
Основой любого приложения является его главный поток. На нем происходят все самые важные вещи: создаются другие потоки, меняется UI. Важнейшей его частью является цикл. Так как поток главный, то и его цикл тоже главный - в простонародье Main Loop.
Тонкости работы главного цикла уже описаны в Android SDK, а разработчики лишь взаимодействуют с ним. Поэтому, хотелось бы разобраться подробней, как работает главный цикл, для чего нужен, какие проблемы решает и какие у него есть особенности.
Это вторая часть цикла статей по разбору главного цикла в Android. В первой части мы разобрались с тем, что такое главный цикл и как он работает. В этой же части давайте разберемся как Main Loop устроен в Android SDK. Разбираться будем в контексте Android SDK версии 30.
По всем правилам приличия представлюсь — меня зовут Перевалов Данил, а теперь давайте перейдём к теме.
Looper
Начнем мы с самого главного - Looper. Напомню, что этот класс отвечает за сам цикл и его работу. Далее в рассуждениях я буду отталкиваться от того, что вы прочли первую часть и/или понимаете общую логику работы главного цикла. Приступим.
Может быть создан для любого из потоков и только один
Первое, что бросается в глаза - приватный конструктор.
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}Создать Looper можно только используя метод prepare.
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}При вызове публичного метода prepare вызывается его приватная реализация. Она принимает в себя параметр quitAllowed. Он будет true, если для данного Looper есть возможность завершится во время работы приложения. Для главного потока этот параметр всегда будет false, так как если завершится главный поток, то завершится и приложение. Для побочных же потоков этот параметр всегда равен true.
Также в методе prepare можно заметить обращение к полю sThreadLocal типа ThreadLocal. Что же это такое?
ThreadLocal это такое хранилище в котором для каждого из потоков будет хранится свое значение. Допустим я из потока 1 кладу в это хранилище true, затем если я обращусь из этого же потока к хранилищу - я получу true. Но если я обращусь к этому хранилищу из другого потока, то мне вернется null, так как для этого потока значение еще не было записано.

Looper использует этот механизм вкупе с приватным конструктором для того, чтобы обеспечить уникальность Looper для каждого из потоков. Внутри метода prepare с помощью ThreadLocal он сначала проверяет был ли уже создан Looper для текущего потока, если это так, то бросает исключение которое скажет о том, что негоже создавать несколько Looper для одного потока. Если же Looper для текущего потока еще не был создан, то он создает новый Looper и сразу же записывает его в ThreadLocal.
Для получения экземпляра Looper, созданного в методе prepare, есть метод myLooper. Он просто каждый раз обращается к sThreadLocal для получения значения для текущего потока.
public static Looper myLooper() {
return sThreadLocal.get();
}С такой логикой Looper можно создать для любого из потоков, пользоваться и при этом точно знать, что для данного потока Looper только один. Допустим у нас есть 5 потоков и каждый из них создает и обращается к Looper. В итоге у нас будет создано 5 экземпляров Looper, но при обращении к Looper.myLooper каждый из потоков будет получать свой уникальный экземпляр.
Главный среди равных
Правда тут появляется вопрос - если Looper может быть несколько, то какой из них является главным циклом? Ведь я могу создать несколько потоков, для каждого из них создать Looper, то как потом другим программистам понять кто же из них главный и куда им слать сообщения? Создатели Android подумали так же. Поэтому в Looper есть следующий код:
private static Looper sMainLooper;
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}Отдельный метод prepareMainLooper как раз занимается тем, что создает Looper для текущего потока и записывает его в отдельное статическое поле sMainLooper, тем самым как-бы объявляя его главным. Теперь если кто-то попробует вызвать prepareMainLooper с другого потока, то будет брошено исключение которое скажет нам, что главный вообще-то может быть только один.
Еще у главного потока есть свой отдельный getter - getMainLooper, ведь обращение к главному циклу может понадобиться где угодно. Таким образом, разработчики всегда будут знать кто тут главный Looper.
Теперь давайте ближе взглянем на особенности самого цикла, а значит на метод loop.
Логирование
Первое что бросается в глаза в методе loop, это то, что у нас вместо цикла while используется for с двумя точками с запятой. Такой подход вроде как производительнее.
Также можно заметить что остановка бесконечного цикла делается не с помощью переключения отдельной переменной isAlive, а помощью получение null от MessageQueue.next.
public static void loop() {
..................
for (;;) {
Message msg = queue.next();
if (msg == null) {
return;
}Куда более интересное отличие, что в Looper из Android SDK у нас появляется логирование. Для него используется класс под названием Printer. По сути его единственной функцией является вывод сообщения с помощью метода println.
