Hello, Habr! Let's me present you a translation of an article "«Ломай меня полностью!» Как одни алгоритмы генерируют капчу, а другие её взламывают", author miroslavmirm.
Doesn't matter what kind of intelligence you have — be it artificial or natural — after this detailed analysis no captcha will be an obstacle. At the end of the article, you can find the simplest and most effective workaround solution.
CAPTCHA is a completely automated public Turing test to tell computers and humans apart by automatically setting up specific tasks that are difficult for computers but simple for human. This technology has become the security standard used to prevent automatic voting, registration, spam, brute-force attacks on websites, etc.
Existing captchas are divided into three categories: text, graphic and audio/video. Below we will look at how various captchas are generated and what successes now are with their bypassing. Do not scold for the quality of images — we took them from scientific publications, to which we provide links =) A full list of publications taken for analysis is given at the end of the article.
Text captchas are the most commonly used, but due to their simple structure they are also the most vulnerable. This type of captcha usually requires recognition of a geometrically distorted sequence of letters and numbers.
To increase security, various protection mechanisms are used, which can be divided into anti-segmentation and anti-recognition. The first group of mechanisms is aimed at complicating the process of characters separation, while the second group — at recognizing the characters themselves. Fig. 1 shows examples of various approaches to captchas defence.

Fig. 1: Captcha defence types
In the captcha-creating strategy “hollow symbols”, contour lines are used to form each symbol.

Fig. 2. Hollow captcha
Such characters are difficult to segment, but they are easily visible to people. Unfortunately, this mechanism is not as secure as expected. In Gao's research [1], the convolutional neural network successfully recognizes from 36% to 89% of images (depending on the type of distortion and the training sample).
Crowing characters together (CCT) complicate segmentation, but also reduce the readability for the user. That is, even human sometimes can not successfully solve such a captcha.

Fig. 3. Overlap and CCT
Researchers from China and Pakistan managed to crack the CCT with a probability of 27.1% to 53.2% [2].

Fig. 4. Background noises
Google's reCAPTCHA, using images from Street View, breaks in 96% of cases [3].
The two-level structure is a vertical combination of two horizontal captchas, which complicates the segmentation of the image.

Fig. 5. Two-level structure
Gao [4] proposed a segmentation approach for separating captcha images both vertically and horizontally, and achieved 44.6% success (9 seconds per image) using a convolutional neural network.
In the case of captcha based on selection, users must select the correct answers according to the prompt provided to this captcha. This is the simplest image based captcha form. For example, you need to highlight all the cars, all traffic signs or all traffic lights among the presented images.

Fig. 6. Various examples of image captchas, based on selection
Gaulle [5] proposed using the support vector machine (SVM) to distinguish images of cats and dogs in Asirra captcha with a probability of successful recognition of 82.7%.
Gao's team [6] used OpenCV to detect faces in FR-CAPTCHA. It was possible to obtain a detection probability from 8% to 42% with image processing in less than 14 seconds. FaceDCAPTCH was recognized with a probability of 48% on average in 6.2 seconds.
Columbia University employees beat reCAPTCHA and Facebook CAPTCHA with a probability of 70.78% and 83.5%, respectively.
In 2008, Richard Chow with his colleagues [7] first proposed click-based captcha. It requires users to click on symbols that are on a complex background in accordance with the prompt, as it shown on Fig. 7.
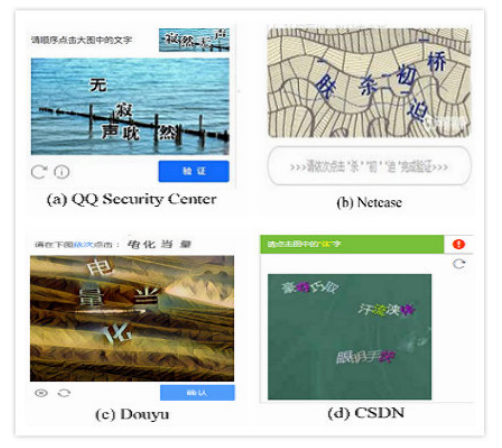
Fig. 7. Click-based captcha
Such click based captcha have two protective mechanisms: anti-detection and anti-recognition. Proper character recognition with the development of machine learning is no longer a difficult task. Therefore, almost all protection mechanisms are designed to prevent attackers from correctly identifying characters.
Dragging-based captcha determines whether the user is a person by analyzing the mouse trail, pointer movement speed, and response time.
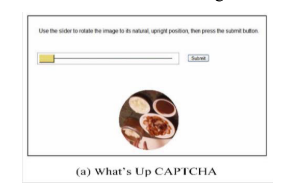
Fig. 8. Drag-and-Drop Captcha
Users need to rotate the image of the subject so that it will take it's a natural position. For example, rotate the image of the table until it is on its legs. It is simple for humans, but difficult for bots.
This captcha is usually considered as an alternative to visual captcha in the case of users with vision impairments. Listeners are invited to complete the task on the basis of what they heard, for example, to determine a specific sound, for example, the sound of a bell or piano [8].
