IDN spoofing — это генерация доменных имён «похожих» на выбранное, обычно применяемая с целью заставить пользователя перейти по ссылке на ресурс злоумышленника. Далее рассмотрим более конкретный вариант атаки.
Представим, что атакуемая компания владеет доменом organization.org, и внутри этой компании используется внутренний ресурс portal.organization.org. Цель злоумышленника -получить учётные данные пользователя, и для этого он присылает ссылку через e-mail или используемый в компании мессенджер.
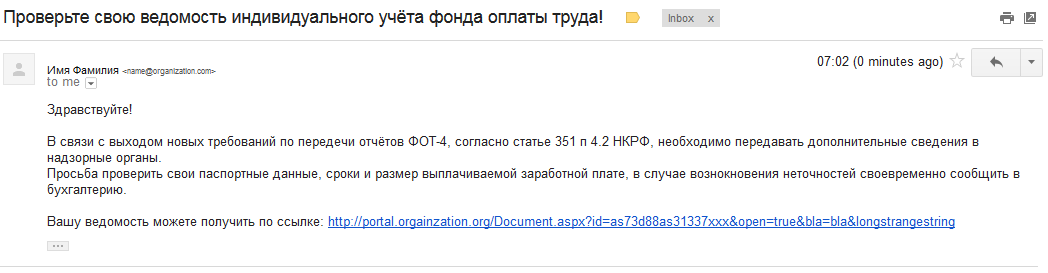
Получив подобное сообщение с большой вероятностью можно не заметить, что ссылка ведёт куда-то не туда. После перехода по ссылке будет запрошен логин\пароль, и жертва, думая, что находится на внутреннем ресурсе, введёт данные своей учётной записи. Шансы злоумышленника особенно высоки, если он уже проник за периметр, скомпрометировав систему любого сотрудника, и теперь борется за привилегии системного администратора.
Абсолютной «защиты от дурака» тут придумать не получится, но можно пробовать перехватить эту атаку на этапе разрешения имени через dns-запрос.
Для защиты нам понадобится последовательно запоминать встречаемые имена в перехваченных dns-запросах. В компании пользуются её внутренними ресурсами, значит мы достаточно быстро обнаружим в запрос на portal.organization.org. Как только мы встретили имя «похожее» на ранее встречавшееся, мы может подменить dns-ответ, вернув ошибку вместо ip-адреса атакующего.
Какие могут быть алгоритмы определения «похожести»?
Вероятнее всего корпоративным сервером будет не bind, который стандарт скорее для web-хостеров или провайдеров, а microsoft dns server из-за повсеместного использования active directory. И первая проблема, с которой я столкнулся при написании фильтра к microsoft dns server – API для фильтрации dns-запросов я не нашёл. Эту проблему можно решать разными способами, я выбрал инжект dll и IAT хук на api работы с сокетами.
Для понимания методики будет необходимо знание PE-формата, подробнее можно прочитать, например, здесь. Исполняемый файл состоит из заголовков, таблицы секций и самих секций. Сами секции – это блок данных, который загрузчик должен отобразить в память по относительному адресу (Relative Virtual Address – RVA), и все ресурсы, код, прочие данные содержатся внутри секций. Также внутри заголовка присутствуют ссылки (RVA) на ряд необходимых для работы приложения таблиц, в рамках этой статьи будут важны две –таблица импорта и таблица экспорта. Таблица импорта содержит список функций, которые необходимы для работы приложения, но находятся в других файлах. Таблица экспорта – это «обратная» таблица, в которой содержится список функций, которые экспортируются из этого файла, либо, в случае export forwarding, указывается имя файла и имя функции для разрешения зависимости.
Инжект dll будем делать без всем надоевшего CreateRemoteThread. Я решил использовать PE export forwarding – это давно известный приём, когда для того, чтобы загрузится в нужный процесс, в каталоге с exe-файлом создаётся dll с именем равным имени любой dll из таблицы импорта exe-файла (главное не использовать HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Session Manager\KnownDLLs ). В созданной dll копируется таблица экспорта из целевой dll, но вместо указателя на код экспортируемой функции, нужно записать RVA на forward-строку вида «endpoint!sendto». Сам microsoft dns server реализован в виде сервиса HKEY_LOCAL_MACHINE\System\CurrentControlSet\services\DNS, который находится в %systemroot%\system32\dns.exe
Итоговый алгоритм инжекта в dns сервер будет таким:
А зачем последний шаг? Дело в том, что в windows есть встроенный firewall, и, по умолчанию, в windows server право слушать 53 порт есть только у приложения %systemroot%\system32\dns.exe. При попытке запустить его из другого каталога прав на доступ к сети не будет. А зачем я его вообще копировал? Для того, чтобы минимизировать воздействие на всю систему и не трогать оригинальный dnsapi.dll. Получается, что если уметь создавать symlink на приложение, то можно получать его сетевые права. По умолчанию, права на создание symlink есть только у администраторов, но достаточно неожиданно обнаружить, что выдав пользователю право на создание symlink, ты даёшь ему возможность обходить встроенный firewall.
