1. Introduction
After Epic released the UE5 technology demo at the beginning of 2021, the discussion about UE5 has never stopped. Related technical discussions mainly centered on two new features: global illumination technology Lumen and extremely high model detail technology Nanite. There have been some articles [1 ][2] analyzing Nanite technology in more detail. This article mainly starts from the RenderDoc analysis and source code of UE5, combined with some existing technical data, aims to provide an intuitive and overview understanding of Nanite, and clarify its algorithm principles and design ideas, without involving too many source code level Implementation details.
2. What do we need for next-generation model rendering?
To analyze the technical points of Nanite, we must first proceed from the perspective of technical requirements. In the past ten years, the development of 3A games has gradually tended to two main points: interactive film narrative and open world. In order to cutscene realistically, the character model needs to be exquisite; for a sufficiently flexible and rich open world, the map size and the number of objects have increased exponentially, both of which have greatly increased the requirements for the fineness and complexity of the scene: The number of objects must be large, and each model must be sufficiently detailed.
There are usually two bottlenecks in the rendering of complex scenes:
The CPU-side verification and communication overhead between CPU-GPU brought by each Draw Call;
Overdraw caused by inaccurate elimination and the resulting waste of GPU computing resources;
In recent years, the optimization of rendering technology has often revolved around these two problems, and some technical consensus in the industry has been formed.
In view of the overhead caused by CPU-side verification and status switching, we have a new generation of graphics APIs (Vulkan, DX12, and Metal), which are designed to allow drivers to do less verification work on the CPU side; different tasks are dispatched through different Queues For GPU (Compute/Graphics/DMA Queue); developers are required to handle the synchronization between CPU and GPU by themselves; make full use of the advantages of multi-core CPU and multi-thread to submit commands to GPU. Thanks to these optimizations, the number of Draw Calls of the new generation graphics API has increased by an order of magnitude compared with the previous generation graphics API (DX11, OpenGL) [3].
Another optimization direction is to reduce the data communication between the CPU and GPU, and more accurately remove triangles that do not contribute to the final picture. Based on this idea, GPU Driven Pipeline was born. For more information about GPU Driven Pipeline and culling, you can read this article by the author [4].
Thanks to the more and more widespread application of GPU Driven Pipeline in games, the vertex data of the model is further divided into more fine-grained Clusters (or Meshlets) so that the granularity of each Cluster can better adapt to the Vertex Processing stage. Cache size and various types of culling (Frustum Culling, Occlusion Culling, and Backface Culling) have gradually become the best practice for complex scene optimization, and GPU vendors have gradually recognized this new vertex processing flow.
However, the traditional GPU Driven Pipeline relies on Compute Shader culling. The removed data needs to be stored in the GPU Buffer. Via APIs such as Execute Indirect, the removed Vertex/Index Buffer is fed back to the GPU’s Graphics Pipeline, which has increased the invisible overhead of reading and writing. In addition, the vertex data will be read repeatedly (Compute Shader reads before culling and Graphics Pipeline reads through Vertex Attribute Fetch when drawing).
Based on the above reasons, in order to further improve the flexibility of vertex processing, NVidia first introduced the concept of Mesh Shader[5], hoping to gradually remove some fixed units (VAF, PD, and other hardware units) in the traditional vertex processing stage. And hand over these matters to the developer to process through the programmable pipeline (Task Shader/Mesh Shader).