Инициализированный объект Printer хранится в поле mLogging, то есть у каждого из Looper может быть свой личный Printer. Выставляется Printer через отдельный сеттер. Если же Printer не задать, то и логирования не будет.
private Printer mLogging;
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}Внутри самого метода loop Printer используется трижды:
в первый раз когда мы принимаем сообщение. Ссылка из поля mLogging записывается в final переменную logging. Это нужно, чтобы не было ситуаций когда во время обработки сообщения мы сменили Printer в поле mLogging и логирование по одному сообщению произошло в разные места;
во второй раз когда он сообщает нам о том, что началась обработка сообщения и выводит информацию о самом сообщении;
в третий раз когда он сообщает нам о том, что обработка сообщения завершена и выводит информацию о самом сообщении;
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
..................
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}Но логирование не является единственным способом отслеживания работы Looper. Дополнительно используется класс Trace. Он нужен для трассировки стека методов через SysTrace. С помощью SysTrace мы в Profiler из Android Studio можем просматривать этот самый стек и время исполнения каждого из методов в нем. Для этого, перед тем как начнет обрабатываться новое сообщение вызывается Trace.traceBegin и когда обработка сообщения завершится Trace.traceEnd.
if (traceTag != 0 && Trace.isTagEnabled(traceTag)) {
Trace.traceBegin(traceTag, msg.target.getTraceName(msg));
}
..................
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}Но это еще не все методы слежки.
Подсчет времени
Looper считает время доставки и обработки сообщений и если это время больше ожидаемого, то он сообщит нам об этом. Это может понадобиться в поисках источников фризов и лагов. Допустим у нас экран 60 Гц, значит желательно, чтобы каждое сообщение обрабатывалось не более 1000 / 60 = 16,6 мс (на самом деле нужно меньше, но не суть), иначе главный поток не успеет подготовить данные для отрисовки и у нас используется прошлый кадр. Из-за этого будет казаться будто бы изображение зависло, а значит интерфейс перестанет быть плавным.
Для этого у нас имеется два поля типа long: mSlowDeliveryThresholdMs отвечающий за время доставки сообщения и mSlowDispatchThresholdMs отвечающий за время обработки сообщения.
private long mSlowDispatchThresholdMs;
private long mSlowDeliveryThresholdMs;
public void setSlowLogThresholdMs(long slowDispatchThresholdMs, long slowDeliveryThresholdMs) {
mSlowDispatchThresholdMs = slowDispatchThresholdMs;
mSlowDeliveryThresholdMs = slowDeliveryThresholdMs;
}Выставляем mSlowDispatchThresholdMs равным 16 и Looper сам будет уведомлять нас о всех сообщениях которые обрабатывались дольше этого времени и соответственно являются причиной подвисания.
Для выставления значений этих полей создан отдельный метод setSlowLogThresholdMs. Эти поля всегда выставляются парой.
Также есть возможность задать это время с помощью системной переменной. Имя которой формируется по следующему принципу: log.looper.<”идентификатор процесса”>.<”имя потока, в нашем случае это будет main”>.slow.
final int thresholdOverride =
SystemProperties.getInt("log.looper."
+ Process.myUid() + "."
+ Thread.currentThread().getName()
+ ".slow", 0);Теперь посмотрим как это всё работает внутри метода loop.
long slowDispatchThresholdMs = me.mSlowDispatchThresholdMs;
long slowDeliveryThresholdMs = me.mSlowDeliveryThresholdMs;
if (thresholdOverride > 0) {
slowDispatchThresholdMs = thresholdOverride;
slowDeliveryThresholdMs = thresholdOverride;
}
final boolean logSlowDelivery = (slowDeliveryThresholdMs > 0) && (msg.when > 0);
final boolean logSlowDispatch = (slowDispatchThresholdMs > 0);
final boolean needStartTime = logSlowDelivery || logSlowDispatch;
final boolean needEndTime = logSlowDispatch;Выглядит как-то путано, не правда ли? Сначала значение полей записываются в локальные переменные. Затем проверяется, не было ли задано ограничение с помощью системной переменной, если это так, то берется именно оно. Если оба значение для время доставки и обработки больше нуля, то метод loop понимает, что время начать считать.
Далее формируются два значения: начала и окончания. Если с обработкой все понятно, то для подсчета времени доставки в качестве времени начала выступает ожидаемое время начала обработки, а в качестве времени окончания используется время реального начала обработки.
После того как обработка сообщения завершится вызывается статический метод showSlowLog отдельно для времени доставки и отдельно для времени обработки.
private static boolean showSlowLog(long threshold, long measureStart, long measureEnd, String what, Message msg) {
final long actualTime = measureEnd - measureStart;
if (actualTime < threshold) {
return false;
}
Slog.w(TAG, "Slow " + what + " took " + actualTime + "ms "
+ Thread.currentThread().getName() + " h="
+ msg.target.getClass().getName() + " c=" + msg.callback + " m=" + msg.what);
return true;
}В самом методе все довольно просто - из времени окончания вычитается время начала, таким образом получается длительность обработки или доставки. Если эта длительность больше чем ожидаемая, то происходит вывод в лог информации о сообщении.