После того как загрузились внутрь процесса из DllMain, можно будет создать поток и установить перехват. В самом простом случае наш dns сервис будет сообщать клиенту ip-адрес для имени через отправку UDP-пакета с 53 порта через фукнцию sendto из ws2_32.dll. Стандарт предполагает возможность использования 53 TCP-порта, если ответ слишком большой, и очевидно, что перехват sendto в этом случае будет бесполезен. Однако, обработать случай с tcp хоть и более трудоёмко, но можно аналогичным способом. Пока расскажу самый простой случай с UDP. Итак, мы знаем, что код из dns.exe импортирует из ws2_32.dll функцию sendto и будет использовать её, чтобы ответить на dns-запрос. Для перехвата функций тоже достаточно много разных способов, классический это сплайсинг, когда первые инструкции sendto заменяются на jmp в свою функцию, а после её завершения осуществляется переход на сохранённые ранее инструкции sendto и далее внутрь функции sendto. Сплайсинг будет работать даже если для вызова sendto будет использован GetProcAddress, а не таблица импорта, но если используется таблица импорта, то вместо сплайсинга проще использовать IAT-хук. Для этого нужно найти в загруженном образе dns.exe таблицу импорта. Сама таблица имеет несколько запутанную структуру и за деталями придётся ходить в описание PE формата.
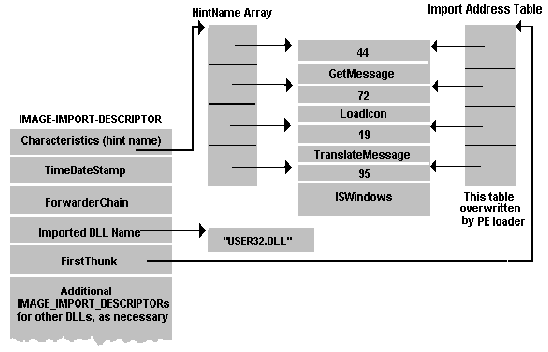
Главное — что система в процессе загрузки образа запишет в таблицу импорта указатель на начало функции sendto. Это значит, что для того, чтобы перехватить вызов sendto, надо просто заменить в таблице импорта адрес оригинальной sendto на адрес своей функции.
Итак, мы установили перехват и начали получать данные. Прототип функции sendto выглядит так:
Если s – это сокет на 53 порту, то по указателю buf будет лежать dns-ответ размером len. Сам формат описан в RFC1035, я кратко опишу, что нужно сделать, чтобы добраться до интересующих данных.
Структура сообщения в стандарте описана так:

В заголовке из нужной информации: тип сообщения, код ошибки и количество элементов в секциях. Сам заголовок выглядит так:
Секцию Question придётся разобрать для того, чтобы добраться до Answer. Сама секция состоит из такого количества блоков, которое указано в заголовке (q_count). Каждый блок состоит из имени, типа и класса запроса. Имя закодировано в виде последовательности строк, каждая из которых начинается с байта с длиной строки. В конце находится строка нулевой длины. Например, имя homedomain2008.ru будет выглядеть так:
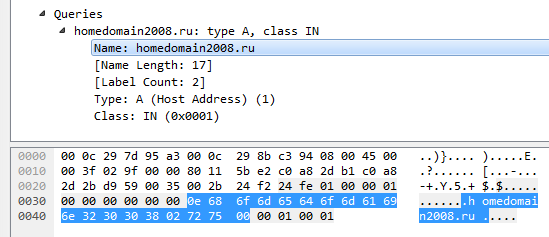
Секция Answers выглядит похожим образом: блок состоит из имени, типа, класса, ttl и дополнительных данных. IP-адрес будет содержатся в доп. данных. С разбором имени возникает ещё одна сложность. Видимо, для уменьшения размера сообщения, вместо длины метки, можно встретить ссылку на другую область данных. Закодирована она так: если 2 старших бита длины равны 11, то следующий байт, а также младшие биты длины, следует интерпретировать как смещение в байтах относительно начала сообщения. Дальнейший разбор имени нужно совершать, перейдя по этому смещению.
