
Попробовать можно тут
Тыкать тут

Привет Хабр, сегодня мы поговорим о такой важной теме как мультимодальные трансформеры.
Что же это такое в контексте машинного обучения - это способность одной модели работать сразу с несколькими видами данных - текстом, картинками, звуком, вытаскивать из них фичи в единое векторное пространство и манипулировать контентом на входе и выходе. Эта идея появилась еще на заре трансформеров в статье One Model To Learn Them All

Авторы из гугл использовали единый байтовый энкодер для любых входных данных, MoE для управления модальностями и единый декодер для всех задач.
Но вернемся в наше время к ресерчу проводимому в рамках fusion brain challenge.

Тут авторы исходят из концепции - большие языковые модели достаточно умны чтобы решать любые задачи, при условии правильного формирования входной последовательности модели - внутренняя модель (Decoder only(GPT/Dalle) / Full transformer (T5/Bart) ) замораживается, учится только линейный слой на входе и на выходе. В таком варианте модель может решать VQA,Image captioning, Code2code, etc при этом не уча каждый раз разную модель. В данном случае одна модель решает все задачи, при этом довольно эффективно хотя и не бьет SOTA результаты.
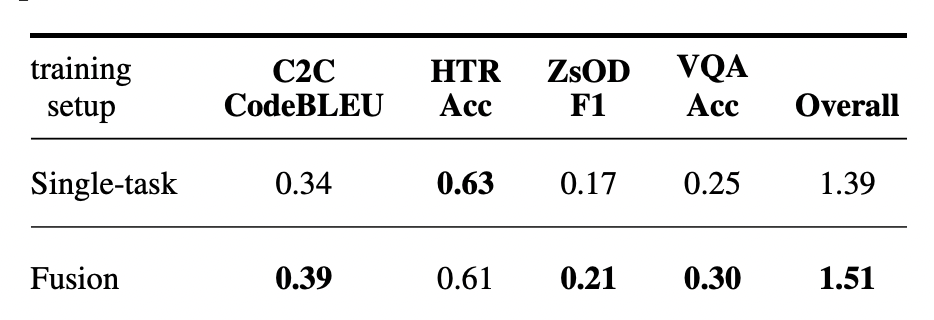
Что то я заговорился про близкую мне тему, а про борщи не слова
В ноябре этого года Сбер выложил супер важную модель - ruDall-e. Далекий от ресерча человек сейчас может задаться логичным вопросом - а в чем ценность? Почему смешные картинки котов так важны?
Ответ прост - это важный шаг к построению более сложных моделей, по сути Dalle-like выполняет роль переводчика между текстовой и картиночной модальностью. Не зная напрямую фактов из реального мира модель тем не менее их использует.
Но как вы поняли речь пойдет о следущей модели Сбера: Rudolph - One Hyper-Modal transformer can be creative as DALL-E and smart as CLIP
Тут идея в том чтобы на вход в декодер подавать не просто Текст-Картинка как в DALL-E/Nuwa/CogView, а триплет вида l-Text-Image-r-Text

при этом, модель учится с разными масками внимания, каждая из которых используется для решения разных задач. Те одна модель может решать и задачу продолжения текста как GPT, задачу генерации изображений и задачу генерации подписи к изображениям. Репозиторий
Давайте перейдем к теме статьи и обучим модель
Коллаб ноутбук для самых нетерпеливых
Пропустим крайне не интересный сбор картинок с подписями, у меня получился такой сет на 500 примеров в таком формате