Интересный момент тут в том, что логирование происходит с помощью класса Slog, а не обычного Log. Slog это специальный класс который выводит логи от имени системы. Так что, имейте ввиду, что если установить фильтр по имени вашего процесса в logcat, то вы не увидите этих сообщений.
Наблюдатели и try/catch
И это еще не все способы наблюдения за Looper. До этого информация выводилась либо в лог, либо в SysTrace. Но что если надо следить за Looper прямо в коде? Для этого используются внутренний interface Looper - Observer.
public interface Observer {
Object messageDispatchStarting();
void messageDispatched(Object token, Message msg);
void dispatchingThrewException(Object token, Message msg, Exception exception);
}Он содержит в себе методы наблюдения за стартом обработки сообщения, за окончанием обработки сообщения и за вероятным исключением при обработке сообщения. Последний метод может понадобиться, чтобы как-то использовать исключение которое привело к падению приложения, например отправить информацию о нем на удаленный сервер, как это делает Firebase Crashlytics.
Сам Observer хранится статической переменной sObserver, то есть наблюдатель выставляется сразу для всех экземпляров Looper. Выставляется он через отдельный сеттер.
private static Observer sObserver;
public static void setObserver(@Nullable Observer observer) {
sObserver = observer;
}Сама логика вызова методов Observer довольно простая.
Object token = null;
if (observer != null) {
token = observer.messageDispatchStarting();
}
long origWorkSource = ThreadLocalWorkSource.setUid(msg.workSourceUid);
try {
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} catch (Exception exception) {
if (observer != null) {
observer.dispatchingThrewException(token, msg, exception);
}
throw exception;
} finally {
ThreadLocalWorkSource.restore(origWorkSource);
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}В момент обработки сообщения внутри метода loop проверяется - есть ли сейчас наблюдатель, если наблюдатель имеется то у него вызывается метод messageDispatchStarting. Методы messageDispatched и dispatchingThrewException вызываются в соответствующих местах.
Можно заметить, что обработка сообщения обернута в try-catch-finally. Это необходимо, чтобы в случае ошибки правильно отработали методы трассировки SysTrace, а так же вызов метода dispatchingThrewException у наблюдателя. И лишь потом будет брошено исключение которое и завершит наше приложение.
Это пожалуй все интересные особенности класса Looper в Android SDK.
ActivityThread
Теперь давайте рассмотрим где же всё-таки у нас идет работа с самим Looper. А происходит это всё также в методе main и находится он в классе ActivityThread.
public static void main(String[] args) {
..................
Looper.prepareMainLooper();
..................
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
..................
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}В нем сначала вызывается метод prepareMainLooper. Далее выставляется реализация Printer. И под самый конец метода вызывается метод loop запускающий главный цикл. Последней строкой этого метода бросается исключение. Таким образом, как только цикл завершится, то и завершится весь процесс.
Если хотите поподробнее узнать о том как запускается процесс в андроид то рекомендую посмотреть эту статью.
MessageQueue
Теперь рассмотрим какими особенностями обладает MessageQueue - класс отвечающий за работу очереди сообщений в Android SDK.
Main Thread не ждет
Первая особенность MessageQueue заключается в том, что вместо стандартных методов из Java wait и notify используются нативные методы nativePollOnce и nativeWake.
private long mPtr;
private native void nativePollOnce(long ptr, int timeoutMillis);
private native static void nativeWake(long ptr);
Message next() {
..................
nativePollOnce(mPtr, nextPollTimeoutMillis);
..................
}
boolean enqueueMessage(Message msg, long when) {
..................
nativeWake(mPtr);
..................
}Когда мы пытаемся запросить следующее сообщение и его не оказывается, то вместо wait вызывается nativePollOnce, в который передается время на которое надо уснуть.
Когда мы пытаемся добавить новое сообщение у нас вместо метода notify вызывается метод nativeWake.
Почему же нельзя воспользоваться обычными wait и notify? Дело в том, что у Android приложений помимо Java слоя есть еще и прослойка C++ в которой на главном потоке тоже могут происходит различные операции которые стоит выполнить. Следовательно воспользоваться wait у нас не получится, так как это усыпит главный поток без передачи управления прослойке C++.
В прослойке C++ так же есть свой Looper, но подробнее мы разберем его в следующей статье.
Вызов C++ конечно интересен сам по себе, но есть в MessageQueue что-то, что может пригодится обычному разработчику? Конечно есть.