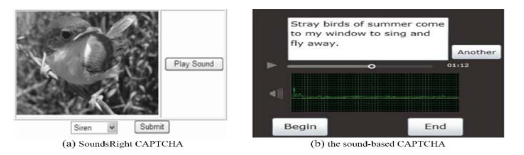
Fig. 9. Audio captcha
There is another type of audio-based captcha in which users are required to not only listen, but to pronounce. For example, Gao [9] proposed a sound captcha (Fig. 9), in which the user should read out a sentence selected randomly from a book. The generated audio file is analyzed to determine if the user is human.
But audio captcha is cracked too: scientists from Stanford University have learned to crack audio captcha with a probability of 75%.
In the video-captcha a video file is provided to users, and they must select a sentence that describes the movement of the person in the video.

Fig. 10. Summary table. Types of captcha
Japanese researchers used a solution based on HMM (hidden Markov model) and obtained an accuracy of 31.75%.
Let us now examine how exactly neural networks are used to crack captcha.
In 2017, Gao Huang, Zhuang Liu and others [10] built 4 deep convolutional neural networks with an architecture now called DenseNet. Dense blocks of neural networks alternated with skip-connection layers (Fig. 10). The input of each layer in the block was the union of the output of all previous layers. This distinguished the new architecture from the traditional at that time neural networks, where the layers were connected in series.
Fig. 11. DenseNet with three dense blocks [11]
The DenseNet architecture has several advantages: it solves the dispersion problem and effectively uses the properties of all previous convolutional layers, reducing the computational complexity of network parameters and demonstrating good classification performance.
An example of a variation of the DenseNet architecture is the DFCR neural network. The original captcha images of size 224x224 were passed through the convolution layer and then were combined into pools to output images of size 56x56. After that, 4 “dense” blocks were alternately connected, alternating with transition layers (Fig. 11). The structure of the transition layer made it possible to reduce the dimension of the feature map and speed up the calculations.
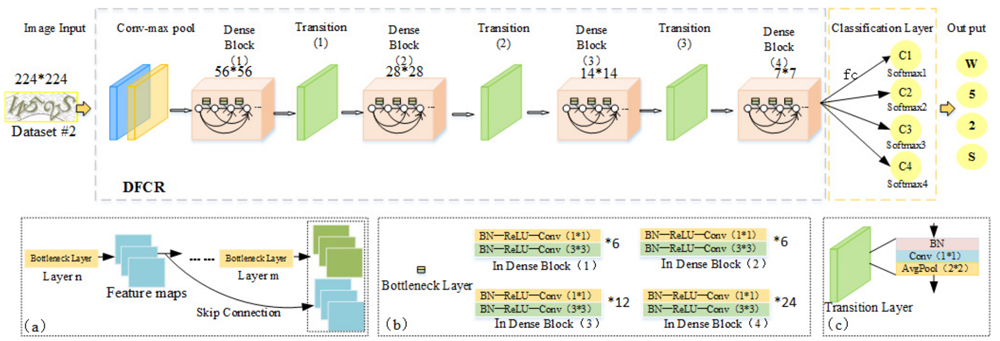
Fig. 12: DFCR architecture by the example of image recognition with the characters «W52S» [11]
Further, the feature maps were used to check the correspondence of the map and class. The values in each feature map were summed to obtain the average value, which was taken as the class value and displayed in the corresponding softmax classification layer.
Experiments show that DFCR not only preserves the main advantages of DenseNet, but also reduces memory consumption. In addition, the recognition accuracy of captcha with background noise and superimposed characters is higher than 99.9% [11].
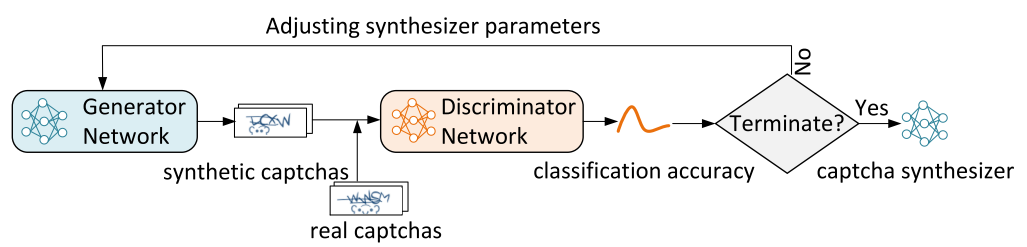
Fig. 13. The learning process of the text captcha generator on the GAN [12]
A captcha generator on a GAN (generative adversarial network) consist of two parts: 1) a network that creates captchas close to the original; 2) a neural network that distinguishes artificial captcha from the real one (solver).
Before serving the captcha to the solver, the used protective means are removed, and the font is normalized. For example, the hollow characters are filled, and the spaces between them are normalized. The preprocessing model is based on Pix2Pix.

Fig. 14. The scheme of the algorithm. First, a small real captcha dataset is used to train the captcha synthesizer (1). Next, artificial captchas (2) are generated to train the solver (3). Improvement of the solver (4) [12]
Then a large number of captchas with marks are generated, which are used to train the solver. A trained solver accepts captcha after preprocessing and issues the corresponding characters. Fine tuning of the solver happens with the help of a small set of manually marked captchas that were collected from the target site.