И вот такое облако слов для нашего сета

Установим все что нам понадобится, скачаем и разжимаем данные
!pip install rudolph==0.0.1rc4 > /dev/null !pip install bitsandbytes-cuda111 > /dev/null !pip install wandb > /dev/null !gdown https://drive.google.com/uc?id=17bPt7G3N_vGKCCxppIOPbPlhv1qUnv0o !unzip -qn food.zip > /dev/null
Гугл диск кажется изменили политику распространения файлов, скачайте руками файл с датасетом и погрузите в среду выполнения
Импортируем все что нужно
import os import sys import random from collections import Counter import PIL import torch import numpy as np import pandas as pd import bitsandbytes as bnb import torchvision.transforms as T import torchvision.transforms.functional as TF from tqdm import tqdm from wordcloud import WordCloud from matplotlib import pyplot as plt from torch.utils.data import Dataset, DataLoader from rudalle import get_tokenizer, get_vae from rudalle.utils import seed_everything from rudolph.model.utils import get_attention_mask from rudolph.model import get_rudolph_model, ruDolphModel, FP16Module from rudolph.pipelines import generate_codebooks, self_reranking_by_image, self_reranking_by_text, show, generate_captions, generate_texts, zs_clf from rudolph import utils device = 'cuda' model = get_rudolph_model('350M', fp16=True, device='cuda') tokenizer = get_tokenizer() vae = get_vae(dwt=False).to(device)
Опишем параметры для обучения, куда будем сохранять модель и гиперпараметры оптимайзера
class Args(): def __init__(self, model): self.device = model.get_param('device') self.l_text_seq_length = model.get_param('l_text_seq_length') self.r_text_seq_length = model.get_param('r_text_seq_length') self.image_tokens_per_dim = model.get_param('image_tokens_per_dim') self.image_seq_length = model.get_param('image_seq_length') self.epochs = 5 self.save_path='checkpoints/' self.model_name = 'awesomemodel_' self.save_every = 500 self.bs = 10 self.clip = 1.0 self.lr = 2e-5 self.wandb = False self.lt_loss_weight = 0.01 self.img_loss_weight = 1 self.rt_loss_weight = 7 self.image_size = self.image_tokens_per_dim * 8 args = Args(model) if not os.path.exists(args.save_path): os.makedirs(args.save_path)
Стандартный класс Dataset для image2text text2image задач
class FoodDataset(Dataset): def __init__(self, file_path, csv_path, tokenizer, shuffle=True): self.tokenizer = tokenizer self.samples = [] self.image_transform = T.Compose([ T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img), T.RandomResizedCrop(args.image_size, scale=(1., 1.), ratio=(1., 1.)), T.ToTensor() ]) df = pd.read_csv(csv_path) df.columns = ['index', 'belok', 'fats', 'uglevod', 'kkal', 'name', 'path'] for belok, fats, uglevod, kkal, caption, f_path in zip( df['belok'],df['fats'], df['uglevod'], df['kkal'], df['name'], df['path'] ): caption = f'блюдо: {caption}; белков: {belok}; жиров: {fats}; углеводов: {uglevod}; ккал: {kkal};' if len(caption)>10 and len(caption)<100 and os.path.isfile(f'{file_path}/{f_path}'): self.samples.append([file_path, f_path, caption.lower()]) if shuffle: np.random.shuffle(self.samples) print('Shuffled') def __len__(self): return len(self.samples) def load_image(self, file_path, img_name): return PIL.Image.open(f'{file_path}/{img_name}') def __getitem__(self, item): item = item % len(self.samples) file_path, img_name, text = self.samples[item] try: image = self.load_image(file_path, img_name) image = self.image_transform(image) except Exception as err: print(err) random_item = random.randint(0, len(self.samples) - 1) return self.__getitem__(random_item) text = text.lower().strip() encoded = self.tokenizer.encode_text(text, text_seq_length=args.r_text_seq_length) return encoded, image
Обратите внимание что размер изображения 128*128, поэтому качество генерации изображения будет не очень интересным, для генерации изображений лучше использовать ruDall-e, там и параметров в 5 раз больше и размер изображения 256.
Опишем класс датасета и загрузим в DataLoader
dataset = FoodDataset(file_path='/content/food' ,csv_path ='/content/food/food.csv',tokenizer=tokenizer) train_dataloader = DataLoader(dataset, batch_size=args.bs, shuffle=True, drop_last=True)
Выставим логи на Wandb если вы залогинились
try: if args.wandb: import wandb wandb.init(project = args.model_name) except: args.wandb = False print('If you want to use wandb logs pls login via wandb -login')
