.42b/ $ # Запустим стандартную обёртку, которая статически добавит инструментацию $ $AFL_PATH/afl-gcc example-bug-libc.c -o example-bug-libc $ # Создадим какой-нибудь пример входного файла (можно несколько) $ mkdir input $ echo test > input/1 $ # Запустим фаззер $ $AFL_PATH/afl-fuzz -i input -o output -- ./example-bug-libc
И что же мы видим:

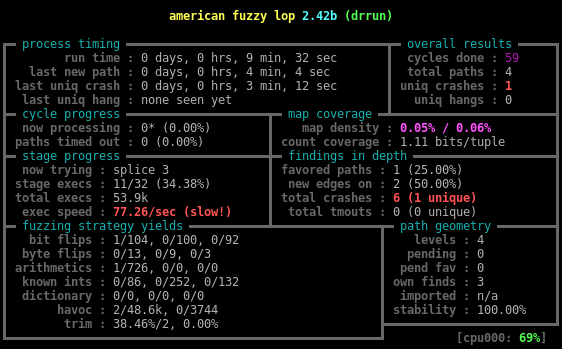
Как-то оно не работает… Обратите внимание на строчку last new path: AFL ругается, что по прошествии 91 тысячи запусков он так и не нашёл новый путь. На самом деле это вполне логично: напомню, мы использовали статическую инструментацию на этапе вызова ассемблера. Основное же сравнение делает функция из libc, которая не инструментирована, и поэтому не получится посчитать количество совпавших символов. Так я думал, пока не решил это проверить, но оказалось, что наш бинарник не импортирует функцию strncmp. Судя по выводу objdump -d, компилятор просто сгенерировал на месте strncmp инструкцию с префиксом вместо цикла, куда можно было бы впихнуть инструментацию.
00000000000007f0 <.plt.got>: 7f0: ff 25 82 17 20 00 jmpq *0x201782(%rip) # 201f78 <getenv@GLIBC_2.2.5> 7f6: 66 90 xchg %ax,%ax 7f8: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201f88 <_exit@GLIBC_2.2.5> 7fe: 66 90 xchg %ax,%ax 800: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201f90 <write@GLIBC_2.2.5> 806: 66 90 xchg %ax,%ax 808: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201f98 <__stack_chk_fail@GLIBC_2.4> 80e: 66 90 xchg %ax,%ax 810: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201fa0 <close@GLIBC_2.2.5> 816: 66 90 xchg %ax,%ax 818: ff 25 8a 17 20 00 jmpq *0x20178a(%rip) # 201fa8 <read@GLIBC_2.2.5> 81e: 66 90 xchg %ax,%ax 820: ff 25 92 17 20 00 jmpq *0x201792(%rip) # 201fb8 <fgets@GLIBC_2.2.5> 826: 66 90 xchg %ax,%ax 828: ff 25 9a 17 20 00 jmpq *0x20179a(%rip) # 201fc8 <waitpid@GLIBC_2.2.5> 82e: 66 90 xchg %ax,%ax 830: ff 25 a2 17 20 00 jmpq *0x2017a2(%rip) # 201fd8 <shmat@GLIBC_2.2.5> 836: 66 90 xchg %ax,%ax 838: ff 25 a2 17 20 00 jmpq *0x2017a2(%rip) # 201fe0 <atoi@GLIBC_2.2.5> 83e: 66 90 xchg %ax,%ax 840: ff 25 aa 17 20 00 jmpq *0x2017aa(%rip) # 201ff0 <__cxa_finalize@GLIBC_2.2.5> 846: 66 90 xchg %ax,%ax 848: ff 25 aa 17 20 00 jmpq *0x2017aa(%rip) # 201ff8 <fork@GLIBC_2.2.5> 84e: 66 90 xchg %ax,%ax ... 0000000000000850 <main>: 850: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp 857: ff 858: 48 89 14 24 mov %rdx,(%rsp) 85c: 48 89 4c 24 08 mov %rcx,0x8(%rsp) 861: 48 89 44 24 10 mov %rax,0x10(%rsp) 866: 48 c7 c1 04 6a 00 00 mov $0x6a04,%rcx 86d: e8 9e 02 00 00 callq b10 <__afl_maybe_log> 872: 48 8b 44 24 10 mov 0x10(%rsp),%rax 877: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx 87c: 48 8b 14 24 mov (%rsp),%rdx 880: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp 887: 00 888: 53 push %rbx 889: be 10 00 00 00 mov $0x10,%esi 88e: 48 83 ec 20 sub $0x20,%rsp 892: 48 8b 15 77 17 20 00 mov 0x201777(%rip),%rdx # 202010 <stdin@@GLIBC_2.2.5> 899: 48 89 e7 mov %rsp,%rdi 89c: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax 8a3: 00 00 8a5: 48 89 44 24 18 mov %rax,0x18(%rsp) 8aa: 31 c0 xor %eax,%eax 8ac: e8 6f ff ff ff callq 820 <.plt.got+0x30> 8b1: 48 8d 3d dc 06 00 00 lea 0x6dc(%rip),%rdi # f94 <cmd> 8b8: b9 04 00 00 00 mov $0x4,%ecx 8bd: 48 89 e6 mov %rsp,%rsi 8c0: f3 a6 repz cmpsb %es:(%rdi),%ds:(%rsi) 8c2: 75 45 jne 909 <main+0xb9> 8c4: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp 8cb: ff 8cc: 48 89 14 24 mov %rdx,(%rsp) 8d0: 48 89 4c 24 08 mov %rcx,0x8(%rsp) 8d5: 48 89 44 24 10 mov %rax,0x10(%rsp) 8da: 48 c7 c1 2d 5b 00 00 mov $0x5b2d,%rcx 8e1: e8 2a 02 00 00 callq b10 <__afl_maybe_log> 8e6: 48 8b 44 24 10 mov 0x10(%rsp),%rax 8eb: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx 8f0: 48 8b 14 24 mov (%rsp),%rdx 8f4: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp 8fb: 00 8fc: 48 8b 05 1d 17 20 00 mov 0x20171d(%rip),%rax # 202020 <ptr> 903: c7 00 01 00 00 00 movl $0x1,(%rax) 909: 0f 1f 00 nopl (%rax) 90c: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp 913: ff 914: 48 89 14 24 mov %rdx,(%rsp) 918: 48 89 4c 24 