IdleHandler
Это особый механизм, который позволяет выполнять какие-либо действия на главном потоке когда все сообщения из очереди будут выполнены. Он хорошо подходит для действий которым неважно когда они будут выполнены - сейчас или через пол секунды. С помощью этого механизма можно избавиться от некоторых фризов, убрав какое-то тяжелое или не очень действие из основной очереди сообщений.
Например в приложении VK отметка о том, что сообщение прочли выставляется именно таким образом, а в ЦИАН IdleHadler используется для тяжелых действий при работе с картой.
Давайте посмотрим на реализацию этого механизма. По своей сути IdleHandler это обычный интерфейс с одним единственным методом - queueIdle. В нем и будет содержатся действие которое мы планируем выполнить.
public static interface IdleHandler {
boolean queueIdle();
}Как можно заметить, этот метод возвращает boolean. Если вернуть false, то наше действие больше не повторится, если же вернуть true - то наше действие выполнится еще раз. Поэтому лучше лишний раз не ставить true, дабы избежать ситуаций когда у нас появляется бесконечно повторяющееся действие на главном потоке.
В классе MessageQueue в поле mIdleHandlers находится список еще не выполненных IdleHandler, а также есть метод для добавления нового IdleHandler - addIdleHandler.
private final ArrayList<IdleHandler> mIdleHandlers = new ArrayList<IdleHandler>();
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}Единственной особенностью addIdleHandler является синхронизация.
Теперь, надо как-то узнать, что основная очередь сообщений опустела и настало время выполнения IdleHandler’ов. Для этого в методе next, после того как станет понятно, что доступных для выполнения сообщений в основной очереди нет, выполнится следующий код:
Message next() {
int pendingIdleHandlerCount = -1;
..................
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
mBlocked = true;
continue;
}
..................
}По сути произойдет проверка, что в ходе выполнения метода next, IdleHandler’ы еще не запускались, а также что сообщений в очереди, которые нужно обработать прямо сейчас, уже нет. Если это так, то начнется обработка IdleHandler, иначе просто будет обработано следующее сообщение.
Настало время выполнить IdleHandler.
private IdleHandler[] mPendingIdleHandlers;
Message next() {
..................
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
..................
}Для этого значения из mIdleHandlers копируются в отдельный массив mPendingIdleHandlers. Отдельный массив нужен, чтобы избежать проблем с многопоточностью.
Само же выполнение происходит достаточно стандартно. В цикле мы проходим по нашим IdleHandler и последовательно выполняем каждый из них.
private IdleHandler[] mPendingIdleHandlers;
Message next() {
..................
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null;
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
pendingIdleHandlerCount = 0;
}При этом выполнение обернуто в try-catch. После выполнения в зависимости от результата метода queueIdle IdleHandler удалиться из общего списка на выполнение. Если во время выполнения IdleHandler он бросит исключение, то он так же удалиться из списка на выполнение.
От чего-то полезного перейдем к тому, чем вы по идее никогда не должны пользоваться, ну разве что очень редко.
syncBarrier
syncBarrier нужен для того чтобы остановить выполнение очереди сообщений по какой-либо причине.
К сожалению (или к счастью) методы работы с syncBarrier помечены аннотацией Hide, а значит мы не сможем вызвать их из своего кода честными методами.
Основной способ использования этого механизма появился в Android 5. В нем появился выделенный поток для рендеринга (до этого рендеринг происходил на главном потоке). Из-за этого пришлось придумывать как останавливать обработку главного потока, а конкретно его задач связанных с интерфейсом, пока поток рендеринга считывал дерево View.
Работает этот механизм очень просто. Для того чтобы исполнение очереди сообщений приостановилось, в очередь сообщений добавляется особо промаркированное сообщение.