As a specific convolutional neural network, the LeNet-5 architecture, which was originally used to recognize single characters, turned out to be a good option. Adding two convolutional layers and three pooling layers has expanded its capabilities to recognize several characters.
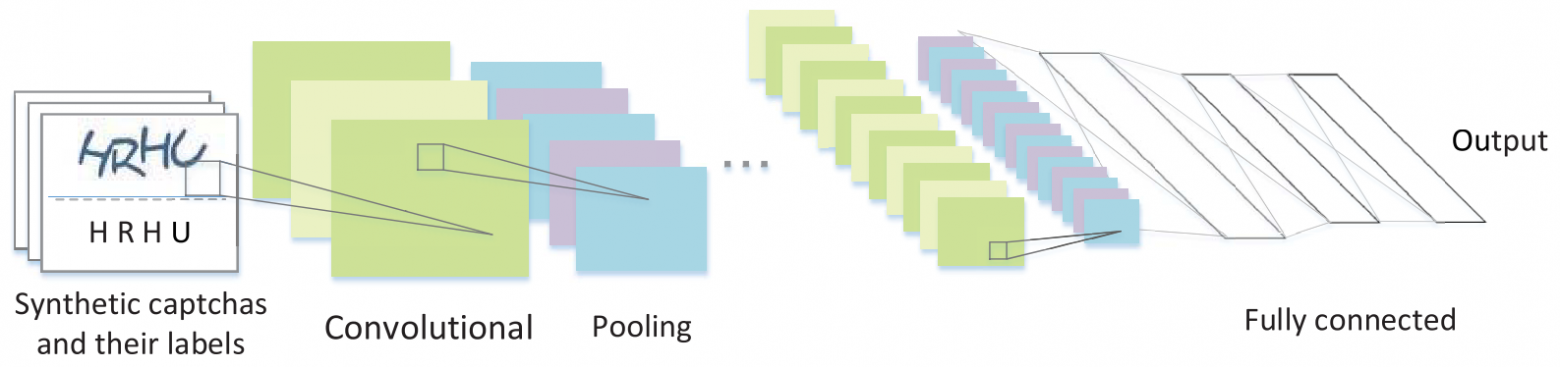
Fig. 15: Solver Training Algorithm [12]
Information obtained on the early layers of neural networks is useful for solving many other classification problems. The more distant layers are more specialized. This property is used to calibrate the solver to avoid systematic error or retraining.
The output layer of the solver consists of a series of neurons with one neuron per symbol. For example, if there are n characters in the captcha, the output layer will contain n neurons, where each neuron corresponds to a possible symbol. If the number of characters is not fixed, then it is necessary to train the solver for every possible n.
Hacking probability results:
CCT and Overlap (depending on complexity) — from 25.1% to 65%
Rotation (15 °, 30 °, 45 °, 60 °) — 100%, 100%, 99.85%, 99.55%
Distortion — 92.9%
Wave Effect — 98.85%
The combination of the above-mentioned — 46.30%
To recognize a sequence of characters without segmentation, you can use a model consisting of a convolutional neural network connected to a neural network with long short-term memory (LSTM) and an attention mechanism.
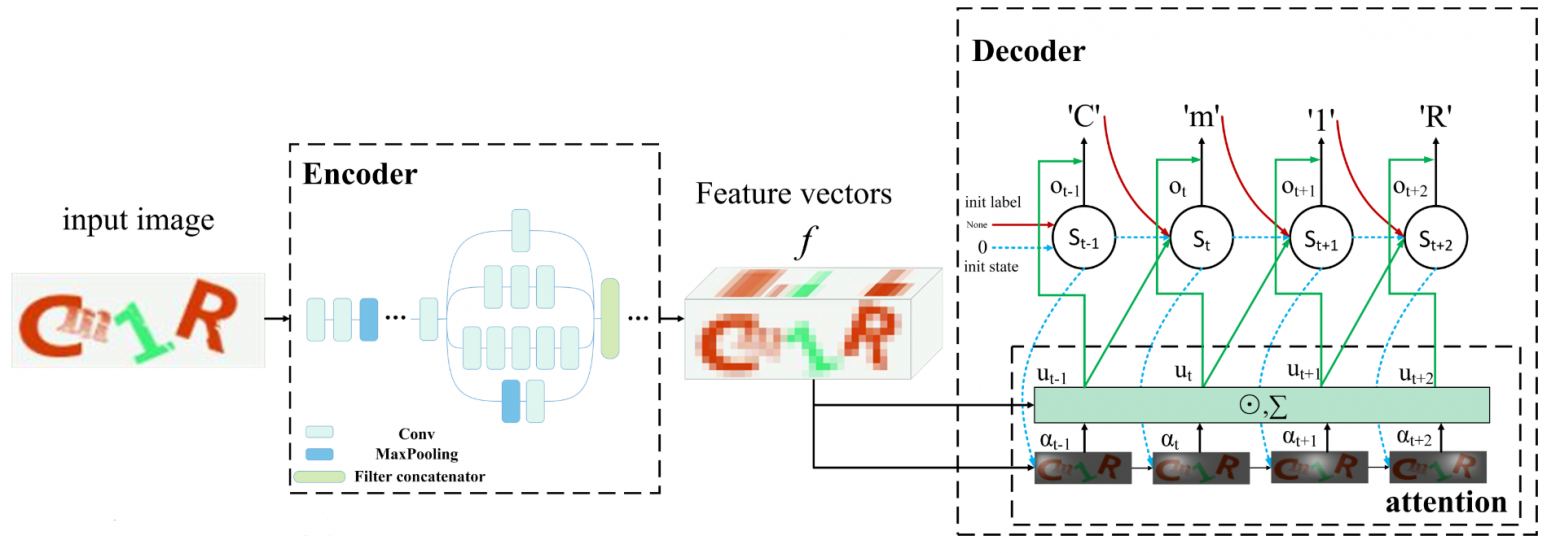
Fig. 16. Architecture Overview
The convolutional neural network is an encoder that extracts features from captcha. The original image is represented as a linear vector space. The feature vector created by the encoder is denoted by fijc, where i and j are the location indices on the feature map, c is the channel index.