08 mov %rcx,0x8(%rsp) 91d: 48 89 44 24 10 mov %rax,0x10(%rsp) 922: 48 c7 c1 8f 33 00 00 mov $0x338f,%rcx 929: e8 e2 01 00 00 callq b10 <__afl_maybe_log> 92e: 48 8b 44 24 10 mov 0x10(%rsp),%rax 933: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx 938: 48 8b 14 24 mov (%rsp),%rdx 93c: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp 943: 00 944: 31 c0 xor %eax,%eax 946: 48 8b 54 24 18 mov 0x18(%rsp),%rdx 94b: 64 48 33 14 25 28 00 xor %fs:0x28,%rdx 952: 00 00 954: 75 40 jne 996 <main+0x146> 956: 66 90 xchg %ax,%ax 958: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp 95f: ff 960: 48 89 14 24 mov %rdx,(%rsp) 964: 48 89 4c 24 08 mov %rcx,0x8(%rsp) 969: 48 89 44 24 10 mov %rax,0x10(%rsp) 96e: 48 c7 c1 0a 7d 00 00 mov $0x7d0a,%rcx 975: e8 96 01 00 00 callq b10 <__afl_maybe_log> 97a: 48 8b 44 24 10 mov 0x10(%rsp),%rax 97f: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx 984: 48 8b 14 24 mov (%rsp),%rdx 988: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp 98f: 00 990: 48 83 c4 20 add $0x20,%rsp 994: 5b pop %rbx 995: c3 retq 996: 66 90 xchg %ax,%ax 998: 48 8d a4 24 68 ff ff lea -0x98(%rsp),%rsp 99f: ff 9a0: 48 89 14 24 mov %rdx,(%rsp) 9a4: 48 89 4c 24 08 mov %rcx,0x8(%rsp) 9a9: 48 89 44 24 10 mov %rax,0x10(%rsp) 9ae: 48 c7 c1 a8 dc 00 00 mov $0xdca8,%rcx 9b5: e8 56 01 00 00 callq b10 <__afl_maybe_log> 9ba: 48 8b 44 24 10 mov 0x10(%rsp),%rax 9bf: 48 8b 4c 24 08 mov 0x8(%rsp),%rcx 9c4: 48 8b 14 24 mov (%rsp),%rdx 9c8: 48 8d a4 24 98 00 00 lea 0x98(%rsp),%rsp 9cf: 00 9d0: e8 33 fe ff ff callq 808 <.plt.got+0x18> 9d5: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 9dc: 00 00 00 9df: 90 nop
0000000000000630 <.plt.got>: 630: ff 25 82 09 20 00 jmpq *0x200982(%rip) # 200fb8 <strncmp@GLIBC_2.2.5> 636: 66 90 xchg %ax,%ax 638: ff 25 8a 09 20 00 jmpq *0x20098a(%rip) # 200fc8 <__stack_chk_fail@GLIBC_2.4> 63e: 66 90 xchg %ax,%ax 640: ff 25 92 09 20 00 jmpq *0x200992(%rip) # 200fd8 <fgets@GLIBC_2.2.5> 646: 66 90 xchg %ax,%ax 648: ff 25 aa 09 20 00 jmpq *0x2009aa(%rip) # 200ff8 <__cxa_finalize@GLIBC_2.2.5> 64e: 66 90 xchg %ax,%ax ... 0000000000000780 <main>: 780: 55 push %rbp 781: 48 89 e5 mov %rsp,%rbp 784: 48 83 ec 30 sub $0x30,%rsp 788: 89 7d dc mov %edi,-0x24(%rbp) 78b: 48 89 75 d0 mov %rsi,-0x30(%rbp) 78f: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax 796: 00 00 798: 48 89 45 f8 mov %rax,-0x8(%rbp) 79c: 31 c0 xor %eax,%eax 79e: 48 8b 15 6b 08 20 00 mov 0x20086b(%rip),%rdx # 201010 <stdin@@GLIBC_2.2.5> 7a5: 48 8d 45 e0 lea -0x20(%rbp),%rax 7a9: be 10 00 00 00 mov $0x10,%esi 7ae: 48 89 c7 mov %rax,%rdi 7b1: e8 8a fe ff ff callq 640 <.plt.got+0x10> 7b6: 48 8d 45 e0 lea -0x20(%rbp),%rax 7ba: ba 04 00 00 00 mov $0x4,%edx 7bf: 48 8d 35 ce 00 00 00 lea 0xce(%rip),%rsi # 894 <cmd> 7c6: 48 89 c7 mov %rax,%rdi 7c9: e8 62 fe ff ff callq 630 <.plt.got> 7ce: 85 c0 test %eax,%eax 7d0: 74 07 je 7d9 <main+0x59> 7d2: b8 00 00 00 00 mov $0x0,%eax 7d7: eb 12 jmp 7eb <main+0x6b> 7d9: 48 8b 05 40 08 20 00 mov 0x200840(%rip),%rax # 201020 <ptr> 7e0: c7 00 01 00 00 00 movl $0x1,(%rax) 7e6: b8 00 00 00 00 mov $0x0,%eax 7eb: 48 8b 4d f8 mov -0x8(%rbp),%rcx 7ef: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx 7f6: 00 00 7f8: 74 05 je 7ff <main+0x7f> 7fa: e8 39 fe ff ff callq 638 <.plt.got+0x8> 7ff: c9 leaveq 800: c3 retq 801: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 808: 00 00 00 80b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
Что интересно, похоже, AFL сам включил оптимизацию, потому что в неинструментированном коде честно вызывается strncmp. Что же до разбухшей PLT в коде, собранном afl-gcc, то, судя по всему, мы видим функции, вызываемые forkserver-ом — его мы тоже напишем, но обо всём по порядку. Хорошо, сделаем вид, что этого не видели, и попробуем наивным образом переписать наш пример без библиотечных функций:
#include <stdio.h> volatile int *ptr = NULL; const char cmd[] = "NULL"; int main(int argc, char *argv[]) { char buf[16]; fgets(buf, sizeof buf, stdin); for (int i = 0; i < sizeof cmd - 1; ++i) { if (buf[i] != cmd[i]) return 0; } *ptr = 1; return 0; }
Компилируем, запускаем и… тадам!