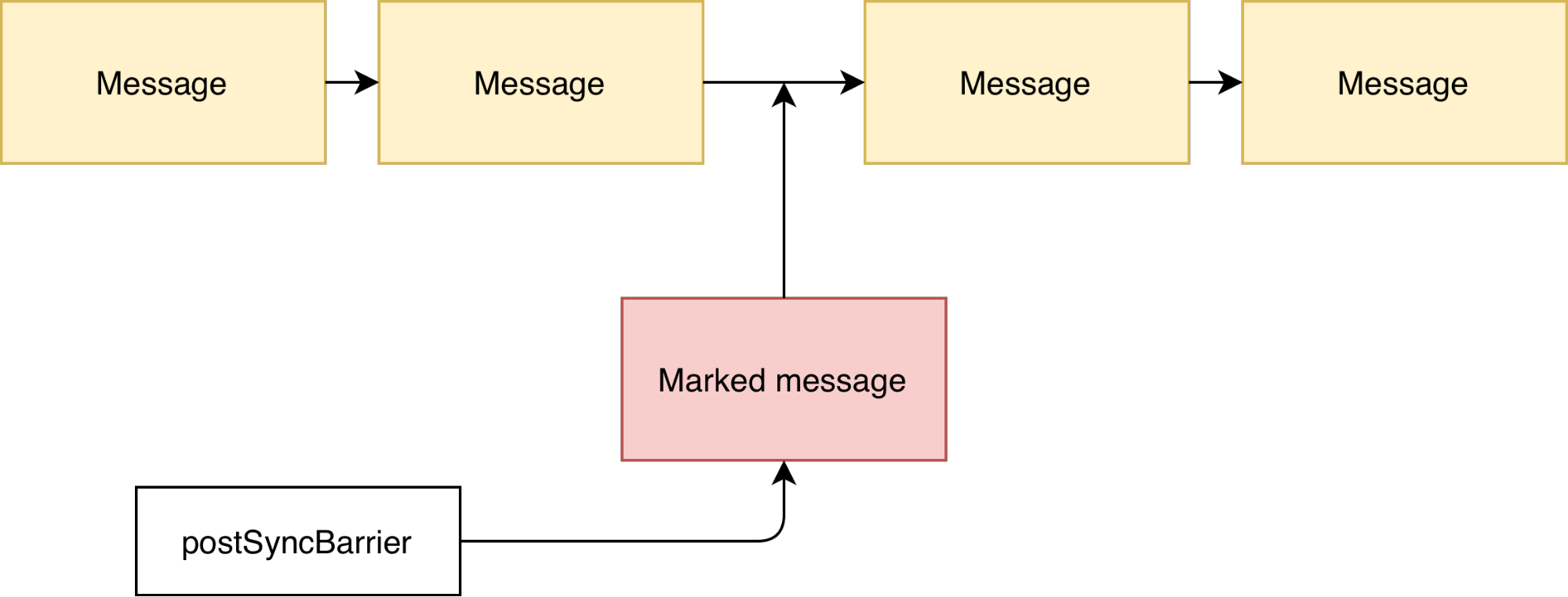
Далее когда при выполнении метода MessageQueue next оно окажется следующим, то очередь сообщений остановится вместо того чтобы выполнять сообщения.
Затем, когда нужно восстановить обработку очереди сообщений промаркированное сообщение удаляется и очередь продолжает работать как не в чем не бывало.
Но ведь не все задачи главного потока связаны с отрисовкой View. Зачем останавливать все сообщения? Разработчики Android SDK подумали так же. Вы можете пометить ваше сообщение как асинхронное, с помощью метода Message.setAsynchronous(true). На такие сообщения syncBarrier не распространяется и они продолжат выполняться в обычном режиме.
Message
Важное примечание. Класс Message и Handler мы будем рассматривать только в контексте главного цикла. Другие их особенности связанные с возможностью передачи сообщений между потоками и между разными узлами приложения - сейчас опустим.
Pool, obtain, recycle
У Message имеется private конструктор. Для чего это сделано? Так как, за время работы процесса в нем генерируется и пересылается огромное количество сообщений, то каждый раз создавать новый объект Message будет весьма затратно. Даже такая простая вещь как создание объекта при большом количестве вызовов может иметь значение. Поэтому используются особый pool сообщений. В него будут складываться уже ставшие ненужными объекты Message и когда нам понадобится новое сообщение мы вместо создания нового объекта просто будем переиспользовать старый ненужный объект.
Так же, как и в случае с очередью сообщений, pool представляет из себя односвязный список, ссылка на начало которого хранится в поле sPool. Отдельным полем sPoolSize хранится размер этого списка, он нам понадобится чтобы наш pool не слишком разрастался и мы могли контролировать его размер.
private static Message sPool;
private static int sPoolSize = 0;
public static final Object sPoolSync = new Object();Так как конструктор приватный, то новое сообщение создается через метод obtain. Рассмотрим его подробнее:
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0;
sPoolSize--;
return m;
}
}
return new Message();
}Первое что нас ждёт - блок синхронизации, внутри него мы смотрим - есть ли у нас сообщения в sPool. Если есть, то забираем первое сообщение из pool и возвращаем его, при этом не забывая поменять ссылку на начало списка и уменьшить значение sPoolSize.
Если же в sPool сообщений нет, то создаем новое сообщение через приватный конструктор. Но как объекты попадают в sPool? Для этого, после того как MessageQueue выполняет действие сообщения, оно вызывает у него метод recycle.
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
recycleUnchecked();
}Внутри этого метода сначала проверяется - используется ли сейчас сообщение, если да, то бросается исключение, ведь в sPool должны попадать уже ненужные сообщения. Иначе вызывается приватный метод recycleUnchecked.
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}Внутри recycleUnchecked во все поля сообщения выставляются значения по умолчанию, а затем если наш pool ещё не заполнен, то в него добавляется наше сообщение, при этом значение sPoolSize увеличивается.