Schematic of Cluster
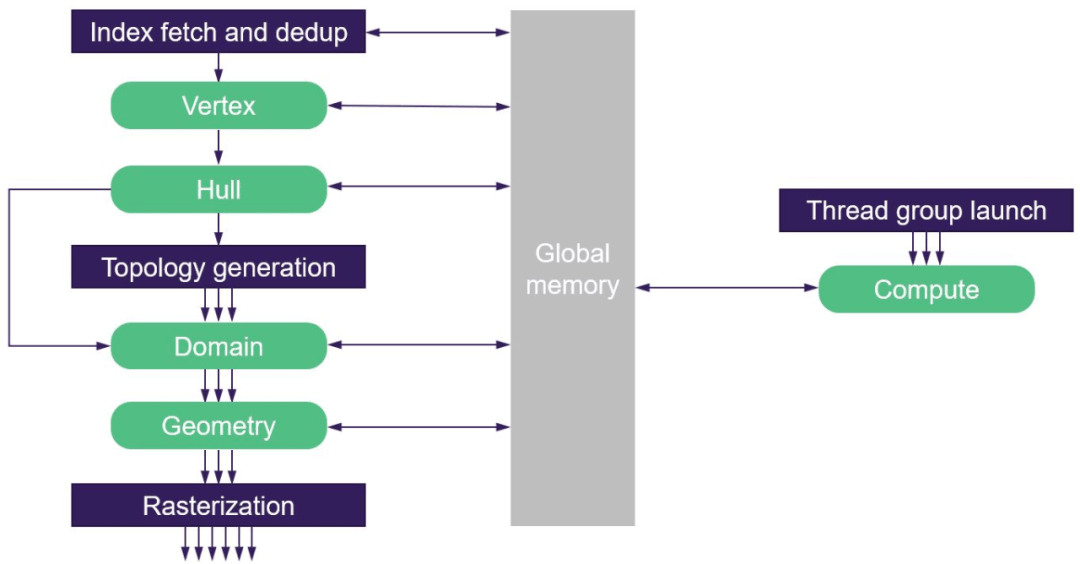
The traditional GPU Driven Pipeline eliminates dependence on CS, and the eliminated data is passed to the vertex processing pipeline through VRAM
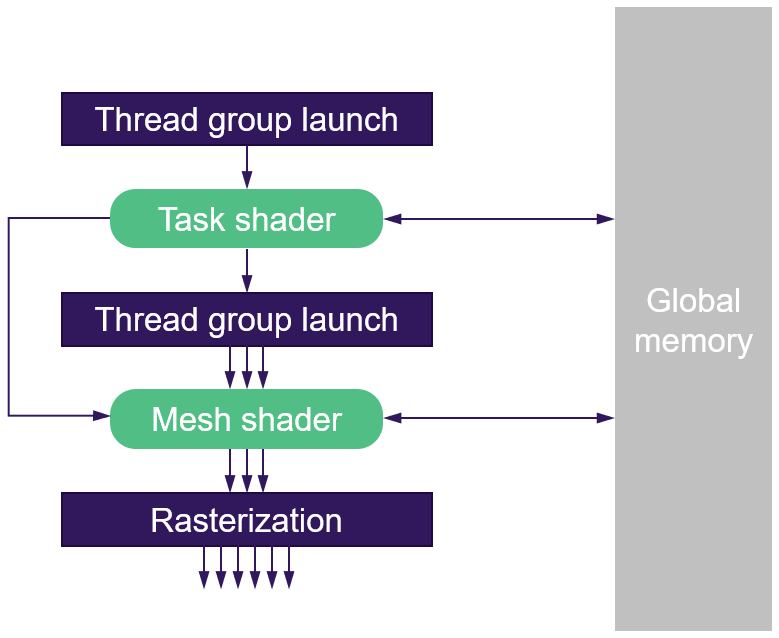
The Pipeline Based on the Mesh Shader, Cluster culling becomes part of the vertex processing stage, reducing unnecessary Vertex Buffer Load/Store
3. Are these enough?
So far, the problems of the number of models, the number of triangle vertices, and the number of faces have been greatly optimized and improved. However, high-precision models and small triangles at pixel level put new pressure on the rendering pipeline: rasterization and overdraw pressure.
Does soft rasterization have a chance to beat hard rasterization?
To clarify this problem, you first need to understand what hard rasterization does and what general application scenarios it envisages is. Read this article if you are interested in this [6]. To put it simply: At the beginning of the design of traditional rasterization hardware, the size of the input triangle envisaged is much larger than one pixel. Based on this assumption, the process of hardware rasterization is usually hierarchical.