LSTM works as a decoder and translates the feature vector into a text sequence. Unlike a recurrent neural network, LSTM can store information over long periods of time.
In the traditional sequence-to-sequence model the vector f is transmitted to the input at each time step. But the bottleneck of the standard model is that the input is constant. The attention mechanism allows the decoder to ignore irrelevant information, while preserving the most significant information about the vector f. Different parts of the feature vector are assigned to different weights, so that the model at each step can focus on a specific part of the vector, making predictions more accurate. This is the main reason why the proposed method can recognize individual characters without segmentation.
In experiments, the abbreviated Inception-v3 model was used for decoding. The decoder consisted of LSTM cells, each of which contained 256 hidden neurons. The number of LSTM cells was equal to the maximum length of the captcha line. For the entire structure, the number of parameters available to be trained was 9 million. Depending on the initial size, each captcha was scaled so that the short side was in the range from 100 to 200 pixels. At the training stage, the model trained on stochastic gradient descent with a moment of 0.9. The training rate was 0.004. 200 eras with a batch size of 64 were spent on training.

Fig. 17. CCT captcha
After each era, the model was tested. If the performance of the model was better than the current best model, the weights of the best model were updating. CCT captchas (text with overlapping) were collected as data for the experiment (Fig. 17).
For a captcha sample in the test set, the complete predicted sequence of characters was considered correctly determined only if it was identical to the manually marked answer. For a set of 10,000 samples (training and test in a 3:1 ratio), the probability of successful recognition was 42.7%. With the number of samples increased to 50,000, 100,000, 150,000, and 200,000, the probability increased to 87.9%, 94.5%, 97.4%, and 98.3%, respectively.
Reinforcement learning was used to bypass Google reCAPTCHA v3 [14].
The bot’s interaction with the environment was modeled as a Markov decision process (MDP). MDP was defined by a tuple (S, A, P, r), where S is a finite set of states, A is a finite set of actions, P is the probability of a transition between states P (s, a, s'), r is the reward received after going to state s' from state s with probability of P.
The goal of the campaign was to find the optimal π * rule that maximizes expected rewards in the future. Suppose that a rule is parameterized by a set of weights w such that π = π (s, w). Then the task is set as
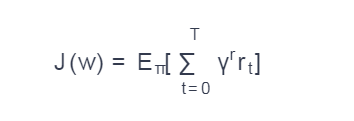
where γ is some constant (discount factor), rt is the reward at time t.
Reinforced learning measures gradients by the formula
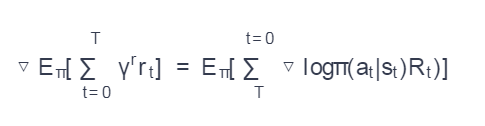
To go through reCAPTCHA, the user moves the cursor until the reCAPTCHA checkbox is selected. Depending on this interaction, the reCAPTCHA system will “reward” the user with a point. This process was modeled as MDP, where the state space S is the possible cursor position on the web page, and the action space A = {up, left, right, down}. This approach makes the task similar to a grid world task.
As shown in Fig. 18, the starting point is the start position of the cursor, and the target is the position of reCAPTCHA. For each test, the starting point is randomly selected from the upper right or upper left area. Then a grid is built, where each pixel between the start and end points is a possible cursor position. Cell size c is the number of pixels between two consecutive positions. For example, if the cursor is at the position (x0, y0) and takes a move to the left, then the next position will be (x0 — c, y0).
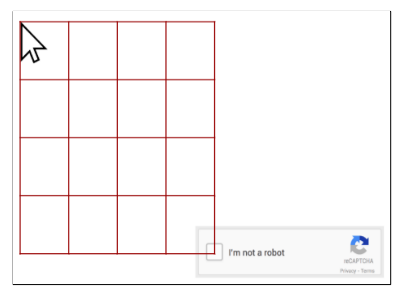
Fig. 18. The grid in the MDP [14]
In each test, the cursor position is random, the bot performs a sequence of actions until reCAPTCHA or the limit T is reached, where a and b are the height and width of the grid, respectively.

At the end of the test, the bot receives feedback from reCAPTCHA, like any ordinary user.
In most of the previous works, Selenium was used to automate the actions of the web browser, however, it often failed the test, since the HTTP requests detected an automatically generated header and other additional variables that were missing in a regular browser.