Handler
Зачем он нужен
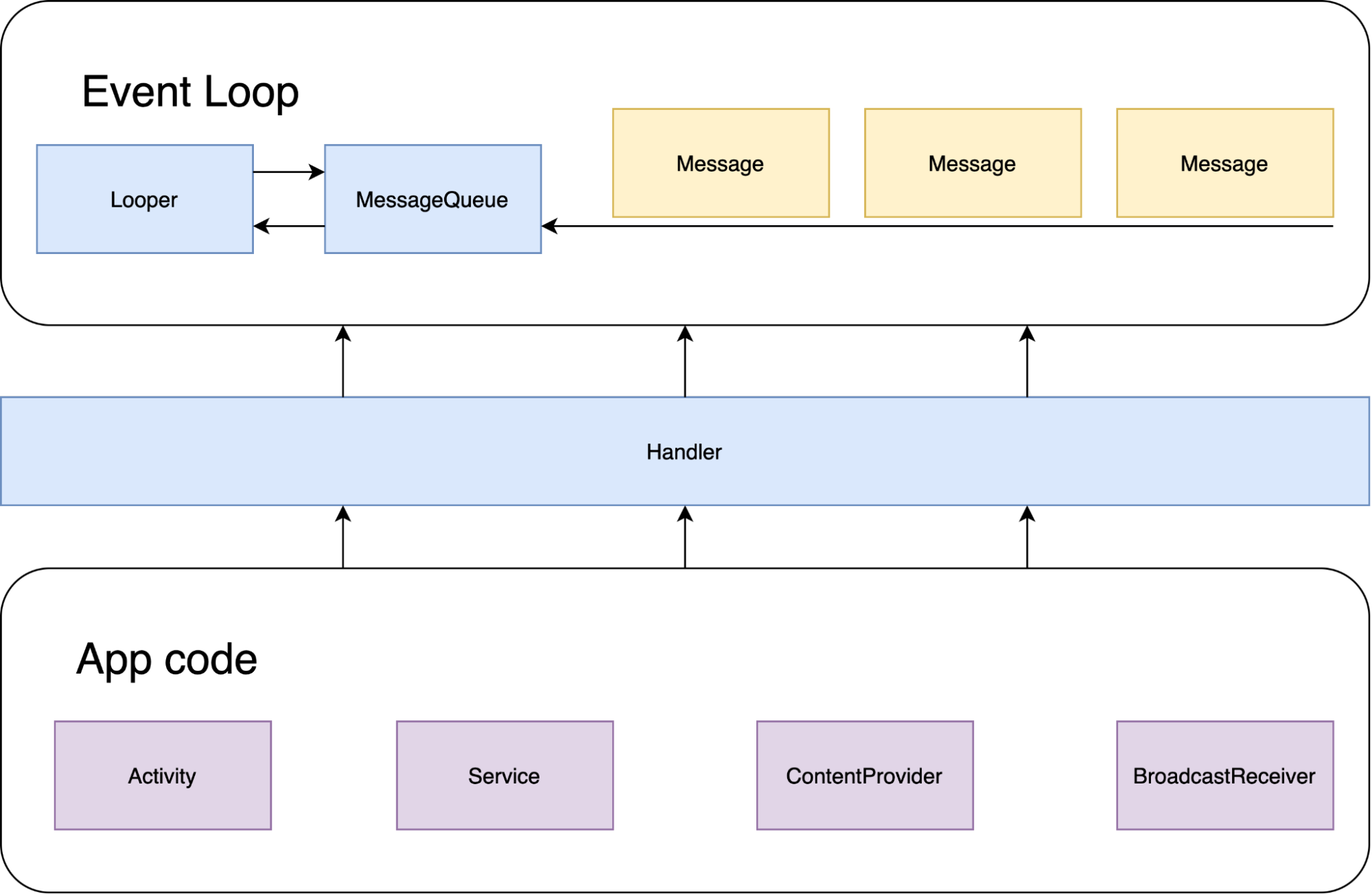
Помимо Looper, Message и MessageQueue в главном цикле Android SDK присутствует ещё один класс - Handler. Для чего же он нужен? Дело в том, что что с точки зрения безопасности и стабильности кода давать программистам прямой доступ к очереди сообщений может быть опасно. Помимо того, что кто-то может напакостить поменяв очередь, так ещё и такие изменения будет очень сложно отследить. Для решения этой проблемы и нужен Handler, он является фасадом для логики работы с очередью сообщений.
Если мы захотим из кода приложения добавить новое сообщение в очередь, то мы должны делать это через Handler, напрямую это сделать никак не получится, так как большинство методов MessageQueue имеют видимость package-local, а не public.