Taking the NVIDIA Rasterizer as an example, a triangle usually undergoes two stages of rasterization: Coarse Raster and Fine Raster. The former takes a triangle as input and 8×8 pixels as a block, and the triangle is rasterized into several blocks (it can also be understood as rough rasterization on the FrameBuffer whose original size is FrameBuffer 1/8*1/8).
At this stage, the occluded block will be completely eliminated through the low-resolution Z-Buffer, which is called Z Cull on the NVIDIA card; after the Coarse Raster, the block that passes through the Z Cull will be sent to the next stage for processing Fine Raster, which finally generates pixels for shading calculations. In the Fine Raster stage, we are familiar with Early Z. Due to the calculation needs of Mip-Map sampling, we must know the information of the adjacent pixels of each pixel, and use the difference of the sampled UV as the calculation basis for the Mip-Map sampling level. For this reason, the final output of Fine Raster is not a pixel, but a small 2×2 Pixel Quad.
For triangles close to the pixel size, the waste of hardware rasterization is obvious. First of all, the Coarse Raster stage is almost useless, because these triangles are usually smaller than 8×8. This situation is even worse for those long and narrow triangles because a triangle often spans multiple blocks, and these triangles cannot be removed by Coarse Raster but also add additional computational burden; in addition, for large triangles, the Fine Raster stage based on Pixel Quad will only generate a small number of useless pixels on the edge of the triangle, which is only a small part of the area of the entire triangle; But for small triangles, Pixel Quad will generate pixels four times the area of the triangle at worst, and these pixels are also included in the execution stage of Pixel Shader, which greatly reduces the effective pixels in WARP.
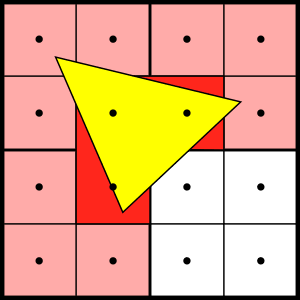
Rasterization waste of small triangles due to Pixel Quad
For the above reasons, soft rasterization (based on Compute Shader) does have a chance to defeat hard rasterization under the specific premise of pixel-level small triangles. This is also one of Nanite’s core optimizations. This optimization makes UE5 improve the efficiency of small triangle rasterization by 3 times [7].
Deferred Material
The problem of redrawing has long been a performance bottleneck in graphics rendering, and optimizations around this topic are also emerging endlessly. On the mobile side, there is the familiar Tile Based Rendering architecture [8]; in the evolution of the rendering pipeline, some people have also proposed Z-Prepass, Deferred Rendering, Tile Based Rendering, and Clustered Rendering, these different rendering pipeline frameworks, In fact, they are all to solve the same problem: when the light source exceeds a certain number and the complexity of the material increases, how to avoid a large number of rendering logic branches in the Shader and reduce useless redrawing. On this topic, you can read my article [9].
Generally speaking, the deferred rendering pipeline needs a set of Render Targets called G-Buffers. These textures store all the material information needed for lighting calculations. In today’s 3A games, the types of materials are often complex and changeable, and the G-Buffer information that needs to be stored is increasing year by year. Taking the 2009 game “Kill Zone 2” as an example, the entire G-Buffer layout is as follows:

Excluding Lighting Buffer, in fact, the number of textures required for G-Buffer is 4, totaling 16 Bytes/Pixel; by 2016, the G-Buffer layout of the game “Uncharted 4” is as follows:

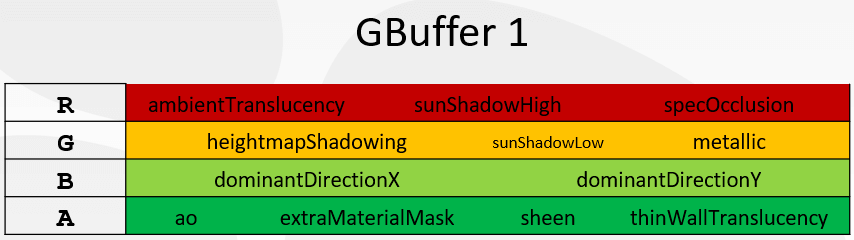
The number of textures in G-Buffer is 8, which is 32 Bytes/Pixel. In other words, in the case of the same resolution, due to the increase in material complexity and fidelity, the bandwidth required by the G-Buffer has been doubled, and this does not consider the factor of the game resolution that has increased year by year.