This problem can be solved in two different ways. The first is to create a proxy to remove the automatic header. The second option is to launch the browser from the command line and control the mouse using special Python packages, such as the PyAutoGUI library.
It's funny that simulations running in a browser with logged in Google account were passing validation more often than simulations without authorization.
In experiments with a discount factor of γ = 0.99, a learning speed of 10^-3 and a batch size of 2000 CAPTCHA was cracked with a probability of 97.4%.
As you can already see from this article, machine learning has a high entry threshold, and after all, everything that was described in the article is just the tip of the iceberg. If you dig deeper, then soon you can claim the title of junior on neural networks =)
But for actual work you need a team of specialists and a rental of computing power. Add to this the time for training/retraining of networks, a growing number of captcha types, a variety of languages — and it will turn out that it’s faster and cheaper to use online services where it's people solve captchas.
Among similar services, 2captcha stands out. The service has a fine-tuning of the solver: the number of words, case, numbers and/or letters, language (55 to choose from), mathematical operations, etc.
The following types of captcha can be solved: plain text, ReCaptcha versions 2 and 3, GeeTest, hCaptcha, ClickCaptcha, RotateCaptcha, FunCaptcha, KeyCaptcha.
Interaction with the server occurs through the API, that is, you can embed the solution in your own product. There is a refund function for rare incorrect answers, also technical support actually does answer the questions (and really adequate in comparison with competitors).
Of course, for solving captchas the service pays to specific people who are ready to solve tasks for a small fee. Accordingly, the service takes this money from customers who do not have to deal with routine anymore. The prices at the time of writing were as follows: 1000 captchas were hacked for no more than $0.75 (on average 7.5 seconds per captcha), 1000 ReCaptchas — for $2.99 (average 32 seconds per captcha). That is, one fixed price regardless of the load and how much other customers paid.
Just for comparison: one middle specialist in machine learning will cost at least $2,000/month on the today's market.
Leave a comment if you used the service — it is interesting to know your opinion (so far we are based on the opinions of the authors of the following articles: in English and three in Russian: one, two, three).
SOURCES:
[1] Gao, H., Wang, W., Qi, J., Wang, X., Liu, X., & Yan, J. (2013, November). The robustness of hollow CAPTCHAs. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security (pp. 1075-1086). ACM.
[2] Hussain, R., Gao, H., & Shaikh, R. A. (2017). Segmentation of connected characters in text-based CAPTCHAs for intelligent character recognition. Multimedia Tools and Applications
[3] Goodfellow, I. J., Bulatov, Y., Ibarz, J., Arnoud, S., & Shet, V. Multitdigit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks.
[4] Gao, H., Tang, M., Liu, Y., Zhang, P., & Liu, X. (2017). Research on the Security of Microsoft’s Two-Layer Captcha. IEEE Transactions on Information Forensics and Security, 12(7), 1671-1685.
[5] Golle, P. (2008, October). Machine learning attacks against the Asirra CAPTCHA. In Proceedings of the 15th ACM conference on Computer and communications security (pp. 535-542). ACM.
[6] The robustness of face-based CAPTCHAs. Haichang Gao, Lei Lei, Xin Zhou, Jiawei Li, Xiyang Liu. Institute of Software Engineering, Xidian University.
[7] Chow, R., Golle, P., Jakobsson, M., Wang, L., & Wang, X. (2008, February). Making captchas clickable
[8] The SoundsRight CAPTCHA: an improved approach to audio human interaction proofs for blind users. Jonathan Lazar, Jinjuan Heidi Feng, Tim Brooks, Genna Melamed, Jon Holman, Abiodun Olalere, Nnanna Ekedebe, and Brian Wentz
[9] Gao, H., Liu, H., Yao, D., Liu, X., & Aickelin, U. (2010, July). An audio CAPTCHA to distinguish humans from computers.
[10] G. Huang, Z. Liu, L. V. D Maaten, et al., Densely connected convolutional networks, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 2261–2269
[11] CAPTCHA recognition based on deep convolutional neural network
[12] Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach Guixin
[13] An end-to-end attack on text CAPTCHAs
[14] Hacking Google reCAPTCHA v3 using Reinforcement Learning
Doesn't matter what kind of intelligence you have — be it artificial or natural — after this detailed analysis no captcha will be an obstacle. At the end of the article, you can find the simplest and most effective workaround solution.
CAPTCHA is a completely automated public Turing test to tell computers and humans apart by automatically setting up specific tasks that are difficult for computers but simple for human. This technology has become the security standard used to prevent automatic voting, registration, spam, brute-force attacks on websites, etc.
1. Categories of captcha
Existing captchas are divided into three categories: text, graphic and audio/video. Below we will look at how various captchas are generated and what successes now are with their bypassing. Do not scold for the quality of images — we took them from scientific publications, to which we provide links =) A full list of publications taken for analysis is given at the end of the article.
1.1. Text captcha
Text captchas are the most commonly used, but due to their simple structure they are also the most vulnerable. This type of captcha usually requires recognition of a geometrically distorted sequence of letters and numbers.
To increase security, various protection mechanisms are used, which can be divided into anti-segmentation and anti-recognition. The first group of mechanisms is aimed at complicating the process of characters separation, while the second group — at recognizing the characters themselves. Fig. 1 shows examples of various approaches to captchas defence.