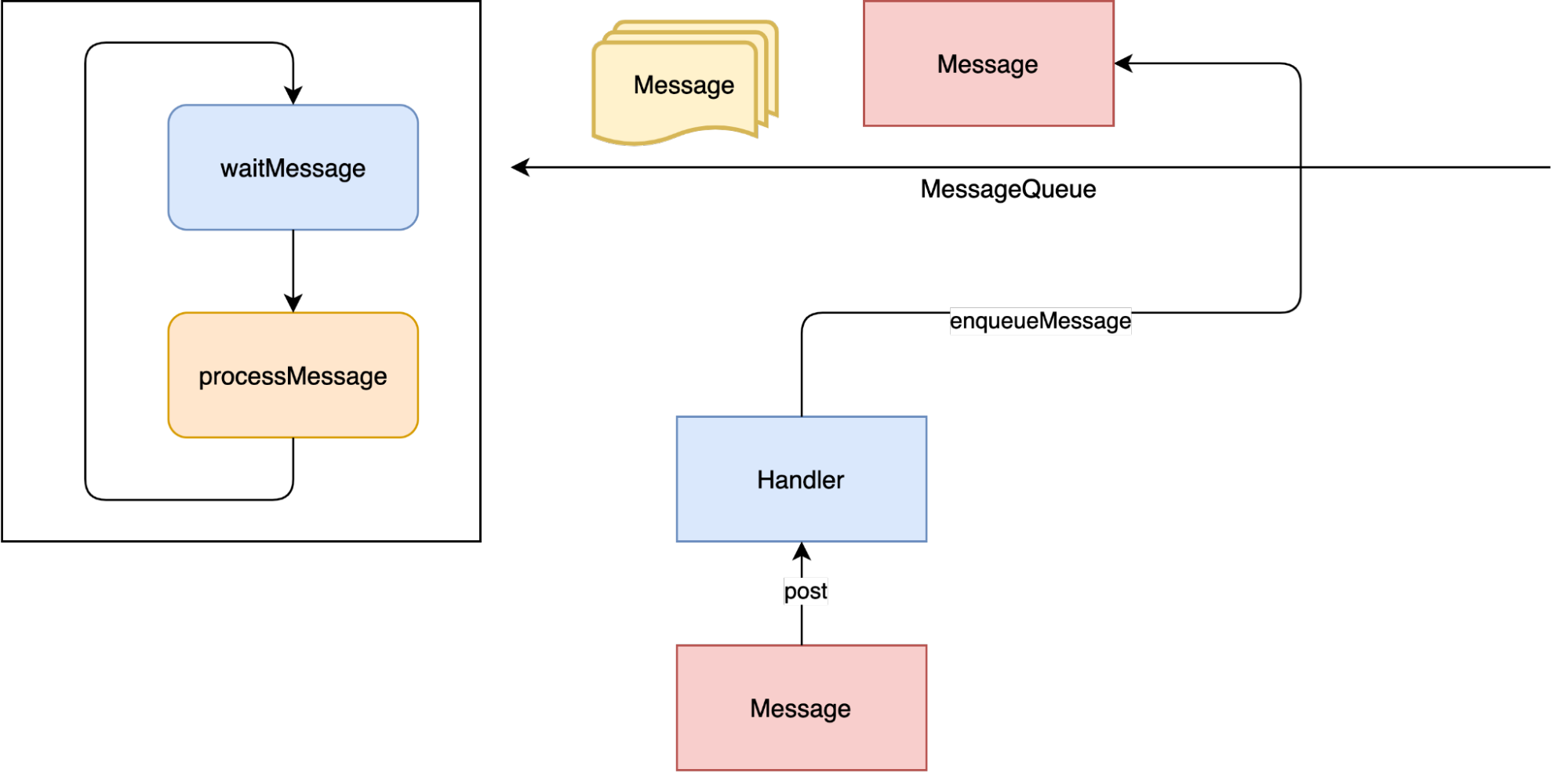
post и postDelayed
Итак, мы захотели добавить новое сообщение в очередь. Как нам это сделать? Для добавления нового сообщения в очередь у Handler есть методы post и postDelayed. Эти методы есть не только у Handler, но и например у view: post, postDelayed, есть аналог и у Activity: runOnUiThread, но все они так или иначе в итоге сводятся к вызову Handler.
Метод post просто добавляет новое сообщение в конец очереди.
Метод postDelayed добавляет отложенное сообщение, которое выполнится через определенный промежуток времени. Для этого в поле when класса Message записывается время с момента старта JVM + время через которое надо выполнить сообщение, таким образом MessageQueue понимает когда надо выполнить сообщение.