Пишем свой forkserver
Как я уже говорил, AFL предполагает наличие инструментации, собирающей информацию о переходах между базовыми блоками исследуемой программы. Но есть и ещё одна оптимизация, добавляемая afl-gcc: forkserver. Смысл её в том, чтобы не перезапускать программу с помощью связки fork-execve, каждый раз выполняя динамическую линковку и т. д., а один раз внутри процесса фаззера сделать fork, потом execve в инструментированную программу. Как же мы будем перезапускать исследуемую программу? Смысл в том, что тестировать мы будем не этот запущенный процесс. Вместо этого в нём запускается код, который в бесконечном цикле ждёт команды от фаззера, делает fork, ждёт завершения дочернего процесса и отзванивается о результате. А вот отпочковавшийся процесс уже реально обрабатывает входные данные и собирает информацию о рёберном покрытии. В случае afl-gcc, если я правильно понимаю его логику, forkserver запускается при первом обращении к инструментированному коду. В случае же llvm mode также поддерживается режим deferred forkserver — таким образом можно пропустить не только динамическую линковку, но и стандартную для исследуемого процесса инициализацию, что потенциально может ускорить весь процесс на порядки, но нужно учитывать некоторые нюансы:
- выполнение процесса до запуска forkserver никак не должно зависеть от входных данных
- порождаемые процессы не должны делить общее состояние, например, указатель текущей позиции для открытого на момент запуска forkserver-а файлового дескриптора
- вызов
forkсоздаёт копию процесса, но в этой копии будет только тот поток, который и сделал вызовfork - ...
Также в llvm mode поддерживается persistent mode, в котором несколько тестовых примеров подряд выполняются внутри одного отпочкованного процесса. Наверное, это ещё больше снижает накладные расходы, но при этом есть опасность, что результат выполнения программы на очередном тестовом примере будет зависеть не только от текущего примера, но и от истории запусков. Кстати, уже после начала написания статьи я наткнулся на информацию о том, что порт AFL на Windows тоже использует DynamoRIO для инструментации, и он как раз использует persistent mode. Ну а что ему ещё остаётся без поддержки fork?
Итак, нужно написать свой forkserver на DynamoRIO, но для начала нужно понять требуемый протокол его взаимодействия с процессом фаззера. Что-то можно почерпнуть по указанной выше ссылке на блог автора AFL, но проще найти в каталоге фаззера файл llvm_mode/afl-llvm-rt.o.c. В нём есть много интересного, но для начала посмотрим на функцию __afl_start_forkserver — там всё подробно описывается, даже с комментариями. Persistent mode нас не интересует, в остальном всё довольно понятно: нам дано два файловых дескриптора с известными номерами — из одного читаем, в другой пишем. Нам нужно:
- Цитата из исходника: Phone home and tell the parent that we're OK. Записываем любые 4 байта.
- Читаем 4 байта. Поскольку похоже, что в нашем случае (без persistent mode) мы имеем инвариант
child_stopped == 0, то что именно мы прочитали, значения не имеет. - Отпочковываем дочерний процесс и закрываем в нём файловые дескрипторы для связи с фаззером.
- Пишем 4 байта с PID дочернего процесса в файловый дескриптор и ожидаем его (процесса) завершения.
- Дождавшись, пишем ещё 4 байта с кодом возврата и переходим к пункту 2.
И вот мы, собственно, подошли к написанию своего клиента. Тут нужно сделать лирическое отступление о том, что хотя примеры из документации и занимают всего пару сотен строчек, но документацию почитать всё-таки стоит. Начать можно, например, отсюда, где, в частности, написано о том, чего делать не стоит. Например, перефразировав известного литературного персонажа, можно сказать, что "клиент инструментации — это очень уж странный предмет: вроде он есть, но его как бы нет", что в документации именуется client transparency: в частности, нужно пользоваться своими копиями системных библиотек (в чём поможет private loader), либо пользоваться API DynamoRIO (выделение памяти, разбор опций командной строки и многое другое). Также важная информация есть в документации на функции API: например, в описании функции dr_register_bb_event указан краткий список из 11 пунктов, чему должна удовлетворять получившаяся последовательность инструкций после инструментации.