Fig. 1: Captcha defence types
1.1.1. Hollow symbols
In the captcha-creating strategy “hollow symbols”, contour lines are used to form each symbol.
Fig. 2. Hollow captcha
Such characters are difficult to segment, but they are easily visible to people. Unfortunately, this mechanism is not as secure as expected. In Gao's research [1], the convolutional neural network successfully recognizes from 36% to 89% of images (depending on the type of distortion and the training sample).
1.1.2. Crowing characters together
Crowing characters together (CCT) complicate segmentation, but also reduce the readability for the user. That is, even human sometimes can not successfully solve such a captcha.
Fig. 3. Overlap and CCT
Researchers from China and Pakistan managed to crack the CCT with a probability of 27.1% to 53.2% [2].
1.1.3. Background noises
Fig. 4. Background noises
Google's reCAPTCHA, using images from Street View, breaks in 96% of cases [3].
1.1.4. Two-level structure
The two-level structure is a vertical combination of two horizontal captchas, which complicates the segmentation of the image.
Fig. 5. Two-level structure
Gao [4] proposed a segmentation approach for separating captcha images both vertically and horizontally, and achieved 44.6% success (9 seconds per image) using a convolutional neural network.
1.2. Captcha based on image
1.2.1. Selection based captcha
In the case of captcha based on selection, users must select the correct answers according to the prompt provided to this captcha. This is the simplest image based captcha form. For example, you need to highlight all the cars, all traffic signs or all traffic lights among the presented images.
Fig. 6. Various examples of image captchas, based on selection
Gaulle [5] proposed using the support vector machine (SVM) to distinguish images of cats and dogs in Asirra captcha with a probability of successful recognition of 82.7%.
Gao's team [6] used OpenCV to detect faces in FR-CAPTCHA. It was possible to obtain a detection probability from 8% to 42% with image processing in less than 14 seconds. FaceDCAPTCH was recognized with a probability of 48% on average in 6.2 seconds.
Columbia University employees beat reCAPTCHA and Facebook CAPTCHA with a probability of 70.78% and 83.5%, respectively.
1.2.2. Click-based Captcha
In 2008, Richard Chow with his colleagues [7] first proposed click-based captcha. It requires users to click on symbols that are on a complex background in accordance with the prompt, as it shown on Fig. 7.
Fig. 7. Click-based captcha
Such click based captcha have two protective mechanisms: anti-detection and anti-recognition. Proper character recognition with the development of machine learning is no longer a difficult task. Therefore, almost all protection mechanisms are designed to prevent attackers from correctly identifying characters.
1.2.3. Drag-and-Drop Captcha
Dragging-based captcha determines whether the user is a person by analyzing the mouse trail, pointer movement speed, and response time.
Fig. 8. Drag-and-Drop Captcha
Users need to rotate the image of the subject so that it will take it's a natural position. For example, rotate the image of the table until it is on its legs. It is simple for humans, but difficult for bots.
1.3. Audio/video captcha
1.3.1 Audio captcha
This captcha is usually considered as an alternative to visual captcha in the case of users with vision impairments. Listeners are invited to complete the task on the basis of what they heard, for example, to determine a specific sound, for example, the sound of a bell or piano [8].
Fig. 9. Audio captcha
There is another type of audio-based captcha in which users are required to not only listen, but to pronounce. For example, Gao [9] proposed a sound captcha (Fig. 9), in which the user should read out a sentence selected randomly from a book. The generated audio file is analyzed to determine if the user is human.
But audio captcha is cracked too: scientists from Stanford University have learned to crack audio captcha with a probability of 75%.
1.3.2 Video-captcha
In the video-captcha a video file is provided to users, and they must select a sentence that describes the movement of the person in the video.
Fig. 10. Summary table. Types of captcha
Japanese researchers used a solution based on HMM (hidden Markov model) and obtained an accuracy of 31.75%.
Let us now examine how exactly neural networks are used to crack captcha.
2. Neural networks with DenseNet and DFCR architectures
In 2017, Gao Huang, Zhuang Liu and others [10] built 4 deep convolutional neural networks with an architecture now called DenseNet. Dense blocks of neural networks alternated with skip-connection layers (Fig. 10). The input of each layer in the block was the union of the output of all previous layers. This distinguished the new architecture from the traditional at that time neural networks, where the layers were connected in series.
Fig. 11. DenseNet with three dense blocks [11]
The DenseNet architecture has several advantages: it solves the dispersion problem and effectively uses the properties of all previous convolutional layers, reducing the computational complexity of network parameters and demonstrating good classification performance.
An example of a variation of the DenseNet architecture is the DFCR neural network. The original captcha images of size 224x224 were passed through the convolution layer and then were combined into pools to output images of size 56x56. After that, 4 “dense” blocks were alternately connected, alternating with transition layers (Fig. 11). The structure of the transition layer made it possible to reduce the dimension of the feature map and speed up the calculations.
Fig. 12: DFCR architecture by the example of image recognition with the characters «W52S» [11]
Further, the feature maps were used to check the correspondence of the map and class. The values in each feature map were summed to obtain the average value, which was taken as the class value and displayed in the corresponding softmax classification layer.