Итак, мы перехватили нужное API, разобрали dns-ответ, теперь нужно принять решение: пропускать дальше этот ответ или вернуть ошибку. Для каждого имени, которое ещё не присутствует в базе, из ответа нужно проверить, является ли оно «подозрительным» или нет.
Будем считать «подозрительным» такие имена, для которых результат функции skeleton из Unicode Technical Standard tr39 совпадает с результатом от любого из имён из базы, или те имена, которые отличаются от присутствующих в базе перестановкой внутренних букв. Для реализации проверок будем хранить 2 таблицы. Первая будет состоять из результатов skeleton для всех имён из базы, во вторую таблицу запишем строки, которые были получены из строк базы путём удаления первого и последнего символа из каждой метки кроме первого уровня, а затем сортировки оставшихся символов каждой метки. Теперь, если новое имя входит в одну из двух таблиц, то считаем его подозрительным.
Смысл функции skeleton в определении похожести двух строк, для этого для каждой строки производится нормализация символов. Например, Xlœ будет преобразовано в Xloe, и таким образом, сравнивая результат функции, можно определить похожесть unicode-строк.
С примером реализации описанного выше можно ознакомится на github.
Очевидно, что изложенное решение на практике предоставить нормальную защиту не может, т. к. помимо мелких технических проблем с перехватом, есть ещё большая проблема с детектированием «похожих» имён. Было бы неплохо обработать:
Представим, что атакуемая компания владеет доменом organization.org, и внутри этой компании используется внутренний ресурс portal.organization.org. Цель злоумышленника -получить учётные данные пользователя, и для этого он присылает ссылку через e-mail или используемый в компании мессенджер.

Получив подобное сообщение с большой вероятностью можно не заметить, что ссылка ведёт куда-то не туда. После перехода по ссылке будет запрошен логин\пароль, и жертва, думая, что находится на внутреннем ресурсе, введёт данные своей учётной записи. Шансы злоумышленника особенно высоки, если он уже проник за периметр, скомпрометировав систему любого сотрудника, и теперь борется за привилегии системного администратора.
Абсолютной «защиты от дурака» тут придумать не получится, но можно пробовать перехватить эту атаку на этапе разрешения имени через dns-запрос.
Для защиты нам понадобится последовательно запоминать встречаемые имена в перехваченных dns-запросах. В компании пользуются её внутренними ресурсами, значит мы достаточно быстро обнаружим в запрос на portal.organization.org. Как только мы встретили имя «похожее» на ранее встречавшееся, мы может подменить dns-ответ, вернув ошибку вместо ip-адреса атакующего.
Какие могут быть алгоритмы определения «похожести»?
- UTS39 Confusable Detection (http://www.unicode.org/reports/tr39/#Confusable_Detection) Юникод — это не только
ценный мехтаблица символов, но ещё и куча стандартов и рекомендаций. В UTS39 определен алгоритм нормализации unicode строки, при котором строки, отличающиеся омоглифами (например русская „а“и латинская „a“) будут приведены к одинаковой форме - Слова отличающиеся перестановками внутренних букв. Довольно легко спутать organization.org и orgainzation.org
- Замена домена первого уровня. Первый уровень имени обычно не несёт никакого смысла и сотрудник компании увидев «organization» может проигнорировать разницу в .org или .net, хотя тут возможны исключения
Вероятнее всего корпоративным сервером будет не bind, который стандарт скорее для web-хостеров или провайдеров, а microsoft dns server из-за повсеместного использования active directory. И первая проблема, с которой я столкнулся при написании фильтра к microsoft dns server – API для фильтрации dns-запросов я не нашёл. Эту проблему можно решать разными способами, я выбрал инжект dll и IAT хук на api работы с сокетами.