Для управления сборкой клиентов для DynamoRIO рекомендуется использовать CMake — им мы и воспользуемся. О том, как это сделать, можно прочитать в документации, мы же перейдём к более интересным вопросам. Например, для того, чтобы сделать deferred forkserver, нам нужно как-то пометить место его запуска в исследуемой программе, а потом найти эту пометку в DynamoRIO (впрочем, вроде бы ничто не мешает сделать forkserver просто в виде вызова обычной функции внутри исследуемой программы, но ведь так же не интересно, правда?), К счастью, подобная функциональность встроена в DynamoRIO и называется аннотациями. Разработчик клиента должен собрать специальную статическую библиотеку, которую нужно прилинковать к исследуемой программе, и в требуемом месте вызвать функцию из этой библиотеки, последовательность инструкций в которой не делает ничего интересного при обычном исполнении, но при запуске под DynamoRIO распознаётся им и заменяется на определённую константу или вызов функции.
Не буду повторять официальный учебник, скажу лишь, что предлагается скопировать заголовочный файл из поставки DynamoRIO, переделать в нём "вызов" двух макросов под название и сигнатуру нашей аннотации (этот файл нужно будет подключить в тестируемую программу), а также создать сишный исходник с ещё одним вызовом макроса, который сгенерирует реализацию заглушки для аннотации (из него будет собрана статическая библиотека, которую нужно прилинковать к тестируемой программе).
По поводу реализации forkserver-а всё тоже довольно прямолинейно, за исключением того, что, вероятно, не очень правильно вызывать fork из нашей копии libc: например, автор AFL в указанной выше статье про особенности реализации forkserver говорил о том, что libc кеширует PID. В случае же вызова fork из копии libc исследуемого приложения и оно будет знать про произошедший вызов fork, и DynamoRIO это, хочется верить, тоже заметит. Поэтому пришлось написать что-то вроде
module_data_t *module = dr_lookup_module_by_name("libc.so.6"); EXIT_IF_FAILED(module != NULL, "Cannot lookup libc.\n", 1) fork_fun_t fork_ptr = (fork_fun_t)dr_get_proc_address(module->handle, "fork"); EXIT_IF_FAILED(fork_ptr != NULL, "Cannot get fork function from libc.\n", 1) dr_free_module_data(module);
Поэтому, чтобы поддержать традиционный режим запуска forkserver-а при старте программы, нужно убедиться, что к этому моменту уже доступна libc.
Когда я попытался это протестировать, я столкнулся со странным поведением: тестируемая программа запускалась, а forkserver — нет. Я добавил в dr_client_main печать на консоль — её тоже не появилось. Переключился на сборочный каталог чернового варианта кода. Хм… работает. Сравнил вывод nm -D на рабочей и нерабочей библиотеке инструментации: и там, и там есть функция dr_client_main. Сравнил ещё раз — действительно есть… Указал для drrun опции -verbose -debug. В общем, после некого количества экспериментов выяснилось, что дело было не в библиотеке клиента, и даже не в тестовой программе. Просто для чернового сборочного каталога QtCreator создал путь .../build-afl-dr-Desktop_3fb6e5-Выпуск, а для "рабочего" — .../build-afl-dr-Desktop-По умолчанию. Ну вы поняли, во втором был пробел. Нет, я понимаю, что некоторые программы не работают, когда в пути есть пробелы, но втихаря выкинуть библиотеку инструментации, это, конечно, креативненько… (Да, я отправил баг-репорт.)
Тестируем:
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug Running forkserver... Cannot connect to fuzzer. 1 $ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug 198<&0 199>/dev/null Running forkserver... xxxx 1 Incorrect spawn command from fuzzer.
Ну, более-менее работает. Проверим, как отнесётся к нему AFL. Для этого запустим его в dumb mode (не собирать рёберное покрытие), но попросим его всё-таки использовать forkserver:
$ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -- ./example-bug ... что-то там про Fork server handshake failed -- правильно, инструментации нет ... $ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug ... что-то там про Timeout while initializing fork server (adjusting -t may help) $ # изучаем логи strace-а и... $ AFL_DUMB_FORKSRV=1 $AFL_PATH/afl-fuzz -i input -o output -n -m 2048 -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug ... всё работает, если дать больше памяти (опция -m)

Впрочем, скорость не ахти. Но речь пока о работе на качественном уровне.
И тут обнаружилась проблема: хотя с тестовой программой такой forkserver работает нормально, некоторые программы с ним просто рушатся по SIGSEGV. После некого времени, потраченного на отладку, ответа так и не появилось, однако оказалось, что в качестве обходного пути можно вызывать fork из копии libc, принадлежащей клиенту, а не приложению. Ну что же, это повод познакомиться с extension под названием droption. Чтобы его использовать, нужно всего лишь объявить статическую переменную типа dr_option_t<T>, в параметрах указав имя опции, описание и значение по умолчанию, а в начале dr_client_main вызвать droption_parser_t::parse_argv(...) (да, клиент теперь у нас получается на C++). Внезапно оказалось, что документация на сайте относится к версии 7.0 RC1, а в 6.2.0-2 документация на это расширение отсутствует, и стандартным способом через CMake именно droption почему-то не подключается. Но само расширение есть. Впрочем, нам нужен лишь путь к заголовочным файлам, поэтому просто подключим другое расширение с тем же путём, например, drutil.