Experiments show that DFCR not only preserves the main advantages of DenseNet, but also reduces memory consumption. In addition, the recognition accuracy of captcha with background noise and superimposed characters is higher than 99.9% [11].
3. Generative adversarial network
Fig. 13. The learning process of the text captcha generator on the GAN [12]
A captcha generator on a GAN (generative adversarial network) consist of two parts: 1) a network that creates captchas close to the original; 2) a neural network that distinguishes artificial captcha from the real one (solver).
Before serving the captcha to the solver, the used protective means are removed, and the font is normalized. For example, the hollow characters are filled, and the spaces between them are normalized. The preprocessing model is based on Pix2Pix.
Fig. 14. The scheme of the algorithm. First, a small real captcha dataset is used to train the captcha synthesizer (1). Next, artificial captchas (2) are generated to train the solver (3). Improvement of the solver (4) [12]
Then a large number of captchas with marks are generated, which are used to train the solver. A trained solver accepts captcha after preprocessing and issues the corresponding characters. Fine tuning of the solver happens with the help of a small set of manually marked captchas that were collected from the target site.
As a specific convolutional neural network, the LeNet-5 architecture, which was originally used to recognize single characters, turned out to be a good option. Adding two convolutional layers and three pooling layers has expanded its capabilities to recognize several characters.
Fig. 15: Solver Training Algorithm [12]
Information obtained on the early layers of neural networks is useful for solving many other classification problems. The more distant layers are more specialized. This property is used to calibrate the solver to avoid systematic error or retraining.
The output layer of the solver consists of a series of neurons with one neuron per symbol. For example, if there are n characters in the captcha, the output layer will contain n neurons, where each neuron corresponds to a possible symbol. If the number of characters is not fixed, then it is necessary to train the solver for every possible n.
Hacking probability results:
CCT and Overlap (depending on complexity) — from 25.1% to 65%
Rotation (15 °, 30 °, 45 °, 60 °) — 100%, 100%, 99.85%, 99.55%
Distortion — 92.9%
Wave Effect — 98.85%
The combination of the above-mentioned — 46.30%
4. Convolutional neural network + long short-term memory (LSTM)
To recognize a sequence of characters without segmentation, you can use a model consisting of a convolutional neural network connected to a neural network with long short-term memory (LSTM) and an attention mechanism.
Fig. 16. Architecture Overview
The convolutional neural network is an encoder that extracts features from captcha. The original image is represented as a linear vector space. The feature vector created by the encoder is denoted by fijc, where i and j are the location indices on the feature map, c is the channel index.
LSTM works as a decoder and translates the feature vector into a text sequence. Unlike a recurrent neural network, LSTM can store information over long periods of time.
In the traditional sequence-to-sequence model the vector f is transmitted to the input at each time step. But the bottleneck of the standard model is that the input is constant. The attention mechanism allows the decoder to ignore irrelevant information, while preserving the most significant information about the vector f. Different parts of the feature vector are assigned to different weights, so that the model at each step can focus on a specific part of the vector, making predictions more accurate. This is the main reason why the proposed method can recognize individual characters without segmentation.
In experiments, the abbreviated Inception-v3 model was used for decoding. The decoder consisted of LSTM cells, each of which contained 256 hidden neurons. The number of LSTM cells was equal to the maximum length of the captcha line. For the entire structure, the number of parameters available to be trained was 9 million. Depending on the initial size, each captcha was scaled so that the short side was in the range from 100 to 200 pixels. At the training stage, the model trained on stochastic gradient descent with a moment of 0.9. The training rate was 0.004. 200 eras with a batch size of 64 were spent on training.
Fig. 17. CCT captcha
After each era, the model was tested. If the performance of the model was better than the current best model, the weights of the best model were updating. CCT captchas (text with overlapping) were collected as data for the experiment (Fig. 17).
For a captcha sample in the test set, the complete predicted sequence of characters was considered correctly determined only if it was identical to the manually marked answer. For a set of 10,000 samples (training and test in a 3:1 ratio), the probability of successful recognition was 42.7%. With the number of samples increased to 50,000, 100,000, 150,000, and 200,000, the probability increased to 87.9%, 94.5%, 97.4%, and 98.3%, respectively.
5. Reinforcement learning
Reinforcement learning was used to bypass Google reCAPTCHA v3 [14].
The bot’s interaction with the environment was modeled as a Markov decision process (MDP). MDP was defined by a tuple (S, A, P, r), where S is a finite set of states, A is a finite set of actions, P is the probability of a transition between states P (s, a, s'), r is the reward received after going to state s' from state s with probability of P.
The goal of the campaign was to find the optimal π * rule that maximizes expected rewards in the future. Suppose that a rule is parameterized by a set of weights w such that π = π (s, w). Then the task is set as
where γ is some constant (discount factor), rt is the reward at time t.
Reinforced learning measures gradients by the formula
To go through reCAPTCHA, the user moves the cursor until the reCAPTCHA checkbox is selected. Depending on this interaction, the reCAPTCHA system will “reward” the user with a point. This process was modeled as MDP, where the state space S is the possible cursor position on the web page, and the action space A = {up, left, right, down}. This approach makes the task similar to a grid world task.