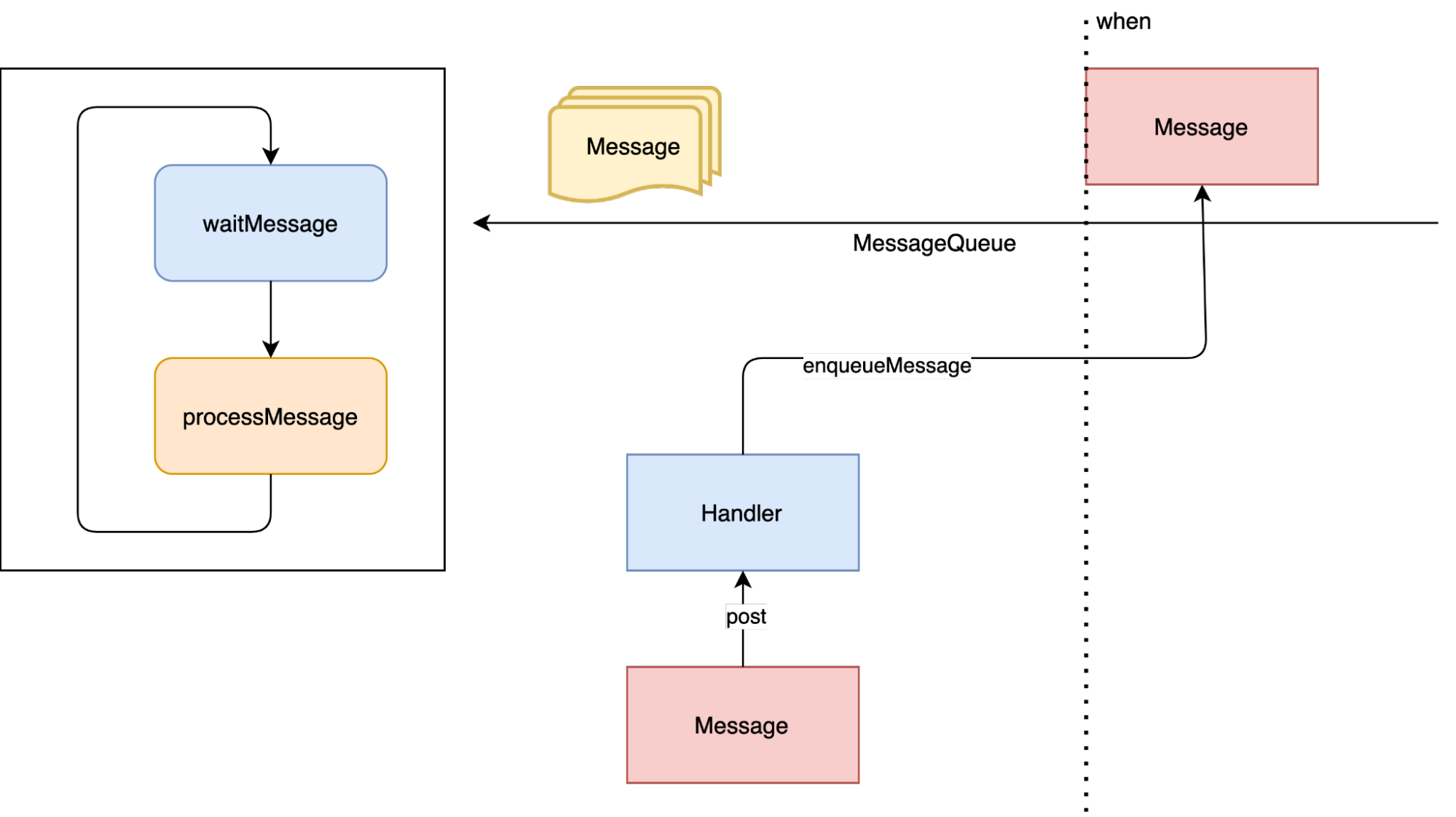
Стоит заметить, что с postDelayed стоит быть аккуратными если вы используете их в объектах с коротким жизненным циклом. Иначе может сложится ситуация когда ваш объект уже готов быть собран сборщиком мусора, но сообщение которое он отправил ещё не успело выполнится. В случае с post беда не велика и я бы даже назвал это микроутечкой памяти, но в случае с postDelayed это уже может быть скорее миниутечка, ведь объект утечет на тот период времени, что вы указали.
На мой взгляд, это пожалуй все самое интересное из Android SDK связанное с Looper, MessageQueue и Message. Поэтому можно сказать, что как главный цикл работает в Android SDK и какие особенности имеет мы разобрались. По крайней мере на слое Java, но есть же еще и упомянутый C++ слой. Да и не секрет, что Android приложения пишутся не только с помощью Java Android SDK, есть Flutter, React Native, Chrome и игры. Какие особенности есть у них мы кратко разберем в следующей и финальной части этого цикла статей.
Main Loop (Главный цикл) в Android Часть 1. Пишем свой цикл
Main Loop (Главный цикл) в Android Часть 3. Другие главные циклы