В итоге получились следующие реализации:
// Based on dr_annotations.h from DynamoRIO sources #ifndef _AFL_DR_ANNOTATIONS_H_ #define _AFL_DR_ANNOTATIONS_H_ 1 #include "annotations/dr_annotations_asm.h" /* To simplify project configuration, this pragma excludes the file from GCC warnings. */ #ifdef __GNUC__ # pragma GCC system_header #endif #define RUN_FORKSERVER() \ DR_ANNOTATION(run_forkserver) #ifdef __cplusplus extern "C" { #endif DR_DECLARE_ANNOTATION(void, run_forkserver, ()); #ifdef __cplusplus } #endif #endif
#include "afl-annotations.h" DR_DEFINE_ANNOTATION(void, run_forkserver, (), );
#include <dr_api.h> #include <droption.h> #include <stdint.h> #include <unistd.h> #include <sys/wait.h> #include "afl-annotations.h" static const int FROM_FUZZER_FD = 198; static const int TO_FUZZER_FD = 199; typedef int (*fork_fun_t)(); #define EXIT_IF_FAILED(isOk, msg, code) \ if (!(isOk)) { \ dr_fprintf(STDERR, (msg)); \ dr_exit_process((code)); \ } static droption_t<bool> opt_private_fork(DROPTION_SCOPE_CLIENT, "private-fork", false, "Use fork function from the private libc", "Use fork function from the private libc"); static void parse_options(int argc, const char *argv[]) { std::string parse_err; if (!droption_parser_t::parse_argv(DROPTION_SCOPE_CLIENT, argc, argv, &parse_err, NULL)) { dr_fprintf(STDERR, "Incorrect client options: %s\n", parse_err.c_str()); dr_exit_process(1); } } static void start_forkserver() { // For references, see https://lcamtuf.blogspot.ru/2014/10/fuzzing-binaries-without-execve.html // and __afl_start_forkserver in llvm_mode/afl-llvm-rt.o.c from AFL sources static bool forkserver_is_running = false; uint32_t unused_four_bytes = 0; uint32_t was_killed; if (!forkserver_is_running) { dr_printf("Running forkserver...\n"); forkserver_is_running = true; } else { dr_printf("Warning: Attempt to re-run forkserver ignored.\n"); return; } if (write(TO_FUZZER_FD, &unused_four_bytes, 4) != 4) { dr_printf("Cannot connect to fuzzer.\n"); return; } fork_fun_t fork_ptr; // Lookup the fork function from target application, so both DynamoRIO // and application's copy of libc know about fork // Currently causes crashes sometimes, in that case use the private libc's fork. if (!opt_private_fork.get_value()) { module_data_t *module = dr_lookup_module_by_name("libc.so.6"); EXIT_IF_FAILED(module != NULL, "Cannot lookup libc.\n", 1) fork_ptr = (fork_fun_t)dr_get_proc_address(module->handle, "fork"); EXIT_IF_FAILED(fork_ptr != NULL, "Cannot get fork function from libc.\n", 1) dr_free_module_data(module); } else { fork_ptr = fork; } while (true) { EXIT_IF_FAILED(read(FROM_FUZZER_FD, &was_killed, 4) == 4, "Incorrect spawn command from fuzzer.\n", 1) int child_pid = fork_ptr(); EXIT_IF_FAILED(child_pid >= 0, "Cannot fork.\n", 1) if (child_pid == 0) { close(TO_FUZZER_FD); close(FROM_FUZZER_FD); return; } else { int status; EXIT_IF_FAILED(write(TO_FUZZER_FD, &child_pid, 4) == 4, "Cannot write child PID.\n", 1) EXIT_IF_FAILED(waitpid(child_pid, &status, 0) >= 0, "Wait for child failed.\n", 1) EXIT_IF_FAILED(write(TO_FUZZER_FD, &status, 4) == 4, "Cannot write child exit status.\n", 1) } } } DR_EXPORT void dr_client_main(client_id_t id, int argc, const char *argv[]) { parse_options(argc, argv); EXIT_IF_FAILED( dr_annotation_register_call("run_forkserver", (void *)start_forkserver, false, 0, DR_ANNOTATION_CALL_TYPE_FASTCALL), "Cannot register forkserver annotation.\n", 1); }
Собираем рёберное покрытие
И вот, наконец, настало время приступить к полноценному перекорёживанию машинного кода. Как и в прошлый раз, не будем изобретать велосипед, а посмотрим в исходниках AFL, как делается существующая инструментация. А именно, изменения вносимые afl-gcc описаны в afl-as.c, а сам вписываемый ассемблерный код находится в виде строковых литералов в afl-as.h. Подробности работы AFL и, в частности, используемая инструментация, описаны в официальном документе technical details. По сути, в места ветвления программы вписывается код эквивалентный
cur_location = <COMPILE_TIME_RANDOM>; shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1;
(псевдокод нагло позаимствован из документации AFL). Каждая локация помечается случайным идентификатором, а ребру в графе переходов соответствует байт в карте с номером, состоящим из поксоренных идентификаторов текущей и предыдущей локации, причём один из идентификаторов сдвигается на 1 — это позволяет сделать рёбра ориентированными. Для взаимодействия с процессом фаззера программе через переменную окружения передаётся ссылка на 64-килобайтную карту в shared memory, пример работы с которой можно посмотреть всё в том же файле llvm_mode/afl-llvm-rt.o.c.