Для понимания методики будет необходимо знание PE-формата, подробнее можно прочитать, например, здесь. Исполняемый файл состоит из заголовков, таблицы секций и самих секций. Сами секции – это блок данных, который загрузчик должен отобразить в память по относительному адресу (Relative Virtual Address – RVA), и все ресурсы, код, прочие данные содержатся внутри секций. Также внутри заголовка присутствуют ссылки (RVA) на ряд необходимых для работы приложения таблиц, в рамках этой статьи будут важны две –таблица импорта и таблица экспорта. Таблица импорта содержит список функций, которые необходимы для работы приложения, но находятся в других файлах. Таблица экспорта – это «обратная» таблица, в которой содержится список функций, которые экспортируются из этого файла, либо, в случае export forwarding, указывается имя файла и имя функции для разрешения зависимости.
Инжект dll будем делать без всем надоевшего CreateRemoteThread. Я решил использовать PE export forwarding – это давно известный приём, когда для того, чтобы загрузится в нужный процесс, в каталоге с exe-файлом создаётся dll с именем равным имени любой dll из таблицы импорта exe-файла (главное не использовать HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Session Manager\KnownDLLs ). В созданной dll копируется таблица экспорта из целевой dll, но вместо указателя на код экспортируемой функции, нужно записать RVA на forward-строку вида «endpoint!sendto». Сам microsoft dns server реализован в виде сервиса HKEY_LOCAL_MACHINE\System\CurrentControlSet\services\DNS, который находится в %systemroot%\system32\dns.exe
Итоговый алгоритм инжекта в dns сервер будет таким:
- Создаём каталог %systemroot%\system32\dnsflt (можно любой другой, нахождения каталога именно в system32 необязательно).
- Копируем туда %systemroot%\system32\dnsapi.dll – это dll из которой dns.exe что-то импортирует, можно выбрать любую другую “не knowndll”.
- Переименовываем скопированную dll в endpoint.dll — это имя будем использовать в forward-строке.
- Берём нашу инжектируемую dll и дописываем в неё правильную таблицу экспорта, копируем нашу dll в %systemroot%\system32\dnsflt
- В реестре в ключе HKEY_LOCAL_MACHINE\System\CurrentControlSet\services\DNS меняем в ImagePath новый адрес бинарника %systemroot%\system32\dnsflt\dns.exe
- Создаём симлинк из %systemroot%\system32\dnsflt\dns.exe в %systemroot%\system32\dns.exe
А зачем последний шаг? Дело в том, что в windows есть встроенный firewall, и, по умолчанию, в windows server право слушать 53 порт есть только у приложения %systemroot%\system32\dns.exe. При попытке запустить его из другого каталога прав на доступ к сети не будет. А зачем я его вообще копировал? Для того, чтобы минимизировать воздействие на всю систему и не трогать оригинальный dnsapi.dll. Получается, что если уметь создавать symlink на приложение, то можно получать его сетевые права. По умолчанию, права на создание symlink есть только у администраторов, но достаточно неожиданно обнаружить, что выдав пользователю право на создание symlink, ты даёшь ему возможность обходить встроенный firewall.
После того как загрузились внутрь процесса из DllMain, можно будет создать поток и установить перехват. В самом простом случае наш dns сервис будет сообщать клиенту ip-адрес для имени через отправку UDP-пакета с 53 порта через фукнцию sendto из ws2_32.dll. Стандарт предполагает возможность использования 53 TCP-порта, если ответ слишком большой, и очевидно, что перехват sendto в этом случае будет бесполезен. Однако, обработать случай с tcp хоть и более трудоёмко, но можно аналогичным способом. Пока расскажу самый простой случай с UDP. Итак, мы знаем, что код из dns.exe импортирует из ws2_32.dll функцию sendto и будет использовать её, чтобы ответить на dns-запрос. Для перехвата функций тоже достаточно много разных способов, классический это сплайсинг, когда первые инструкции sendto заменяются на jmp в свою функцию, а после её завершения осуществляется переход на сохранённые ранее инструкции sendto и далее внутрь функции sendto. Сплайсинг будет работать даже если для вызова sendto будет использован GetProcAddress, а не таблица импорта, но если используется таблица импорта, то вместо сплайсинга проще использовать IAT-хук. Для этого нужно найти в загруженном образе dns.exe таблицу импорта. Сама таблица имеет несколько запутанную структуру и за деталями придётся ходить в описание PE формата.
Главное — что система в процессе загрузки образа запишет в таблицу импорта указатель на начало функции sendto. Это значит, что для того, чтобы перехватить вызов sendto, надо просто заменить в таблице импорта адрес оригинальной sendto на адрес своей функции.