For scenes with high Overdraw, the read and write bandwidth generated by the drawing of G-Buffer will often become a performance bottleneck. So Academia proposed a new rendering pipeline called Visibility Buffer [10] [11]. Algorithms based on Visibility Buffer no longer generate bloated G-Buffer alone but instead use Visibility Buffer with lower bandwidth overhead. Visibility Buffer usually needs the following information:
(1) Instance ID, which indicates which Instance (16~24 bits) the current pixel belongs to;
(2) Primitive ID, which indicates which triangle (8~16 bits) of Instance the current pixel belongs to;
(3) Barycentric Coord, which represents the position of the current pixel in the triangle, expressed in barycentric coordinates (16 bits);
(4) Depth Buffer, which represents the depth of the current pixel (16~24 bits);
(5) Material ID, which indicates which material the current pixel belongs to (8~16 bits);
Above, we only need to store about 8~12 Bytes/Pixel to represent the material information of all geometries in the scene. At the same time, we need to maintain a global vertex data and texture map. The table stores the vertex data of all geometries in the current frame. , As well as material parameters and textures.
In the lighting shading stage, only need to index to the relevant triangle information from the global Vertex Buffer according to the Instance ID and Primitive ID; further, according to the center of gravity coordinates of the pixel, the vertex information in the Vertex Buffer (UV, Tangent Space, etc.) Perform interpolation to obtain pixel-by-pixel information; further, according to the Material ID to index the relevant material information, perform operations such as texture sampling, and input to the lighting calculation link to complete the coloring. Sometimes this type of method is also called Deferred Texturing.
The following is the rendering pipeline process based on G-Buffer:

This is the rendering pipeline process based on Visibility-Buffer:
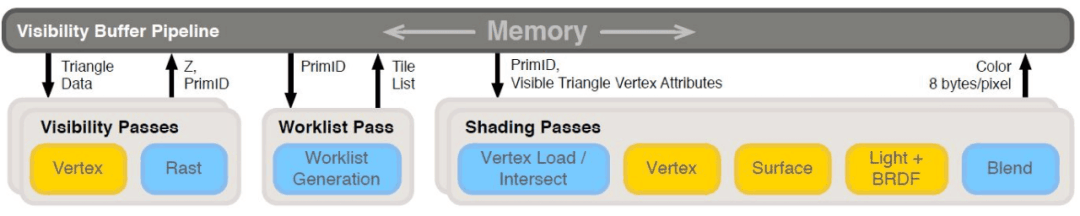
Intuitively, Visibility Buffer reduces the storage bandwidth of the information needed for shading (G-Buffer -> Visibility Buffer); in addition, it delays the reading of geometric information and texture information related to lighting calculations to the shading stage, so those non-visible Pixels on the screen do not need to read these data, but only need to read the vertex position. For these two reasons, Visibility Buffer’s bandwidth overhead is greatly reduced compared to traditional G-Buffer in complex scenes with higher resolution. However, maintaining global geometry and material data at the same time increases the complexity of engine design and reduces the flexibility of the material system. Sometimes it is necessary to use Graphics APIs such as Bindless Texture that is not yet supported by all the hardware platforms [12], which is not conducive to being compatible.
4. The Implementation in Nanite
Please check the full content on their official webpage at www,blog.en.uwa4d,com
Thanks so much for reading.