О том, как это всё реализовать с помощью DynamoRIO, есть ещё один официальный учебник. Суть в том, что при наступлении некоторых событий (таких как трансляция очередного базового блока или, например, запуск / остановка потока) DynamoRIO вызывает зарегистрированные обработчики. Поскольку мы хотим дописывать машинный код в каждый базовый блок, то нам потребуется зарегистрировать свой обработчик с помощью функции dr_register_bb_event. Также, последуем совету из туториала, и вместо атомарных операций инкремента будем использовать thread-local карты, а по завершении потока всё суммировать, поэтому нам также понадобится подписаться на создание и завершение потоков и создать мьютекс для синхронизации обращения к глобальной карте. Наконец, по-хорошему, мьютекс надо бы удалить в конце работы, поэтому подпишемся ещё и на завершение работы программы:
// Внутри dr_client_main: lock = dr_mutex_create(); dr_register_thread_init_event(event_thread_init); dr_register_thread_exit_event(event_thread_exit); dr_register_bb_event(event_basic_block); dr_register_exit_event(event_exit);
Обработчики создания и удаления потоков довольно бесхитростны:
typedef struct { uint64_t scratch; uint8_t map[MAP_SIZE]; } thread_data; static void event_thread_init(void *drcontext) { void *data = dr_thread_alloc(drcontext, sizeof(thread_data)); memset(data, 0, sizeof(thread_data)); dr_set_tls_field(drcontext, data); } static void event_thread_exit(void *drcontext) { thread_data *data = (thread_data *) dr_get_tls_field(drcontext); dr_mutex_lock(lock); for (int i = 0; i < MAP_SIZE; ++i) { shmem[i] += data->map[i]; } dr_mutex_unlock(lock); dr_thread_free(drcontext, data, sizeof(thread_data)); }
… а удаление мьютекса я даже приводить не буду. Из интересного в этом коде стоит обратить внимание, во-первых, на то, что DynamoRIO имеет собственные функции и для выделения памяти, и для примитивов синхронизации, причём есть вариант аллокатора с thread-specific memory pool. Во-вторых, здесь мы видим создание глобальных-на-уровне-потока структур thread_data, чей адрес мы заносим в tls field.
И вот, мы подошли к сути происходящего: функции event_basic_block(void *drcontext, void *tag, instrlist_t *bb, bool for_trace, bool translating), которая и занимается переписыванием машинного кода. Как я и обещал, нам не придётся ворочать шестнадцатиричные коды инструкций и высчитывать байты — инструкции придут к нам уже в декодированном виде в параметре instrlist_t *bb. Есть даже несколько макросов для кроссплатформенной (в плане архитектуры процессора) генерации наиболее типичных инструкций, но, увы, нам всё же придётся разбираться с ассемблером amd64 aka x86_64. Читать документацию по используемым функциям DynamoRIO вообще полезно, а в случае с dr_register_bb_event это полезно вдвойне. Например, вот что понимается под basic block:
DR constructs dynamic basic blocks, which are distinct from a compiler's classic basic blocks. DR does not know all entry points ahead of time, and will end up duplicating the tail of a basic block if a later entry point is discovered that targets the middle of a block created earlier, or if a later entry point targets straight-line code that falls through into code already present in a block.
Также, там имеется список ограничений на результирующий машинный код, который может получаться после инструментации — при написании своих клиентов обязательно почитайте!
Для работы нашей инструментации нам понадобится два регистра. Также мы будем выполнять арифметические операции, целую одну штуку, поэтому нужно сохранить флаги вроде признака переполнения:
static dr_emit_flags_t event_basic_block(void *drcontext, void *tag, instrlist_t *bb, bool for_trace, bool translating) { instr_t *where = instrlist_first(bb); reg_id_t tls_reg = DR_REG_XDI, offset_reg = DR_REG_XDX; dr_save_arith_flags(drcontext, bb, where, SPILL_SLOT_1); dr_save_reg(drcontext, bb, where, tls_reg, SPILL_SLOT_2); dr_save_reg(drcontext, bb, where, offset_reg, SPILL_SLOT_3); dr_insert_read_tls_field(drcontext, bb, where, tls_reg); // здесь будет дописываться инструментация dr_restore_reg(drcontext, bb, where, offset_reg, SPILL_SLOT_3); dr_restore_reg(drcontext, bb, where, tls_reg, SPILL_SLOT_2); dr_restore_arith_flags(drcontext, bb, where, SPILL_SLOT_1); return DR_EMIT_DEFAULT; }
В tls_reg тут же положим адрес нашей структуры с временной картой для текущего потока. Также в приведённом выше псевдокоде из документации фигурирует COMPILE_TIME_RANDOM. Проблема с использованием случайных идентификаторов в том, что наш event_basic_block может вызываться несколько раз: обратите внимание на аргументы for_trace и translating. Дело в том, что, кроме трансляции отдельных блоков, наиболее часто встречающиеся цепочки блоков DynamoRIO собирает в трейсы. Перед тем, как добавить блок в трейс, ещё раз вызываются зарегистрированные обработчики трансляции базового блока, но уже с for_trace = true, в которых можно сгенерировать специальную инструментацию для помещения блока в трейс. Также иногда возникает необходимость понять, какому реальному адресу кода соответствует кешированный, на котором произошло некое событие, тогда наш обработчик вызывается с translating = true — тут уже, конечно, нужно повторить ровно те же преобразования, как с translating = false. Впрочем, можно вернуть из обработчика DR_EMIT_STORE_TRANSLATIONS вместо DR_EMIT_DEFAULT, и адреса будут запомнены за нас, но на это потребуются дополнительные ресурсы. Даже, если бы никаких повторных вызовов не предполагалось бы by design, всё равно пришлось бы хитро координировать наши случайные метки с учётом того, что часть будет создана уже после форка процесса. Поэтому просто будем давать идентификатор как функцию от адреса кода, где лежит basic block.
void *app_pc = dr_fragment_app_pc(tag); uint32_t cur_location = ((uint32_t)(uintptr_t)app_pc * (uint32_t)33533) & 0xFFFF;
Если уже после форка будут загружены дополнительные динамические библиотеки, то ASLR испортит нам планы, но будем считать это редким случаем. Кстати, "если припрёт", рандомизацию можно временно отключить для всей системы с помощью sysctl -w kernel.randomize_va_space=0.