Заморозим часть параметров модели для экономии памяти и воспользуемся 8-битным оптимайзером для более эффективного файнтюна
def freeze( model, freeze_emb=False, freeze_ln=False, freeze_attn=True, freeze_ff=True, freeze_other=False, ): for name, p in model.module.named_parameters(): name = name.lower() if 'ln' in name or 'norm' in name: p.requires_grad = not freeze_ln elif 'embeddings' in name: p.requires_grad = not freeze_emb elif 'mlp' in name: p.requires_grad = not freeze_ff elif 'attn' in name: p.requires_grad = not freeze_attn else: p.requires_grad = not freeze_other return model model.train() optimizer = bnb.optim.Adam8bit(model.parameters(), lr=args.lr) scheduler = torch.optim.lr_scheduler.OneCycleLR( optimizer, max_lr=args.lr, final_div_factor=500, steps_per_epoch=len(train_dataloader), epochs=args.epochs )
И функцию для обучения модели
def train(model,args: Args, train_dataloader: FoodDataset): """ args - arguments for training train_dataloader - RuDalleDataset class with text - image pair in batch """ loss_logs = [] try: progress = tqdm(total=len(train_dataloader)*args.epochs, desc='finetuning goes brrr??☃️') save_counter = 0 for epoch in range(args.epochs): for text, images in train_dataloader: save_counter+=1 model.zero_grad() total_seq_length = args.l_text_seq_length + args.image_seq_length + args.r_text_seq_length masks = torch.ones(args.bs, args.r_text_seq_length, dtype=torch.int32) attention_mask = get_attention_mask(masks, args.bs, args.l_text_seq_length, args.image_tokens_per_dim, args.r_text_seq_length, device) image_input_ids = vae.get_codebook_indices(images.to(device)) r_text = text.to(device) l_text = torch.zeros((args.bs, args.l_text_seq_length), device=device, dtype=torch.long) input_ids = torch.cat((l_text, image_input_ids, r_text), dim=1) loss, loss_values = model.forward(input_ids, attention_mask, lt_loss_weight=args.lt_loss_weight, img_loss_weight=args.img_loss_weight,rt_loss_weight=args.rt_loss_weight, return_loss=True) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(),args.clip) optimizer.step() scheduler.step() optimizer.zero_grad() if save_counter % args.save_every == 0: print(f'Saveing checkpoint here {args.model_name}_dalle_{save_counter}.pt') plt.plot(loss_logs) plt.show() torch.save( model.state_dict(), os.path.join(args.save_path,f"{args.model_name}_dalle_{save_counter}.pt") ) if args.wandb: wandb.log({"loss": loss.item()}) loss_logs+=[loss.item()] progress.update() progress.set_postfix({"loss": loss.item()}) print(f'Complitly tuned and saved here {args.model_name}__dalle_last.pt') plt.plot(loss_logs) plt.show() torch.save( model.state_dict(), os.path.join(args.save_path,f"{args.model_name}dalle_last.pt") ) except KeyboardInterrupt: print(f'What for did you stopped? Please change model_path to /{args.save_path}/{args.model_name}_rudolf_Failed_train') plt.plot(loss_logs) plt.show() torch.save( model.state_dict(), os.path.join(args.save_path,f"{args.model_name}_rudolf_Failed_train.pt") ) except Exception as err: print(f'Failed with {err}') model = freeze( model=model, freeze_emb=False, freeze_ln=False, freeze_attn=True, freeze_ff=True, freeze_other=False, ) train(model, args, train_dataloader)
Запустим обучение

Запустим инференс и проверим что все работает хорошо
template = 'блюдо:' import requests from PIL import Image import torch img_by_url = 'https://kulinarenok.ru/img/steps/31445/1-7.jpg' #@param {type:"string"} img_by_url = Image.open(requests.get(img_by_url, stream=True).raw).resize((128, 128)) #@markdown number of images captions_num = 4 #@param{type:'slider'} display(img_by_url) texts = generate_captions(img_by_url, tokenizer, model, vae, template=template, top_k=16, captions_num=captions_num, bs=16, top_p=0.6, seed=43, temperature=0.8, limit_eos=False) ppl_text, ppl_image = self_reranking_by_image(texts, img_by_url, tokenizer, model, vae, bs=16, seed=42) for idx in ppl_image.argsort()[:8]: print(texts[idx])
Проверим на шаурме способности модели к ZeroShot(способности модели предсказывать данные которых не было в обучающей выборке)

Ну и в целом получаем верный результат, а именно лаваш с ветчиной и сыром.
Полезные ссылки
Благодарности и ссылки
Отдельное спасибо Мишин Лернинг и Денису Димитрову за редактуру и мотивацию для написания статьи.