Итак, мы установили перехват и начали получать данные. Прототип функции sendto выглядит так:
int sendto(
_In_ SOCKET s,
_In_ const char *buf,
_In_ int len,
_In_ int flags,
_In_ const struct sockaddr *to,
_In_ int tolen
);Если s – это сокет на 53 порту, то по указателю buf будет лежать dns-ответ размером len. Сам формат описан в RFC1035, я кратко опишу, что нужно сделать, чтобы добраться до интересующих данных.
Структура сообщения в стандарте описана так:

В заголовке из нужной информации: тип сообщения, код ошибки и количество элементов в секциях. Сам заголовок выглядит так:
struct DNS_HEADER
{
uint16_t id; // identification number
uint8_t rd : 1; // recursion desired
uint8_t tc : 1; // truncated message
uint8_t aa : 1; // authoritive answer
uint8_t opcode : 4; // purpose of message
uint8_t qr : 1; // query/response flag
uint8_t rcode : 4; // response code
uint8_t cd : 1; // checking disabled
uint8_t ad : 1; // authenticated data
uint8_t z : 1; // its z! reserved
uint8_t ra : 1; // recursion available
uint16_t q_count; // number of question entries
uint16_t ans_count; // number of answer entries
uint16_t auth_count; // number of authority entries
uint16_t add_count; // number of resource entries
};Секцию Question придётся разобрать для того, чтобы добраться до Answer. Сама секция состоит из такого количества блоков, которое указано в заголовке (q_count). Каждый блок состоит из имени, типа и класса запроса. Имя закодировано в виде последовательности строк, каждая из которых начинается с байта с длиной строки. В конце находится строка нулевой длины. Например, имя homedomain2008.ru будет выглядеть так:
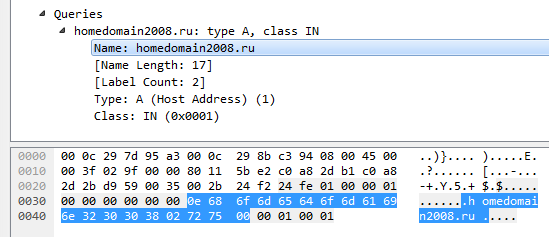
Секция Answers выглядит похожим образом: блок состоит из имени, типа, класса, ttl и дополнительных данных. IP-адрес будет содержатся в доп. данных. С разбором имени возникает ещё одна сложность. Видимо, для уменьшения размера сообщения, вместо длины метки, можно встретить ссылку на другую область данных. Закодирована она так: если 2 старших бита длины равны 11, то следующий байт, а также младшие биты длины, следует интерпретировать как смещение в байтах относительно начала сообщения. Дальнейший разбор имени нужно совершать, перейдя по этому смещению.
Итак, мы перехватили нужное API, разобрали dns-ответ, теперь нужно принять решение: пропускать дальше этот ответ или вернуть ошибку. Для каждого имени, которое ещё не присутствует в базе, из ответа нужно проверить, является ли оно «подозрительным» или нет.
Будем считать «подозрительным» такие имена, для которых результат функции skeleton из Unicode Technical Standard tr39 совпадает с результатом от любого из имён из базы, или те имена, которые отличаются от присутствующих в базе перестановкой внутренних букв. Для реализации проверок будем хранить 2 таблицы. Первая будет состоять из результатов skeleton для всех имён из базы, во вторую таблицу запишем строки, которые были получены из строк базы путём удаления первого и последнего символа из каждой метки кроме первого уровня, а затем сортировки оставшихся символов каждой метки. Теперь, если новое имя входит в одну из двух таблиц, то считаем его подозрительным.
Смысл функции skeleton в определении похожести двух строк, для этого для каждой строки производится нормализация символов. Например, Xlœ будет преобразовано в Xloe, и таким образом, сравнивая результат функции, можно определить похожесть unicode-строк.
С примером реализации описанного выше можно ознакомится на github.
Очевидно, что изложенное решение на практике предоставить нормальную защиту не может, т. к. помимо мелких технических проблем с перехватом, есть ещё большая проблема с детектированием «похожих» имён. Было бы неплохо обработать:
- Комбинации перестановок и омоглифов.
- Добавление\замену символов не учитываемых skeleton.
- UTS tr39 не исчерпывается skeleton, можно ещё ограничивать смешивание наборов символов в одной метке.
- Японскую полноширинную точку и другие label separator.
- А так же такие прекрасные вещи, как rnicrosoft.com