Наконец, сам сбор рёберного покрытия. Нам нужно добавить четыре инструкции. Для этого в API имеются удобные функции и макросы для создания инструкций, операндов разных видов и т. д.:
instrlist_meta_preinsert(bb, where, XINST_CREATE_load(drcontext, opnd_create_reg(offset_reg), OPND_CREATE_MEM64(tls_reg, offsetof(thread_data, scratch)))); instrlist_meta_preinsert(bb, where, INSTR_CREATE_xor(drcontext, opnd_create_reg(offset_reg), OPND_CREATE_INT32(cur_location))); instrlist_meta_preinsert(bb, where, XINST_CREATE_store(drcontext, OPND_CREATE_MEM32(tls_reg, offsetof(thread_data, scratch)), OPND_CREATE_INT32(cur_location >> 1))); instrlist_meta_preinsert(bb, where, INSTR_CREATE_inc(drcontext, opnd_create_base_disp(tls_reg, offset_reg, 1, offsetof(thread_data, map), OPSZ_1)));
Кстати, если вы ошибётесь с инструкциями, то вместо подробного сообщения о том, что ай-ай-ай такие операнды задавать этой инструкции, вы получите просто Segmentation fault. Например, заменим в первой инстукции XINST_CREATE_load на XINST_CREATE_store и запустим:
$ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so --private-fork -- ./example-bug Cannot get SHM id from environment. Creating dummy map. Running forkserver... Cannot connect to fuzzer. ^C $ # Поменяли load на store $ ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so --private-fork -- ./example-bug Cannot get SHM id from environment. Creating dummy map. <Application /path/to/example-bug (5058). Tool internal crash at PC 0x00005605e72bbeaa. Please report this at your tool's issue tracker. Program aborted. Received SIGSEGV at pc 0x00005605e72bbeaa in thread 5058 Base: 0x00005605e71c5000 Registers:eax=0x0000000000000001 ebx=0x00007ff6dfa12038 ecx=0x0000000000000048 edx=0x0000000000000000 esi=0x0000000000000049 edi=0x0000000000000005 esp=0x00007ff6dfa0ebb0 ebp=0x00007ff6dfa0ebc0 r8 =0x0000000000000003 r9 =0x0000000000000005 r10=0x0000000000000000 r11=0x00005605e72b70ef r12=0x0000000000000000 r13=0x0000000000000000 r14=0x000000000000000c r15=0x00005605e7368c50 eflags=0x0000000000010202 version 6.2.0, build 2 -no_dynamic_options -client_lib '/path/to/libafl-dr.so;0;"--private-fork"' -code_api -stack_size 56K -max_elide_jmp 0 -max_elide_call 0 -early_inject -emulate_brk -no_inline_ignored_syscalls -native_exec_default_list '' -no_native_exec_managed_code -no_indcall2direct 0x00007ff6dfa0ebc0 0x0000020803000000>
Что делать? Можно по одной комментировать инструкции, пока не перестанет падать. Можно задать опции командной строки вроде -debug -loglevel 1 -logdir /tmp/dynamorio/ и тогда вместо невразумительного падения на консоль будет написано о невозможности закодировать инструкцию, а в логе будет что-то вроде:
ERROR: Could not find encoding for: mov (%rdi)[8byte] -> %rdx SYSLOG_ERROR: Application /path/to/example-bug (5192) DynamoRIO usage error : instr_encode error: no encoding found (see log) SYSLOG_ERROR: Usage error: instr_encode error: no encoding found (see log) (/dynamorio_package/core/arch/x86/encode.c, line 2417)
Пожалуй, оба способа имеют право на жизнь: второй позволяет понять что не понравилось, а первый — где оно происходит.
Что же, инструментация готова, можно запускать:
$ $AFL_PATH/afl-fuzz -i input -o output -m 2048 -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug afl-fuzz 2.42b by <lcamtuf@google.com> [+] You have 4 CPU cores and 1 runnable tasks (utilization: 25%). [+] Try parallel jobs - see docs/parallel_fuzzing.txt. [*] Checking CPU core loadout... [+] Found a free CPU core, binding to #0. [*] Checking core_pattern... [*] Checking CPU scaling governor... [*] Setting up output directories... [+] Output directory exists but deemed OK to reuse. [*] Deleting old session data... [+] Output dir cleanup successful. [*] Scanning 'input'... [+] No auto-generated dictionary tokens to reuse. [*] Creating hard links for all input files... [*] Validating target binary... [-] Looks like the target binary is not instrumented! The fuzzer depends on compile-time instrumentation to isolate interesting test cases while mutating the input data. For more information, and for tips on how to instrument binaries, please see docs/README. When source code is not available, you may be able to leverage QEMU mode support. Consult the README for tips on how to enable this. (It is also possible to use afl-fuzz as a traditional, "dumb" fuzzer. For that, you can use the -n option - but expect much worse results.) [-] PROGRAM ABORT : No instrumentation detected Location : check_binary(), afl-fuzz.c:6894
Но… У нас же есть инструментация… Неужели она не работает? На самом деле ситуация ещё смешнее: если посмотреть на лог strace для этой команды, то мы увидим, что drrun даже не запускался. И что же это за телепатия, как afl-fuzz видит отсутствие инструментации, даже не запуская программу? Помните, я говорил о том, что AFL — это подборка железобетонных эвристик? Так вот, идём куда послали, ну, в смысле, в afl-fuzz.c:6894, и видим:
f_data = mmap(0, f_len, PROT_READ, MAP_PRIVATE, fd, 0); // ... if (!qemu_mode && !dumb_mode && !memmem(f_data, f_len, SHM_ENV_VAR, strlen(SHM_ENV_VAR) + 1)) { // ... FATAL("No instrumentation detected"); }
Да-да, именно так: AFL ищет в бинарнике строчку __AFL_SHM_ID — имя переменной окружения, через которую инструментированная программа получает идентификатор общей памяти. Теперь-то всё ясно, echo -ne "__AFL_SHM_ID\0" >> /path/to/drrunAFL_SKIP_BIN_CHECK и отключить проверку:
$ # Опция -d заставляет пропустить детерминированные шаги фаззинга $ AFL_SKIP_BIN_CHECK=1 $AFL_PATH/afl-fuzz -i input -o output -m 2048 -d -- ~/soft/DynamoRIO-Linux-6.2.0-2/bin64/drrun -c libafl-dr.so -- ./example-bug

Ура, AFL признал нашу инструментацию, но что это, Бэрримор, total paths: 12, а раньше было только 4-5. Точно сказать сложно, но подозреваю, что это овсяlibc. Ведь теперь инструментации подвергается не только наш код из example-bug, но и всё, что исполняется в процессе (ну, кроме DynamoRIO, конечно). Да и скорость не ахти… Поэтому самое время начать делать
Оптимизации
… и первой будет выбор, какие модули процесса мы хотим инструментировать. Точнее, пока просто будем ограничивать инструментацию главным модулем программы, и сделаем опцию "сделать как раньше". Для этого я заведу глобальную переменную типа module_data_t *, в dr_client_main проинициализирую её информацией о главном модуле программы, а в event_basic_block буду сразу прерывать обработку, если код "не наш":
module_data_t *main_module; // В dr_client_main: main_module = dr_get_main_module(); // В event_basic_block: if (!opt_instrument_everything.get_value() && !dr_module_contains_addr(main_module, pc)) { return DR_EMIT_DEFAULT; }
Для тестового примера это увеличило скорость фаззинга до 80 запусков в секунду (приблизительно в 2 раза), а в output/queue строка test за пару минут уже превратилась в NU — медленно, но как будто бы работает.
Далее, у DynamoRIO есть опция -thread_private, при указании которой он будет использовать отдельные кеши кода для каждого потока. В этом случае значение из tls field фактически становится константой, поэтому, хотя выкинуть использование регистра у меня не получилось, но инициализировать его можно immediate-константой:
if (dr_using_all_private_caches()) { instrlist_meta_preinsert(bb, where, INSTR_CREATE_mov_imm(drcontext, opnd_create_reg(tls_reg), OPND_CREATE_INTPTR(dr_get_tls_field(drcontext)))); } else { dr_insert_read_tls_field(drcontext, bb, where, tls_reg); }
Запускаем с опцией -thread_private (но эта опция должна идти до -c libafl-dr.so, поскольку она принадлежит самому DynamoRIO, а не нашему клиенту), и получаем приблизительно на 5 запусков в секунду больше. Впрочем, даже если написать if (0 && dr_using_all_private_caches()), то результат идентичный — видимо, DynamoRIO просто эффективнее работает в таком режиме. :)
В принципе, мы можем указать ещё одну опцию командной строки: -disable_traces — она отключает создание трейсов, что, вероятно, негативно скажется на производительности долго живущих программ, но, как сказано в документации, может благотворно сказаться на скорости больших короткоживущих приложений. Попробуем… и получаем ещё плюс 10-15 запусков в секунду. Но, повторюсь, с этой опцией нужно экспериментировать, возможно, даже, уже после появления в очереди интересных test case-ов.
Напоследок скажу, что ещё чуть улучшить производительность можно, если "прогреть" тестируемую программу перед запуском forkserver-а: добавим в example-bug.c код
ungetc('1', stdin); char ch; fscanf(stdin, "%c", &ch); RUN_FORKSERVER();
… и получим ещё плюс 15 запусков в секунду. Впрочем, сложно с ходу сказать, в чём конкретно дело: возможно, за счёт этого кода какая-то затратная инициализация в libc произошла до запуска forkserver, а возможно, просто был транслирован какой-то ощутимый кусок кода.
За сим разрешите откланяться. В этом небольшом проекте ещё есть над чем подумать:
- можно не тратиться на инструментацию безусловных переходов, как это и сделано в
afl-as - можно попытаться научиться пересоздавать запущенные потоки после форка (такой функциональности в текущих реализациях, вроде бы, нет)
- можно по аналогии с патчем для QEMU отправлять в сторону forkserver информацию о транслированных адресах, чтобы он их также транслировал у себя и последующие его потомки уже не тратили на это время (но, видимо, в лучшем случае придётся допиливать DynamoRIO. Хотя, надо отдать должное гитхабовским телепатам: не успел я отправить feature request, полез смотреть существующие issues, а они это уже две недели назад закоммитили...)
… но это уже совсем другая история. И помните, все врут: не стоит на вопрос "А правда ли эту функцию API / ассемблерную инструкцию можно так использовать?" отвечать, "Да, конечно, я так вон в той статье видел!" — сложно сказать, сколько разнокалиберных неожиданностей ещё предстоит вычистить из этого небольшого кода. Впрочем, надеюсь, вы убедились, что написание несложной, но полезной динамической инструментации — задача намного более выполнимая, чем кажется на первый взгляд.
Ссылки:
- Этот проект на Github.
- WinAFL — ещё одна реализация подобного на DynamoRIO (для Windows).
- Ещё размышления и эксперименты по поводу неофициальных реализаций инструментации: раз, два.
- Dynamic Binary Instrumentation в ИБ — статья 2012 года про другую систему динамической инструментации, PIN
UPD: Реализовал трансляцию в родительском процессе базовых блоков, исполненных в дочерних процессах (как это сделано в qemu_mode). Пришлось использовать API слегка не по назначению, но скорость на примитивной тестовой программе из статьи поднялась раз в 5. Вот теперь, пожалуй, пора оптимизировать генерируемую инструментацию.