As shown in Fig. 18, the starting point is the start position of the cursor, and the target is the position of reCAPTCHA. For each test, the starting point is randomly selected from the upper right or upper left area. Then a grid is built, where each pixel between the start and end points is a possible cursor position. Cell size c is the number of pixels between two consecutive positions. For example, if the cursor is at the position (x0, y0) and takes a move to the left, then the next position will be (x0 — c, y0).
Fig. 18. The grid in the MDP [14]
In each test, the cursor position is random, the bot performs a sequence of actions until reCAPTCHA or the limit T is reached, where a and b are the height and width of the grid, respectively.
At the end of the test, the bot receives feedback from reCAPTCHA, like any ordinary user.
In most of the previous works, Selenium was used to automate the actions of the web browser, however, it often failed the test, since the HTTP requests detected an automatically generated header and other additional variables that were missing in a regular browser.
This problem can be solved in two different ways. The first is to create a proxy to remove the automatic header. The second option is to launch the browser from the command line and control the mouse using special Python packages, such as the PyAutoGUI library.
It's funny that simulations running in a browser with logged in Google account were passing validation more often than simulations without authorization.
In experiments with a discount factor of γ = 0.99, a learning speed of 10^-3 and a batch size of 2000 CAPTCHA was cracked with a probability of 97.4%.
6. CAPTCHA-solving by humans
As you can already see from this article, machine learning has a high entry threshold, and after all, everything that was described in the article is just the tip of the iceberg. If you dig deeper, then soon you can claim the title of junior on neural networks =)
But for actual work you need a team of specialists and a rental of computing power. Add to this the time for training/retraining of networks, a growing number of captcha types, a variety of languages — and it will turn out that it’s faster and cheaper to use online services where it's people solve captchas.
Among similar services, 2captcha stands out. The service has a fine-tuning of the solver: the number of words, case, numbers and/or letters, language (55 to choose from), mathematical operations, etc.
The following types of captcha can be solved: plain text, ReCaptcha versions 2 and 3, GeeTest, hCaptcha, ClickCaptcha, RotateCaptcha, FunCaptcha, KeyCaptcha.
Interaction with the server occurs through the API, that is, you can embed the solution in your own product. There is a refund function for rare incorrect answers, also technical support actually does answer the questions (and really adequate in comparison with competitors).
Of course, for solving captchas the service pays to specific people who are ready to solve tasks for a small fee. Accordingly, the service takes this money from customers who do not have to deal with routine anymore. The prices at the time of writing were as follows: 1000 captchas were hacked for no more than $0.75 (on average 7.5 seconds per captcha), 1000 ReCaptchas — for $2.99 (average 32 seconds per captcha). That is, one fixed price regardless of the load and how much other customers paid.
Just for comparison: one middle specialist in machine learning will cost at least $2,000/month on the today's market.
Leave a comment if you used the service — it is interesting to know your opinion (so far we are based on the opinions of the authors of the following articles: in English and three in Russian: one, two, three).
SOURCES:
[1] Gao, H., Wang, W., Qi, J., Wang, X., Liu, X., & Yan, J. (2013, November). The robustness of hollow CAPTCHAs. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security (pp. 1075-1086). ACM.
[2] Hussain, R., Gao, H., & Shaikh, R. A. (2017). Segmentation of connected characters in text-based CAPTCHAs for intelligent character recognition. Multimedia Tools and Applications
[3] Goodfellow, I. J., Bulatov, Y., Ibarz, J., Arnoud, S., & Shet, V. Multitdigit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks.
[4] Gao, H., Tang, M., Liu, Y., Zhang, P., & Liu, X. (2017). Research on the Security of Microsoft’s Two-Layer Captcha. IEEE Transactions on Information Forensics and Security, 12(7), 1671-1685.
[5] Golle, P. (2008, October). Machine learning attacks against the Asirra CAPTCHA. In Proceedings of the 15th ACM conference on Computer and communications security (pp. 535-542). ACM.
[6] The robustness of face-based CAPTCHAs. Haichang Gao, Lei Lei, Xin Zhou, Jiawei Li, Xiyang Liu. Institute of Software Engineering, Xidian University.
[7] Chow, R., Golle, P., Jakobsson, M., Wang, L., & Wang, X. (2008, February). Making captchas clickable
[8] The SoundsRight CAPTCHA: an improved approach to audio human interaction proofs for blind users. Jonathan Lazar, Jinjuan Heidi Feng, Tim Brooks, Genna Melamed, Jon Holman, Abiodun Olalere, Nnanna Ekedebe, and Brian Wentz
[9] Gao, H., Liu, H., Yao, D., Liu, X., & Aickelin, U. (2010, July). An audio CAPTCHA to distinguish humans from computers.
[10] G. Huang, Z. Liu, L. V. D Maaten, et al., Densely connected convolutional networks, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 2261–2269
[11] CAPTCHA recognition based on deep convolutional neural network
[12] Yet Another Text Captcha Solver: A Generative Adversarial Network Based Approach Guixin
[13] An end-to-end attack on text CAPTCHAs
[14] Hacking Google reCAPTCHA v3 using Reinforcement Learning
